논문의 링크: 논문 링크
논문의 open source 링크 : github link
Abstract
Inductive(귀납적) 전이학습은 cv에 큰 영향을 미쳤으나 자연어 처리 영역에서는 못하였다.
NLP에서는 작업별 수정 및 처음부터 훈련이 필요하였다.
-> 이는 매우 비효율적이기에 본 논문에서는 모든 작업에 적용할 수 있는 전이학습 방법인 ULMFiT(Universal Language Model Fine-tuning)을 제안
-> 적은 데이터만을 사용해도 충분한 성능이 나온다.
Introduction
Inductive transfer learning은 cv에 큰 영향을 미쳤으며, 사전 훈련된 모델을 바탕으로 Fine-tuning을 하게 된다.
-> CV영역에선 대부분 Fine-tuning을 이용하여 사전학습 모델을 조정한다.
deep learning 모델들은 많은 NLP 영역에서 SOTA를 달성하였지만, 모두 처음부터 훈련하여 대규모 데이터 셋과 수렴하는데 며칠이 소모되었다.
NLP 영역에서는 주로 transductive transfer 방법에 초점이 맞춰져 있었다.
Inductive transfer에서는 사전학습된 word embedding은 성능이 좋아 SOTA 모델에서 자주 사용되었다.
하지만 처음부터 훈련하는 것은 여전하였으며, Fine-tuning을 통한 transfer 방법은 NLP에서 실패하였다.
LM은 작은 데이터셋에 과적합이 되어 fotgetting 문제가 발생할 뿐만 아니라 CV에 비해 NLP 모델이 일반적으로 얕기 때문에 다른 미세조정 방법이 필요하다.
본 논문에서 제안하는 ULMFiT는 NLP문제에 안정적인 Inductive transfer learning 방법을 보여준다.
- 요약
-> cv와 달리 nlp는 Inductive transfer learning이 어렵다.
-> lm은 작은 데이터셋으로 인하여 과적합 및 forgetting 문제가 발생한다.
-> cv와 다른 미세조정 방법이 필요하다.
contributions
- NLP 작업에 대해 CV와 같은 전이학습을 달성하는데 사용하는 방법 ULMFiT를 제안
- discriminative fine-tuning, slanted triangular learning rates, and gradual unfreezing를 제안하며, 미세 조정 중의 forgetting 문제를 방지한다.
- 6개의 대표적인 텍스트 분류 데이터셋에서 SOTA를 크게 능가하며 18~24%의 error reduction을 보였다,.
- 매우 효율적인 전이 학습이 가능할 뿐만 아니라 extensive ablation analysis을 수행한다.
- 사전 훈련된 모델과 코드를 사용하여 더 광범위 하게 사용 가능하다.
Related work
CV에서 전이학습
첫번째 layer에서 마지막 layer로 진행 될때 일반적인 작업에서 개별적 작업으로 전환 된다 -> model의 첫번째 layer를 transfer 하는데 초점을 둔다.
-> cv에서 기존 모델을 그대로 유지하고, 마지막 layer만 학습을 하는 방법으로 대체되었다.
Hypercolumns
다른 작업을 통해 사전훈련된 embedding을 가져온다 -> 다른 작업에서의 embedding은 단어 임베딩 또는 중간 layer의 입력으로 사용
-> 이러한 과정을 통하여 추가적인 context를 얻게 된다.
-> CV에서는 end2end fine-tuning에 밀려서 대체되었다.
Multi-task learning
주요 작업 모델과 공동으로 훈련된 모델에 언어 모델링 목표를 추가하는 방법(기존 모델에 다른 언어모델을 추가하여 결합 학습이 되는 방식)
-> 매번 처음부터 훈련해야 하므로 비효율적이며, 작업별 신중한 weight가 필요
Fine-tuning
언어 모델을 미세 조정할때 관련 있는 작업은 성공, 관련 없으면 실패 하였으며, 미세 조정을 하여 좋은 성능을 내기 위해서는 수백만 개의 도메인 내 문서가 필요하다.
-> 논문에서 제안하는 ULMFiT는 100개의 레이블이 지정된 예제로도 과적합을 피하고 작은 데이터 셋으로 SOTA성능을 달성한다.
Universal Language Model Fine-tuning
ULMFiT 방법
Large domain dataset을 이용하여 pretrain을 진행하여 target work에 대해 fine-tuning하는 방법
ULMFiT의 특징
1. 문서 크기, 수 및 레이블 유형이 다양한 작업 간에 작동
2. 단일 아키텍처 및 교육 프로세스를 사용
3. 사용자 지정 기능 엔지니어링 또는 전처리가 불필요
4. 추가적인 도메인 내 문서 또는 레이블이 필요하지 않다는 점
실험에서 다양한 dropout, hyper parameter 변수가 있는 LSTM인 AWD-LSTM을 사용
ULMFiT의 단계
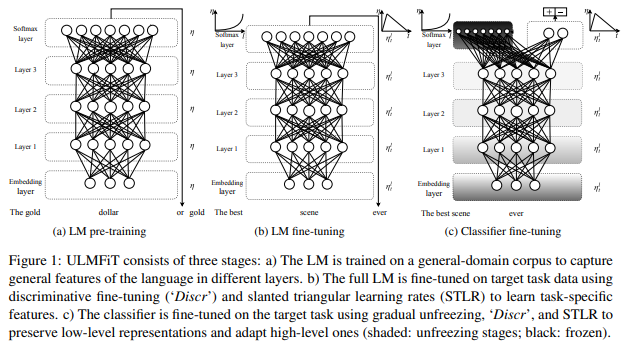
1. 일반 도메인 LM pretrain
2. 대상 작업 LM의 fine-tuning
3. 대상 task fine-tuning
Target task LM fine-tuning
사전 훈련된 도메인 데이터가 다양하더라도 대상 작업의 데이터는 다른 분포에서 나올 가능성이 높다. -> Fine-tuning이 필요
일반적인 task에서 대상 task에만 적응하면 되기 대문에 빠르게 수렴(적은 데이터셋에도 적용가능)
Discriminative fine-tuning
서로 다른 layer가 서로 다른 type의 정보를 가진다.
-> 이러한 이유로 동일한 학습률을 이용하는게 아닌 Discriminative fine-tuning 방법을 이용해서 각 계층이 서로 다른 학습률을 가져야 한다.
t에서 model parameter 의 정규 SGD update 수식은 다음과 같다
이를 개선한 Discriminative fine-tuning 방법을 적용하면 수식은 다음과 같다.
논문에서는 마지막 layer만 fine-tuning하고 하위 계층에 대한 학습 률을 이전 layer/2.6으로 할때 성능이 잘나온다고 한다
Slanted triangular learning rates
train 초기에 parameter space를 적절한 값으로 빠르게 수렴한 뒤에 hyperparameter를 세분화 한다.
훈련시 동일 학습률 또는 annealed한 학습 률을 사용하는 건 가장 좋은 방법 X
-> slanted triangular learning rates(STLR)를 제안
- slanted triangular learning rates
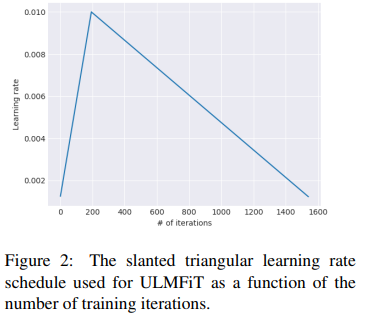
-> 학습률을 선형적으로 증가 시킨 뒤 다음 update일정에 따라 선형적으로 감소하는 방법 수식은 아래와 같다.

-> 변수 설명
: 반복횟수 : Learning Rate를 증가시키는 반복함수
: 학습률이 증가에서 감소로 전환할때의 반복
는 각각의 학습률이 증가 또는 감소시키는 반복 횟수
: LR µmax에서 가장 낮은 학습률이 얼마나 작은지를 지정
: 반복 t에서의 학습속도
Target task classifier fine-tuning
classifier의 fine tuning을 하기 위해 사전 훈련된 언어 모델을 두개의 linear block으로 보강
각 block은 drop out, batch normalization을 사용하며 중간 계층에 대한 ReLU activation funcition과 마지막 layer에는 softmax를 사용한다.
-> classifier의 parameter는 처음부터 학습되는 유일한 매개변수 이다.
Concat pooling
GPU 메모리 적합한 만큼 time에 걸쳐 마지막 단계 hT에서 hidden state의 max pool과 mean pool을 모두 연결한다.
- fine-tuning을 할때 주의할점
-> 지나치게 공격적으로 하면 언어 모델링을 통해 캡쳐된 정보의 이점이 제거된다
-> 너무 신중하게 하면 학습속도가 느려진다(결과적으로는 과적합)
Gradual unfreezing
모든 계층을 fine-tuning 하는것이 아닌 last layer 부터 점진 적으로 model의 layer를 unfreezing 하는 것
-> 모든 계층은 가장 일반적인 지식을 포함하기 때문에 이를 유지하기 위해서 제안한것 : 결론적으로는 잘 된다.
BPTT for Text Classification (BPT3C)
언어 모델들은 일반적으로 BPT(back propagation through time)을 사용하지만 논문에서는 BPT3C를 제안
(일반적인 bptt를 사용하게 될 경우 sequence lenth가 길 경우 문제가 생긴다)
1. batch의 크기를지정
2. 이전 batch의 final state가 다음 batch의 초기 상태
3. mean or max polling으로 hidden state를 추적
4. gradient가 hidden state가 최종 예측에 기여한 batch로 역전파
Bidirectional language model
backward, forward 모두 이용(각각 독립적으로 학습)
각각이 값을 평균 시켜 최종 분류로 사용
Experiments
Datasets and tasks
Experimental setup
문서의 길이가 다양한 6개의 데이터셋을 사용
-
dataset
Sentiment Anlaysis : 영화리뷰 IMDB데이터 세트 및 Yelp 리뷰 데이터셋을 사용
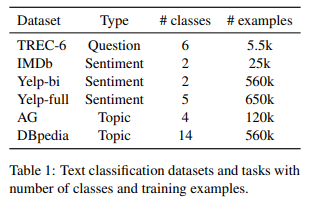
Question Classification : 괌범위한 의미 범주로 분할된 도메인 기반 TEC 데이터셋 사용
Topic classification : 대규모 AG 뉴스 및 DBpedia 온톨로지 데이터셋을 사용 -
Pre-processing
전처리는 이전과 동일한전처리를 사용, 분류와 관련될 수 있는 측면을 포착하게끔, 대문자, 신장, 반복에 대한 특수 토큰을 추가 -
Hyperameters
IMDB validation set에서 튜닝하는 작업 전반에 걸쳐 동일한 하이퍼 파라미터를 사용
Result
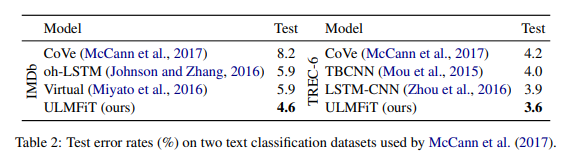
McCann 등(2017)이 사용한 IMDb 및 TEC-6 데이터 세트의 테스트 오류율
AG, DBpedia, Yelp-bi 및 Yelp-full 데이터 세트에 대한 테스트 오류율
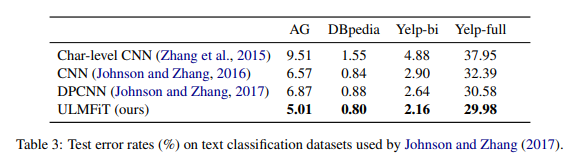
Analysis
-
Low-shot learning
labeling 된 예제는 LM Finetuning(Supervised)에 사용
모든 task 데이터는 LM(semisupervised)에서 Fine-tuning
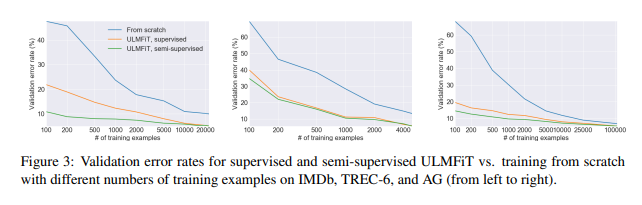
100개의 label만 있는 데이터셋을 가지고 ULMFiT 모델은 10배, 20배 이상으로 학습한 모델과 성능이 비슷하다
Unsupervised datasest를 semisupervised learning에 활용하게 하면 50배, 100배 이상 데이터셋이 있어야 한다. -
Impact of pretraining
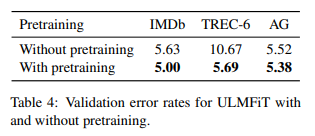
논문에서의 모델은 pretrain 되지 않는 것과 비교한다. -
Impact of LM quality
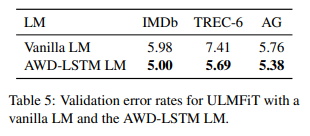
드롭아웃이 없는 동일한 하이퍼파라미터를 가진 vanilla LM을 드롭아웃 매개변수를 가진 AWD-LSTM LM과 비교 후 좋은 성능을 보임
(단 데이터셋이 작을 경우 과적합 위험) -
Impact of LM fine-tuning
Discr(차별적 학습률)과 Stlr(slanted triangle 학습률)은 데이터 세트 모두에서 성능 향상을 보여주며, regular fine-tuning이 좋지 않은 TREC-6 데이터셋에서 좋다. -
Impact of classifier fine-tuning
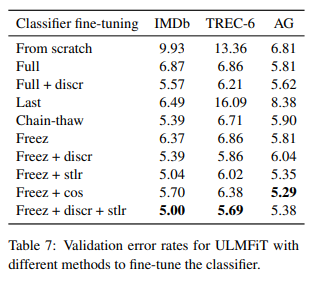
ULMFiT 가 전박적으로 우수한 성능을 보여준다. -
Classifier fine-tuning behavior
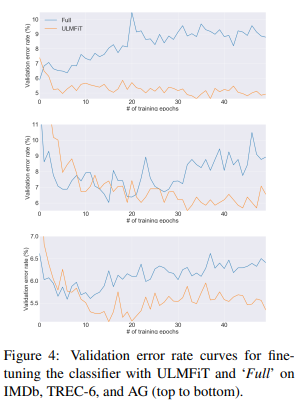
모든 데이터셋에서 Full finetuning을 하면 초기에 비교적 낮은 오류가 발생하며 점점 과적합 되고, 망각현상이 생겨 오류가 증가한다.
반면 ULMFiT는 더 안정적이고 망각을 겪지 않아 성능이 개선되거나, 학습속도에 좋은 효과를 보여준다.
Impact of bidirectionality
두번째 모델을 훈련하는 것보다 bidrectionality를 이용하여 forward 와 backward를 예측을 결합하면 0.5~0.7의 성능 향상을 보인다.
Discussion and future directions
- 영어 이외의 데이터셋이 부족한 부분에서 유용할 것이다.
- labeled 데이터가 제한되어 있는 작업에서 유용할 것이다.
- 사전 훈련 및 확장성을 높히는 것
-> 멀티 태스킹 학습이나, 더 일반적이고 적합한 모델을 만들 수 있다. - classification 뿐만 아니라 다른 QA 등의 다른 작업으로 적용해볼 수 있다.
Conclusion
모든 NLP 작업에 적용할 수 있는 ULMFiT를 제안
망각을 방지하고, 다양한 작업에서 학습이 가능
6개의 분류 작업에서 SOTA를 달성
