논문 링크
Retrieval 관련 논문에서 나오는 DPR에 관련된 논문
Abstract
Open-domain qa에서 후보 context를 선택하기 위해 효율적인 passage retrieval에 의존하며, TF-IDF 또는 BM25와 같은 전통적인 sparse vector space model이 사실상의 방법이였다.
-> 논문에서는
간단한 dual encoder framework를 이용하여 적은 수의 question과 passage에서 embedding을 학습하는 dense한 표현만을 사용하여 retrieval을 실질적으로 구현할 수 있음을 보여준다.
--> 정확도 측면에서 LuceneBM25를 9~19%를 능가하며, 광범위한 OpenQA dataset에서 SOTA성능을 달성하는데 도움이 된다.
Introduction
Open-domain QA는 많은 large collection of documents를 사용하여서 질문에 답변을 하는 task입니다.
초기에는 복잡했지만 현재는 발전하여 두가지 frame work로 발전하였다.
1. context retriever는 먼저 질문에 대한 passage의 small subset을 선택
2. machine reader는 검색된 context를 철저히 검색하고 정답을 식별한다.
-> machine reading은 open-domain QA를 줄이는 합리적인 전략이지만, 성능저하가 보인다.
Open domain QA의 retrieval는 일반적으로 TF-IDF, BM25(휴리스틱한 방법들)를 사용하여 구현 되며, 이는 keyword를 inverted index로 효율적으로 매칭하고 질문과 context를 고차원 sparse vector로 표현하는 것으로 볼 수 있다.
반대로 dense하고 latent semantic encoding은 설계에 의한 희소 표현과 보완 적이다.
sparse한 경우 -> 동일 단어가 매칭 되면 잘 맞추지만 단어가 다를 경우 어려움
dense한 경우 -> 동일 단어가 아니더라도 비슷한 단어에 대해 더 잘 일치하고 올바른 context를 가져온다.
dense encoding은 embedding 기능을 조정함으로써 학습을 할 수 있으며, 작업별 표현을 가질 수 있도록 추가적인 유연성을 제공한다. special in-memory 내 data구조 및 index schemes를 사용하면 MIPS 알고리즘을 사용하여 효율적인 수행이 가능하다.
-> dense vector representation을 학습하려면 많은 Question and context pair가 필요하다
--> dense한 retrieval method는 추가 pre train을 위해 mask sentence를 포함하는 block을 예측하는 정교한 sophisticated inverse cloze task를 제안하는 ORQA 이전의 open domain QA에 대한 TF-IDF/BM25를 능가하는 것으로 나타낸 적은 없다
-> Question encdoer와 reader model은 Question과 answer 쌍을 공동으로 사용하여 fine-tuning된다.
ORQA는 dense retrieval이 BM25를 능가할 수 있음을 보여주며, SOTA를 설정할 수 있지만 약점이 존재한다.
- ICT pretraining은 계산 집약적이며, objective function은 question의 좋은 대체물이라는 것이 명확하지 않다.
- context encdoer가 Question and answer 쌍을 사용하여 fine-tuning 되지 않기 때문에 대응하는 표현은 차선일 수 있다.
-> 논문에서 하고자 하는 것
추가적인 train 없이 question과 answer만을 사용하여 더 나은 dense한 embedding model을 훈련할 수 있는가라는 질문을 다룬다.
BERT Pretrain model과 Dual encoder 아키텍처를 활용하여 상대적으로 적은 question-passage 쌍을 사용하여 올바른 train 계획을 개발하는데 중점을 둔다
--> 그 결과 일괄적으로 비교하는 목적으로 Question과 관련 passage vector의 inner product를 최대화 하도록 최적화 되었다.
--> 그 결과 DPR은 BM25를 큰폭으로 능가하였다.
논문의 contribution
- 적절한 train 설정을 통하여 기존 question-passage pair에서 question과 passage encoder를 fine-tuning 하는 것만으로 bm25를 크게 능가함을 보여줌
- Open domain Question-answer의 context에서 더 높은 retrieval 정밀도가 실제로 더 높은 end-to-end QA 정확도로 변환되는지 확인
-> 이를 통하여 Open-retrieval setting의 여러 QA data set에서 여러 복잡한 시스템과 비교할 수 있거나 더 나은 결과를 얻을 수 있다.
Background
open domain QA의 예시
-> 8대 달라이 라마는 누군가요? 같은 사실적 질문을 large corpus를 사용하여 답변
답변이 하나 이상의 span에 나타나는 범위로 제한되는 추출형 QA설정을 가정한다. (하나이상의 span에서 나타난다.)
각 문서를 기본 검색단위와 동일한 길이의 text passages로 나누고 corpus에서 M개의 총 passages를 얻는다.
각 passage 는 token 의 sequence로 볼 수 있다.
질문 q가 주어지면 passage 중에서 하나의 span을 찾는다. 다양한 domain을 포함하기에 corpus의 크기는 중 하나에서 의 span을 찾아야 한다.
매우 다양한 doamin을 포함하기 위해 corpus 크기는 수백만개의 document에서 수십 억(웹)에 이르기 까지 확장 가능
결과적으로 open domain QA system은 reader를 적용하여 답을 추출하기 전까지 효율적인 retriever를 포함해야 한다.
retriever 는 질문 q와 corpus C를 input으로 받아들이고 더 작은 text 의 필터 세트를 소환하는 함수이며, 이다.
고정된 k의 경우 retriever 가 질문에 답하는 범위에 포함하는 질문의 상위 비율인 top k 검색 정확도에서 분리되어 평가할 수 있다.
Dense Passage Retriever(DPR)
Open domain QA에서 retrieval component를 개선하는데 초점을 맞춘다.
M개의 Passage가 주어지면 DPR의 목표는 런타임에 reader에 대한 입력 질문과 관련된 top k개의 passage를 효율적으로 검색할 수 있도록 저차원 및 연속 공간에서 모든 passage를 색인화 하는것
M은 매우 클수 있으며 k는 20~100과 같이 작다.
Overview
DPR은 임의의 Passages를 추가적인 float vector에 매핑하고 retriever에 사용할 모든 M개의 passage의 index를 구축하는 Dense encoder(EP)를 사용한다.
DPR은 런타임에 입력된 질문을 d차원의 벡터에 매핑하는 다른 encoder(EQ)를 적용하고, question vector에 가장 가까운 vector k개의 passage를 검색한다. question 과 vector dot product를 사용하여 passage 사이의 similarity를 정의한다.
cross atention의 여러 layer로 구성된 network와 같이 question과 passage 사이의 similarity를 측정하기 위한 model 형태가 존재하지만, similarity function은 분해 가능한 passage collection ㅍ현이 사전 계산될 수 있다.
가장 분해 가능한 similarity는 유클리드거리(L2)의 일부변환이다.
inner product search은 cosine similarity 및 L2거리와의 연결 뿐만 아니라 연구 되어 왔다. 따라서 더 간단한 inner product함수를 선택하고 더 나은 encoder를 학습하여 조밀한 passage retriever를 개선한다.
Encoder
원칙적으로 Question 및 passage encoder는 모든 신경망에 의해 구현될 수 있지만, 이 작업에서는 두개의 독립 BERT network를 사용하고 [CLS] token에서의 표현을 출력으로 사용하므로 d=768이다.
Inference
Inference timne 동안, passage encoder EP를 모든 passage에 적용하고 오프라인에서 FAISS를 사용하여 색인화 한다.
런타임에 질문 q가 주어지면 embedding vq = EQ(q)를 도출하고 vq에 가장 가까운 embedding으로 상위 k개의 passage를 검색한다.
Training
dot-product similarity가 검색을 위한 좋은 ranking function가 되도록 encoder를 훈련하는 것이 metric train문제이다. 목표는 더 나은 embedding 기능을 학습하여 관련 question 및 passage 쌍이 관련 없는 것보다 smaller distance를 가지도록 vector space를 만드는 것이다.
은 m개의 instance로 이루어진 train data이다.
각 instance는 하나의 질문 qi와 하나의 관련 passage p+1를 포함하며, 관련 irrelevant passage는 무관하지 않다.
positive passage의 negative log likelihood로 loss function을 최적화 한다.
Positive and negative passages
retrieval problems의 경우 종종 긍정적인 예시를 명시적으로 사용하는 반면 매우 큰 pool에서 부정적인 예를 선택해야하는 경우가 있다.
예를 들어 Question과 관련된 passage는 QA dataset에서 제공되거나 답변을 사용하여 찾을 수 있다.
collection의 다른 모든 지문은 명시적으로 지정되지 않았지만, 기본적으로 무관한 것으로 볼 수 있다.
실제로 negative example을 선택하는 방법은 간과되지만, 고품질의 encoder를 학습하는데 결정적일 수 있다.
논문에서는 3가지 다른 유형의 negative example를 고려한다.
1. Random : Corpus로 부터의 임의의 passage
2. BM25 : 답을 포함하지 않지만 대부분의 Question token과 일치하는 BM25에 의해 반환 되는 top passage
3. Gold : positive passage는 Train set에 나타나는 다른 Question과 pair를 이루어야 한다.
논문은 다른 유형의 negative passage와 train schemes의 영향에 대해 논의할 것이다. 최상의 모델은 동일한 mini batch의 Gold passage와 하나의 BM25 부정적인 passage를 사용한다.
특히 동일 batch의 Gold passage를 negative로 재사용하면 계산을 효율적으로 하는 동시에 우수한 성능을 달성할 수 있다.
In-batch negatives
mini-batch에 B개의 question이 있고, 각 question과 관련있는 passage가 있다고 가정할때 Q와 P를 B크기의 batch에 포함된 Q와 P의 (Bxd)행렬이 있다고 하면
는 similarity score(B x B)행렬이며, 각 행은 질문에 해당하여 B절과 pair를 이룬다.
이러한 방식으로 계산을 재사용하고 각 batch에서 question/passage에 대해 효과적으로 훈련한다. i = j일때 쌍이 positive 예이며, 그렇지 않으면 negative이다.
이렇게 하면 각 batch에서 B train instace가 생성되고 각 question에는 B-1개의 negative passage가 있다.
trick of in-batch negatives는 train example을 증가시키는 dual encoder model을 학습하는데 효과적인 전략이다.
Experimental Setup
Wikipedia Data Pre-processing
영어 위키백과 dump를 Question에 답하기 위한 source document로 사용
DrQA에 공개된 전처리 코드를 적용하여 article의 깨끗한 text 부분을 추출
-> 각 article를 100 단어의 여러개의 서로 분리된 text block으로 분할하여 기본 검색 단위로 사용한다.
Question Answering Datasets
이전 연구들에서 사용했던 5개의 QA dataset과 train/develop/test 분할 방법을 사용한다.
Natural Question : end-to-end Question answer를 위해 설계 되었으며, 질문은 실제 구글 검색 query에서 추출 되었고, 답변은 주석자에 의해 식별된 위키피디아 article 범위이다.
WebQuestion : 구글 Suggest API를 사용하여 선택한 질문으로 구성되며, 답변은 Freebase entity이다.
TREC : TREC QA track과 다양한 web source 질문을 제공하며, 비정형 corpus의 open domain QA를 위해 고안 되었다.
SQuAD v1.1 : 읽기 이해를 위한 인기 있는 benchmark dataset
주석자는 위키피디아 문단을 제시 받고, 주어진 text에서 답 할 수 있는 질문을 작성하도록 요청
SQuAD는 이전 open domain QA에 사용되었지만, 많은 질문에 context가 부족하여 이상적이진 않다 하지만 이전 연구와 비교를 위해 사용
Positive passage 선택은 TREC, WebQuestion 및 TriviaQA6에서는 question과 answer 쌍만 제공되므로, BM25에서 답변을 포함하는 가장 높은 순위의 passage로 사용한다.
검색된 top-100의 passage중 정답이 없는 경우 question은 폐기 된다.
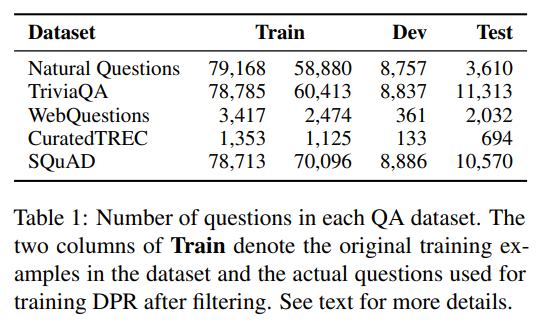
Table1은 모든 dataset에 대한 train/dev/test set의 question 수와 retriever train에 사용된 실제 question을 보여준다
Experiments: Passage Retrieval
DPR model
batch size : 128
BM25의 in-batch negative setting
대형 데이터의 경우 최대 40 epoch, 소형 데이터의 경우 100 epoch
학습률 : Adam을 사용하며,
warm up and drop out : 0.1
각 dataset에 retriever를 적응 시킬 수 있는 유연성을 가지고 있는 것이 좋지만, 전반적으로 잘 작동하는 단일 retriever를 얻는 것도 바람직하다.
따라서 모든 dataset(SQuAD를 제외한)의 train data를 결합하여 multi dataset encoder를 훈련한다.
DPR외에도 새로운 ranker 함수로 전통적인 retriever 방법 및 BM25 + DPR인 BM25의 결과도 제시한다.
Main Results
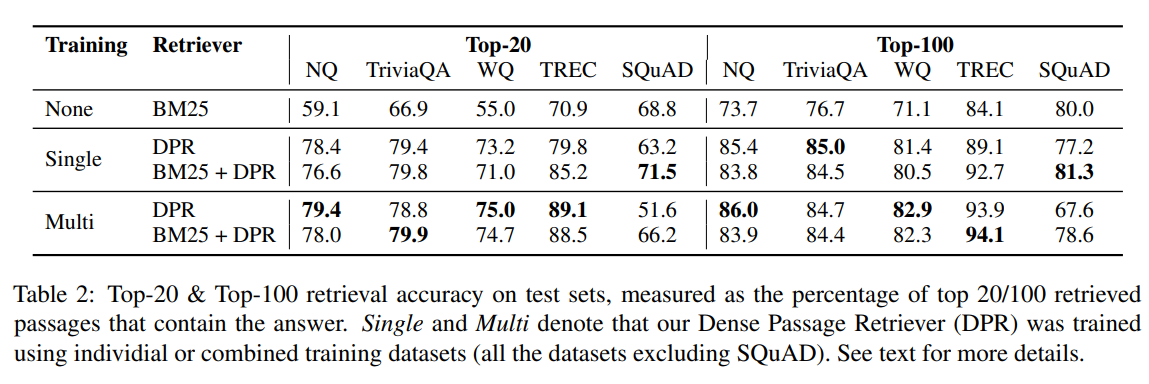
top-k 정확도를 사용하여 5개의 QA dataset에서 서로 다른 passage retrieval system을 비교
SQuAD를 제외하고 DPR은 모든 dataset에 대해서 BM25보다 지속적으로 우수하며 k가 작을 수록 그 격차는 크다.
single 및 multi dataset 설정 모두에서 DPR를 bm25와 결합하여 일부 경우에 더 개선 할 수 있다.
논문의 저자들이 말하는 SQuAD에서 성능이 떨어지는이유
1. 주석자가 해당 span을 본 후 질문을 작성
2. data는 500개 이상의 위키피디아 article에서 수집되었기 때문에 이전 주장과 같이 train example에 극도로 편향 되어 있을 수 있다.
Ablation Study on Model Training
Sample efficiency
우수한 passage 성능을 달성하기 위해 얼마나 많은 train example이 필요한지 본다.
일반적인 pretrained language model을 사용하면 적은 수의 question-passage pair로 고품질의 dense retriever를 train할 수 있음을 보여준다.
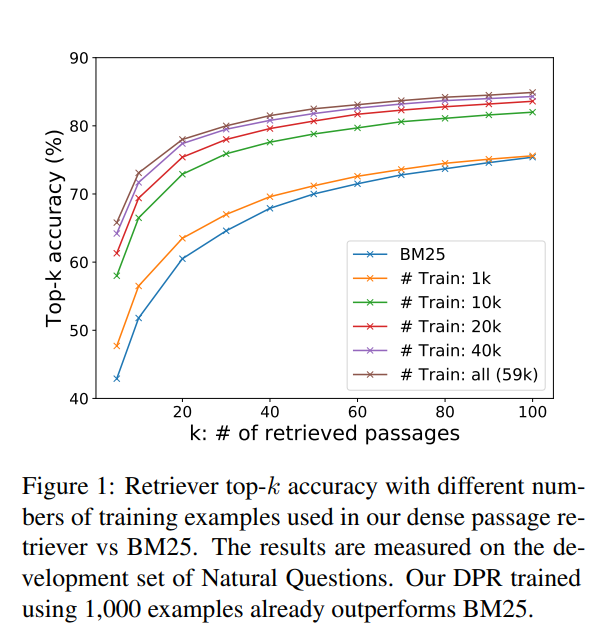
In-batch negative training
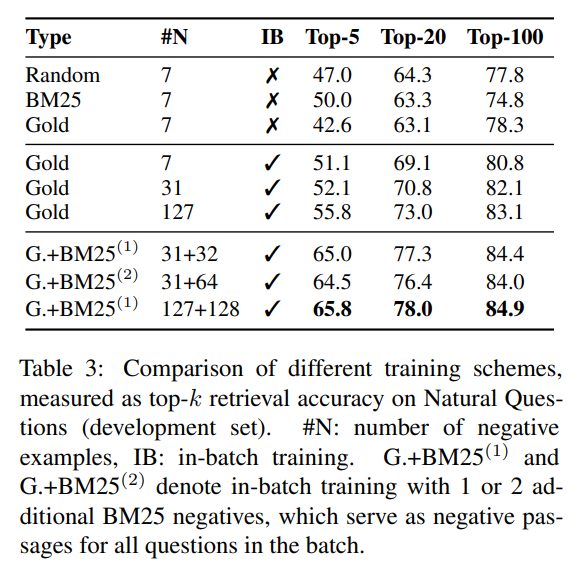
Natural question의 development 집합에 대한 다양한 훈련 계획을 테스트 하고 위의 표에 요약 되었다.
1. k가 20보다 큰 경우 random, bm25 또는 gold passage와 같은 negative choice는 top k의 정확도에 큰 영향을 미치지 않는다
2. 유사한 구성을 사용함녀 in batch negative train이 결과를 크게 개선한다.
-> 배치 내에 있는 negative train이 결과를 크게 개선한다. 결과적으로 정확도는 배치 크기가 증가함에 따라 지속적으로 향상된다
3. question이 주어진 BM25 점수는 높지만 답변 문자열을 포함하지 않는 추가적인 hard negative passage로 in-batch train을 한다. 이 경우 하나의 bm25는 negative passage를 사용하면 결과가 크게 개선되고, 두 개를 추가하면 더이상 도움이 되지 않는다.
Impact of gold passages
positive example로 원본 dataset의 gold context와 일치하는 passage를 사용한다.
natural question에 대한 논문에서 실험은 distantly-supervised passages로 전환되는 것이 작 은 영향을 미치는 것을 보여준다. retrieval을 위한 top-k의 정확도가 1% 낮아졌다.
Similarity and loss
dot product외에도 cosin 및 L2 거리도 일반적으로 분해 가능한 similarity 함수로 사용된다.
-> L2가 dot product와 동등한 성능이고, 두가지가 cosine보다 성능이 좋음을 발견
negative log likelihood 외에도 positive passage와 negative passage를 triplet ross가 순위를 매기는 인기 있는 옵션이였다.
Cross-dataset generalization
DPR의 discriminative training과 관련된 한가지 흥미로운 question은 ID가 아닌 설정으로 인해 얼마나 많은 성능저하를 겪느냐 -> fine-tuning 없이 다른 dataset에 직접 적용할때 여전히 일반화를 잘 할 수 있는가
--> DPR을 natural한 question만 훈련하고 웹 및 CuratedTREC dataset에서 직접 테스트
그 결과 가장 성능이 좋은 fine-tuning model 에서 3-5점이 손실되어 일반화는 잘되지만 BM25는 크게 능가함을 발견
Qualitative Analysis
일반적으로 DPR이 BM25보다 성능이 우수
하지만 검색된 span은 차이가 있다.
BM25는 keyword 및 span에 민감
DPR은 어휘변화 또는 의미적 관계를 더 잘 포착한다.
Run-time Efficiency
open domain QA를 위해 retrieval component가 필요한 주요 이유는 사용자 질문에 실시간으로 응답하는데 중요한 고려대상 passage를 줄이기 위해서 이다.
BM25/Lucene index를 처리하면 CPU 스레드마다 초당 23.7개의 question을 처리한다.
반면 dense vector를 위한 index를 구축하는데 필요한 시간은 더 길다.
2100만개의 passage를 dense embedding을 계산하는 것은 resource 집약적이지만 쉽게 병렬화 가능해서 8개의 GPU에서 8.8시간이 걸린다.
하지만 단일 서버에서 FAISS index를 구축하는데 8.5시간이 걸린다. 이에 비해 Lucene을 이용하여 inverted index를 구축하면 30분 밖에 걸리지 않는다.
Experiments: Question Answering
End-to-end QA System
서로 다른 retriever system을 직접 plug 할 수 있는 end-to-end QA system을 구현
QA system은 retriever, neural reader로 구성
검색된 top-k 개의 passage가 주어지면 reader는 각 passage의 selection score를 할당한다. 점수를 받은 passage에서 가장 좋은 passage가 최종 답변이 된다.
passage selection model은 question과 passage 사이의 cross attention을 통해 reranker 역할을 한다 cross attention은 분해 할수 없는 특성 때문에 large corpus에서 관련 passage를 검색하는데 실현되지는 않는다.
다만 dual encoder model 보다 더 많은 용량을 가지며 이를 소수의 검색된 후보로부터 passage를 선택하는데 적ㅇ요하는 것은 잘 작동하는 것으로 나타난다.
token이 답변 범위의 시작/종료 위치이고, passage가 선택될 확률은 다음과 같다.
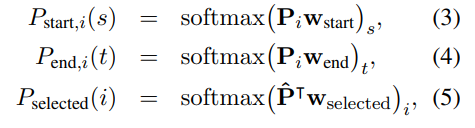
위에서 P와 w_start, end, selected는 학습이 가능한 vector이다.
i번째 passage에서 s~t까지 word의 span scroe를 P_start,i(s) x P_end,i(t)로 계산하고, i번째 passage의 passage selection score를 P_selected(i)로 계산한다.
training 중에, 각 question에 대해 검색 시스템에 의해 반환되는 top-100의 passage에서 하나의 positive 및 개의 negative passage를 sampling 한다.
이때 는 hyper parameter이며, 모든 실험에서 는 24를 사용하였다.
training object는 positive passage에서 모든 정답 범위의 marginal log-likelihood를 최대화 하는 것이며, 선택된 positive passage의 log-likelihood와 결합된다.
가장 큰 dataset에서는 16의 batch size를 사용하고, 작은 dataset에서는 4의 batch size를 사용하며 development set에서는 k를 조정한다.
다른 dataset에서는 다중 설정에서 작은 dataset의 실험의 경우 모든 natural 질문에 대해 훈련된 reader를 대상 dataset에 fine-tuning한다.
Result
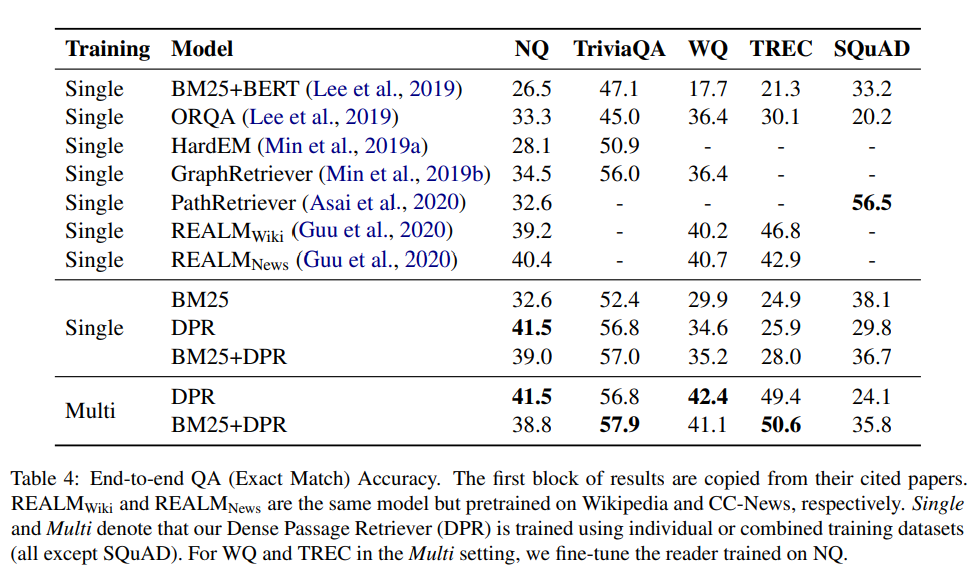
최종 end-to-end QA결과를 요약하며 base 답변rhk dlfclwjdehfh cmrwjdehlsek.
표를 통해 retriever의 정확도가 높을수록 일반적으로 더 나은 QA결과가 도출됨을 볼 수 있다.
SQuAD를 제외한 모든 경우에서 BM25의 답변에 비해 DPR에 의해 검색된 passage에서 추출된 답변이 더 정확할 가능성이 높다
- 대규모 데이터셋의 경우
NQ 및 TriviaQA와 같은 대규모 data set의 경우 여러 dataset을 사용하려 훈련된 model은 개별 train set를 사용하여 훈련된 모델과 유사한 성능을 발휘한다. - 소규모 데이터셋의 경우
WQ 및 TREC와 같은 소규모 data set에서는 multi dataset 설정이 명확한 이점이 있다. 전체적으로 DPR 기반 모델은 정확한 일치 정확도에서 5개 dataset 중 4개 dataset에서 이전의 sota를 능가한다.
두 방법 모두 End-to-End를 사용하지만 DPR은 단순히 question과 answer 쌍을 사용하여 강력한 passage 검색 모델을 학습하는데 집중함으로써 NQ 및 TriviaQA 모두에서 이를 능가한다. 추가 사전 훈련 작업은 대상 train set이 작을때만 더 유용할 수 있다.
작은 데이터셋에서의 DPR의 결과는 경쟁력이 떨어지지만 더 많은 question answer 쌍을 추가하면 성능이 향상되어 SOTA를 달성하는데 도움이 된다.
Pipeline 훈련 접근 방식은 joint learning과 비교하기 위해 retriever와 reader가 공동으로 훈련되는 natural question에 대한 ablation을 실행한다.
-> 이 방식은 39.8 EM의 점수를 얻으며, retriever와 reader를 격리하여 훈련하는 전략이 더 간단한 설계로 비교 가능한 joint learning 접근 방식을 능가하는 동시에 효과적으로 사용 가능한 감독을 활용할 수 있음을 시사한다.
주목할 만한 점은 추론에 얼마나 더 많은 시간이 걸리는지 완전히 명확하지 않지만 ORQA에 비해 더 많은 passage를 고려한다.
DPR이 각 질문에 대해 최대 100개의 passage를 처리하는 동안 reader는 32GB의 GPU에서 그 모든 것을 하나의 batch에 맞출 수 있으므로, 지연 시간은 single passage 사례와 거의 동일하게 유지된다. 처리량에 대한 정확한 영향은 측정하기 더 어렵다. ORQA는 DPR에 비해 2~3배 더 긴 passage를 사용하고ㅡ 계산 복잡성은 passage의 길이에 superlinear하다.
또한 k-50이 NQ에 최적이며, k-10은 정확한 일치도에서 marginal loss를 초래하며 ORQA의 55개의 passage 설정과 비교할 수 있어야한다.
Conclusion
- Dense retrieval이 open domain QA에서 전통적인 sparse component를 능가하고 잠재적으로 대체함을 보여줌
- Dense retriever를 효과적으로 훈련하기 위한 몇가지 구성요소가 있음을 보여줌
- 복잡한 모델 frame work나 similarity 함수가 반드시 추가적인 값을 제공하지 않음을 나타냄
- 검색 결과의 향상이 여러 open domain QA benchmark에 대한 SOTA를 얻음
