본 논문은 Microsoft에서 21년도에 만든 논문입니다.
LORA 논문이 가지는 의의는 현재 LLM이 유행하고, 더 커지고 있으면서 이를 Fine-Tuning 하는데 많은 하드웨어 자원이 소모가 되고 있다. 하지만 모든 parameter를 학습하는 것이 아닌 소수의 parameter만 tuning 하여 성능을 낼 수 있다는 측면에서 LORA 논문은 그 의의를 가진다.
Abstract
사전훈련된 모델 가중치를 동결하고 Transformer 아키텍처의 각 layer에 훈련 가능한 rank decomposition matrices를 주입하여 downstream을 줄이는 LORA방법을 제안하였다고 한다.
이를 통하여 GPT-3에 trainable parameter를 10000배, GPU 메모리 요구량을 3배 줄일 수 있게 되었다.
Introduction
자연어처리 분야에서 Fine-tuning은 모든 parameter를 업데이트 하는 과정을 통해서 진행이 되었다.
하지만 Fine-tuning의 큰 문제점은 원래의 모델과 새 모델은 동일한 수의 매개 변수가 포함이 되어 있다는 것(학습하는데 필요한 매개변수가 많다는 것을 의미)
학습량이 많은 문제를 개선하기 위해 일부 매개변수만 적용하거나 외부 모듈을 사용
-> 운영 효율성은 올라갔으나, 깊이가 확장되거나 sequence 길이가 줄어드는 등의 문제 발생
더 큰 문제는 모델 품질과 효율성의 불균형을 초래
LORA는 가중치의 변화는 낮은 intrinsic rank를 가지고 있어 제안된 LORA 접근법으로 이어진다고 가정 하였다. 이를 바탕으로 LORA는 Figure 1과 같이 pretrained 가중치를 동결하고, 대신 조밀한 계층의 변화의 rank 분해 행렬을 최적화 하여 간접적인 훈련을 하였다.
(본래의 모델의 rank가 high 하더라도 낮은 rank의 값만으로도 성능을 낼 수 있다.)
- LORA의 장점
- 사전훈련된 모델을 공유하고 다양한 작업을 위한 LORA 모델을 구축하는데 사용 가능
-> storage 요구사항과 작업전환 overhead를 크게 감소 - LORA는 대부분의 매개 변수에 대해 gradient 계산이 불필요 하여, 훈련을 효율화 한다.
- 간단한 선형 설계를 사용하면 구축에 의해 완전히 미세 조정된 모델에 비해 추론 대기 시간을 도입하지 않고 고정된 가중치와 병합 가능하다.
- 이전의 많은 방법과 orthogonal 하여 접두사 조정과 같은 많은 방법과 결합 가능하다.
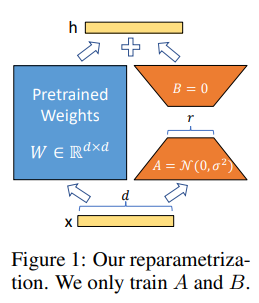
본 논문에서는 를 사용하며, 각각읜 query, key, value, output의 가중치를 의미한다. 그리고 W 혹은 W0는 사전훈련된 가중치를 의미하며, 는 축적되는 기울기 업데이트에 대한 값을 의미한다.
모델의 최적화를 위해 activation은 Adam을 사용하였으며 Transformer MLP ff 계층의 차원은
를 사용하였다.
Problem statement
LORA 방법은 훈련 목표에 구애가 없지만, 사례로 언어 모델링에 중점을 두었다.
아래는 논문을 설명하기 위한 값들에 대한 설명이다.
- 사전학습된 모델(논문에서는 GPT라고 한 부분)
- 파라미터를 최적화 하는 수식1
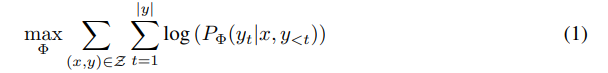
- 수식1이 전체 파라미터를 학습하는데 사용하는 식이라면, 파라미터 중 일부만을 학습하여 갱신하는 수식2
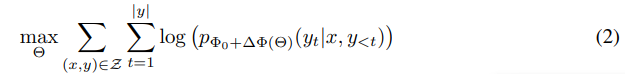
AREN’T EXISTING SOLUTIONS GOOD ENOUGH?
기존 방식의 문제점
- adapter layer에 추론 지연시간이 발생
- Prompt를 직접 최적화 하는 것은 어렵다.
아래의 이미지는 추론 대기시간은 짧은 sequence 길이 시나리오에서 상당히 큰 것을 의미한다.

Method
LORA 논문에서 제시하는 LORA의 방법에 대한 설명이 나와 있는 부분(핵심)
1. Pre-trained weight 행렬인 가 차원을 가진다고 가정
2. 를 row rank를 이용하여 로 나타낼 수 있다.
3. 로 업데이트 제한
4. 3.을 통해 는 gradient 갱신을 하지않고 를 학습한다.
- 를 로 scale하는 부분은 를 튜닝하는 것은 학습률을 튜닝하는 것과 같고, 를 첫번째 로 설정하고 조정하지 않는다.
-
A Generalization of Full Fine-tuning.
-> 훈련가능한 매개변수의 수를 늘리면, LORA는 원래 모델 훈련으로 수렴되며, Adapter 기반 훈련은 MLP 및 접두사 기반 방법으로 수렴되어 입력 sequence를 취할 수 없게끔 수렴된다. -
No Additional Inference Latency
에 배치가 되면 를 이용하여 계산 하되, 다른 작업으로 전환시 기존의 를 제거하고 다른 를 추가하여 를 복구 할 수 있다.
-> overhead가 거의 없게 된다.
APPLYING LORA TO TRANSFORMER
LORA를 트랜스포머에 적용할때는 다음과 같다
1. 를 d차원 모델의 단일 행렬로 취급하여 adapting한다.
2. attention weight만 가중치를 적용하고 MLP 모듈은 동결
위의 과정을 통해얻는 이점과 한계
이점은 freezing 된부분에 대해 저장할 필요가 없어 Vram 사용량이 이 감소하였으며, 대부분의 매개변수에 대해 학습이 불필요하여 학습시간 증가
- VRAM사용량 감소(최대 )
- 학습 시간 향상(약 25%)
한계점
- A와 B를 W로 흡수하게 될 경 A와 B가 다른 작업에 대한 입력을 배치하는 것이 간단하지 않다.
- 대기 시간이 중요하지 않은 시나리오의 경우 배치에서 샘플에 사용할 LORA 모듈을 동적으로 선택 할 수 있다.
EMPIRICAL EXPERIMENTS
논문에서는 RoBERTa, DeBERTa, GPT2에서 downstream 작업을 평가 하였다.
각각의 방법에 대한 소개
-
FineTuning : 가장 일반적인 방식이자 모델의 모든 매개변수가 Gradient update를 하는 방법과 일부 layer만 update하는 방법 2가지로 나누어진다.
-
Bias-only or BitFit : 다른 모든걸 동결하면서 bias vector만 훈련하는 방법
-
Prefix-embedding tuning(PreEmbed) : input token에 special token lp와 li를 주입 시키며 이 speical toekn은 word embedding을 가지고 model vocab에는 포함되어 있지 않다. 이런 special token을 배치하는 위치는 성능에 영향을 주며, prefixing에 초점을 맞춰 prompt에 토큰을 배치하고 infixing 하여 prompt에 추가하는 방식이다.
-
Prefix-layer tunning(PreLayer): Prefix-embedding tuning방법의 확장이다. 일부 special token에 대한 word embedding 이나 embedding layer 다음 activation만 학습하는게 아닌 모든 트랜스포머 layer 이후 activation을 학습한다.
훈련 가능한 매개변수의 수는 다음과 같다 -
Adapter tuning : self attention module과 residual connection 모듈 사이에 adapter를 삽입한다. 이에 대해 방법이 여러가지가 존재하는데
-> AdapterH : 중간에 비선형성이 있는 Adapter Layer에는 bias를 가진 2개의 완전연결계층이 있는 것
-> AdapterP : MLP module 이후 및 LayerNorm 이후에만 Adapter layer를 적용하여 보다 효율적인 설계
-> AdapterL : 일부 Adapter layer를 삭제하는 Adapter Drop을 포함한 방법 -
LORA : 논문에서 제안한 방식 기존 weight 행렬과 병렬하게 훈련 가능한 rank decomposition 행렬 쌍을 추가한다. 단순성을 위해 LORA를 및 에만 적용
훈련 가능한 매개 변수의 수는 다음과 같다. 은 LORA를 적용하는 가중치 행렬의 수
실험 결과
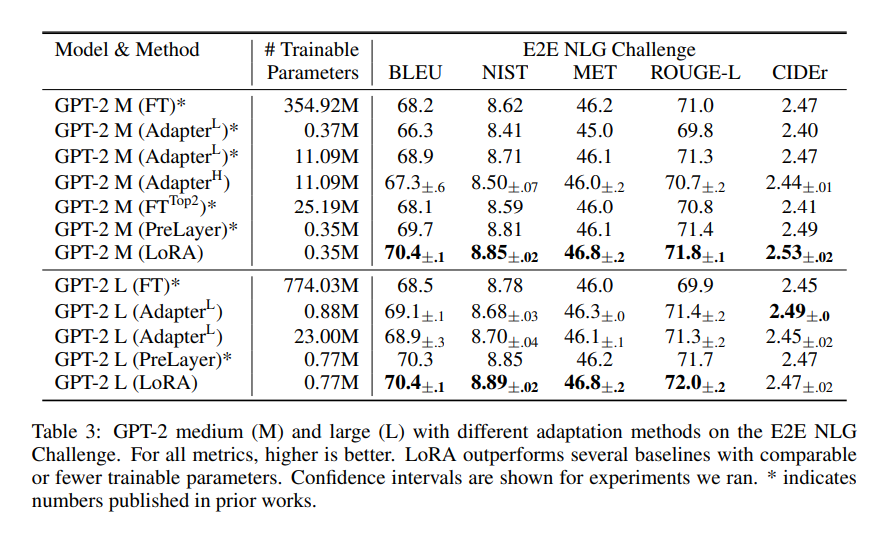
GPT2에 대한 실험결과
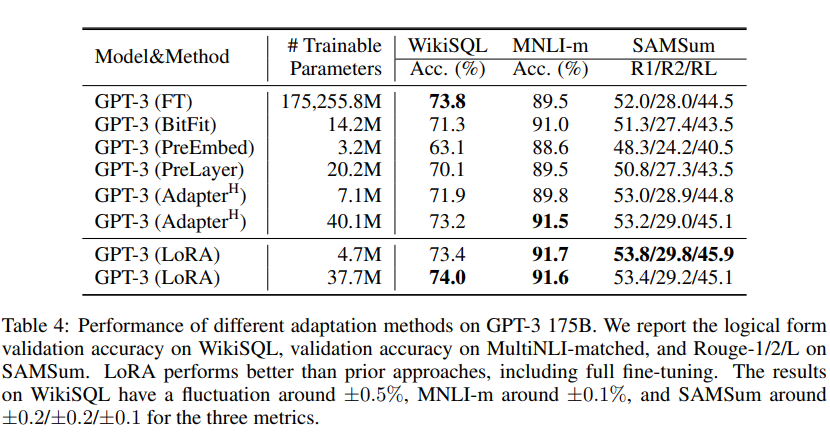
GPT3에 대한 실험 결과
Relation Work
Understading the low-rank update
LORA는 Downstream작업에서 학습한 low rank adaptation의 특성을 병렬로 실행 할 수 있게하여 하드웨어 장벽을 낮출 뿐만 아니라 업데이트 가중치가 사전 훈련된 가중치와 어떠한 상관관계가 있는지 해석 가능성을 제공한다.
-
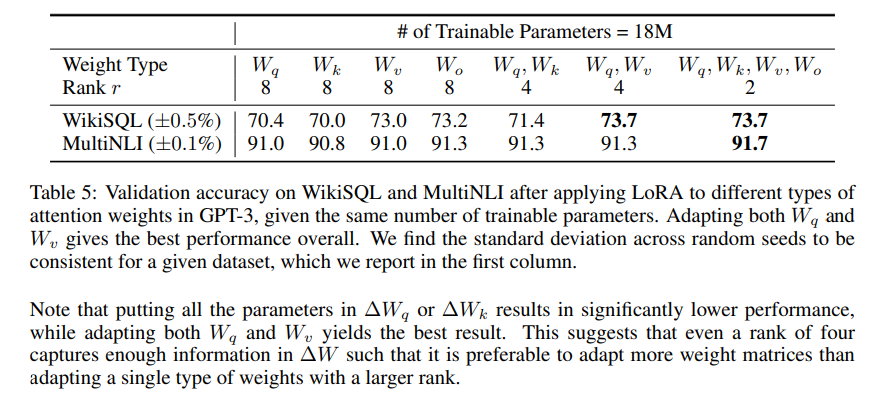
어떠한 가중치 행렬을 LORA에 적용을 해야 하는가?
-> self attention 모듈에서만 weight 행렬을 고려한다.
-> 모든 매개변수를 하는 것 보다 를 사용하는 것이 성능이 좋다. 최고의 성능을 가지는 것은 를 사용하는 것이다.
-> rank가 4인 경우에도 에서 충분한 정보를 가져오므로 rank가 큰 단일 유형보다 더 많은 가중치 행렬을 사용하는게 좋다는 것을 의미한다.
-
LORA의 최적화를 위한 rank는 무엇인가?
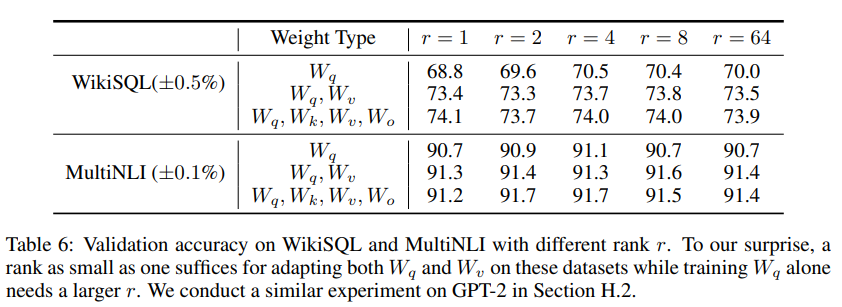
Table 6는 LORA가 매우 작은 r로도 성능이 좋다는 것을 보여준다. 뿐만 아니라 r이 커진다고 해서 더 의미 있는 subspace를 커버하지 않는 다는 것도 보여주고 있다. -
r의 크기와 subspace의 유사성
아래의 수식은 rank 8과 64로 학습한 adaptation 행렬을 singular value decomposition 해서 얻은 right singular unitary 행렬을 얻는다.
해당 행렬에서 top i singular vector에 의해 얼마나 많은 subspace가 span되는지 Grassmann 거리 기반 normalized subspace 유사도를 정량화하여 측정한다.
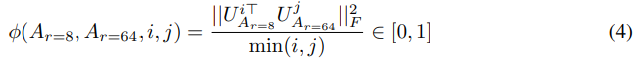
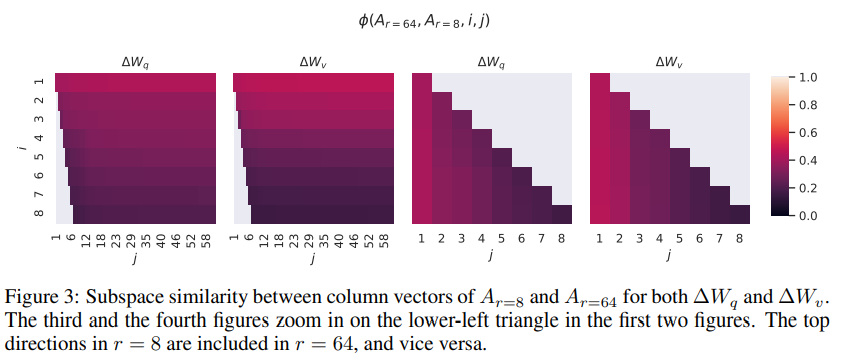
이를 통해 알 수 있는 것은 r=8인 경우와 64인 경우 top singular vector의 방향은 상당히 중첩되지만 다른 방향은 그러지 못했다. 다른 방향의 경우 훈련 중에 무작위 noise가 들어가게 되었다. 이를통해 adaptation matrix가 매우 low rank를 가질 수 있음을 보여준다
Adaptation 행렬과 기존 weight 행렬의 비교

Table 7을 통해 알 수 있는 것
1. 는 랜덤 행렬에 비해 W와 상관 관계가 강하며 가 이미 W에 있는 일부 특징을 증폭시킨다.
2. W의 top singular 방향을 반복하는 대신 는 W에서 강조되지 않는 방향만 증폭 시킨다.
3. r =4인경우 r=64인 경우보다 증폭률이 크다.
이를 종합하면 low rand adaptation 행렬이 학습 되었지만 일반적인 사전 훈련 모델에서 강조되지 않은 특정한 downstream에 대해 중요한 특징이 강화되었음을 알 수 있다.
잘못된 부분 있으면 가르쳐주시면 감사합니다
