Abstract
생성 중에 Corpus에서 관련 문서의 LM을 조건으로 하는 Retrieval-Augmented Language model(이하 RALM)은 언어 모델링을 크게 향상 시키며 Natural source attribution mechanism을 제공한다.
기존의 방식은 LM 아키텍처를 수정하는데 초점을 맞춰 복잡하다
-> 논문에서는 아키텍처 수정이 아니라 input에 grounding document를 추가한다
--> 이를 통하여 기존의 Retriever를 사용하는 모델이 large LM에 큰 이득을 주는 것을 확인 하였다.
논문에서는 이런 in context RALM이 pretrain LM을 수정 없이 하는 경우에 LM의 grounding의 보급률을 증가 시킬 수 있는 잠재력이 있다고 본다.
Introduction
Language model이 외부 지식에 대한 접근에는 내재적인 한계를 가지고 있다.
1. 어떤 source와의 귀속과도 결합되지 않으며, 사실의 부정확성 또는 오류를 포함할 수 있다.
2. LM이 교육중 보지 못한 최신 정보를 통합하려면 재교육을 받아야한다.
-> 해결하기 위한 방법 RALM
RALM의 장점
1. 외부 지식 source에서 검색된 관련 문서를 조건화 하여 생성 중에 LM을 접지 시킨다.
2. RALM은 문서 검색 도는 조건을 지정할 문서 set 선택rhk 문서 읽기 및 선택된 문서를 LM 생성 process에 통합하는 방법의 두가지 상위 구성요소가 포함
기존의 연구 방향은 RALM의 아키텍처 변화에 초점이 맞춰져 있었으며, 성능이 잘 나오더라도 그 복잡성과 재교육으로 인하여 모델의 광범위한 채택을 방해했다.
논문에서 제시하는 방법은 문서 선택 매커니즘을 언어 모델링 작업에 적용하여 많은 이득을 얻고 기존 LM이 동작할때 RALM의 많은 이점을 달성하였다.
-> 이를 바탕으로 RALM의 framework를 제안 하였으며, 단순히 선택한 문서를 LM의 input text에 추가하였다.
RALM은 간단한 판독 매커니즘을 고려할때, in-context RALM은 LM 작업에 특화된 document retriever 방법을 개발하기 위한 clean prove의 역할을 할 수 있으며, 기성 LM과의 호환성 때문에 in-context RALM은 RALM system 보다 광범위한 배치를 추진하는데 도움이 된다.
Related Work
RALM의 접근 방식은
KNN-LM과 Retriever 및 read model의 두가지로 대변 될 수 있다.
-> 논문의 방식은 유사하지만 LM의 추가 훈련을 포함하지 않는다.
KNN-LM
KNN-LM의 방식은 두개의 토큰 분포 사이를 보간하는 간단한 inference-time model을 제안한다.
하나는 LM 자체에 의해 유도된 것, 다른 하나는 LM embedding 공간에서 query token에 가장 가까운 retrieval corpus에서 k개의 이웃에 의해 유도된 것이다.
-> 접근 방식의 문제점은 token에 대한 표현을 corpus에 저장해야하며, 작은 corpus의 경우에도 비싼 요구사항이다
Retrieve and Read Models
RALM Family는 문서 검색과 문서 읽기 구성요소 사이에 명확한 구분을 만든다.
-> 이전 작업은 LM을 교육한다.
1. downstream 작업을 해결하기 위해 작업을 설명한 다음 RALM을 지향한는 작업을 언급
Lewis 및 Izacard and Grave는 encoder가 문서를 읽도록 훈련되는 downstream 지식 집약적 작업을 위한 fine tuning encoder-decoder 아키텍처를 설명
Izacard는 이러한 모델의 pretrain의 다양한 방법을 탐구
Levine은 문장 embedding 공간에서 가장 가까운 이웃의 cluster에 대해 autoregressive LM을 pretrain 등등이 있따.
본 논문에서는 언어 모델링 작업인 RETRO에 초점이 맞춰져 있으며, 이는 chuncked cross-attention을 통해 관련 문서에 참석하도록 autoregressive LM을 수정하며 모델에 새로운 parameter을 도입한다.
-> 논문에서의 모델은 약간 다른 측면이 존재
1. LM에 대한 추가 train 없이 문서 판독을 위해 기성 LM을 사용
2. LM 성능 향상을 위한 문서 선택 방법에 초점을 맞추고 있다.
Our Framework
In-Context RALM
언어 모델은 token sequence에 대한 확률 분포를 정의한다.
확률을 모델링하는 표준 방법은 이며 pre sequence라고도 한다.
위에서 조건부 확률은 causal sefl-attention를 사용하여, 모델링이 된다. GPT와 같은 leading LM은 이 매개변수화를 따른다.
하지만 RALM은 외부 corpus C로부터 하나 이상의 문서를 검색하는 연산ㅇ르 추가하고, 이런 문서위의 LM 예측을 조건화 한다.
를 예측하기 위해 C로부터의 retrieval operation은 접두사 에 의존하여, 가장 일반적인 RALM 분해는 다음과 같다.
이다.
검색된 문서에 LM 생성을 조건화 하기 위해 이전 RALM접근법은 아키텍처나 알고리즘을 사용하였으나 in-context RALM은 접두사 이전에 변환기 입력 내에서 검색된 문서를 연결하는 방법을 사용한다.
Transformer 기반 LM 구현은 제한된 길이의 입력 sequence를 지원하여, 이 제한을 초과할 경우 전체 입력 길이가 모델에서 허용하는 길이와 같을때까지 시작 부분에서 token을 제거한다.

RALM Design Choices
Retrieval Stride
Retriever의 호출 비용과 생성 중 LM 접두사의 문서를 교채하기 때문에 token에 한번만 검색을 수행을 원할 수 있다.
-> in context에서는 다음의 공식을 사용한다.
위의 식에서 는 retrieval strides 이다.
Retrieval Query Length
검색 쿼리는 원칙적으로 모든 접두사 token 에 의존하지만, 접두사 끝에 있는 정보가 생성된 token과 가장 관련이 많으며, query가 길면 정보가 희석 될 수 있다.
이를 방지하기위해
, ..., x_{s\cdot i-1}
여기서 l을 retreval query length라 하며, 기존의 RALM작업에서는 retrieval stride와 retreval query 길이를 결합한다.
s=l을 강제하는 것이 성능이 떨어지며, hyper parameter를 incontext RALM 공식에 통합하면 아래와 같다.
Experimental Detail
dataset
5개의 다양한 데이터셋에 걸쳐 맥락 내 RALM의 효과를 평가 하였다.
1. WikiText103
2. The Pile에서 다양한 주제에 걸쳐 있는 3개의 dataset
3. RealNews
Models
Language Model
GPT2의 4가지 model
OPT의 8개 model
GPTNeo 및 GPT-j의 3개 모델을 사용
GPTNeo 및 POT 모델은 2048의 sequence길이를 지원함에도 불구하고 1024인 모든 보델을 실행(비교를 용이하게 하기 위해서)
Retrievers
단어 기반 sparse 및 dense retrievers 모두로 실험을 진행하였다.
sparse model로 BM25를 사용하였으며, dense model의 경우 BERT에 이어 mean pooling으로 실험을 진행하였따.
Unsupervised 방식으로 훈련된 Contriever model로 실험을 하였다.
Reranking
reranker를 훈련할때 Roberta-base로부터 초기화를 진행하였다.
Implementation Details
Transformer library를 기반으로 구현을 하였다.
DPR code 저장소를 기반으로 밀도 높은 retrieval code를 기반으로 하였다.
Retrieval Corpora
WikiText-103의 경우 전처리를 사용하여 표준화 한 데이터를 사용
모델에 입력할때 retrieved passages를 256개의 token으로 잘라내지만 일반적으로는 훨씬 작다
Retrieval
sparse retrieval을 위해 pyserini 라이브러리를 사용하였으며, dens retrieval을 위해 FAISS를 사용하여 정확한 검색을 허용하였다.
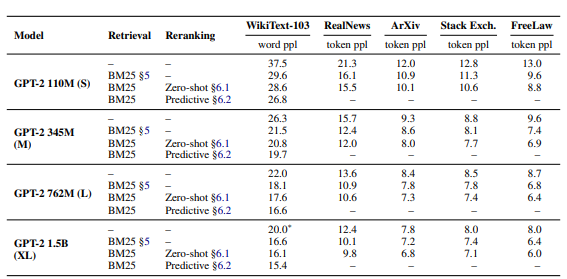
The Effectiveness of In-Context RALM with Off-the-Shelf Retrievers
간단한 문서 판독 매커니즘에도 불구하고 내장형 RALM은 다양한 평가에서 LM의 상당한 이득을 가져왔다.
-> 내장형 RALM에 대한 기성 검색기의 효과를 조사하는 것으로 시작한다.
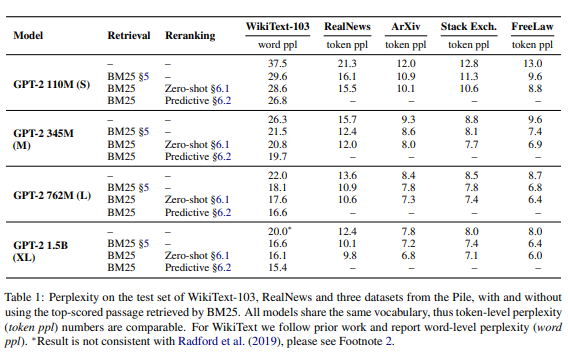
위의 이미지는 in context RALM을 사용하여 2~3배 큰 model과 충분히 일치할 정도로 LM 복잡성을 개선한 모든 조사된 corpus에 대해 보여준다.
figure2는 OPT 모델에 대해 WikiText-103 및 RealNews dataset 모두에 대해 66B 매개변수 까지 개선 추세가 유지됨을 보여준다.
BM25 Outperforms Off-the-Shelf Neural Retrievers in Language Modeling
다양한 기성 범용 retriever를 사용하여 실험한 결과 sparse한 BM25 retriever는 자체 감독 검색기 contriever 및 spider와 RETRO system에 사용된 BERT embedding의 mean pooling에 기반한 retriever의 세가지 인기 있는 dense retriever보다 성능이 우수하다.

l이 64일때 모든 dense retriever에 가장 잘 동작함을 보여준다.

context RALM의 서능 향상을 4개의 범용 retriever와 비교한다. BM25 retriever는 모든 dense retriever보다 성능이 뛰어났으며, 이 결과는 zeroshot 설정에 적용 될때 BM25가 광범위한 작업에서 neural retriever보다 성능이 우수하다는 것을 보여준다.
Frequent Retrieval Improves Language Modeling
retrieval stride를 변경하는 효과를 조사 하였다.
retrieval 작업이 빈번해짐에 따라 LM 성능이 향상되었으며, 이는 생성된 token과 더 밀접해질 수록 retrieval query와 더 관련성이 높아짐을 보여준다.
성능과 runtime의 균형을 맞추기 위해 s=4를 사용하며, 비교를 위해 RETRO는 s=64의 검색 빈도를 사용하여 복잡도를 낮추었다.
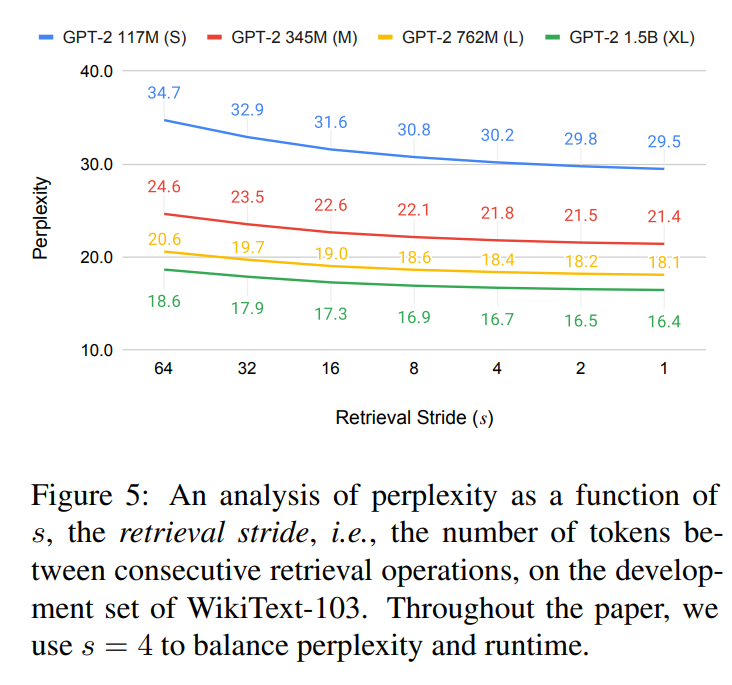
A Contextualization vs. Recency Tradeoff in Query Length
BM25에 대한 retrieval query length인 l을 벼화시키는 효과를 보면 figure 6에 나와 있다.
retrieval query가 너무 짧을때 input context가 충분하지 않아 문서의 관련성이 감소한다, 반대로 query가 지나치게 증가하면 접두사 맨 끝의 token이 강조되지 않아 LM 작업에 대한 query의 관련성이 희석된다.
Improving In-Context RALM with LM-Oriented Reranking
context 내 RALM은 정의에 따라 고정된 문서 읽기 구성 요소를 사용하기에 LM 작업에 문서 검색 매커니즘을 특화하여 성능을 향상 시킬 수 있다.
BM25 검색기에 의해 검색된 첫번째 문서에만 모델을 조건화 하는 것을 고려하였다. 또한 나중에 생성된 text와 더 관련이 있다는 것을 인식하는 것과 같이 다른 query token에 다른 중요도를 부여할 수 있는 방법이 제공X
BM25 검색기에 의해 반환된 상위 k개 문서의 순위를 변경하며 model에 제공할 문서를 선택하는데 초점을 맞추고 있다.

위의 그림에서 BM25검색기에 의해 반환된 상위 16개의 문서중 개선 가능성이 큼을 보여준다.
LMs as Zero-Shot Rerankers
문맥내 RALM 설정을 위한 문서 reranker로 언어 모델을 사용하였다. 형식적으로 LM 입력 X의 접두사에 있는 마지막 token l token으로 구성된 query q에 대해 를 BM25에 의해 반환되는 상위 k개의 문서라고 가정한다. retrieval iteration i 에 대해 생성을 위한 text는 이다. 이상적으로 생성을 위한 textㄹ의 확률을 최대화 하는 문서 를 찾는다.

test시간에 y token에 접근할 수 없으므로, test time에 사용할수 있는 마지막 접두사 token의 수를 결정하는 hyper parameter s' 를 정의하고 다음과 같은 방식으로 문서를 선택한다.

BM25가 어휘 검색기이기 때문에 LM에 의해 유도된 semantic sign을 통합하기를 원한다. 이 reranking은 개방 도메인 질문 답변을 위한 reranking framework와 개념적 유사성을 공유하며, 여기서 접두사 는 question으로 생각될 수 있다.
제로샷 재배열은 재배열에 사용되는 LM이 생성에 사용되는 LM과 동일한 모델일 필요가 없다는 점에 유의하여, 를 매개변수화한 LM은 된 식의 LM일 필요가 없다.
-> 더 작은 모델로 재배열할 가능성이 열림
장점 1. k개의 문서의 재배열에는 k개의 전진 패스가 필요하다
장점 2. 실제 LM의 log 확률을 사용할 수 없는 경우 논문에서의 방법을 사용할수 있도록 한다.
Result
개발 세트에 대한 최소한의 hyper parameter 검색 결과 최적의 query 길이는 s' = 이므로 해당 값으로 진행을 한다.
작은 LM이 큰 LM에 대해 문서순위를 다시 매기는데 사용 될 수 있으며, 각 LM이 자체적으로 순위를 다시 매기는 것과 거의 동일한 성능으로 엑세스 할 수 있는 LM에 대해 논문의 방식을 적용할 수 있다.
reranker는 retriever에서 반환된 첫번째 결과를 취하는 것보다 더 나은 결과를 도출한다.
Training LM-dedicated Rerankers
LM-dedicated Rerankers
BM25에 의해 검색된 상위 k개의 문서에서 문서를 선택하도록 reranker를 훈련 시킨다.
Reraner는 어떤 문서가 다가오는 text를 예측하는데 도움이 되는지를 선택하는 방법을 배우기에 predict reranker라고 부르며, 이 process를 위해 대상 corpus에서 train data의 가용성을 가정한다. 논문의 저자는 reranker는 document 와 접두사 를 얻는 분류기 이며, 의 연속에 대해 의 관련성과 유사해야하는 scalar f를 생성한다.
그런 다음 관련 score를 정규화한다.

문서 j는 아래의 방법으로 선택을 한다.
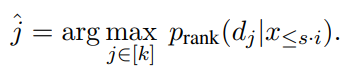
Training Process
논문에서의 reranker는 훈련된 정밀한 RoBERTa 기반이였다.
를 훈련 데이터에서 샘플링한 접두사라고 하고, 를 다음 단계의 text라 한다. 에서 파생된 query q에서 BM25를 실행하고 k개의 문서 를 얻는다 각 문서 dj에 대해 LM을 실행하여 를 계산한다. reranker를 훈련하는데 사용되는 손실함수는 이전의 연구를 따른다.
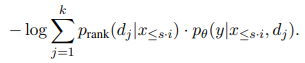
이러한 두 작업과 달리 논문에서의 방식은 reranker만 훈련하고 LM의 가중치는 동결된다.
Result
wikitext-103의 trainset에 대한 predictive reranker를 훈련한 결과이다.
predictive reranking을 통해 얻은 이득이 관찰 가능했으며, 복잡성이 감소하였음을 관찰 할 수 있다.
-> domain별 data를 사용하여 reranker를 훈련하는 것이 zeroshot reranking 보다 더 효과적임을 보여준다.
BM25 검색기를 통해 k>16개의 문서를 검색하거나 RALM 작업 전용의 더 강력한 retriever를 훈련함으로 개선할 수 있다.
Discussion
외부 소스로부터의 검색은 지식 집약적인 작업에서 일반적인 관행이 되었다. 이를 병행하여 LM 생성 기능의 최근의 발전은 긴 텍스트를 생성할 수 있는 LM으로 이어졌다.
-> 그러나 부저확성은 기계 생성 텍스트가 부족할 수 있는 일반적인 방법으로 남아있으며, 증거 부족시 신뢰하기 어렵다.
이전 연구는 RALM을 조사했지만 베포가 되지 않았다 -> 기존의 방식이 LM을 fine-tuning하는데 의존하기 때문이며, 일반적으로 이는 어렵고 비용이 많이든다.
논문은 frozen된 기존 LM이 검색의 혜택을 받을 수 있도록 하는 맥락 내 RALM의 framework를 제시하였다.
범용 retriever를 사용하여 성능 향상을 입증 하였으며, document 선택을 LM 설정에 맞춤화하여 추가적인 이득을 얻을 수 있음을 보여주엇다.
향후 연구 방향
1. 논문에서는 외부 문서를 context에 추가하는 경우만 고려
2. 생성하는 동안 token의 고정 간격 마다 문서를 검색했지만, 전문 모델이 검색이 필요하다고 예측하는 경우에만 검색하는 것과 같이 더 드문 경우 검색함으로 대기 시간이 길어지고 비용이 증가할 가능성이 존재
3. 최근 기성 LM을 사용하여 생성할때 입력 sequence를 병렬화 하는 방법을 제안
