요즘 미세먼지가 너무 심해서 미세먼지 관련 데이터를 분석해보았다.
데이터 출처 : 한국환경공단_도로 재비산먼지 측정 정보_20230228.csv
먼저 데이터 가져오기
dust_df = pd.read_csv('한국환경공단_도로 재비산먼지 측정 정보_20230228.csv', encoding='cp949')1. 지역 별 재비산먼지 평균 농도
dust_mean_df = dust_df.groupby('지역')['재비산먼지평균농도'].mean().sort_values(ascending=False)
plt.bar(dust_mean_df.index, dust_mean_df, color=['pink', 'gray'])
plt.title('2월 간 지역 별 재비산먼지 평균 농도')
plt.xlabel('지역')
plt.ylabel('평균 농도')
for i in range(len(dust_mean_df)) :
plt.text(dust_mean_df.index[i], dust_mean_df[i] + 4, '%.2f' % (dust_mean_df[i]),
fontsize=7,
horizontalalignment='center',
verticalalignment='center')
plt.show()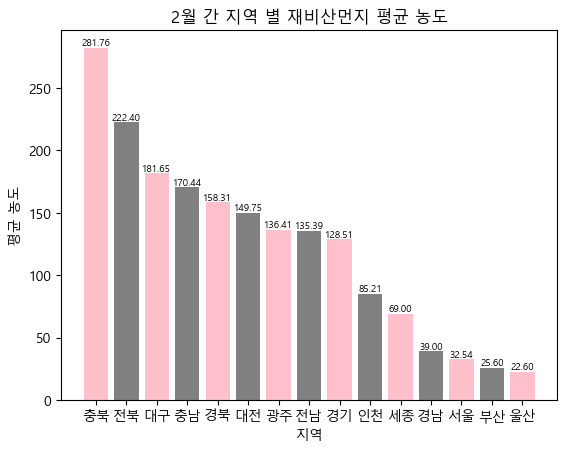
서울, 경기가 가장 높을 것이라 예상했는데 충북이 가장 높다는 결과가 도출되었다. 하지만 모든 지역을 매일 조사하지 않았다는 점 등이 큰 변수로 작용되었다고 생각된다. 일례로 세종은 2월에 세 번 조사함.
2. 날짜 별 평균 먼지 농도
dust_date_df = dust_df.groupby('측정일자')['재비산먼지평균농도'].mean()
dust_date_df.index = pd.to_datetime(dust_date_df.index)
filled_date_df = dust_date_df.resample("D").asfreq().fillna(0).sort_values(ascending=False)
filled_date_df.index = filled_date_df.index.strftime("%Y-%m-%d")
plt.bar(filled_date_df.index, filled_date_df)
plt.title('2월 날짜 별 평균 미세먼지 농도')
plt.xlabel('날짜')
plt.ylabel('평균 농도')
plt.xticks(filled_date_df.index, rotation=90)
no_date_idx = filled_date_df[filled_date_df.values==0].index
for i in range(len(no_date_idx)) :
plt.text(no_date_idx[i], 15, '미\n측\n정',
fontsize=7,
horizontalalignment='center',
verticalalignment='center')
plt.show()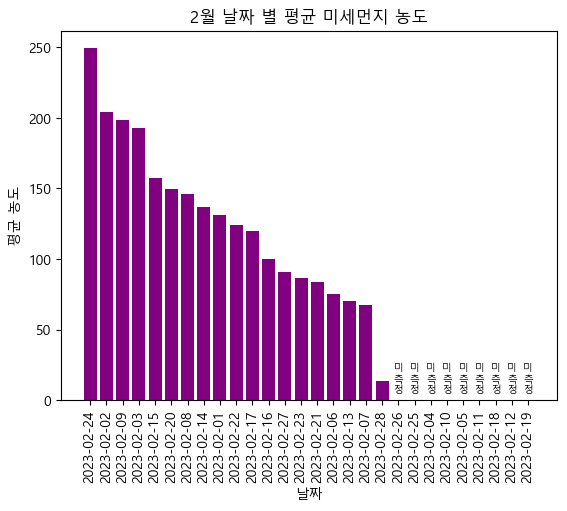
측정된 날짜 중 2월 24일이 평균 재비산먼지 농도가 가장 높음을 확인할 수 있다.
해당 실습으로 알게 된 것
날짜 리샘플링
2023-02-01 130.875000
2023-02-02 204.500000
2023-02-03 193.147059
2023-02-06 75.141026
2023-02-07 67.697248
2023-02-08 145.898305
2023-02-09 198.521739
2023-02-13 70.282051
2023-02-14 137.044776
2023-02-15 157.043478
2023-02-16 100.081967
2023-02-17 119.705882
2023-02-20 149.280000
2023-02-21 83.976190
2023-02-22 124.115385
2023-02-23 86.479167
2023-02-24 249.388889
2023-02-27 91.076923
2023-02-28 13.545455중간중간 없는 날짜를 삽입하고 싶었다.
dust_date_df.index = pd.to_datetime(dust_date_df.index)
filled_date_df = dust_date_df.resample("D").asfreq().fillna(0)위 코드를 통해 해결할 수 있었다.
2023-02-01 130.875000
2023-02-02 204.500000
2023-02-03 193.147059
2023-02-04 0.000000
2023-02-05 0.000000
2023-02-06 75.141026
2023-02-07 67.697248
2023-02-08 145.898305
2023-02-09 198.521739
2023-02-10 0.000000
2023-02-11 0.000000
2023-02-12 0.000000
2023-02-13 70.282051
2023-02-14 137.044776
2023-02-15 157.043478
2023-02-16 100.081967
2023-02-17 119.705882
2023-02-18 0.000000
2023-02-19 0.000000
2023-02-20 149.280000
2023-02-21 83.976190
2023-02-22 124.115385
2023-02-23 86.479167
2023-02-24 249.388889
2023-02-25 0.000000
2023-02-26 0.000000
2023-02-27 91.076923
2023-02-28 13.545455날짜 index는 시각화할 때 자동 정렬된다는 사실
다른 방식으로 정렬하고 싶다면 string으로 타입을 변경하자.
filled_date_df.index = filled_date_df.index.strftime("%Y-%m-%d")
성장 중독 | 서버, 데이터, 정보 보안을 공부합니다.