해당 논문은 ICML 2020에서 소개된 논문이며, Microsoft에서 나온 논문이다.
Abstract
- 본 논문에서는 학습률의 warming up 단계가 필수적인 이유를 보고 layer normalization 위치의 중요성을 살펴본다
- Post LN tarnsformer의 경우 output layer 근처의 매개 변수의 예상 gradient가 크다는 것을 평균 필드 이론으로 증명
- 위의 과정을 통하여 gradient에 큰 학습 속도를 사용하면 훈련이 잘 되지 않지만, 논문에서 제안하는 방법(PreLN)은 초기에도 잘 훈련한다.
Introduction
트랜스포머 모델은 큰 성공을 이루었으나, CNN ,seq2seq 모델보다 post LN 트랜스포머 모델이 최적화를 하기 더 어렵다
이러한 어려움을 해결하기 위해 최적화를 위해서는 학습 속도가 낮게 시작한 다음 사전에 정한 반복 횟수 만큼 점진적으로 증가해나간다. 이러한 준비 단계는 최적화를 느리게 하며, 더 많은 매개변수 튜닝을 가져오게 된다.
(속도가 느리며, 이 구간이 최종 모델 성능의 학습률과 반복횟수에 민감하다)
본 논문에서 제시하는 것
학습률 준비 단계를 안전하게 제거하는 방법을 제시 (mean field theory를 이용)
layer normalization이 gradient 척도를 제어하는데 결정적인 역할을 하는 것을 보여줌
pre layer normalization(Pre-LN)을 연구
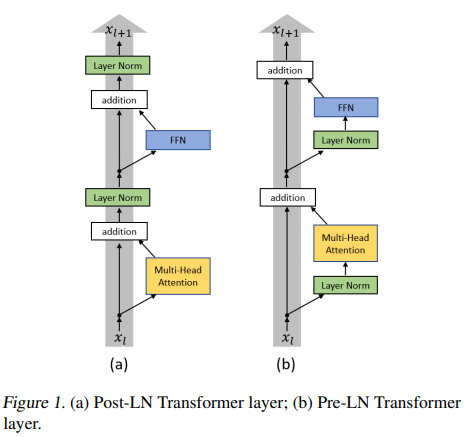
위의 그림에서 Layer Norm의 위치를 바꿔서 실험을 진행하였다. 이에 대한 결과는 초기화 시 이론적으로나 경험적으로 Pre-LN Transformer에 대한 폭발이나 소멸 없이 gradient가 잘 작동하였다. -> 준비 단계가 제거 될 수 있다 -> 하이퍼 파라미터 수의 감소
- 본 논문은 하이퍼 파라미터 조절을 용이하게 하는 Pre-LN Transformer에 대해 준비 단계를 제거 하며, train time을 줄일 수 있음을 보여 주었다.
Related work
- Gradient descent-based methods : 일반적으로 초기에는 큰 학습률 이후 감소하는 방식이다. 하지만 학습률 준비 단계에서 대규모 배치 훈련 같은 일부 구체적인 문제를 처리하는데 필수적이다. 그러나 학습률 준비 단계는 대부분 트랜스포머 모델을 최적화 할때 필수적이며, 중요하다.
PreLN 변압기는 더 깊은 모델을 훈련할때 몇 가지 연구에서 제안되지만, 준비 단계는 남아있으며, 활성함수를 변형하는 시도를 하였지만, 최적화 준비 단계도 최적화 프로그램에 상당히 도움이 된다는 것을 발견하였다.
Optimization for the Transformer
Post-layer Normalization을 적용한 트랜스포머
트랜스포머는 self-attention layer와 ff layer 두 하위 layer가 존재하며, 두 계층에 각각 layer normalization이 적용이 된다.
Post-layer normallization은 BERT 및 트랜스포머에서 최초이자 가장 많이 쓰이는 아키텍처이며 self-attention -> residual connection -> layer normalization 의 순서를 따른다.
(그림 1의 좌측 그래프이다.)
The leearning rate warm-up stage
실험은 독일어-영어의 기계번역 작업으로 수행
모델이 warm-up의 가치에 민감한지와 warm up 단계가 필수적인지에 초점을 맞추어서 실행
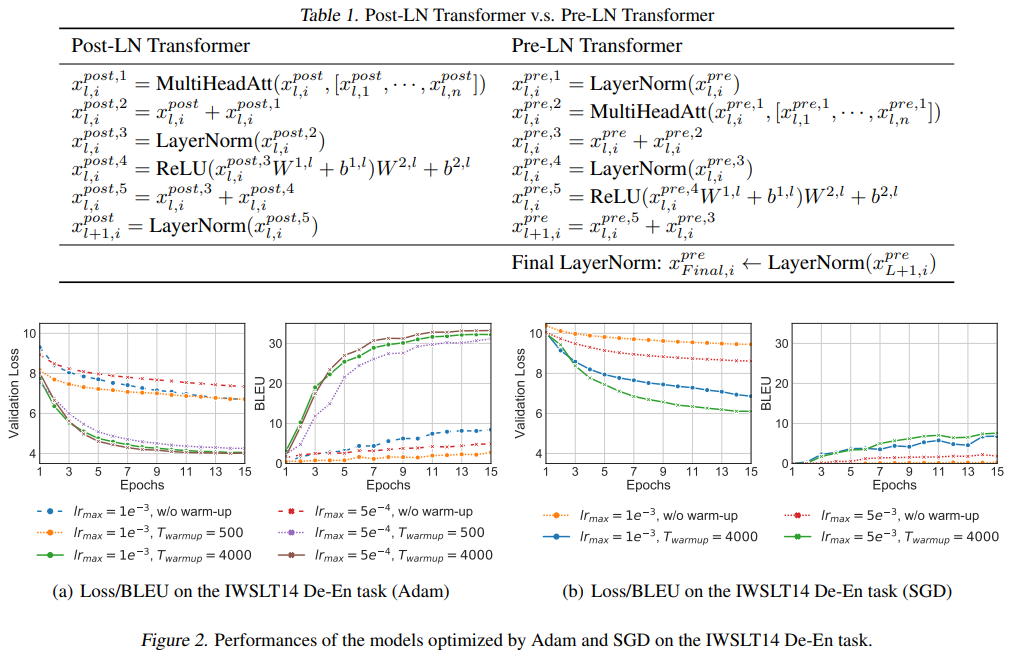
실험에 대한 결론
-
warm up 단계가 필수적임을 알 수 있다.
-> 없을 경우 Adam을 통해 학습한 모델의 성능이 낮으며, 있을 경우 성능이 더 잘나옴을 확인 가능 -
최적화 과정에서 warm up의 값에 민감하게 반응하며, 이는 중요한 hyper-parameter임을 알 수 있다.
-
본 실험에서는 Adam과 SGD 두가지를 사용하여 비교를 진행하였고, 그 결과 warm-up 과정은 Optimizer 관계 없이 이점을 가진다.
wram up 단계의 단점
- config가 최종 성능에 큰 영향을 미친다.
- warm up 단계는 최적화 속도를 늦출 수 있다.
Understanding the Transformer at initialization
Post LN transformer 는 처음부터 큰 학습률로 훈련이 불가능하다.
Parameter Initialization
Xavier 초기화 초기롸로 초기화
이론적인 분석을 위한 단계
1. multi head attention 대신 single head attention에 초점을 맞추고 을 모양으로 만든다.
-
Self-attention의 하위 계층에 의 parameter 행렬을 0행렬로 초기화 한다.
-
input vector도 동일한 가우시안 분포에서 샘플링 된다고 가정한다.
Post-LN Transformer vs Pre-LN Transformer
-
Post-LN Transformer
-> layer 수가 증가할때 Pre-LN 보다 성능이 부족
-> residual block 사이에 layer normalization을 한다. -
Pre-LN Transformer
-> residual connection 내부에서 layer normalization 배치하고 다른 모든 비선형 변환보다 먼저 배치한다.
Definition 1
가 bounded면 높은 확률로 기댓 값에너 먼 위치에 있지 않을 것이다.
위의 내용을 전제로 아래의 정리를 보면 다음과 같다.

위의 두 식에서 아래의 식은 루트 안에 L로 나누는 부분이 있다.
Theorem 1을 보면 Post LN의 경우 마지막 FFN 층에 대한 Gradient 척도가 L과 무관한 차수 임을 알 수 있다.
반면 Pre-LN의 경우 L이 증가할 수록 Gradient의 scale이 훨씬 작다.
Lemma 1
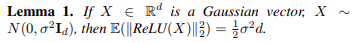
D-dimensional 가우시안 벡터를 ReLU에 넣을때 L2 Norm의 기댓값을 나타내며 이는, Post LN Transformer와 Pre LN Transformer에 대한 서로 다른 layer의 hidden state를 추정하기 위한 장치이다
Lemma 2

Lemma 2 는 Post LN 과 Pre LN의 hidden state에 대한 예상 표준을 연구한다.
Lemma 2를 통해 알 수 있는것
Pre-LN의 hidden state는 Layer의 깊이에 따라 선형적으로 증가
Post-LN의 경우 hidden state의 scale은 기대에서 동일하게 유지
Lemma 3
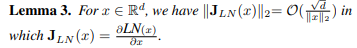
Layer normalization의 실리는 Gradient가 Input vector의 norm에 반비례.
이러한 과정의 Main idea는 layer normalization은 gradient를 정규화 할것이라는 것
Post LN - Layer와 무관
Pre LN - layer와 선형 적이며 모든 parameter의 gardient는 로 정규화 된다.
Extended theory to other layers/parameters
논문에서 제시하는 결과는 다음과 같다
Post-LN의 경우 gradient norm이 출력 근처의 매개변수에 대해 크고 layer지수 l이 감소함에 따라 붕괴할 가능성이 높다는 것
반면 Pre-LN의 경우 모든 layer l에 대해서 동일하게 유지될 가능성이 있다.
Empirical verification of the theory and discussion
Theorem 1은 post LN Transformer가 모든 크기에 대해 마지막 FFN 하위 layer의 gradient norm의 scale이 동일하게 유지된다. 반면 Pre LN Transformer는 모델이 커질 수록 감소한다.
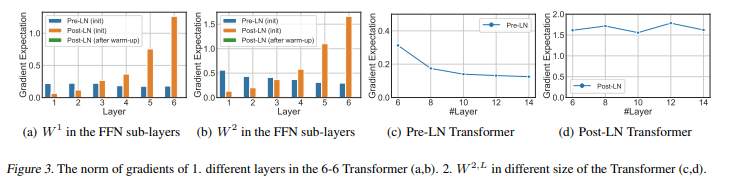
Figure3를 보면 Post LN의 경우 layer index와 같이 증가하는 반면, Pre LN의 경우 여러 layer에 대해 scale이 거의 동일하게 유지된다.
The critical warm-up stage for Post-LN Transformer
논문에서는 Gradient scale이 Post LN이 학습률 scaling이 필요한 이유라고 가정한다.
warm up 없이 큰 학습률을 사용하면 훈련이 불안정해질 수 있는데, 이를 검증하기 위해 figure 3(a),(b)에서 warm upd을 한 뒤 gradient 통계를 연구했다. 그 결과 gradient scale이 매우 작고 큰 학습률로 모델을 훈련 시킬 수 있음을 알 수 있다.
작은 학습률을 사용하여 훈련을 진행하면 문제가 완화되고 Post LN Transformer를 어느정도 최적화 할 수 있지만 수렴이 느리다.
- PostLN의 경우 학습률을 작게 주거나, warm up 단계가 있어야한다.
- Pre LN의 경우 학습률 조정만으로도 가능하다.
Experiments
NLP의 주요 작업인 기계번역과 비지도 사전훈련에 대한 검증
Experiment Settings
기계 번역
IWSLT14 독일어 - 영어로 수행
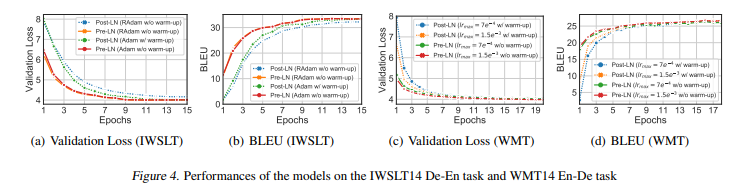
모든 실험에서 Optimizer는 Adam을 사용, LRmax를 Pre LN Transformer의 초기 학습 속도와 동일하게 설정
Unsupervised Pre-training BERT
train과 valdiation의 비율은 199:1로 나누었다.
실험은 base모델을 사용하였으며, Wram up 없이 Pre LN BERT를 훈련하고 Post LN BERT를 비교하였다.
Pre LN BERT의 경우 warm up 없이 3e-4 부터 선형학습률 감쇠를 사용하였다.
반면 Post LN BERT에 더 큰 학습속도를 사용하려고 했으나 최적화가 분산됨을 알 수 있었다.
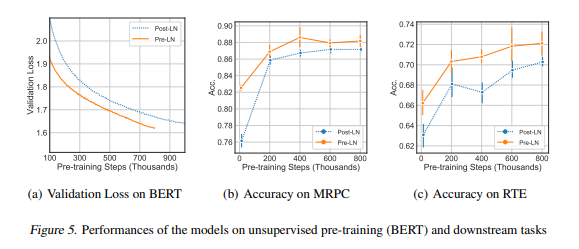
Experiment Results
기계 번역
- warm up 단계는 Pre LN Transformer를 훈련하는데 중요하진 않다.
- Pre LN Transformer는 동일한 lr max를 사용하는 Post LN Tramsformer보다 빠르게 수렴딘다.
- RAdam과 비교하여 layer normalization의 위치 변화가 Optimizer의 변화를 지배하는 것을 발견
Unsupervised Pre-training BERT
- Pre LN 의 경우 warm up 을 제거할 수 있다.
- Pre LN 의 경우 모델이 더 빨리 훈련 될 수 있다.
- Pre LN model이 down stream 작업에서 더 빠르게 수렴하며, 학습률이 warm up에 의존하지 않고 Post LN Transformer보다 빠르게 훈련될 수 있음을 보여준다.
Conclusion and Future Work
layer normalization의 위치가 중요하다는 것을 보여준다.
Pre Layer normalization을 사용하면 warm up 없이, 훨씬더 빠르게 수렴할 수 있음을 보여준다.
