Abstract
BERT라는 언어 모델을 설명한다
BERT라는 모델은 양방향 context를 조건화하여 label이 지정되지 않은 텍스트에서 deep bidrectional representation을 사전 훈련하도록 설계된 모델이다.
Introduction
언어 모델의 사전훈련은 NLP 작업을 개선하는데 효과적이였다.
(이전 부터 많이 연구가 되었던 분야라는 의미이며, 다양한 작업에서 필수적이였다.)
Downstream 작업에서 훈련된 언어 표현을 적용하기 크게 두가지가 있었다.
-
feature-based approach (ex: ELMo)
사전훈련 된 표현을 추가적인 feature로 활용해 task-specific 아키텍처를 사용한다. -
fine-tuning approch (ex: GPT)
GPT는 최소한의 task-specific 한 parameter의 수를 최소한으로 하고, 사전 훈련된 parameter를 fine-tuning하여 downstream 작업에 대해 훈련된다. -
두 접근 방식의 공통점
-> 사전 훈련 중에 동일한 목적 함수를 공유한다. 이때 unidirectional 한 언어 모델을 사 용한다.
논문에서 말하고자 하는 것
-> 기존의 방법들이 사전훈련된 표현을 제약하지만 그 중 fine-tuning이 사전훈련된 표현의 성능의 제한이 심하다.
-> 논문은 왜 그렇게 생각하는가?
1. 표준 언어 모델이 unidirectional 하다.
2. 단방향 언어 모델의 경우 모든 토큰이 이전 토큰하고만 attention을 계산하여, 문장 수준의 작업에서는 sub-optimal 하며, 양방향 context의 통합이 중요한 작업에서는 성능이 매우 떨어진다.
(sub-optimal하다고 한 이유, 양방향을 사용하는것이 optimal하기 때문)
-> 논문은 이를 해결하기 위해 BERT를 제안
BERT라는 양방향 인코더 표현법을 제안 MLM을 사전학습 목적으로 사용하여 단방향의 제약을 완화
MLM은 입력에서 토큰의 일부를 무작위로 masking하며, 목표는 masking된 단어의 원래 어휘를 예측하는 것이다.
--> MLM의 목표는 표현이 왼쪽과 오른족의 context를 융합할 수 있게해 deep bidirectional transformer를 사전 훈련 할 수 있게 해준다.
덧붙여서 MLM에서 텍스트 쌍 표현을 사전훈련 하면 다음 문장 예측 task도 적용할 수 있다.
- 논문에서 하고자 하는 말
1: 양방향 사전훈련의 중요성을 보여준다
- 사전 훈련된 표현이 많은 고도로 엔지니어링된 작업의 특정 아키텍처 필요성을 줄인다.
Related Work
language representation을 사전훈련하는 역사와 가장 널리 사용되는 접근 방식에 대해 이야기 한다.
Unsupervised Feature-based Approaches
사전 훈련된 단어 임베딩은 현대 NLP 시스템의 필수적인 부분으로 처음 부터 학습하는 임베딩에 비해 상당한 개선을 제공한다.
word embedding -> sentence embedding, paragraph embedding 으로 세분화
sentence embedding을 훈련시키기 위한 학습은 다음과 같다.
1. 다음 문장의 순위를 매기는 방법
2. 이전 문장의 표현이 주어진 다음 문장의 왼쪽에서 오른쪽으로 생성
(left to right generation)
3. denoising auto encoder에서 파생된 방법
등을 사용하였다.
ELMo와 그 후속 모델들은 다른 차원을 따라 전통적인 word embedding 연구에서 발전 시켰다.
left-to-right와 right-to-left 언어 모델을 통해 context sensitive feature를 추출 하였다.
이렇게 생성된 token 별 contextual representation은 left-to-right와 right-to-left concat 하는 것이다.
이렇게 concat 한것 만으로 ELMo는 주요한 NLP 벤치마크들에서 SOTA를 달성하였다.
하지만 ELMo는 feature-based 일뿐, deeply bidrectional 하지는 않다.
Unsupervised Fine-tuning Approaches
기존의 연구 방향은 Feature based approch와 똑같이 unlabeld text로 부터 word embedding parameter를 pretraining 하는 방향으로 진행 되었다.
더 최근에는 contextual token representation을 만들어내는 encoder가 unlabeled text 에서 사전훈련되고, supervised downstream task에 맞게 fine-tuning 된다.
-> 장점 : 처음부터 배울 필요가 있는 parameter가 거의 없다.(학습하는데 적은 parameter로 충분)
--> GPT는 이러한 장점으로 다양한 문장 단위 task에서 SOTA를 달성
Transfer Learning from Supervised Data
대규모 데이터 셋이 있는 supervised 작업에서 효과적으로 transfer 하는 연구도 있다.
-> cv 영역에서는 pretrain model을 fine-tuning 하는 방법인 대규모 모델의 transfer learning의 중요성을 입증
BERT
논문에서는 pretrain 과 fine-tuning 두가지 단계로 나누어서 설명한다.
pretrain part : pretraining task의 unlabeld data를 사용해 초기 parameter를 초기화 한다.
fine-tuning : downstream task에서 labeled data를 사용해 fine-tuning을 진행
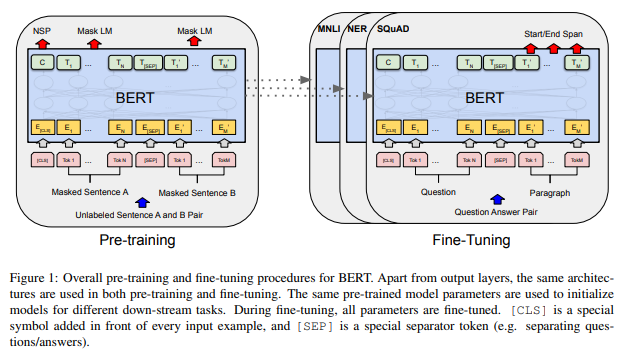
위의 그림을 보게 되면 pre-training 단게에서 초기화된 parameter가 MNLI, NERm, SQuAD 등의 작업에서 동일한 parameter로 전달 되는 것을 확인 할 수 있다.
-
Model architecture
BERT model architecture는 multi layer bidrectional Transformer encoder이다.
: transformer block (layer)의 개수
: hidden size
: multi head attention 개수 -
BERT base의 경우
, , , -
BERT large의 경우
, , ,
BERT base는 GPT와 비교를 위해 동일한 parameter로 만들어 진행하였다.
BERT : bidirectional self-attention
GPT : constrained self-attention
- Input/Output Representation
BERT가 다양한 downstream 작업을 해결하기 위해 필요한것
-> 단일 문장과 한 쌍의 문장을 모두 하나의 token sequence로 표현
(sequence : 연속된 텍스트의 임의 범위 - 우리가 생각하는 문장일 필요 X)
논문 30000개의 token 어휘를 가진 Wordpiece 임베딩을 사용
-> 모든 token의 첫번째 token은 항상 분류 token(CLS)이다.
문장을 구별하는 방법
-> (CLS) token과 대응되는 최종 hidden state는 분류 문제를 해결하기 위해 sequence representation을 종합
-> 문장 A에 속하는지 문장 B에 속하는지 모든 토큰에 학습된 embedding을 추가
-> 주어진 token의 경우, 입력 표현은 해당 token, segment 및 위치 embedding을 합산하여 구성
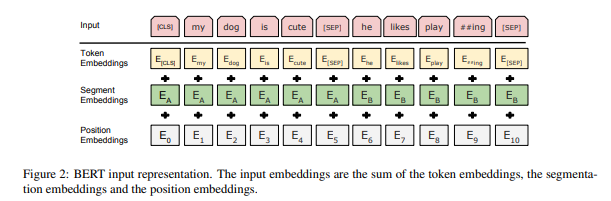
Pre-training BERT
BERT는 사전 훈련을 하기위해 전통적인 단방향 model을 사용하지 않는다.
- Task #1: Masked LM
직관적으로 양방향 모델 > 단방향 모델
-> 하지만 표준 조건 언어모델은 단방향으로 학습 가능
BERT는 양방향 표현을 학습하기 위하여, input token의 일부 비율을 무작위로 maskinig한다음 해당 masking 된 token을 예측한다. -> MLM 작업
이를 하고 난 뒤 mask token에 해당하는 최종 hidden vector는 표준 LM과 같이 어휘를 통해 출력 softmax로 공급된다.
이러한 과정으로 양방향 사전 훈련 모델을 얻는다
단점
1. fine-tuning 중에 [MASK] token이 나타나지 않아 pre training과 fine-tuning간의 불일치가 발생
--> [MASK]token이 fine-tuning 과정에서는 나타나지 않는 문제 발생
--> 이를 해결하기 위하여 항상 MASKED 단어를 실제 [MASK] token으로 교체X
훈련 data 생성기는 예측을 위해 token 위치 중 15%를 무작위로 선택
아래는 그 15%의 token에 대하여 추가적인 처리를 말한다.
- 80%의 경우 token을 [MASK] token으로 바군다.
- 10%의 경우 token을 random word로 바꾼다.
- 10%의 경우 token을 원래 단어 그대로 둔다.
- Task #2: Next Sentence Prediction(NSP)
QA 및 NLI와 같은 많은 중요한 downstream 작업은 언어 모델링에 의해 직접 캡처되지 않는 두 문장 사이의 관계를 이해하는것을 기반으로 한다.
-> 논문에서는 문장 관계를 이해하는 모델 훈련을 위해 pre train을 실시한다.
ex) 각 사전 교육 예에 대해 문장 A와 B를 선택할때 50%는 A 다음에 오는 실제 문장인 B이고, 50%는 말뭉치의 무작위 문장 B를 고른다.
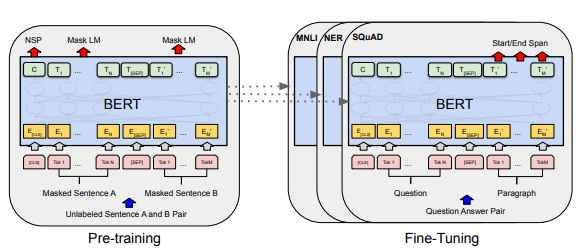
그림에서 볼수 있듯이, C는 NSP를 위한 token이며, BERT는 이 C를 이용하여 input인 두 문장이 원래 corpus에서 이어 붙여져 있던 문장인지 아닌지를 학습한다.
- Pre-training data
사전 훈련 corpus의 경우 bookscorpus와 영어 위키피디아를 사용
위키피디아의 경우 텍스트만 추출하고, 목록 및 표는 사용 X
Fine-tuning BERT
Trasformer의 self-attention 매커니즘 덕에 downstream task modeling은 간단하다.
각 작업에 대해 작업별 input, output을 BERT에 연결하고 모든 parameter를 fine-tuning한다.
1. sentence pairs in paraphrasing
2. hypothesis-premise pairs in entailment
3. question-passage pairs in question answering
4. degenerate text-∅ pair in text classification or sequence tagging
Output도 downstream에 따라 달라지며, CLS표현은 entailment나 sentiment analysis와 같은 분류를 위한 출력 layer를 추가한다.
fine-tuning 과정은 pretrain 과정보다 훈련 시간이 훨씬 적게 소모된다.
Experiment
GLUE
GLUE를 fine-tuning 하기 위해 input sequence를 표현하고 첫번째 입력(CLS)에 해당하는 최종 hidden vector C 를 집계표현으로 사용
fine-tuning 중 도입 되는 유일한 새로운 매개 변수는 classification layer weights 이며, K는 label 수이다.
C와 W 를 이용하여 표준 분류 손실()을 계산한다.
실험 parameter
batch size : 32
각 작업에 대한 Dev set에서 최고의 fine-tuning 학습률(5e-5, 4e-5, 3e-5 및 2e-5)
BERT large 모델의 경우 작은 데이터셋에서 불안정 -> 여러번 재시작 하고 Dev set에서 최고의 모델을 선택.
무작위 재시작의 경우 사전 훈련된 동일한 체크포인트를 사용하지만 서로 다른 fine-tuning data shuffle과 layer initialization을 한다.
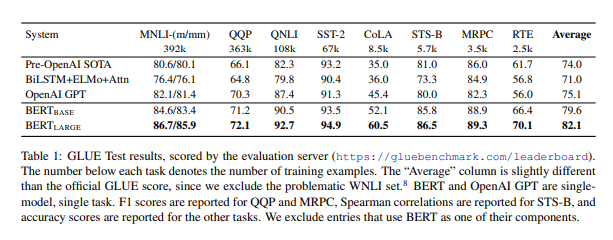
결과로 알 수 있는점
- 모든 작업에서 모든 시스템을 상당한 차이로 능가
- BERT LARGE가 훈련 데이터가 매우 적은 작업에서 BERT BASE를 능가하는걸 발견
SQuAD v1.1
Stanford QA dataset으로 100K crowdsourced qa의 모음이다.
QA 작업에서는 입력된 질문과 구절을 단일 sequence로 나타내고, 질문은 A embedding을 사용하고 지문은 B embedding을 사용
fine-tuning 동안 start vector 와 end vector E \in R^H만 소개한다.
단어 i가 답변 범위의 시작이 될 확률은 Ti와 S 사이의 dot product로 계산되고 단락 사이의 모든 단어에 softmax가 뒤따른다.
유사한 공식은 답변 범위의 끝에 사용된다. 위치 i에서 위치 j 까지의 후보 범위의 score는 로 정의되며, 가 예측으로 사용되는 최대 score 범위이다.
훈련 목표는 시작 위치와 종료 위치의 log likelyhood의 합이며, 학습률은 5e-5와 batch size는 32로 3epoch를 실험하였다.
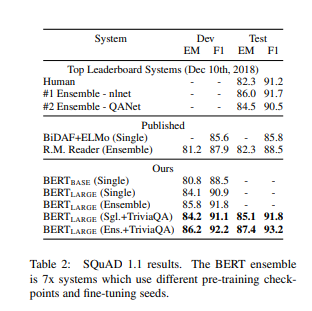
최고 성능 모델은 기존의 모든 시스템을 큰 차이로 능가하였다.
SQuAD v2.0
1.1에서 사용한 BERT 모델을 확장하기 위해 간단한 접근 바식을 사용
답변이 없는 질문은 CLS 토큰에 시작과 끝이 있는 답변 범위를 가진 것으로 취급한다.
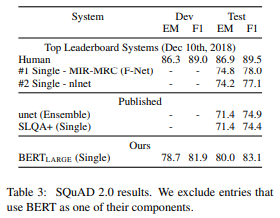
학습률은 5e-5를 사용하고 batch 크기는 48에 2epoch를 이용하여 fine-tuning을 진행
SWAG
SWAG 데이터 셋에는 근거 있는 상식 추론을 평가하는 113K 문장 사 완료 예가 포함 되어 있다.
과제는 4가지 선택 중 가장 설득력 있는 연속을 선택하는 것이다.
fine-tuning을 할때 주어진 문장 A와 가능한 연속 문장 B의 연결을 포함하는 4개의 input sequence를 구성한다. 유일한 작업별 매개변수는 CLS 토큰 표현 C가 있는 dot product가 softmax layer로 정규화된 각 선택에 대한 점수를 나타낸다.
학습률 2e-5 와 batchsize는 16, 3 epoch로 모델을 fine-tuning을 진행하였다.
Ablation Studies
Effect of Pre-training Tasks
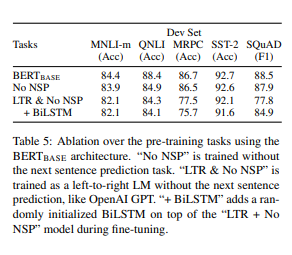
BERTBASE와 정확히 동일한 train data, fine-tuning 및 hyper parameter를 사용하여 두가지 pretrain 목표를 평가하여 BERT의 deep bidirectionalty의 중요성을 입증
NSP: MLM을 사용하여 훈련 되지만 NSP 작업은 없는 양방향 모델
LTR&No NSP : MLM이 아닌 표준 LTR LM을 사용하여 훈련되는 좌선 전용 모델(GPT와 유사)
NSP 작업이 가져올 영향을 보면 다음과 같다. NLP를 제거하면 QNLI, MNLI, SQuAD1.1에서 성능이 크게 저하, 반면 LTR 모델은 모든 작업에서 MLM model 보다 성능이 낮다.
token의 hidden state에는 Right context가 없어, SQuAD의 경우 LTR 보다 token 예측이 저조한 성능을 보인다.
-> 이를 개선하기 위해 BiLSTM을 썼지만 SQuAD는 개선되고, GLUE 작업에서 성능이 감소 그리고 사전훈련된 양방향 모델에 미치지 못함
LTR 및 RTL 모델을 훈련하고 ELMo 처럼 두 모델을 연결하는 것 같이 각 토큰을 나타내면 다음과 같은 문제가 있다
1. 단일 양방향 모델보다 비용이 두배로 든다.
2. RTL 모델은 질문에 대한 답을 조건화할 수 없어 QA 작업에 부적합
3. 모든 계층에서 왼쪽 및 오른쪽 context를 모두 사용 할 수 있어 deep bidirectional model 보다 덜 강하다.
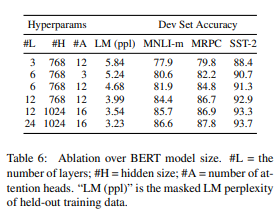
Effect of Model Size
- 모델 크기가 커질 수록 성능이 좋아지는걸 확인 가능
- 모델이 충분히 pre train 된 경우 극단적으로 모델 크기를 확장하면 매우 작은 규모의 작업도 개선
Feature-based Approach with BERT
pretrain model에서 고정된 특징을 추출하는 기능 기반 접근법에는 특정 이점이 있다.
1. 모든 작업을 transformer encoder 아키텍처로 표현 할 수 있는것 X
-> 작업별 model 아키텍처가 추가 되어야한다.
2. 훈련 데이터의 값비싼 표현을 한번 계산한 다음 이 표현 위에 더 저렴한 모델로 많은 실험을 실행할 수 있는 주요 계산 이점이 있다.
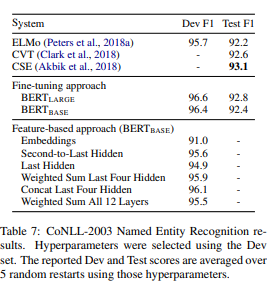
NER 작업에서 BERT를 적용하여 두 접근 방식을 비교하면 다음 과 같다.
-> 이는 BERT가 finetuning 및 기능 기반 접근 방식 모두에 효과적임을 보여준다.
Conclusion
비지도 사전 훈련이 많은 언어 이해 시스템의 필수적인 부분이라는 걸 보여준다.
-> 낮은 자원의 작업도 deep bidirectional 아키텍처의 이점을 받게 한다.
본 논문은 이를 일반화 하여 사전훈련 모델이 광범위한 NLP 작업을 성공적으로 수행되게끔한다
