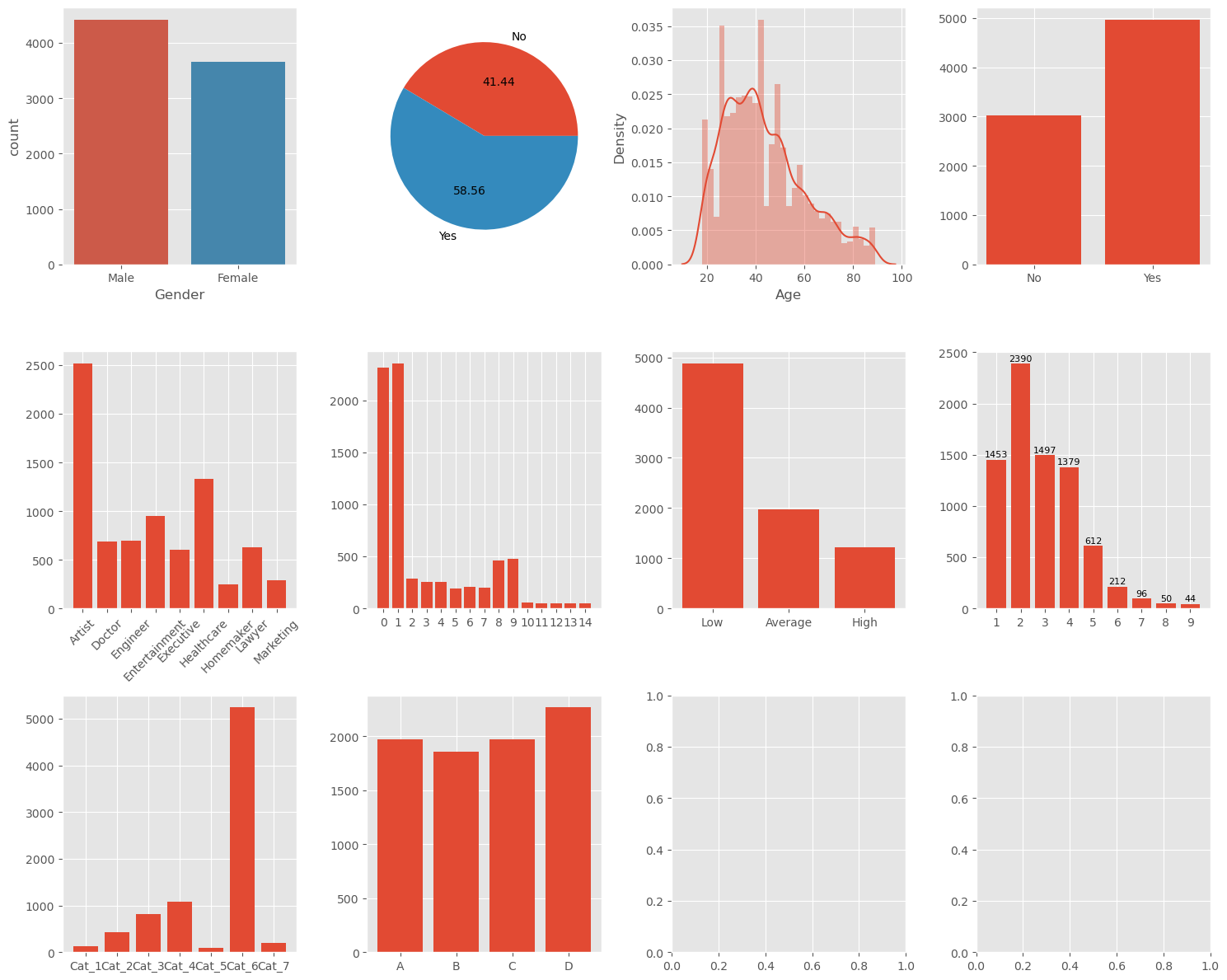
(문제 2-3) Distribution Check를 진행하며
Gender 별 분포
Male과 Female이 존재하는 Gender열에서 각 성별 별 데이터 수를 비교하고 싶었다. 이를 위해 bar plot의 형태로 시각화를 진행했다.
처음에는 내 머릿속에 존재하는 방법으로만 시각화를 진행해보았다.
ax_00 = train_df.groupby('Gender')['ID'].count()
ax[0][0].bar(ax_00.index, ax_00)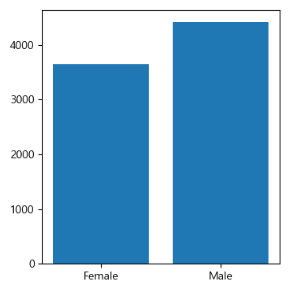
총 10개의 subplot를 그렸는데, 전부 이런 방식으로 코드를 작성하니 굉장히 장황했다. 후에 검색 힌트를 확인해보니 seaborn의 countplot이라는 함수가 있었다. 위 코드를 countplot을 활용하여 다시 작성해보았다.
sns.countplot(x='Gender', data=train_df, ax=ax[0][0])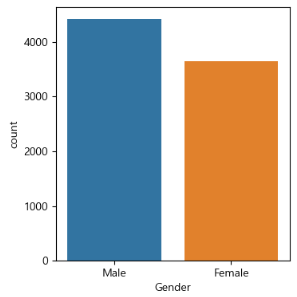
한 줄로 완성이 되었다. Dataframe을 직접 그룹화해서 count하는 과정이 불필요해졌다. 심지어 label까지 알아서 추가해준다. 짱이다.
Ever_Married 별 분포
위의 Gender plot과 비슷한 형태의 데이터이다. Yes와 No 두 개의 value를 갖는다. Gender와 비슷한 방식으로 그릴 수도 있지만 pie chart를 이용해 다르게 구성해보았다. 두 value의 비중을 비교할 때 좋은 듯.
ax_01 = train_df.groupby('Ever_Married')['ID'].count()
ax[0][1].pie(ax_01, labels=ax_01.index, autopct='%.2f')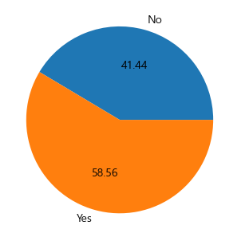
Age 별 분포
Seaborn의 distplot을 이용하였다.
나이 별 사람의 분포를 density로 표현하여 시각화한다.
sns.distplot(train_df['Age'], ax=ax[0][2])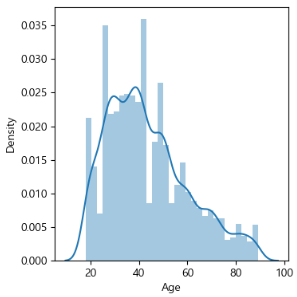
etc.
남은 일곱가지의 그래프는 모두 bar plot의 형태로 시각화하였다. Index 별 크기 비교와 수량 확인까지 하고 싶을 때는 막대 형태의 그래프가 가장 수월해 보인다.
 또한 위와 같이 격자 무늬 배경을 추가하고 싶을 땐
또한 위와 같이 격자 무늬 배경을 추가하고 싶을 땐
plt.style.use('ggplot')
fig, ax = plt.subplots(3,4)이 코드를 subplots 생성하기 전에 추가해준다.
생성 후에 추가해주면 바로 적용되지 않음.
plt.style.use('default')위와 같이 작성하면 원래대로 reset 된다.

성장 중독 | 서버, 데이터, 정보 보안을 공부합니다.