Abstarct
LM을 blackbox로 취급하고 조정 가능한 검색 모델로 증강하는 검색 증강 언어 모델링 frame work인 REPUG를 논문에서는 제시 하였다.
-> special cross attention 매커니즘을 가진 언어 모델을 훈련하는 이전 LM과 달리 REPUG는 검색된 문서를 동결된 black box model에 대한 입력에 추가된다. -> 기존의 retriever랑 LM에 쉽게 적용 가능하다.
논문에서의 실험은 REPUG가 LM에서 GPT-3의 성능을 6.3% 향상 시킬 뿐만 아니라 five-shot MMLU에서 codex의 성능을 5.1% 향상시켰다.
Introduction
GPT-3 및 Codex와 같은 LLM은 성능을 보였으나 parameter에 지식을 저장한다. 이 뿐 아니라 환각에 취약하고, corpus에서 얻은 지식의 전체 긴 tail을 나타낼 수가 없었다.
반면에 retrieval-augmented language model의 경우 필요할때 외부 DB에서 지식을 검색할수 있다 -> 환각 감소, coverage 증가
논문에서는 LM을 blackbox로 보고 retrieval component를 조정 가능한 plug & plug module로 추가하는 새로운 retrieval LM framework인 REPLUG를 제안하였다
inputcontext가 주어지면 REPLUG는 retriever를 사용하여 외부 corpus에서 관련 document를 검색 -> 검색된 문서는 input context에 의해 선행되고 blackbox LM과 병렬로 encoding 하는 새로운 앙상블 방식을 도입하여 정확성을 위해 쉽게 계산 가능하다.
REPLUG는 기존의 blackbox LM 및 retriever와 사용이 가능하다
blackbox language model의 supervised sign을 통해 REPLUG의 초기 retriever model을 더 개선할 수 있는 REPLUG LSR을 제안
retriever를 LM에 적응 시키는 것
-> language model을 retriever에 적응시키는 이전 연구와 대조적
--> 이러한 언어 모델 복잡성을 개선하는 문서 검색을 선호하는 훈련 목표를 사용하였으며, 이를 통하여 성능이 향상 되었음을 보여준다.
본 논문의 주요 기여는
1. retrieval augmented language model frame work인 REPLUG를 소개
2. language modeling score를 supervision signal로 사용하여 검색 품질이 향상된 LM에 기성 검색 모델을 추가로 적용하기 위한 훈련 계획을 제안
3. language modling, ODQA 및 MMLU에 대한 평가는 GPT, OPT 및 BLOM과 같은 다양한 LM의 성능향상을 보여준다.
Background and Related Work
Black-box Language Models
GPT-3, codex와 같은 대형 LLM은 상업적 고려 사항으로 인하여 open source가 아닌 query를 보내서 받는 API 형태로만 사용 가능하다.
반면 OPT및 BLOM은 open source language model로 local에서 실행이 되고 fine-tuning 하려면 상당한 계산 resource가 필요
-> 대형 언어 모델의 경우 크기가 커지고, blackbox의 특성이 증가함에 따라 fine-tuning과 같은 실현이 불가능하다.
Retrieval-augmented Models
다양한 지식 저장소에서 검색된 관련 정보로 언어 모델을 증강하면 언어 모델링 및 ODQA를 포함한 다양한 NLP 작업에서 성능 향상에 도움이 되었다.
1. 검색기는 corpus에서 문서 집합을 검색한 다음
2. 언어 모델은 검색된 문서를 최종 예측을 위한 추가 정보로 통합된다.
-> encoder & decoder model 이나 only decoder 모델에 추가 가능하다.
KNN-LM과 같은 검색 강화된 LM의 또 다른 라인은 token set를 검색하고 추론 시 검색된 토큰에서 계산된 KNN 분포 사이를 보간한다.
-> 하지만 대형 LM에 사용이 불가능하며, 내부 LM 표현에 access를 할 수 있어야 한다.
논문에서는 더 많은 문서를 통합하기위해 앙상블 방법과 대형 LM에 retriever를 추가로 적응 시키기 위한 train 계획을 제안한다.
REPLUG
language model이 blackbox로 처리되고 retrieval component가 잠재적으로 조정 가능한 모듈로 추가 되는 검색증강 LM 패러다임
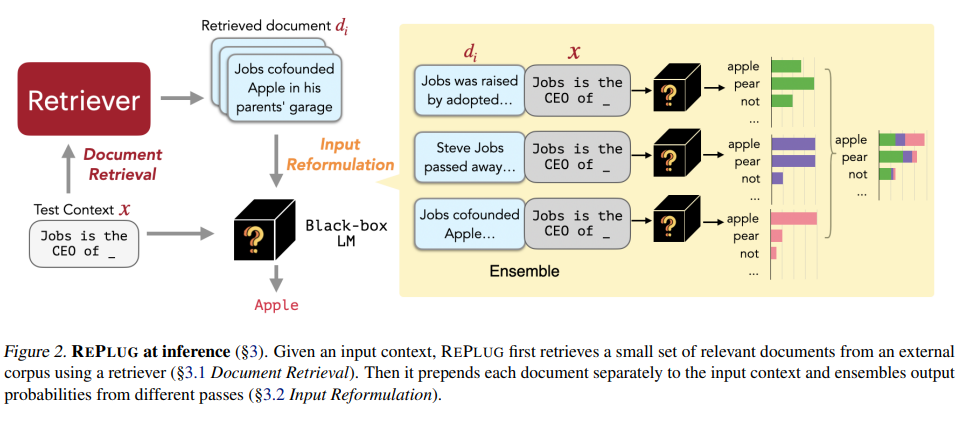
input context가 주어지면 REPLUG는 retriever를 사용하여 외부 corpus로부터 문서의 작은 set를 검색
검색된 각 문서와 input context의 연결을 LM을 통해 병렬로 전달하여 예측된 확률을 앙상블 한다.
Document Retrieval
input context x가 주어지면 retriever는 x와 관련된 corpus에서 작은 문서 set을 검색하는 것을 목표로 한다.
input context x와 document d를 모두 encoding 하기 위해 encoder가 사용 되는 dual encoder 아키텍처 기반의 조밀한 retriever를 사용한다.
encoder는 d에 있는 token에 대한 마지막 숨겨진 표현의 mean pooling을 취하여 각 문서 d D를 embedding E(d)에 매핑한다.
query 시간에 동일한 encoder가 input context x에 적용되어 query embedding E(x)를 얻는다.
query embedding과 document embedding 사이의 유사성은 cosine similarity에 의해 계산된다.
input x와 비교하였을때 유사도 점수가 높은 상위 k개의 문서는 위의 단계에서 검색이 된다.
효율적 검색을 위해 각 문서는 의 embedding을 미리 계산하고 이러한 embedding에 대해 FAISS index를 구성한다.
Input Reformulation
검색된 top-k 문서는 원래 input context x에 대한 정보를 제공하고 LM이 더 나은 예측을 하는데 잠재적으로 도움을 준다.
검색된 문서를 LM의 input의 일부로 통합하는 방법은 간단하지만 언어 모델의 context window를 생각하면 제한이 된다.
-> 논문에서는 이 제한을 해결하기 위해 앙상블 방법을 사용한다
는 score function에 다라 x부터 k개의 가장 관련 있는 문서로부터 구성된다고 가정한다.
각 문서 를 x에 추가하고 이 연결을 LM에 별도로 전달한 다음 모든 k개의 pass에서 출력 확률을 앙상블 한다.
input context x와 해당 top-k 관련 문서 가 주어지면 다음 토큰 y의 출력확률은 가중치 평균 앙상블로 계산한다.
위의 식에서 는 두 sequence의 연결을 나타내고 가중치 는 document d와 input context x 사이의 유사성 점수에 기초한다.
논문에서 제시한 앙상블 기법은 LM k 시간을 실행해야 하지만 각 검색된 문서와 input context 사이에서 cross entropy를 수행한다.
-> 모든 문서 앞에 붙이는 방법과 비교하여 overhead가 발생하지 않는다.
REPLUG LSR: Training the Dense Retriever
dense retrieval model에 의존하는 대신 LM을 사용하여 REPUG의 검색기를 조정하여 어떤 문서를 검색해야 하는지 supervise를 제공하는 REPUG LSR을 추가로 제안한다.
논문의 접근 방식
-> 언어 모델의 output sequence perplexities의 확률과 일치하도록 검색된 문서의 확률을 조정한다.
--> 논문 에서는 retriever가 perplexities score가 낮은 document를 찾기를 운한다.
1. 훈련 알고리즘은 문서의 검색 및 가능성 계산
2. language model에 의해 검색도니 문서에 점수를 매긴다.
3. 검색 가능성과 LM의 점수 분포 사이의 KL divergence를 최소화 하여 parameter update
4. datastore index의 비동기 업데이트
로 구성이 되었다.
Computing Retrieval Likelihood
input context x가 주어진 corpus D로부터 가장 높은 유사도 점수를 받은 k개의 문서 를 검색한다.
이후 검색된 각 문서 d의 검색 가능성을 계산한다.
여기서 는 softmax의 temerature를 조절하는 hyperparameter이다.
실제로 다루기 어려운 corpus D의 모든 문서를 주변화 함으로써 계산한다. 검색된 문서 를 marginalizing하여 검색 가능성을 근사화한다.
Computing LM likelihood
LM을 scoring function으로 사용하여 각 document가 LM의 perplexity를 얼마나 개선하는지 측정한다.
input context x와 document d가 주어지면 truth output y의 LM 확률인 PLM(y|d,x)을 계산한다.
확률이 높을 수록 document di가 LM의 perplexity를 개선하는데 더 효과적이다.
이후 각 문서 d의 LM 가능성을 다음의 수식으로 계산한다.
위의 식에서 는 다른 hyperparameter이다
Loss Function
input context x와 대응 되는 연속된 truth 값인 y가 주어지면 검색 가능성과 언어 모델 가능성을 계산한다.
dense retriever는 두 분포 사이의 KL divergence를 최소화 하여 훈련된다.
위의 식에서 는 input context의 집합이며, loss를 최소화할때 검색 모델 parameter들만 업데이트가 가능하며, LM의 parameter는 blackbox가정으로 고정된다.
Asynchronous Update of the Datastore Index
train 과정에서 retriever의 parameter가 업데이트 되어 이전에 계산된 document embedding은 최신이 아니게 된다.
-> 최신으로 하기 위해 document embedding을 다시 계산하여 효율적인 retrieval index를 재구성한 뒤 새로운 document embedding과 index를 검색하여 교육 절차를 반복
Training Setup
REPLUG
dense 또는 sparse 모든 retriever를 REPLUG를 사용할 수 있다.
-> 이러한 이유로 논문에서는 Contriever를 사용한다.
REPLUG LSR
REPLUG LSR의 경우 contriever model로 retriever를 초기화 하고, LM 가능성을 계산하기 위해 GPT-3 query를 supervise LM으로 사용한다.
Training data
훈련 데이터에서 sampling된 256 token의 800k sequence를 train query로 사용한다.
각 query는 두가지 부분으로 분할되며
1. 128 query는 input context로 활용, 나머지 query는 truth continuation y로 활용
외부 corpus D의 경우 파일 훈련 데이터에서 128개의 token 36M 문서를 sampling 한다.
Training details
FAISS index를 생성하며, query x가 주어지면 FAISS index에서 top 20의 문서를 검색하고, temperature 0.1 retrieval likelihood와 LM likelihood를 계산한다.
학습률은 2e-5, 배치 크기 64, warm up 비율이 0.1인 adam을 사용하여 retriever 를 훈련한다.
Experiments
언어 모데링과 MMLU, ODQA와 같은 downstream에서 실험을 진행
Language modeling
dataset
웹페이지, code, 학술 논문 등의 다양한 domain으로 구성된 text source로 실험을 진행하였다.
baseline
GPT-3 및 GPT-2의 family model들을 사용하였으며, API를 사용한 black box 모델이다.
Our model
논문은 baseline에 REPLUG와 REPLUG LSR을 추가하여 훈련 데이터를 subsampling 하여 모든 model의 retriever corpus로 사용하였다.
중복 제거를 위해서 REPLUG와 REPLUG LSR 모두에게 retriever를 수행하고 추론 중 top 10의 검색된 문서를 통합하기 위해 앙상블 기법을 사용
Result
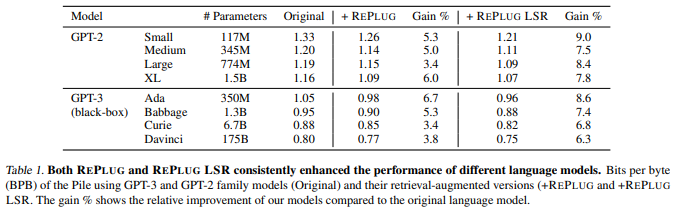
두가지 모두 baseline을 크게 증가
Retriever를 대상 LM에 추가 적용하는 것이 이득이 되는 것을 확인
MMLU
Datasets
Massive Multi-task Language Understanding은 57개의 과제의 시험 문제를 다루는 다중 QA 데이터 셋이다.
baseline
이전 모델을 baseline으로 사용하며 Codex, PaLM, LanPaLM을 포함하였다.
두번째 baseline으로는 Atlas를 사용하였으며, retriever랑 LM 모두 훈련 시켜 white box LM 설정으로 간주한다.
Our model
PaLM과 Flan-PaLM과 같은 모델은 접근 불가, Codex와 REPLUG및 REPLUG LSR을 추가하였으며, query를 사용하여 top 10의 문서를 검색하고 LM에 공급되어 output 확률은 앙상블 된다.
Result
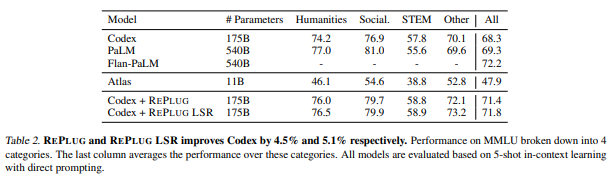
-> parameter개수를 생각했을때 좋은 성능을 보이며, 기존 모델보다 더 뛰어난 성능을 보여준다.
Open Domain QA
Codex를 포함한 대규모 LM으로 구성된다.
모델들은 few-shot을 사용하여 평가 되었으며, 두번째 비교 모델 그룹에서는 retriever 강화 언어 모델이 포함된다. 모두 몇 번의 샷 설정 및 학습 데이터와 함께 훈련 데이터에 fine-tuning 된다.
Our model
-> context train에서 16-shot을 사용 하여 평가하기 위해 retrieval corpus로 하여 Codex에 REPLUG와 REPLUG LSR을 추가한다.
앙상블 방법을 사용하여 top-10의 문서를 통합한다.
Result
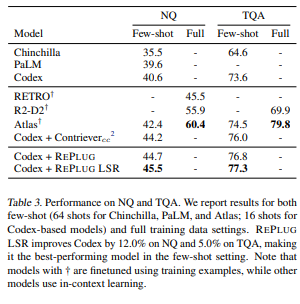
REPLUG LSR은 codex 성능을 NQ에서 12% TQA에서는 5%를 향상 시켰다.
이전의 SOTA 모델을 능가하며, 새로운 SOTA 성능이 나온다. 하지만 전체 훈련 데이터에서 fine-tuning된 retrievel-augmented LM에는 밀린다.
Analysis
REPLUG
서로 다른 path의 출력 확률을 결합하는 앙상블 방법을 사용하는 것이 핵심

위의 그림과 같이 임의의 문서, REPLUG에 의해 검색된 문서, REPLUG LSR에 의해 검색된 문서로 증강하였을때 GPT3의 query의 성능을 평가 하면
임의의 결합에서는 성능저하, REPLUG 일때는 성능이 이득을 보는 것을 확인 할 수 있다.
REPLUG is applicable to diverse language models
REPLUG가 서로 다른 data와 방법을 사용하여 사전 훈련된 다양한 언어 모델 family를 향상 시킬수 있는지 연구

-> 모델 크기와 일관성 유지를 확인 가능
-> 서로 다른 크기를 가진 다양한 LM에 적용 가능을 보여줌
Qualitative Analysis: rare entities benefit from retrieval
REPLUG가 Language modeling 성능을 향상하기 위해 perplexity를 감소하는 것을 분석
-> REPLUG가 sparse 개체들에 도움이 된다는 것을 발견하였다.
-> REPLUG를 사용하였을 경우 perplexity가 향상 되었다.
Conclusion
-> blackbox model을 retriever로 증강하는 REPLUG를 제안
-> 기존의 LM과 통합하여 성능 향상을 보여준다.

감사합니다. 이런 정보를 나눠주셔서 좋아요.