ANALOG BITS: GENERATING DISCRETE DATA USING DIFFUSION MODELS WITH SELF-CONDITIONING 논문 읽기
LLM 논문 읽으며 정리
본 논문은 ICLR2023에서 소개된 논문으로 구글에서 발표한 논문입니다.
Abstract
연속 상태와 연속 시간 Diffusuion 모델로 간단하고 일반적인 비트 확산을 제시하였다.
주요 아이디어
이산적인 데이터 -> 이진 비트 -> 연속 확산 모델
위의 이진 비트를 실수(아날로그 비트)로 모델링 하기 위하여 모델을 훈련하는 것
생성하기 위한 모델의 생성 순서
1. 모델은 아날로그 비트를 생성
2. 이산 변수를 나타내는 비트를 얻기 위한 임계값 설정
본 논문에서는 생성된 품질을 개선 시키기 위하여 Self-Conditioning 과 Asymmetric Time Intervals를 제안
논문에서 제안된 방식은 단순하지만 좋은 성능을 달성 하였다.
CIFAR 10 데이터에서는 SOTA모델을 능가하였으며, MS-COCO데이터셋의 경우 Autoregression model 과 경쟁 할만한 결과를 얻었다.
Introduction
이산적인 이미지와 데이터를 생성하는 SOTA모델들은 Autoregressive modeling을 기반으로 만들어졌다.
종종 트랜스포머 순차적으로 또는 인과 관계 mask를 이용하여서 이전 토큰이 주어진 각 토큰을 예측하도록 훈련 되었다.
- 문제점
- 데이터 차원에 2차적인 계산 및 메모리가 필요하여 큰 데이터의 모델링의 경우 어렵다.
- 생성 중에 Autogressive 모델이 한번에 하나의 토큰을 수행하여 샘플링 단계의 수가 같아 큰 데이터를 생성 하는 경우 속도가 느려진다.
반면 Diffusion 모델 또는 Scorebased 생성 모델의 경우
메모리 문제 발생 X
순차적인 샘플링 단계의 수 Down (반복적인 정제 작업으로 인해)
- 문제점
- 연속적인 데이터만 생성 가능하며, 이산적인 생성의 경우 Autoregressive model에 비해 경쟁력있는 결과 X
본 논문이 제시하는 것
연속적인 Diffusion model이 이산 데이터를 생성 할 수 있는 접근법 제안
해당 접근 법의 핵심적인 요소 -> 아날로그 비트
아날로그 비트는 이상 데이터를 비트로 모델링 할때 사용하는 실수
- 사용하는 이유
- 이산 상태 공간이나 연속 확산 프로세스의 재공식화(reformulation)없이 이산 변수로 디코딩
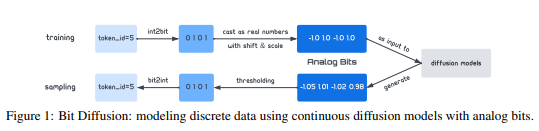
본 논문에서는 강한 연속 생성 모델을 이용하여 아날로그 비트가 이진 비트에 가까운 고집약 bimodal 데이터를 생성하는 것이 어렵지 않다고 이야기 한다.
손실 함수를 줄이기 위해 신경망은 임계값 후에 실제로 의미 있는 이산변수로 이어질 아날로그 비트 사이의 구조를 모델링한다.
본 논문은 이산 이미지 생성과 이미지 조건부 텍스트/캡션 생성 모두에 대해 제안된 접근 방식을 평가하며, CIFAR10에서 SOTA모델을 웃돌고, MS-COCO데이터셋 에선 경쟁력 있는 결과 도출
Method
배경 지식(Diffusion model)
Diffusion 모델의 경우 이전 노이즈 를 데이터 분포의 에 매핑 하기 위해 상태 전환을 학습
요약
Diffusion 모델의 경우
순방향 프로세스 로 노이즈 를 주입하여 노이즈 분포로 만든다.
역방향 프로세스 의 과정으로 훈련을 진행하게 되며, 에서 를 구할 수 있게 된다.
노이즈 의 경우 가우시안 분포를 따르고 있다.
DDPM에 대한 설명 참고 https://jang-inspiration.com/ddpm-2
아날로그 비트
크기가 K인 알파뱃의 이산 데이터 변수는 비트를 사용하여 으로 나타낼 수 있다.
기존 연구의 경우 이산 데이터 공간과 상태 공간을 채택하여 연속 확산 모델을 재구성 해야 한다.
반면에 본 논문에서는 연속확산 모델에 대해 이진비트 을 단순히 실수 으로 캐스팅 할 것은 제안
이진 비트와 동일한 바이모달 값을 공유하는 방법법을 배우지만 실제 숫자로 모델링 되어 본 논문에서는 아날로그 비트라고 부른다.
샘플을 생성하기 위해 아날로그 비트를 임계값으로 하여 마지막에 양자화(quantization)연산을 적용하는 것을 제외 하고는 연속 확산 모델 모델에서의 샘플링 절차와 동일하다,.
이는 이진 비트를 생성하여 원래의 이산/범주 변수로 변환할 수 있다.

모델이 정확한 이진 비트를 생성하도록 강제하는 제약은 없지만, 명확한 바이모달 농도를 나타내는 실수를 생성할 강력한 연속 생성 모델을 기대한다.
단순화를 위해 손실 함수는 cross entropy 함수를 사용하며, 아날로그 비트를 구성하기 위해 이진 인코딩 매커니즘이 확장 가능하다는 것에 주목한다(one-hot encoding)
Self-Conditioning
Conditioning은 확산 모델을 개선하는데 유용한 기법이다.
본 논문에서는 일반 적인 조건화 변수나 다른 네트워크 저해상도 이미지 등은 외부 소스에서 가져 왔다.
본 논문에서는 반복 샘플링 과정에서 모델이 이전에 생성된 샘플 자체를 직접 조건화 하는 기술을 제안 하였으며, 이는 샘플 품질을 크게 향상 시킬 수 있다.
일반적인 Diffusion model의 샘플링 과정에서는 데이터에 매핑하는 체인을 진행하기 위해 나 노이즈 을 반복적으로 예측한다.
그러나 이전 시간으로 부터 추정 할때 이전에 추정된 값들()은 폐기 된다. 즉 노이즈 제거 함수()는 이전에 추정된 에 의존하지 않는다.
이 부분에서 본 논문은 약간 다른 노이즈 제거 기능을 고려한다.(그림 2(b))
간단한 Self-Conditioning은 텍스트를 이전에 추정된 값과 연결하는 것이다.
값이 sampling chain의 초기 예측값에서 나온 것이기에 이것은 무시 할 수 있는 추가 비용이 든다.
노이즈 제거 기능을 훈련 시키기 위해 훈련에 약간의 변경을 가하는데 일부 확률로 self-conditing이 없이 모델링으로 돌아가는 을 설정한다.
다른 경우에는 를 추정한 다음 self-conditioning을 사용한다.
추정된 를 이용해 backpropagation을 하지 않아 훈련 시간이 적다.
Asymmetric Time Intervals
Self-conditioning 외에도 비트 확산모델에 영향을 주는 시간 단계 t를 식별한다.
t는 노이즈 제거 신경망인 뿐만 아니라 상태 전환에도 필요한 필수 부분이다.
전형적인 denoising process 동안 모델은 상태 전이와 시간 감소 자체에 대해 대칭적인 시간 간격을 취하여 의 두 인수 모두에 대한 same/share t를 생성한다.
하지만 대규모 reverse step을 취할 때 생성 시 Asymmetric Time Intervals(비대칭 시간 간격)을 사용하면 비트 확산 모델의 샘플링 품질을 향상 시킬 수 있다는 것을 발견
더 구체적으로는 표본 추출 과정 중 Asymmetric Time Intervals으로 를 가지며, (ξ는 음이 아닌 시간 차이 매개변수)
훈련은 변경되지 않고 의 두 인수 모두에 same/share t가 사용된다.
figure3은 forward process를 사용하여 구성된 상태 텍스트에서 두개의 역방향 단계를 수행하도록 요청하는 훈련된 비트확산 모델의 효과를 보여주고 있다.

Putting it together
알고리즘 1과 2를 결합하면 매개변수를 통하여 아날로그 비트, Self-Conditioning, Asymmetric Time Intervals를 이용하여 확산 모델에 대한 훈련 및 샘플링 알고리즘이 요약된다.
아래의 알고리즘에서 기존 확산 모델에 대한 제안도니 변경 사항은 파란색
- Algorithm 1 Bit Diffusion training algorithm
def train_loss(x):
# Binary encoding: discrete to analog bits.
x_bits = int2bit(x).astype(float)
x_bits = (x_bits * 2 - 1) * scale
# Corrupt data.
t = uniform(0, 1)
eps = normal(mean=0, std=1)
x_crpt = sqrt(gamma(t)) * x_bits +
sqrt(1 - gamma(t)) * eps
# Compute self-cond estimate.
x_pred = zeros_like(x_crpt)
if self_cond and uniform(0, 1) > 0.5:
x_pred = net(cat([x_crpt, x_pred], -1), t)
x_pred = stop_gradient(x_pred)
# Predict and compute loss.
x_pred = net(cat([x_crpt, x_pred], -1), t)
loss = (x_pred - x_bits)**2
return loss.mean() - Algorithm 2 Bit Diffusion sampling algorithm
def generate(steps, td=0):
x_t = normal(mean=0, std=1)
x_pred = zeros_like(x_t)
for step in range(steps):
# Get time for current and next states.
t_now = 1 - step / steps
t_next = max(1 - (step+1+td) / steps, 0)
# Predict x_0.
if not self_cond:
x_pred = zeros_like(x_t)
x_pred = net(cat([x_t,x_pred],-1), t_now)
# Estimate x at t_next.
x_t = ddim_or_ddpm_step(
x_t, x_pred, t_now, t_next)
# Binary decoding to discrete data.
return bit2int(x_pred > 0)표준 확산 모델과 달리 최대 유연성을 위해 고정 이산 시간 대신 0과 1 사이의 연속 시간 매개 변수 화를 사용하여 유사하게 수행된다.
Experiment
해당 부분에서는 두 가지 다른 이산 데이터 생성 작업, 즉 이산/범주 이미지 생성과 이미지 캡션을 실험
Experimental Setup and Impletentation Detail
Dataset
본 논문은 이미지 생성 실험에 CIFAR10과 Imagenet 64x64를 사용하였다.
평가 지표로는 FID를 주요 평가 지표로 채택 하였으며, 생성된 샘플 50K와 전체 훈련 세트 사이에서 계산 된다. 이미지 캡션의 경우 MS-COCO 캡션 데이터 세트를 사용하였다.
Binary encoding
각 화소는 3개의 서브픽셀(RGB채널)로 구성되며 0~256의 정수로 이루어져 있다. 표준 연속 생성 모델은 RGB채널을 실수로 캐스팅 하고 [-1.1]로 정규화 한다. 이산 이미지의 경우 하위 픽셀에 대한 이산 인코딩을 고려한다.(UNIT8, GRAYCODE 및 UINT8(RAND))
본 논문은 UINT8로 사용하며, 인접한 두 정수가 1비트만 차이 나도록 하위 픽셀 정수에 8비트 이진 코드를 고유하게 할당
그리고 UINT8(RAND)에서 UINT8의 정수 대 비트 매핑을 무작위로 섞음으로써 모든 하위 픽셀 정수에 8비트 이진 코드를 할당한다.
UINT8과 GRAYCODE의 이진 코드는 원래 하위 픽셀 강도와 약하게 상관 되어 있지만 UINT8(RAND)와는 상관 관계가 없으므로, 각 하위 픽셀은 범주형 변수이다.
아날로그 비ㅡ에 대해 이진 비트를 0,1에서 01,1로 이동가ㅗ 스케일을 조정한다..
이미지 캡션의 경우 32K의 크기의 어휘를 가진 문장 조각을 사용하여 캡션을 토큰화 한다.
토큰화 후 우리는 정수에서 변환된 이진코드를 사용하여 각 토큰을 15개의 아날로그 비트로 인코딩한다. 토큰의 최대 수를 64로 설정하여 총 시퀀스 길이는 960비트이다.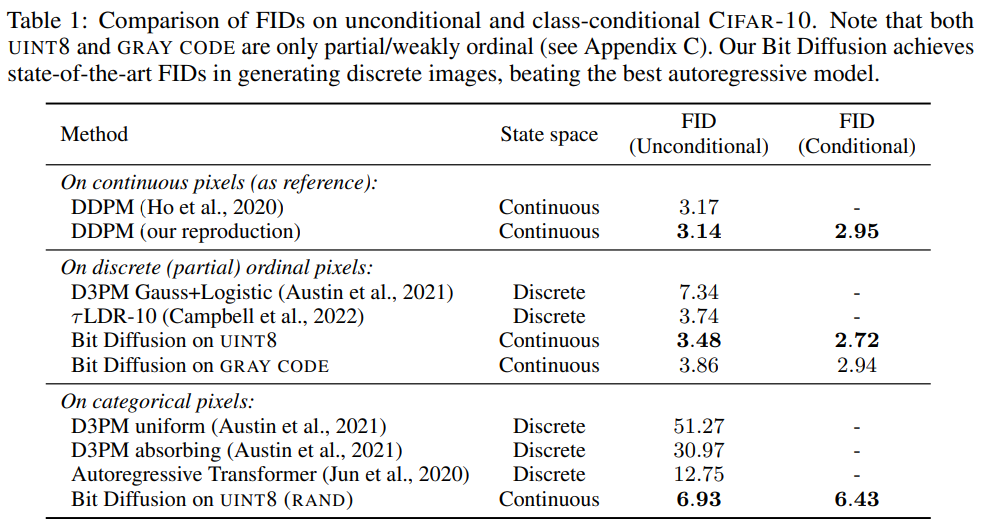

Architecture
이미지 생성을 위해 U-Net 아키텍처를 사용
CIFAR10의 경우 51M 파라미터를 가진 256,3 단계 및 3개의 Residual blck의 단일 채널 차원을 사용한다. 본 논문은 CIFAR-10의 연속 확산 모델에 대해 0.3 드롭아웃만 사용한다.
Imagenet 64x64의 경우 4단계에서 1,2,3,4를 곱한 192의 차원 채널을 기본으로 사용 했으며, stage당 3개의 residual bolck을 사용한다. 이는 총 240M 매개변수를 차지한다.
UINT(RAND) 인코딩의 경우 최종 출력 계층에서 Softmax factorization 아키텍처 수정이 더 나은 성능으로 이어지는 것을 발견 하였으며, 선형 출력 레이어를 사용하여 아날로그 비트를 예측하는 것이 아닌 하위 픽셀당 256개 클래스 이상의 확률 분포를 예측한 뒤 256개의 서로 다른 모든 8비트 코드에 대한 가중 평균을 취하여 클래스 분포를 아날로그 비트에 매핑한다.
이미지 캡션의 경우 제안된 방법 + autoregressive baseline 모두에 대해 객체 감지 작업을 사용하여 사전 훈련된 이미지 인코더를 사용하는 아키텍처를 다른다. 두 디코더는 무작위로 초기화된 6 layer transformer decoder로 layer당 512개의 치수를 가지고 있다.
autoregressive decoder의 경우 token attention metrix는 causal masks에 의해 상쇄 되지만 비트 확산에 대한 전체 주의는 마스킹 되지 않는다.
Other settings
Adam optimizer를 사용
- CIFAR10의 경우 0.0001의 지속적인 학습률과 128의 배치 크기 150만 단계의 모델에 대한 훈련
- Imagenet 64x64의 경우 0.00024의 학습률과 1024의 배치 크기 500K 단계에 대한 모델 훈련
- bit Diffusion의 경우 자체 조절된 학습률을 사용하며, 0.9999 decay factor로 훈련 중 가중치 지수이동 평균을 사용한다.
본 논문에서는 step의 변화를 100, 250, 400, 1000의 샘플링 단계 및 0.01, 0.1, 0.2, 0.5의 time difference를 조절한다.
Discrete Image Generation
Table1에서 이산 CIFAR10 이미지를 생성할 때 모델은 기존의 이산 확산 모델과 SOTA 모델과 비교하여 더 나은 결과를 얻었다.
DDPM과 비교시에 UINT8과 GRAYCODE의 비트 확산 모델은 유사한 성능을 달성하였다.
Imagenet 64x64의 이산 생성은 CIFAR10에 비해 어렵고 FID가 있는 다른 방법이 없어 DDPM과 비교만 되었다.
UINT8(RAND)의 확산 모델이 FID가 가장 나쁘며, 연속 픽셀 확산 모델이 FID가 좋은 것을 발견하였는데 이는 하위 픽셀에서 강도/순서 정보를 제거할때 경도가 증가했음을 나타낸다.

Ablation of Self-Conditioning
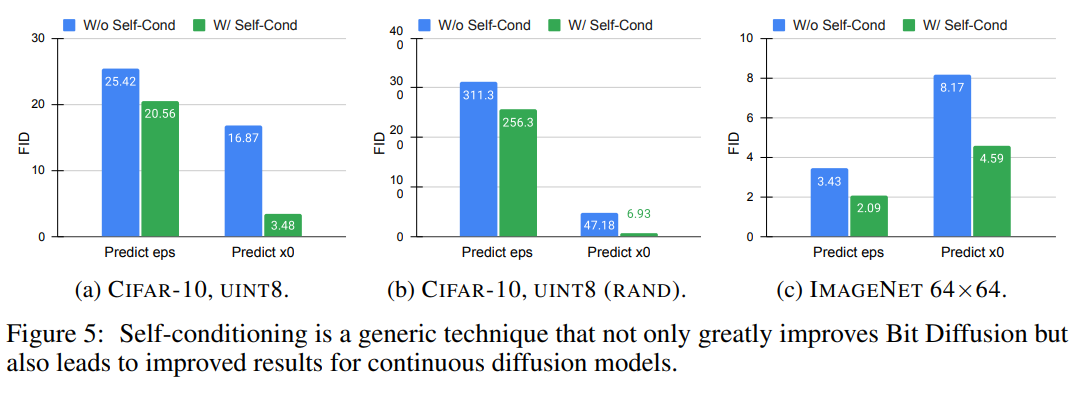
그림 5는 비트 확산 및 연속 확산 모델 모두 self-conditioning 기법의 효과를 보여준다.
CIFAR10의 경우 self-conditioning이 다른 이진 인코딩에서 성능을 크게 향상 시키는것을 발견
bit diffusion의 경우 를 예측하는 것이 을 예측 하는 것보다 더 효과적인 것을 발견
Imagenet 64x64의 경우 self-conditioning은 지속적인 diffusion을 위한 FID의 개선으로도 이어진다. 따라서 본 논문은 Self-conditioning이 연속 및 이산 데이터 모두에서 확산 모델에 도움을 주는 일반적인 기술이라 결론
Ablation of asymmetric time intervals
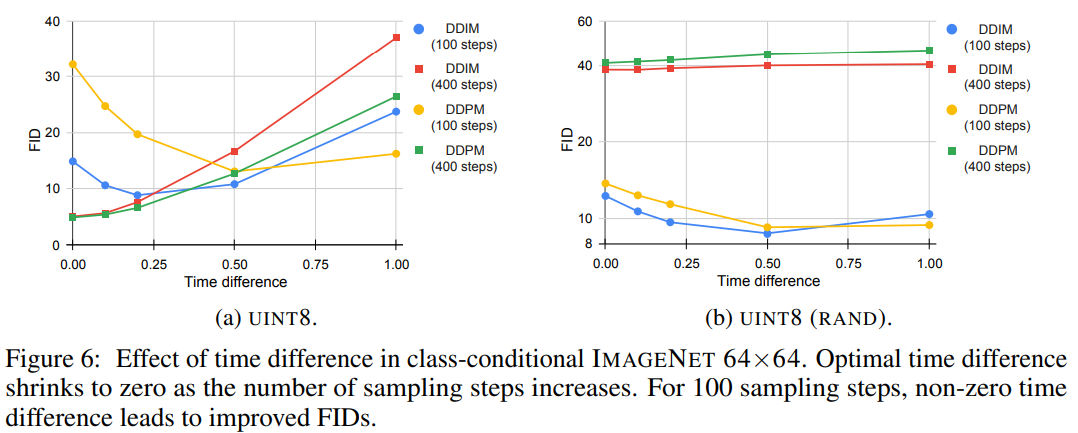
그림 6은 sampling process동안 asymmetric time intervals을 변경할때 생성된 Imagenet 64x64 샘플의 FID를 보여준다.
단계가 증가함에 따라 시간차이가 0으로 감소하며, 100단계의 경우 0이아닌 시간차이는 FID의 상당한 향상으로 이어졌다.
UINT8(RAND)의 비트 확산의 경우 400개의 Sampling process를 사용하는 것이 100 단계를 사용하는 것보다 더 나쁜 품질로 이어 졌다.
이러한 결과는 Self-conditioning이 적용되는 방법과 관련이 있음을 가르쳐준다.
Concentration of generated analog bits
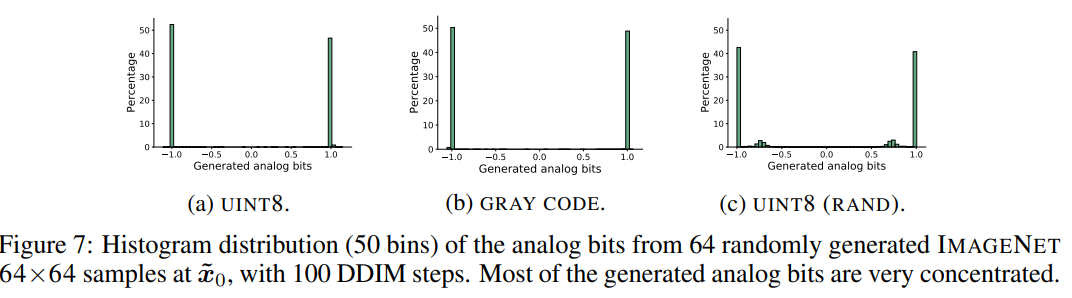
그림 7은 Imagenet 64x64에서 생성된 64개의 이미지에서 생성된 아날로그 비트 분포를 시각화 한것이다.
아날로그 비트가 binary/bimodal이 되는 것에 대한 제약은 없으나 두 가지 모드에 매우 집중 되어 있기에 thresholding/quantization을 쉽고 강하게 한다.
IMAGE CAPTIONING
해당 부분에서는 bit diffusion model 과 autoregressive transformermodel을 비교한다.
두 모델 모두 유사한 아키텍처를 가지고 있다
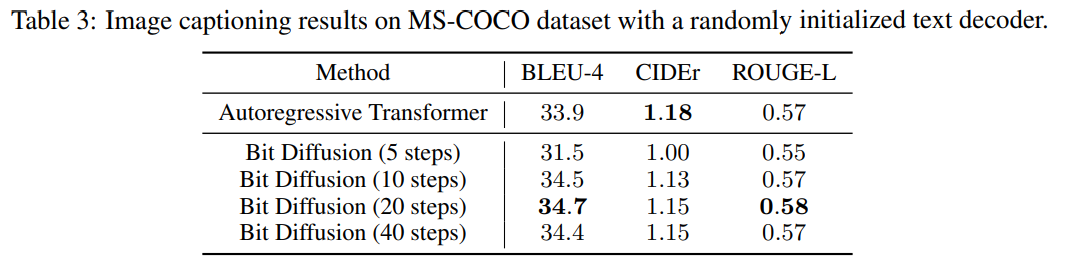
표3을 보면 전체적으로 Autoregressive model과 비슷한 성능이 나온다.
최대 960비트 까지 있음에도 10단계만 수행하면 좋은 결과가 나오는 것을 발견
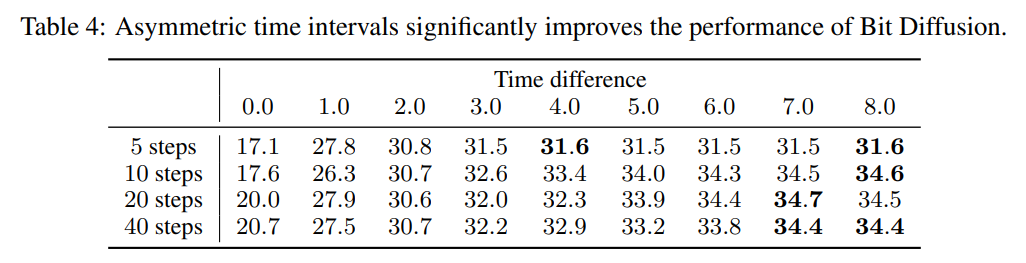
표4를 보면 asymmetric time intervals이 sampling 단계가 적을때 모델의 최고 성능에 중요한 역할을 하는 것을 발견하였다.

표 5는 서로 다른 추론 단계가 사용될 때 생성된 모델의 몇가지 샘플을 제공한다. 모델은 샘플링 단계가 너무 적을때 실수를 범하며, 모델이 토큰화된 단어 조각 뒤의 비트를 직접 예측하고 비트의 작은 차이가 완전히 다른 단어로 이어질 수 있기 때문에 실수가 항상 해석 가능하지 않을 수 있다.
RELATED WORK
Autoregressive models for discrete data
autoregressive model은 이산 데이터 생성과 관련하여 SOTA결과를 보여 주었다. 특히 텍스트 생성과 같은 언어 모델링의 경우 autoregressive 접근 법에 의해 지배 된다. 이는 이산/범주 이미지 생성에도 적용 되는 것을 알 수 있다. 이러한 autoregressive model작은 이미지에서도 잘 동작하는 것을 보여준다. 하지만 시퀀스 또는 이미지의 해상도가 증가함에 따라 메모리 요구 사항은 급격하게 증가하여, 큰 차원의 데이터로 확장하는 것은 매우 어렵다.
Diffusion models for discrete data
SOTA Diffusion모델은 이산 또는 범주형 데이터를 생성할 수 없다. 이산 데이터에 대한 연속 Diffusion 모델의 기존 확장은 이산 데이터 공간과 상태 공간 모두 기반으로 한다. 이산 상태 공간에 비해 연속 상태 공간은 더 유연하고 잠재적으로 더 효율적이다.
본 논문의 접근 방식은 이산 시간과 연속 시간 모두 호환되며, 기존 연속 모델의 재구성을 필요로 하지 않기에 더 단순하고 광범위한 생성 모델군으로 연결 가능하다.
(기존에는 연속적인것만 되었지만, 본 논문을 적용하면 이산적인 것 까지 가능하므로)
이산 확산 모델의 또 다른 라인은 이산 데이터의 임베딩을 기반으로 하며, 아날로그 비트를 사용한 이진 인코딩을 간단한 고정 인코더로 간주 할 수 있으며, bimodal 아날로그 비트의 decoding/quantization는 간단한 임계값 작업을 통해 쉽고 강력하다. 대조적으로 생성된 연속 임베딩 벡터에서 실수의 양자화는 차원당 여러 모드를 포함 할 수 있어 thresholding/quantization의 잠재적 어려움을 초래할 수 있다.
Normalizing Flows for discrete data
정규화 흐름은 일부 가역 매핑을 기반으로 하는 고차원 연속 분포에 대한 강력한 생성 모델계열이다. 그러나 범주형 데이터에 대한 흐름 기반 모델의 직접적인 적용은 이산 지원에 대한 고유한 과제로 인해 제한 된다. 이산 흐름은 야코비안 로그 결정 요인을 계산할 필요 없이 이산 공간에서 임의 변수의 가역적 변환을 도입한다.
다른 연구들의 경우 이산 데이터를 분리 지원을 통해 연속 공간으로 변화하기 위한 임베딩 방법을 소개한다. 또는 사전에 이산데이터를 풍부하게 하여 프레임 워크에 따른 이산 데이터의 흐름을 정규화 하는 것을 탐구한다.
이러한 모델은 본 논문의 접근 방식과 비교하여 엄격한 가역적 제한으로 인해 용량이 제한 된다.
Other generative models for discrete data
VAE, GAN과 같은 다른 생성 모델도 이산 데이터를 생성하기 위해 적용 되었다.
이런 방법들은 샘플 품질 또는 데이터 가능성 측면에서 이산 이미지 생성 또는 텍스트 생성과 같은 작업에서 Autoregressive model로서의 성능을 달성하지 못했다.
본 논문에서 제안된 아날로그 비트는 네트워크가 직접 아날로그 비트를 모델링하고 생성하도록 하여, 연속 생성에 적용할 수 있지만, 이 연구에서는 탐구 되지 않는다.
Other related work
Self-conditioning 기법은 GANs(초기 잠재 상태가 이후 잠재 상태를 직접 조절하는 경우) 및 SUNDAY(노이즈 제거를 위해 추론 단계가 통합된 경우)의 자가 조절과 몇가지 유사한 점을 공유한다.
Conclusion
연속적인 상태 확산 모델을 가능하게하는 간단하고 일반적인 기술을 본 논문에서 소개 했따.
주요 아이디어
- 이산 또는 범주형 데이터를 비트로 인코딩 -> 비트를 아날로그 비트라 하는 실제 숫자로 모델링
본 논문은 또한 샘플 품질을 향상시키는 두 가지 간단한 기술인 Self-conditioing과 Asymmetric Time Intervals를 제안하였다.
MS-COCO데이터 셋에 대한 이미지 조건부 텍스트 생성 작업에서 Autoregressive model 과 비교하여 경쟁력 있는 결과를 얻었다.
하지만 본 논문에서 제안된 방식에 한계가 존재하며, 한계는 이미지 생성을 위해 상당한 수의 추론 단계가 필요하다는 것이다. 그러나 연속 데이터에 대한 확산 모델의 향후 개선 사항은 아날로그 비트를 사용하는 이산 데이터로도 전송될 것으로 기대한다.
즉 diffusion model의 개선 방안은 본 논문에서 제안된 방법에도 적용 될 것으로 기대한다는 뜻
