[토치의 호흡] 10 About Transformer PART 04 "In EncoderLayer: Multi Head Attention"
Torch's Breath
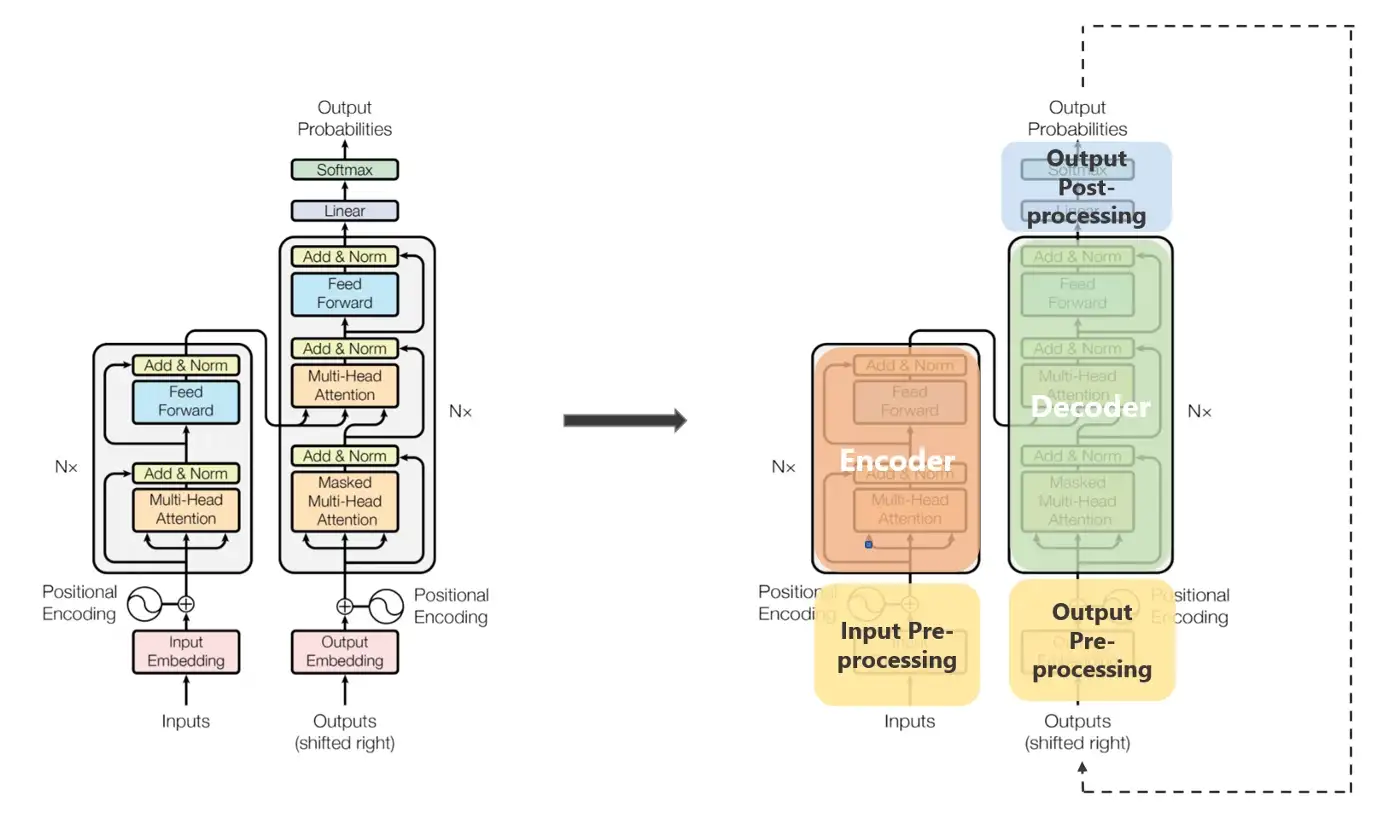
INTRO
: 이번 포스트에서는 EncoderLayer의 내부를 살펴보도록 한다. 정확히 말하자면, Multi Head Attention, PositionwiseFeedForwardLayer 에 대해서 다룰 것이다.
- 이 포스트를 보기 전에 이전 포스트들에 대해서 어느 정도 숙지가 되어있기를 바란다.
- References
- wandb 트랜스포머(Transformer) 심층 분석
- bentrevett/pytorch-seq2seq/attention_is_all_you_need.ipynb
: Seq2Seq부터 트랜스포머 공부할 때, 여기를 많이 참고했다. - 고현웅님의 트랜스포머 구현 깃허브
- Colab Code
: 오늘의 실습코드이다. 실습코드만 보고 Flow를 이해하기 어려울 수 있을 것이다. 순서적으로 보기 난해할 수 있다. 그렇기 때문에, 본문 포스트 순서대로 따라서 보면 이해하는 데 어렵지 않을 것이다.
EncoderLayer - Code
: 여기서의 Flow를 제대로 이해하기 위해서는 Multi Head Attention에서 일어나는 일들을 살펴볼 필요가 잇다. 그렇게 하기 위해서 이번 포스트에서는 Multi Head Attention, PositionwiseFeedForwardLayer 에 대해서 다룬다. 그 전에 기억을 되살리기 위해 간략하게 EncoderLayer 를 작성해보았다. 설명이 필요하다면, 09 About Transformer PART 03 "Encoder and EncoderLayer" 를 참고하길 바란다.
class EncoderLayer(nn.Module):
def __init__(self, hid_dim = 8, pf_dim = 16,n_heads = 2, dropout = .1, device = device):
super().__init__()
self.device = device
self.dropout = nn.Dropout(dropout)
self.self_attn = MultiHeadAttention(hid_dim, n_heads, dropout, device)
self.attn_layer_norm = nn.LayerNorm(hid_dim)
self.ff = PositionwiseFeedForwardLayer(hid_dim, pf_dim, dropout, device)
self.ff_layer_norm = nn.LayerNorm(hid_dim)
def forward(self, src, src_mask):
# src: [bs, sl, hid_dim]
# src는 현재, Encoder에서 Positional Encoding Layer까지 지난 상태
# (1) Multi-Head Attention
_src, _ = self.self_attn(src, src, src, src_mask)
# _src, _ = self.self_attn(query, key, value, mask)
# Multi Head Attention 에서 Query, Key, Value 자리에 동일한 src가 들어간다.
# Layer Normalization after Multi-Head Attention
src = self.attn_layer_norm(self.dropout(_src) + src)
# (2) PositionwiseFeedForwardLayer
_src = self.ff(src)
# Layer Normalization after PositionwiseFeedForwardLayer
src = self.ff_layer_norm(self.dropout(_src) + src)
return src
# src: [bs, sl, hid_dim] (1) Multi-Head Attention
- Why Multi Head Attention?
- 만약 여러 개의 Multi Head Attention을 만들지 않고 진행한다면, 어떤 문제점이 있는 지 생각해보면 어떨까?
- Softmax()를 이용해서 가중치(attention weights)를 만들 때, Multi Head로 나누지 않고 진행한다면, 한 측면에만 초점을 맞출 수 있기 때문이다.
- 만약 여러 개의 헤드가 존재한다면, 여러 측면에 초점을 맞출 수 있다.
- 예시) 헤드1: 주어와 동사 상호 작용 | 헤드2: 인접한 형용사
- 참고: 트랜스포머를 활용한 자연어 처리
- 일부 설명은 코드 주석에서 하고 상세한 설명이 필요한 부분은 따로 설명하도록 하겠다.
- 만약 여러 개의 Multi Head Attention을 만들지 않고 진행한다면, 어떤 문제점이 있는 지 생각해보면 어떨까?
class MultiHeadAttention(nn.Module):
def __init__(self,
hid_dim = 8,
n_heads = 2,
dropout = .1,
device = device,
):
super().__init__()
self.device = device
self.dropout = nn.Dropout(dropout)
self.attn = Attention()
# Multi Head Attention 만들기 위한 곳이다.
# hid_dim이 n_heads로 나누었을 때, 나머지가 0이 되어아야 Multi Head가 만들어질 수 있다.
# 그래서 assert로 다음과 같은 조건을 넣은 것이다.
assert hid_dim % n_heads == 0
self.hid_dim = hid_dim
self.n_heads = n_heads
self.head_dim = hid_dim // n_heads
# 1)
self.linear_dim = (hid_dim, hid_dim)
self.linears = nn.ModuleList([copy.deepcopy(nn.Linear(*self.linear_dim)) for _ in range(4)])
self.fc = nn.Linear(*self.linear_dim)
def forward(self, q, k, v, mask = None):
# 2) q, k, v = src, src, src
# 3) mask = src_mask
bs = q.shape[0]
# 4)
q, k, v = [l(x).view(bs, -1, self.n_heads, self.head_dim).transpose(1, 2) for l, x in zip(self.linears, (q, k, v))]
# 5) Scale Dot Product
x, attn_weights = self.attn(q, k, v, mask = mask)
# x: [bs, n_heads, ql, head_dim]
# attn_weights = [bs, n_heads, ql, kl]
# 6) x Reshape
x = x.transpose(1, 2).contiguous()
x = x.view(bs, -1, self.hid_dim)
# 7)
x = self.fc(x)
return x, attn_weights예시의 출발선
: 05 NLP Basic "Text to Tensor" 에서 들었던 "커피가 맛이 좋네요" 문장을 토크나이징 한 후, 각 토큰을 korbow에 따라서 torch Int로 바꾼 sample1_tensor이다. 이 sample1_tensor으로 오늘 코드의 예시를 계속 들 것이다.
- 05 NLP Basic "Text to Tensor" 꼭 숙지하고 오기

1) nn.ModuleList 활용
: nn.Linear 같은 SubModule을 리스트에 담아두도록 한다. 생각보다 간단하지 않은가? nn.Linear(hid_dim, hid_dim)이 현재 4개가 nn.ModuleList 안에 있다. (사실 3개만 있어도 무관하다.)
linear_dim = (hid_dim, hid_dim)
linears = nn.ModuleList([copy.deepcopy(nn.Linear(*linear_dim)) for _ in range(4)]).to(device) # GPU
fc = nn.Linear(*linear_dim).to(device)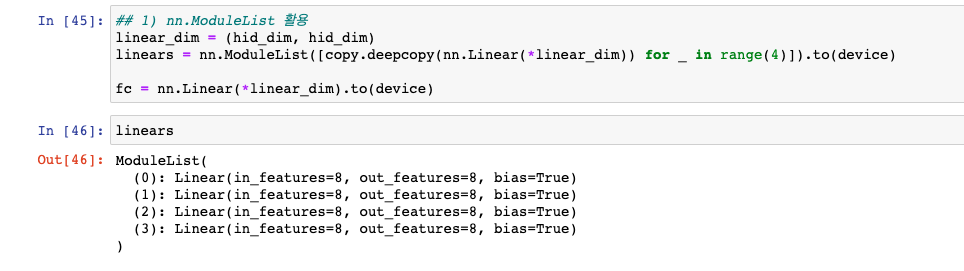
2) q, k, v = src, src, src
: EncoderLayer에서 self.self_attn(query, key, value, mask) 이렇게 들어가야하는데, self.self_attn(src, src, src, src_mask) 이렇게 들어간다고 써있을 것이다. 즉, Query, Key, Value 자리에 동일한 src가 들어가는 것이다. 이는 Self Attention을 통해서 문장내에서의 토큰별 관계를 연산하기 위함이다.
- src : "커피가 맛이 좋네요" 텍스트가 Positional Encoding Layer까지 지나고 나온 값을 의미한다.
q, k, v = src, src, src
mask = src_mask
q.shape, k.shape, v.shape, src.shape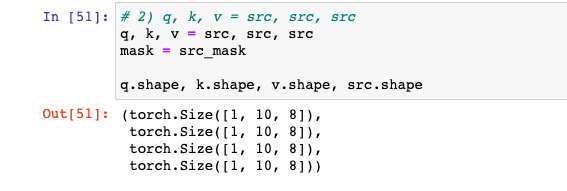
3) mask = src_mask: About 'mask'
: 필자가 Transformer를 공부했을 때, mask는 두 가지 종류가 있었다. pad_mask로 쓰는 경우(Encoder에서)와 pad_mask & sub_mask로 쓰는 경우(Decoder에서) 이렇게 두 가지가 있었다. 하지만, 어느 방법으로 하던 무관하였지만, 두 가지에 대해서 다 소개하겠다. (실습은 pad_mask & sub_mask의 경우로 진행)
-
역할: src에서 <PAD> 토큰이 있는 곳과 없는 곳을 구분하는 역할을 한다. Attention Class에서 Scale Dot Product 이후, Softmax를 통해서 가중치로 만들 때, <PAD> 토큰이 있는 부분을 -1e10(거의 음의 무한대값)으로 바꾸어서 확률값이 0이 나오게끔 한다.
- korbow를 만들 때, <PAD> 토큰은 Int 0으로 주었다.
- 기억이 나지 않는다면, 05 NLP Basic "Text to Tensor" 을 다시 보자.
-
pad_mask: sample1_tensor('커피가 맛이 좋네요' 토크나이징 및 torch Int로 바뀐 형태, Shape: [bs, sl])에서 <PAD> 토큰인 부분은 False로, <PAD> 토큰이 아닌 부분은 True로 놓는다.
## pad_mask
# sample1_tensor: [bs, sl]
pad_mask = (sample1_tensor!=0).unsqueeze(1).unsqueeze(2).to(device)
pad_mask.shape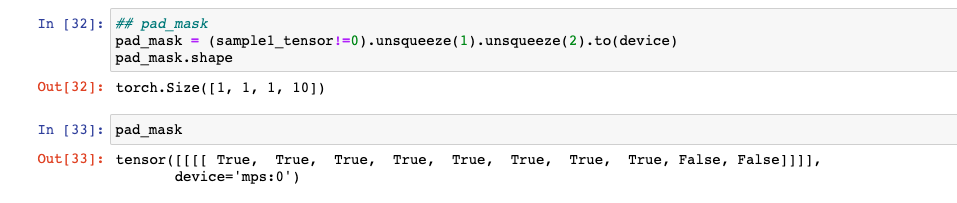
-
pad_mask & sub_mask
: 이 방법은 attention이 다음 토큰을 미리 보지 못 하도록 하는 역할을 한다. (Cheating 방지)- 먼저 sub_mask를 만들어야하는데, 문장 길이만큼의 torch.tril을 이용해 하삼각행렬을 만든다.
# src: [bs, sl, hid_dim] sl = src.shape[1] # 문장 길이(= 한 문장에서의 토큰의 수) sub_mask = torch.tril( torch.ones((sl, sl), device = device) ).bool() sub_mask.shape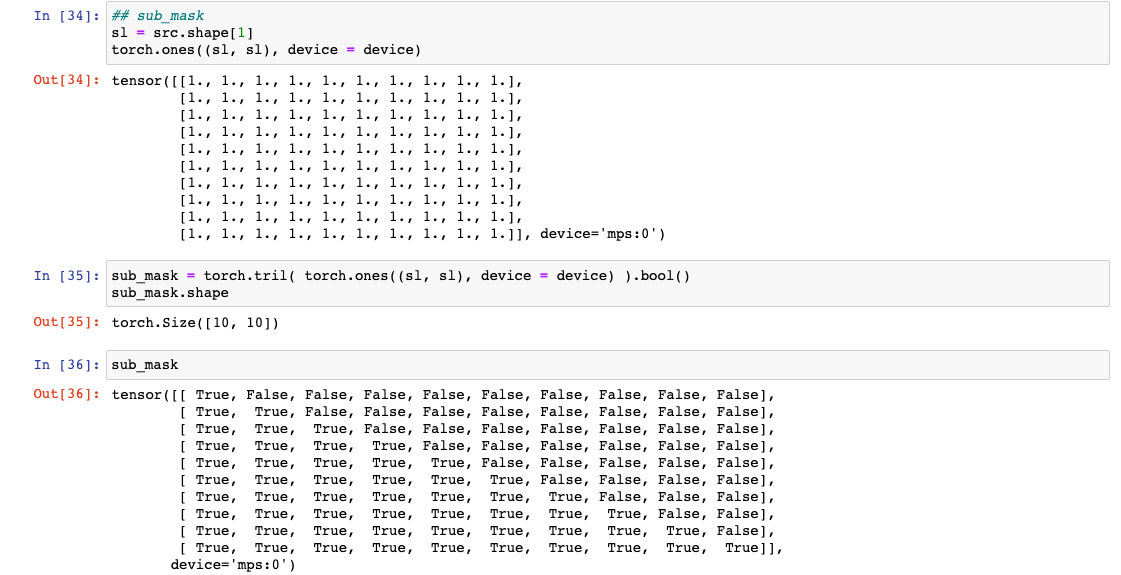
- pad_mask & sub_mask 로 src_mask를 만든다. (여기서는 이 src_mask로 진행)
# src_mask - 여기서는 이 src_mask를 mask로 지정하여 진행한다. src_mask = pad_mask & sub_mask src_mask.shape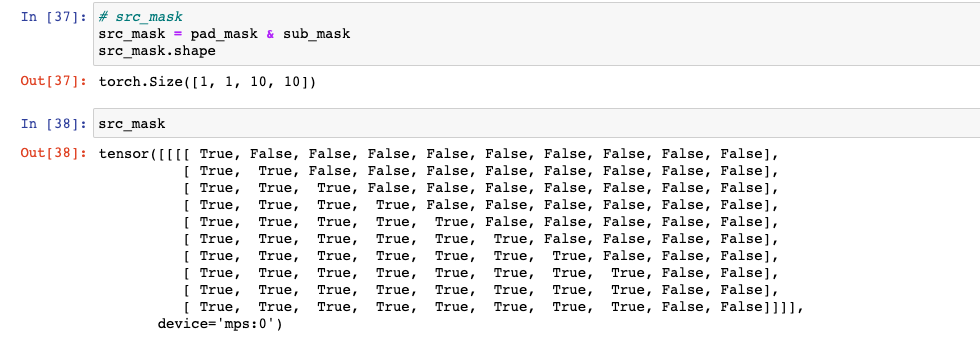
4) q, k, v = [ ... ]
- Multi Head로 나누는 부분이다.
# hid_dim, n_heads = 8, 2
# head_dim = 4
bs = q.shape[0]
q, k, v = [l(x).view(bs, -1, n_heads, head_dim).transpose(1, 2) for l, x in zip(linears, (q, k, v))]
q.shape, k.shape, v.shape, src.shape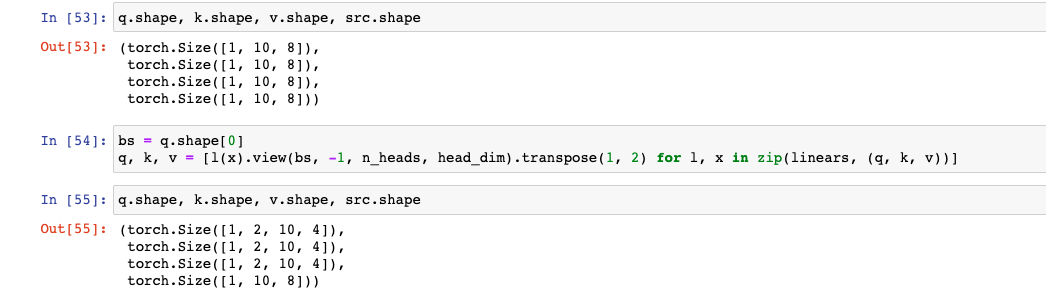
-
위 코드를 풀어서 쓰면 다음과 같다.
: 위 코드는 wandb 트랜스포머(Transformer) 심층 분석에서 가져왔다. 상당히 효율적이지 않은가?bs = q.shape[0] q = nn.Linear(hid_dim, hid_dim)(q) k = nn.Linear(hid_dim, hid_dim)(k) v = nn.Linear(hid_dim, hid_dim)(v) # 여기까지는 위 코드처럼 바꾸었을 때 다음과 같다. # q, k, v = [l(x) for l, x in zip(linears, (q, k, v))] q = q.view(bs, -1, n_heads, head_dim) k = q.view(bs, -1, n_heads, head_dim) v = q.view(bs, -1, n_heads, head_dim) # 여기까지를 위 코드처럼 바꾸었을 때 다음과 같다. # q, k, v = [l(x).view(bs, -1, n_heads, head_dim) for l, x in zip(linears, (q, k, v))] q = q.transpose(1, 2) k = q.transpose(1, 2) v = q.transpose(1, 2) # 여기까지 위 코드처럼 바꾸었을 때 다음과 같다. # q, k, v = [l(x).view(bs, -1, n_heads, head_dim).transpose(1, 2) for l, x in zip(linears, (q, k, v))] q.shape, k.shape, v.shape, src.shape -
transpose
: torch tensor의 Shape을 변형하고 싶을 때 사용한다. Shape을 변형하는 방법으로는 view, reshape 등이 있지만, 지금 하려는 것은 Shape의 순서(?)를 바꾸려는 것이다. (물론 permute도 있다.) 아래 예제에서 보면, [1, 3, 2, 5] Shape의 a라는 텐서가 있는데, a의 Shape을 [2, 3, 1, 5]로 바꾸려고 한다. 이 때 transpose를 사용해서 바꾸려는 Shape의 Index 2개를 넣어주기만 하면 된다. Shape에서 1과 2를 바꾸려고 하기 때문에, 그 Index인 0과 2를 transpose에 넣어서 바꾸어주도록 한다.a = torch.randn(1, 3, 2, 5) print(a.shape) a = a.transpose(0, 2) a.shape
5) Scale Dot Product @ Attention
# 5) Scale Dot Product
x, attn_weights = self.attn(q, k, v, mask = mask)
# q: [bs, n_heads, ql, head_dim] # ql: Query's Sequence Length
# k: [bs, n_heads, kl, head_dim] # kl: Key's Sequence Length
# v: [bs, n_heads, vl, head_dim] # vl: Value's Sequence Length
# mask = src_mask : 실습 Code에 보면 나와있다. (mask와 src_mask는 동일)
# mask (=src_mask) : [bs, 1, 1, sl]이 부분이다. 여기서는 Attention Class로 넘어가게 된다. 넘어가기 전에 위 코드의 주석을 보면서 q, k, v, mask의 Shape을 확인하고 넘어가자.
- 사실 Encoder에서는 ql, kl, vl을 구분할 필요는 딱히 없다. 필자는 공부하기 위해서 구분하였다.
- Decoder에서는 따로 구분짓는 것이 필요하다고 생각한다.
- Attention 코드를 살펴보자.
Attention
: Scale Dot Product Attention을 구하는 과정이다. 수식은 다음과 같다.
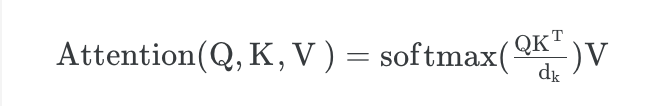
필자는 개인적으로 이 과정을 사람의 사고방식으로 표현하자면, 어법이나 문법적인 규칙이 학습(feat.Back-Prop)되고 완성되는 과정이라고 생각한다.
이제 코드를 살펴보자.
class Attention:
def __init__(self,
device = device,
dropout = .1):
self.device = device
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask = None):
# q: [bs, n_heads, ql, head_dim]
head_dim = q.shape[-1]
# attn_score(attention score)
attn_score = torch.matmul(q, k.transpose(2, 3)) / torch.sqrt(torch.Tensor([head_dim])).to(self.device)
# attn_score: [bs, n_heads, ql, kl]
# masked fill
if mask is not None:
attn_score = attn_score.masked_fill(mask == 0, -1e10)
# attn_weights(attention weights)
attn_weights = torch.softmax(attn_score, dim=-1)
# attn_weights: [bs, n_heads, ql, kl]
# x: Scale Dot Product Attention
x = torch.matmul(self.dropout(attn_weights), v)
# x: [bs, n_heads, ql, head_dim]
return x, attn_weights
def __call__(self, q, k, v, mask = None):
# nn.Module을 상속받지 않았기에 다음과 같이 __call__함수를 만들어준다.
# 그래서 nn.Module을 상속받은 Class에서 forward와 동일한 효과가 나도록 해주기 위함이다.
return self.forward(q, k, v, mask= mask)-
attn_score(attention score) : Query와 Key를 행렬곱을 하여서, 각 토큰별 관계를 Score로 수치화한 것이 attention score이다. Query와 Key가 비슷하면 값이 크게 나오고, 그렇지 않으면 작게 나온다.
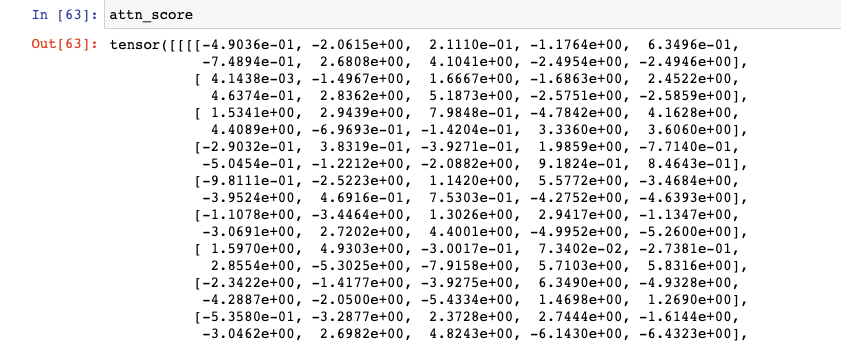
- 예시: “커피가 맛이 좋네요” -> 이 문장에서 "커피” 라는 토큰이 “가”, “맛", "이", "좋", “네요” 라는 토큰들과의 관계(=의미적 유사도)를 계산한다. 의미적으로 같을수록 높은 값이 나오게 되고, 의미적으로 다를 수록 낮은 값이 나오게 된다.# Shape 부터 다시 한 번 확인! # q: [bs, n_heads, ql, head_dim] # ql: Query's Sequence Length # k: [bs, n_heads, kl, head_dim] # kl: Key's Sequence Length # v: [bs, n_heads, vl, head_dim] # vl: Value's Sequence Length # mask (=src_mask) : [bs, 1, 1, sl] head_dim = q.shape[-1] attn_score = torch.matmul(q, k.transpose(2, 3)) / torch.sqrt(torch.Tensor([head_dim])).to(device) # q, k: [bs, n_heads, sl, head_dim] # k.transpose(-2, -1): [bs, n_heads, head_dim, kl] attn_score.shape # [bs, n_heads, ql, kl]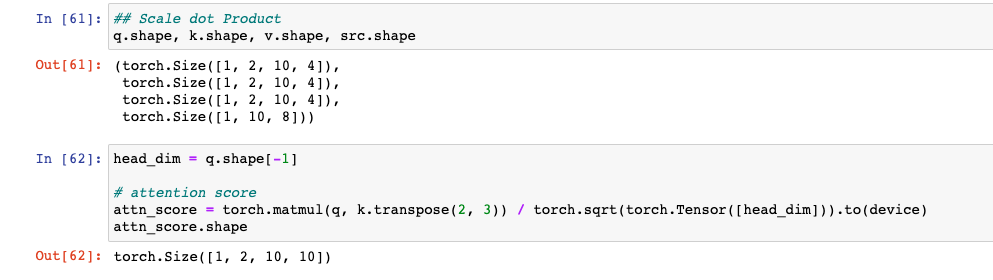
attn_score 꽤 길기 때문에 일부만...
-
masked fill : masked_fill 함수를 이용해서, 마스크에서 특정값만을 바꿔주도록 한다. 여기에서는 0(=False)을 -1e10으로 바꿔줘서 Softmax를 통과할 때 0이 나오도록 한다. (mask는 위에서 설명한대로 pad_mask & sub_mask로 진행. )
# mask는 위에서 선언한 pad_mask & sub_mask로 진행 attn_score = attn_score.masked_fill(mask == 0, -1e10) attn_score.shape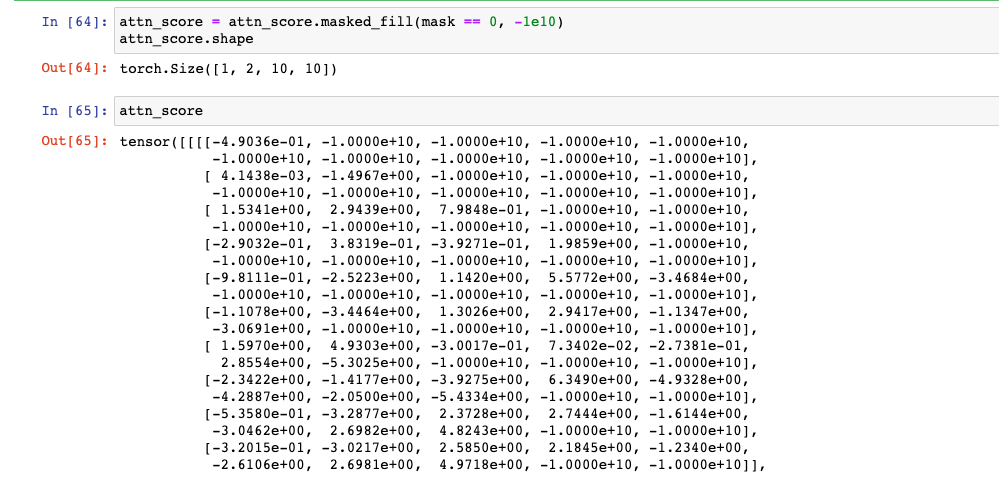
-
여러분의 이해를 돕기 위해, pad_mask로 진행했을 때를 보여주겠다.
# 이번에는 Pad Mask로 했을 때 attn_score_after_padmask = attn_score.masked_fill(pad_mask == 0, -1e10) attn_score_after_padmask.shape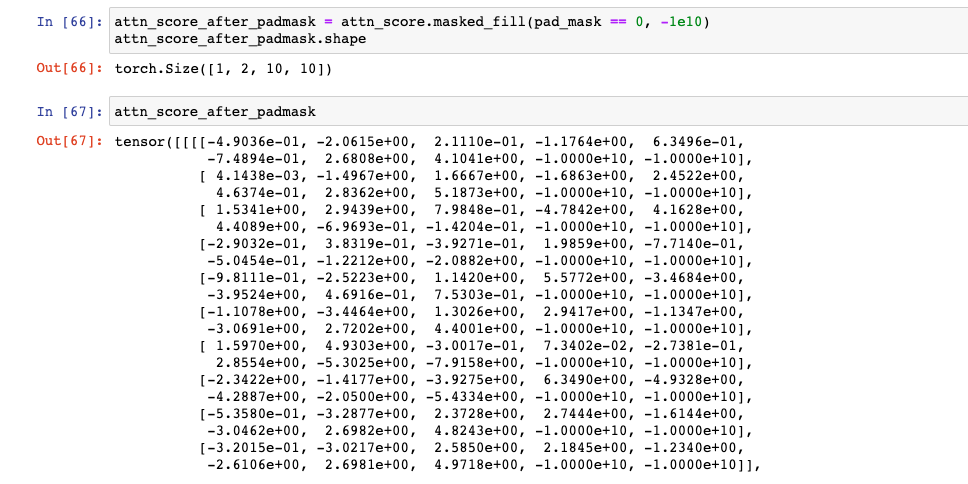
-
pad mask와 pad_mask & sub_mask는 어떤 차이일까?
- 위에서 한 설명을 보면서 다시 한 번 생각해보자.
- 먼저 이걸 기억해보자. 그리고 토큰이 0으로 바뀐다는 점을 기억해내자.

- 위의 두 결과를 잘 살펴보자. 차이점이 잘 보이지 않는다면, 아래 그림을 보자. 좌측은 pad_mask만 적용했을 때, attn_score의 모습이고, 우측은 pad_mask & sub_mask로 적용했을 때, attn_score의 모습을 그림으로 그린 것이다. 아래 그림을 보고 위 결과들을 다시 한 번 보자.

- 이제 차이점이 보일 것이고 어렴풋하게나마 위의 mask에 대한 설명들이 이해가 갈 것이다.
- pad_mask는 kl 기준으로 토큰인 부분만 -1e10으로 바뀌지만, pad_mask & sub_mask에서는 하삼각행렬 모양대로 그리고 pad_mask에서 kl 기준으로 토큰인 부분도 같이 -1e10으로 바뀌게 한다.
- 트랜스포머를 활용한 자연어 처리에서는 torch.tril(torch.ones( ... ) )(즉, 여기에서는 sub_mask)를 mask로 쓰기도 한다.
"어텐션 헤드가 미래 토큰을 엿보지 못 합니다."
-
-
attn_weights(attention weights): 위 attn_score(attention score)를 가중치로 만들어주는 과정이다. Shpae은 attn_score와 동일하다.
# 스샷은 일부만 잘라서 attn_weights = torch.softmax(attn_score, dim=-1) attn_weights # attn_weights: [bs, n_heads, ql, kl]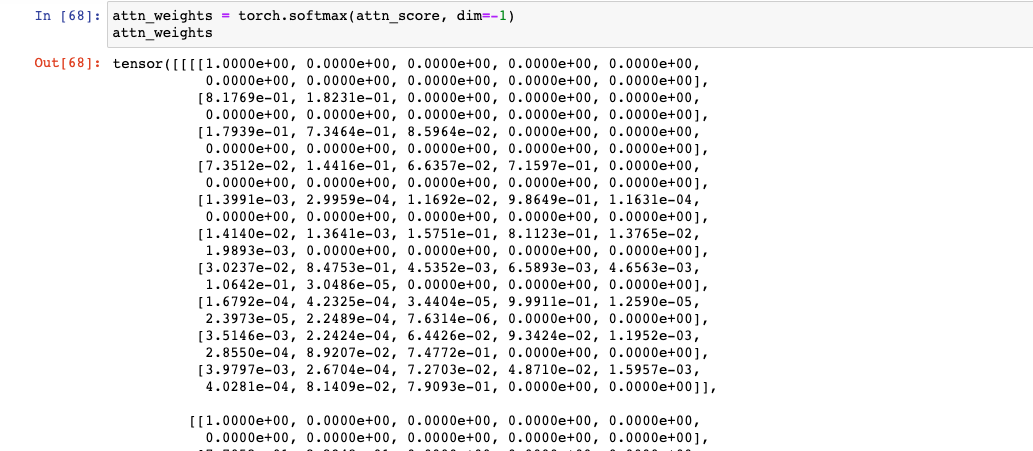
-
x: Scale Dot Product Attention
: Scale Dot Product Attention이 완성되는 과정이다. 이제 위에서 힘들게 구한 attn_weights를 Value와 행렬곱으로 곱해주면 된다. -
x가 (Scale Dot Product) Attention 이라고 할 수 있다.
-
필자는 개념상 혼동을 방지하기 위해 attention output이라고 부른다.
# x: Scale Dot Product Attention Completed x = torch.matmul(nn.Dropout(.1)(attn_score_after_mask), v) x.shape # x: [bs, n_heads, ql, head_dim]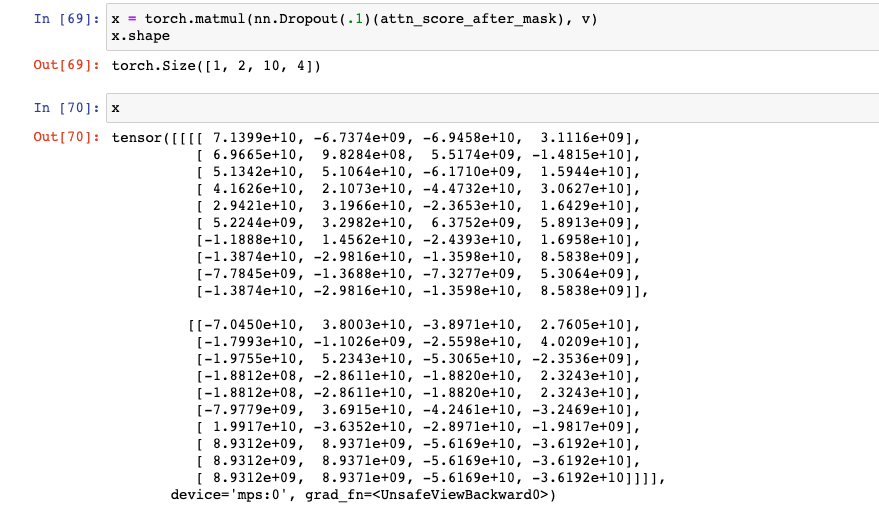
6) x Reshape
: Attention을 이해했으니 이제 Multi Head Attention으로 돌아오자. Attention에서 (힘겹게 구한) x가 되는 것까지 보았다. (attn_weights와 같이 Return) 이제 이 x를 [bs, sl, hid_dim] Shape으로 다시 바꿔주면 된다.
# 6) x Reshape
# x: [bs, n_heads, ql, head_dim]
x = x.transpose(1, 2).contiguous()
x = x.view(bs, -1, self.hid_dim)
# x: [bs, -1, hid_dim]
-
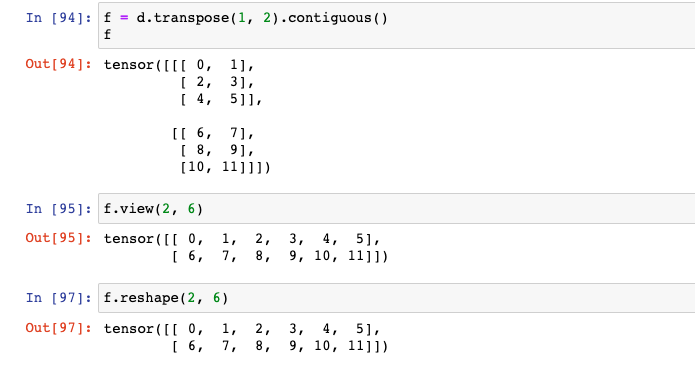
Q: 바로 reshape을 쓰면 안 되나요?
: 원래 의도한 배열대로 돌아오지 않거나 수의 배열이 의도한 바와 다르게 달라질 수 있다. 즉, 의미가 달라질 수 있다는 말이다. 다음 예시를 보자.# 다음 예시를 보자. a = torch.arange(0, 12) b = a.view(2, 6) # b를 [2, 3, 2]3차원으로 만든 뒤, Shape 기준으로 Index 0과 1의 자리를 바꾼 후 # Reshape으로 b와 같은 Shape으로 만들어보자. # 이것을 e라고 했을 때, e와 b를 비교해보자. c = a.view(2, 3, 2) d = c.transpose(1, 2).contiguous() e = d.reshape(2, 6)b를 [2, 3, 2]3차원으로 만든 뒤, Shape 기준으로 Index 0과 1의 자리를 바꾼 후(=d), Reshape으로 b와 같은 Shape으로 만들어보자. 이것을 e라고 했을 때, e와 b를 비교해보자. 배열 자체가 다르다는 것을 볼 수 있다.

# 위 예시의 e와 f를 비교해보자. f = d.transpose(1, 2).contiguous() f하지만, 위와 과정을 역행한다면, 즉, d를 Shape 기준으로 Index 0과 1의 자리를 다시 바꾼 후, [2, 6] Shape으로 view 혹은 reshape을 해보자. 그리고 b와 비교해보자. b와 배열이 같다는 것을 볼 수 있다.
7) self.fc
: 마지막으로 self.fc를 통과시켜주면 된다.
# 7)
# self.fc = nn.Linear(*self.linear_dim)
# = nn.Linear(hid_dim, hid_dim)
x = self.fc(x)
# x: [bs, sl, hid_dim] --> [bs, sl, hid_dim]PositionwiseFeedForwardLayer가 남았다.
(2) PositionwiseFeedForwardLayer
코드만 봤을 때 간단하고 별 거 없어보인다. 각 문장별 임베딩 벡터를 독립적으로 처리한다는 것에 의미가 있다. 그래서 Positionwise-Feed-Forward-Layer 라고 부른다.
class PositionwiseFeedForwardLayer(nn.Module):
def __init__(self,
hid_dim = 8,
pf_dim = 16,
dropout = .1,
device = device,
):
super().__init__()
self.device = device
self.dropout = nn.Dropout(dropout)
self.fc1 = nn.Linear(hid_dim, pf_dim)
# [bs, sl, hid_dim] -> [bs, sl, hid_dim]
self.fc2 = nn.Linear(pf_dim, hid_dim)
# [bs, sl, hid_dim] -> [bs, sl, hid_dim]
def forward(self, x):
# x(=src): [bs, sl, hid_dim]
x = self.fc1(x)
# [bs, sl, hid_dim] -> [bs, sl, hid_dim]
x = self.dropout(torch.relu(x))
# ReLU()와 Dropout()으로 인해 Shape이 바뀌지 않습니다.
# [bs, sl, hid_dim] -> [bs, sl, hid_dim]
x = self.fc2(x)
# [bs, sl, hid_dim] -> [bs, sl, hid_dim]
return x길었을 텐데 읽어주셔서 고맙습니다.
: 다음 포스트는 이전에 06 NLP Basic Classification with GRU(Text Classification Task)를 이제까지 구현한 Transformer Encoder 부분만 직접 구현해서 train 해보려고 한다.
- 다음 포스트는 짧을 예정
- 이후 Decoder 부분까지 구현하여 기계 번역 예제는 현재 고민 중
