논문 링크
논문 코드
ACL 2023에서 공개가 된 논문입니다.
Abstract
기존의 언어 모델의 문제
softmax로 토큰을 예측하여 희귀 token이나 phrases 는 예측하기 어려움
-> 본 논문은 이를 nonparametric distribution로 대체하여 만든 NPM을 제안
어떠한 점이 좋아졌는가?
1. 전체 말뭉치 검색에 대한 대조적인 목표와 배치 내 근사치를 효율적으로 훈련
2. 16개의 NLP 작업에 대해 실시한 제로샷 평가는 훨씬 더 큰 parameter를 가진 모델을 능가하였다.
3. 희귀한 토큰에 대하여 처리하고 예측하는 부분에서 두각을 보였다.
Introduction
기존의 LLM 모델의 문제점
1. 광범위한 사용과 좋은 성능이 있지만 비용이 많이 들며, 업데이트가 어려움
2. long-tail 지식과 패턴으로 어려움
-> 이를 해결하기 위하여 검색 및 생성 접근 방식을 따른다.
--> 문제점은 유한한 어휘에 softmax를 사용하여, 희귀 토큰에 취약하다.
이러한 이유로 NPM을 본 논문에서 제안한 것이다
NPM은 텍스트를 고정 크기 벡터에 매핑하는 인코더와 NPM이 구문 검색을 하고 MASK를 채우는 참조 코퍼스로 구성
(encoder와 참조 corpus로 구성)
-> 이러한 이유로 softmax를 사용하는 것이 아닌 Nonparameter distribution을 가진다.
--> 최근 연구 방향인 parametric model + nonparameteric compononts를 하는 것과는 대조적
NPM을 훈련하는데 있어서 어떠한 문제점이 있었고 어떻게 해결하였는가?
문제점
1. 훈련 중 전체 corpus 검색은 비용이 많이 든다.
2. decoder 없이 임의의 구문을 예측하는 학습은 사소한것이 아니다.
해결법
1. 전체 corpus 검색에 대한 일괄 근사를 사용하여 첫번째 문제 해결
2. span masking과 phrase-lebel contrastive objective를 확장하여 해결
(혹시나 해서 span의 의미
한 개 이상의 단어로 이뤄진 명사구가 될 수 있는 단어들의 집합)
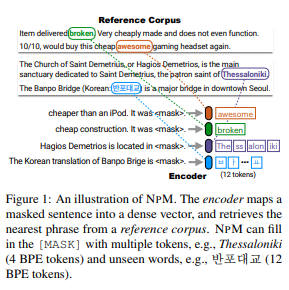
평가 방식
16 tasks including classification, fact probing and question answering 에 대해서 zero shot 평가를 진행하였다.
결과 NPM은 500배 더 큰 모델과 37배 더 큰 모델을 능가하여 더 parameter 효율적임을 보여준다.
특히 희귀 단어 예측, 명확한 단어 의미에 유용, 번역 작업에 대해 NPM이 극히 드문 문자로 구성된 단어를 예측함을 보여주었다.
- Introduction 요약
-
corpus를 통해 nonparameter distribution에서만 [MASK]를 채우는 NPM 모델을 소개
-
unlabeled data에 대해 NPM을 훈련 시키는 계획을 소개
->softmax를 제거하고 n-gram을 예측하여 제한 없는 출력 공간을 가능하게 함 -
downstream 작업 16개에 대하여 더 큰 모델들 보다 성능이 뛰어나고, 희귀 패턴에 대해서도 우수하였다.
-
Related Work
- Language models
방대한 양의 텍스트에 대해 훈련된 대규모 LM은 작업을 cloze 형식으로 변환하여 제로샷 방식으로 광범위한 downstream 작업을 수행
-> 다양한 지식이 모델의 매개 변수에 인코딩 되어 가능
-> 최근에는 매개변수를 추가하여 매개변수 LM을 확장
--> 하지만 이러한 방식으로 인해 예측하는데 어려움 및 시간이 지남에 따라 업데이트 불가능
최근에는 nonparameteric component와 통합하는 작업이 있었다.
- 검색된 텍스트를 입력에 연결하고 표준 LM 목표로 훈련시키는 작업
- 출력으로 보간 되는 확률 분포를 추정하기 위해 대규모 텍스트 말뭉치에서 토큰을 검색하는 작업
-> 논문의 방식은 첫번째 것과 같으며, 구문에 대한 분포를 모델링 하거나 희귀하거나 보이지 않는 단얼르 예측하는 것과 같은 다양한 기능을 제공
-
Bottleneck in softmax
많은 언어모델에서 유한 어휘에 대한 범주형 확률 분포를 softmax로 사용한다.
-> 모델의 표현력이 떨어지는 문제가 있다. 고정된 출력 어휘가 언어 모델의 새로운 도메인과 작업에 대한 적응에 적항적으로 만든다.
--> nonparameteric output space를 사용할 것을 제안 이는 어휘가 클 때 더 효율적으로 만들 수 있다. -
Nonparametric models
NPM에서 데이터 분포는 고정된 parameter 집합이 아니라, 사용가능한 데이터의 함수이다.
데이터가 증가함에 따라 복잡성이 증가
Nonparameter라는 용어가 매개변수가 없다는것 의미 X
-> 유효 매개변수의 수와 특성이 유연하고 데이터에 따라 달라질 수 있다는것
최근 연구 방향
-> 훈련 없이 Nonparameter 추론을 탐구, 특정 downstream 작업을 위해 지정된 데이터에 대한 비모수 모델을 훈련
--> 본 논문에서는 unlabeled 데이터로 완전한 Nonparameter language model을 훈련시키고 다양한 task를 제로샷으로 수행
Method
NPM은 encoder와 참조 corpus로 구성되어 참조 corpus에 대한 Nonparameter distribution을 모델링
핵심 아이디어
encoder를 사용하여 corpus의 모든 구문을 조밀한 벡터 공간에 매핑하고, 추론시 [MASK]가 있는 쿼리가 주어지면 encoder를 사용하여 corpus에서 가장 가까운 구문을 찾고, [MASK]를 채우는 것
NPM: inference
Overview
encoder는 참조 corpus C의 모든 고유 구문을 조밀한 벡터 공간에 매핑
test 시 encoder는 마스킹된 query를 동일한 벡터 공간에 매핑하고 C에서 구문 검색을 하여 [MASK]를 채운다.
(C)는 train corpus와 같을 필요가 없으며, encoder를 다시 훈련 하지 않고 test 시간에 교체하거나, 크기 조정이 가능하다.
corpus에는 상당한 수의 phrase가 있으며, 이를 색인화 하는데 많은 비용이든다.
-> 논문에서는 구문의 시작과 끝을 토큰으로 표현
이 접근 방식에는 각 고유 토큰의 표현을 C로 인덱싱한 다음 test 시간에 구문의 시작과 끝에 가장 가까운 이웃 검색을 개별적으로 사용
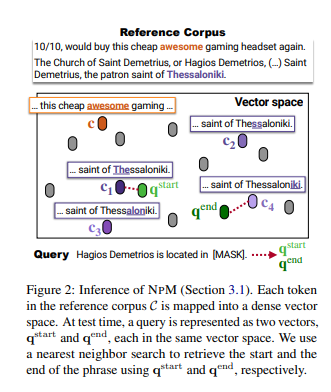
와 라는 두 개의 벡터를 가진 query로 나타낸 다음 각각을 사용하여 타당한 문구의 시작과 끝을 검색
Method
형식적으로 = 을 N개의 토큰을 참조한 참조 말뭉치라고 하면, 텍스트를 encoder에 입력하여 각 토큰 를 문맥화 된 h차원 벡터 ∈에 매핑하고 각 토큰에 해당하는 벡터를 취한다.
추론 시에는 NPM에 각 t번째 토큰이 masking 된 query가 제공된다.
[MASK]를 두개의 특수 토큰 ,로 대체 를 encoder에 입력하여 h차원 벡터 목록을 얻는다.
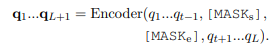
그런 다음 및 에 해당하는 벡터를 각각 및 로 가져옵니다.
그런 다음 아래를 통해 추론을 한다.
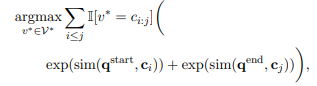
은 정의된 가능한 N-gram 집합
V와 sim은 벡터 쌍을 스칼라 값으로 매핑하는 사전에 정의된 유사성 함수
실제로 N개의 토큰을 반복하는 것은 불가능하기에 시작과 끝을 개별적으로 가장 가까운 이웃검색을 사용하여 근사치를 구한다.
유사성 함수
여기서 h는 token 벡터의 차원이다.
NPM: Training
NPM은 unlabeled textdata로 학습한다.
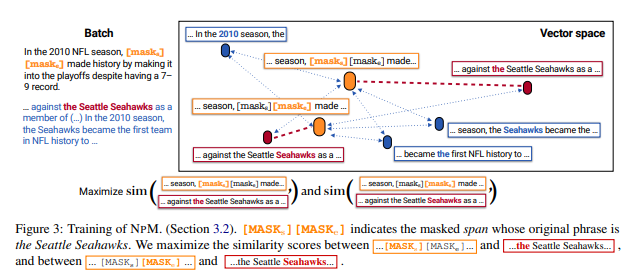
Masking
논문에서는 기하학적 분포에서 길이가 샘플링 되는 span을 masking 하는 span masking을 확장한다.
논문에서 사용하는 span masking과 기존의 span masking은 다르다.
1. 훈련 중 배치 양성을 보장하기 위해 배치의 다른 sequence에서 span이 동시에 발생하는 경우 span을 masking 한다.

ex) figure 4에서 masking된 범위 는 2010, Seattle Seahawks와 to the이며, 이것들은 다른 sequence에서 발견된다.
2. span의 각 token을 [MASK]로 대체하는 대신에 전체 span을 두개의 특수 토큰 [MASK]로 교체한다.
ex) 2010, Seattle Seahawks와 to the는 [MASKe]로 대체 된다.
이것은 추론에서 시작과 끝 벡터를 얻기 위한 것이다.
Training Objective
-
Key idea
Masking 된 점위는 Seattle Seahwaks이므로 모델은 test 시간에 이와 같은 query가 제공될때 참조 corpus의 다른 sequence에서 seattle seahawks를 검색해야 한다.
특히 [Masks] 벡터가 the Seattle Seahawks 에 가깝게 해야한다. 그리고 [MASKe] 벡터가 Seattle Seahawks token들은 다른 token들과 거리를 멀리 한다.
전체 corpus를 배치의 다른 sequence로 근사하여, 모델이 훈련하도록 한다.
논문에서 사용한 Masking 전략은 모든 Masking span이 배치에서 동시 발생 span을 갖도록 보장한다. -
Obtaining vector representations
L token으로 구성된 i 번째 sequence를 고려한다. 논문에서는 은 를 통한 span masking의 결과이다.
는 모두 인코더에 입력되고, 각 토큰은 h차원으로 매핑된다. -
Training objective
[MASKs]와 [MASKe]로 표현된 안의 masking 된 span을 고려한다
그럼 다음 를 로 표현된 n-gram으로 나타낸다.
masking된 span의 training objective는 아래와 같다.
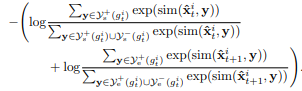
위의 수식에서 sim은 유사도를 측정하는 함수이다.
그리고
,,,
는 다음과 같은 순서를 가진다.
start positives, start negatives, end positives and end negatives of
이 object는 구문 수준의 이전 대조학습 목표를 다중 positive를 허용하려는 확장을 따른다.
- In-batch positives and negatives
start positive와 end positive는 시작과 끝이고, start negative와 end negative는 각각 시작과 끝의 negative가 아니라 토큰이다.
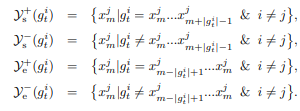
여기서 는 span 의 길이를 나타낸다.
Training Details
Training data
총 13B개의 token이 포함된 영어 위키백과와 CC-News의 영어 부분을 사용
데이터는 최대 256개의 toekn을 가진 sequence로 분할
Training
354M parameter로 구성된 RoBERTa Large의 모델 아키텍처와 초기 가중치를 사용
32GB GPU 32개를 사용하여 100000 Steps로 훈련을 진행
한 배치는 512개의 sequence로 구성되었으며, learning rate는 로 구성 되었다. 4000 step의 Adam optimizer를 사용
Batch
동일한 문서의 sequence를 그룹화 하고 동일한 배치에 할당하여 배치를 구성
긍정이 context를 공유할 가능성이 높아 거짓 긍정을 줄이고
부정은 모델이 혼동할 가능성이 높은 것이므로 모델에 대한 훈련이 긍정을 더 잘 식별하도록 도움을 준다.
훈련 중에 효과적인 배치 크기를 늘리고, 배치 내 근사치를 효과적으로 만들기 위해 여러 GPU에서 모든 sequence를 수집한다.
Experiments: Closed-set Tasks
작은 후보 집합이 제공되는 closed set tasks에 대해 제로샷 평가를 수행
Evaluation datasets
AGN 뉴스, 야후, Subj, SST2, MR, Rotten Tomato, CR, Amazon 등 9개의 분류 데이터 셋을 포함한다. task 범위는 주제 분류, 감정 분석 및 주관석 분류 등등 다양하다.
Baselines
encoder 전용 모델 : RoBERTa
decoder 전용 모델 : GPT2/3
encoder-decoder 모델 : T5
를 이용하여 평가한다.
decoder 전용 모델의 경우 PMI를 추가로 적용하며 KNN 추론을 사용하는 모델과 비교를 한다. GPT2 KNN은 훈련 없이 KNN 추론을 사용하며 GPT-2 KNN-LM은 GPT2와 GP2 KNN의 분포를 보간한다.
Setup
논문은 도메인별 참조 corpus를 사용하며, 각 데이터셋 마다 주관성 corpus, 감정 분류 데이터셋을 위한 corpus 등이 15M부터 126M 토큰까지 다양하다.
빠른 유사도 검색을 위하여 HNSW index와 FAISS를 사용하여 수행한다.
Result
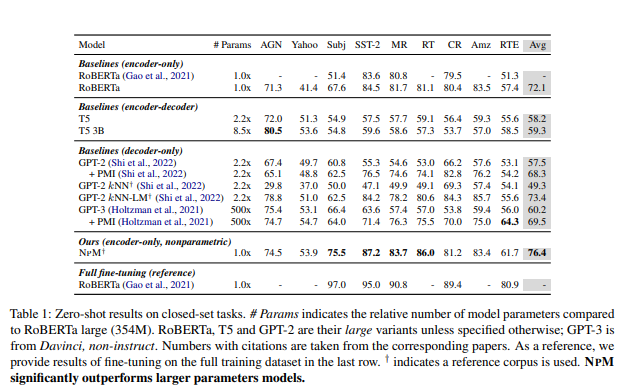
NPM은 제로샷에서 baseline을 능가한다.
-
Comparison between baselines
RoBERTa는 GPT-3를 능가하는 최고 성능을 달성하였다.
-> encoder 전용 모델의 양방향성이 중요한 역할을 하였을거라 추정
Nonparameter component를 parametric model에 통합하는 KNN-LM 접근법은 다른 모든 baseline을 능가한다.
하지만 KNN에만 의존하는 것은 GPT-2 보다 성능이 낮다. -
Baselines versus NPM
NPM은 모든 baseline을 크게 능가하며 모든 데이터셋에서 일관된 경쟁력 있는 성능을 달성 하였다.
-> 외부 지식이 명시적으로 필요하지 않아도 NPM이 경쟁력 있음을 보여줌
-Qualitative anlysis

figure5를 보면 첫번째 예제는 cheap 을 사용하여 inexpensive를 보여주고 두번째 예제는 낮은 품질을 보여준다.
RoBERTa는 두 가지 모두에 대해 긍정적인 예측을 하지만, NPM은 입력과 동일한 context에서 저렴한것을 사용하는 context를 검색하여 정확한 예측을 한다.
NPM 표현이 더 나은 단어 감각 모호성으로 이어지는 것을 발견
-> RoBERTa는 cheap한 것과 poor quality 사이에 높은 유사도를 할당한다.
반면 NPM은 표면 형태가 동일함에도 둘 사이에 낮은 유사도를 성공적으로 달성한다.
Experiments: Open-set Tasks
임의 길이 문자열일 수 있는 개방형 task에 대한 제로샷 평가가 포함된다.
Evaluation Datasets
LAMA의 T-RE와 Google-RE, KAMEL, NQ, TQA, TempLAMA 및 entity 작업의 7개의 데이터셋에 대해 평가를 진행
entity 변환 작업은 영어에서 다른 라틴어가 아닌 언어로 변환하는 작업을 포함, 모델이 매우 희귀한 문자를 예측해야한다.
Baselines
T5 모델(encoder-decoder model), GPT-3(decoder model),OPT(decoder model)을 비교한다.
-> 예측할 토큰수가 불분명하여 encoder model 적용 X
이전 연구에서 검색 및 생성 방식이 지식 의존작업에서 도움을 준다는걸 발견 -> BM25의 최대 5개 passages를 사용하여 baseline에 추가하였다.
Setup
모든 데이터 셋에 대해 정확한 일치(EM)를 보고한다.
LAMA 테스트 데이터는 BERT에 기반한 단일 token인 답변만 포함하도록 필터링 되어 빈번한 entity로 편향 된다.
-> 논문은 편향되는걸 원하지 않는다.
1,2,3,4+ grams 데이터에 대한 micro 평균 정확도를 보고한다.
다른 데이터 셋에는 이러한 필터링이 없어 평균 EM으로 보고한다 참조 corpus에서는 810 token으로 구성된 영어 위키 백과 데이터셋을 사용
NPM의 경우 밀도가 높은 검색과 희소 검색이 상호 보완적인 기능을 캡쳐하여 ->희소 검색과 결합하는 것이 도움
--> BM25기반으로 검색 공간을 상위 3개 통로로 줄이고 밀도 높은 검색을 수행
Result
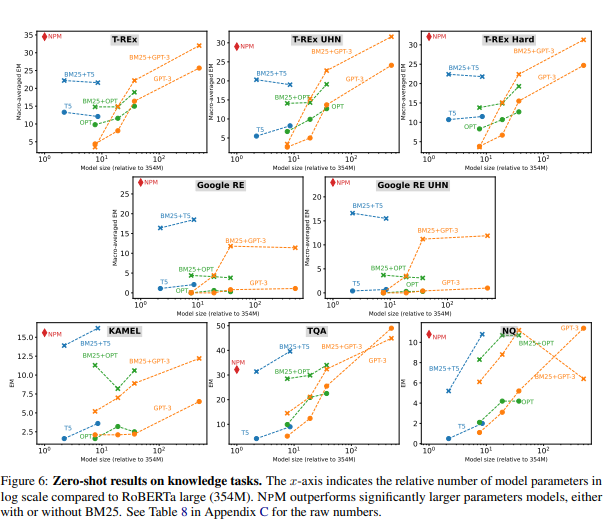
1. parametric model의 성능은 이전 연구에서 보았듯이 parameter 수에 크게 좌우된다.
parameteric model과 BM25를 결합한 검색 및 생성 접근 방식은 성능을 크게 향상시킨다.
NPM은 모든 데이터에서 baseline을 능가하거나, 비슷하다.
BM25가 유무와 관계없이 GPT-3를 비롯한 모델들을 두개의 LAMA데이터셋에서 모든 모델을 크게 능가한다.
희소 검색이 NPM에서도 중요하다. 희소 검색이 없으면 LAMA TREx의 성능이 34.5 -> 16.1로 감소
1. 희소 검색과 빈번한 검색이 보완적인 기능을 함을 포착
2. 검색에서 근사치를 제거하면 검색 품질이 향상된다.
-
Impact of the reference corpus size
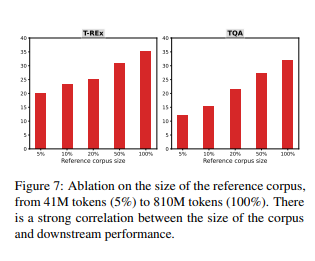
4100만 token에서 8억 1000만 token까지 참조 corpus의 크기를 보고한다. -> NPM의 성능은 참조 corpus와 높은 상관관계가 있으며 큰 corpus를 사용하는것이 중요함을 보여준다. -
Results on temporal knowledge tasks
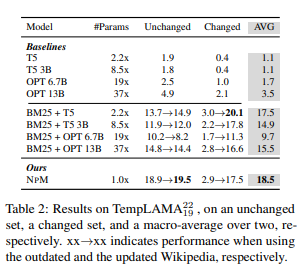
Table2는 TempLAMA에 대한 결과이다.
NPM은 변경되지 않은 셋에서 성능을 유지하고 변경된 셋에서 answers를 성공적으로 업데이트 한다.
모델의 성능은 최대 13B parameter를 가진 parameteric model의 성능보다 훨씬 우수하며 업데이트 된 corpus를 활용하여 답변을 성공적으로 update하는 검색 및 생성 접근 방식의 더 큰 모델과 동등하다.
-> NonParameteric component를 가진 model이 test 시간에 기준 corpus를 대체하여 시간적 업데이트에 적응한다는 것을 보여주는 이전 연구와 일치
--> 하지만 검색 및 생성 접근 방식은 entity가 드물때 NPM 보다 성능이 나쁘다. -
Performance on rare entities
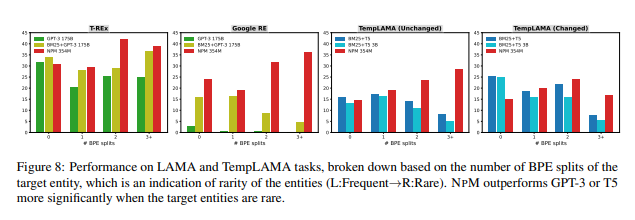
entity의 BPE 분할 수를 기반으로 LAMA와 TempLAMA의 인스턴스를 분류한다.
BPE는 단어가 드문 경우 단어를 분할하므로 BPE 분할 수는 entity의 희귀성을 나타낸다.
GPT3, BM25+GPT3, BM25+T5와 비교한다.
LAMA에서 NPM은 GPT3보다 일관적으로 성능이 우수 BPE 분할 수가 증가함에 따라 더 큰 이득을 얻는다.
TempLAMA. BM25+T5는 BPE분할이 0인 빈번한 entity에 대해 경쟁력이 있지만 1보다 큰 BPE 분할로 NPM에 지속적으로 뒤쳐진다.
-> 검색 및 생성 접근 방식에 비해 NPM이 희귀 entity를 잘 처리함을 알 수 있다. -
Results in Entity Translation
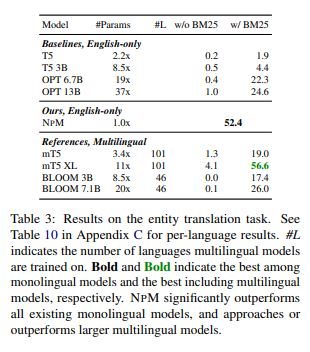
T5 및 OPT는 작업을 수행하는데 어려움이 있지만 NPM은 모든 언어에서 우수한 성능을 보여준다.
NPM은 성능을 더 잘 보정하기 위해 다국어 데이터에 대해 의도적으로 훈련된 모델의 참조 성능을 제공한다.
-> NPM은 영어 교육을 받았음에도 훨씬 더 큰 모델에 접근한다. NPM이 훈련 중 정확한 단어를 못봐도, 주변 상황을 기반으로 구문 검색을 할 수 있다.
Conclusion
출력 어휘에 대한 softmax가 아닌 Nonparameteric distribution을 사용한 NPM 모델을 제시
Limitation
- Scaling through the inference corpus
- Significant memory usage
- Exploration of larger vocabulary
- Extension for generation
- Extension to few-shot learning and fine-tuning
- Better cross-lingual transfer
- Limitation in speed
