본 논문은 Open ai에서 발표한 논문이며, Instruct GPT라고도 불리는 논문입니다.
Abstract
해당 논문에서는 end2end 학습 접근 방식으로 GPT-3의 few shot learning을 크게 능가하는 방법을 제시한다. (soft prompt를 학습하기 위한 prompt tuning)
이를 통하여 하나의 모델을 다양한 downstream 작업에 재사용 할 수 있으며, prefix tuning의 단순화로 볼 수있다.
soft prompt로 동결한 모델을 조건화 하는 것이 도메인 전송에 견고성에 이점을 제공하고 prompt 앙상블을 가능하게 한다는것을 보여준다.
introduction
텍스트 prompt를 통해서 frozen GPT-3모델을 조절하는게 놀라울 정도로 효과적인 것을 보여주었다. -> 기존의 모델들에 fine-tuning 하는 것이 아닌 단일 모델에 여러 작업을 수행 가능성제시
(본 논문의 방법 이전에는 fine tuning이 가장 효과적인 방법이였다.)
하지만 prompt 기반 adaptation은 몇가지 문제가 있다.
1. 오류가 발생하기 쉽다.
2. 사람의 개입이 필요하다.
3. prompt에 있는 조건에 따라 효과가 제안된다.
4. 결과적으로 품질이 떨어진다.
본 논문에서는 언어 모델에 적응 시키기 위한 추가적인 단순화를 통한 prompt tuning을 제안
기존 모델의 문제점은 다음과 같다.
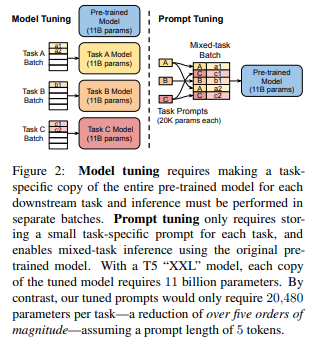
downstream task 별로 fine-tuning된 모델을 만들어야 하며, 이는 prompt tuning에 비하여 매개변수가 많이 필요하다.
전체 모델을 동결후 downstream 작업당 추가적인 k 튜닝가능 토큰만 입력텍스트에 추가할 수 있도록 한다.
이 soft prompt는 end2end로 훈련되어 전체 레이블이 지정된 데이터 셋을 응축할 수 있어 few shot으로 학습한 모델보다 좋은 성능을 보여준다.
이 논문에서의 주요 기여는 다음과 같다.
1. 대규모 언어 모델체제에서 모델 튜닝으로 prompt tuning을 제안하고 경쟁력확보
2. 다양한 설계 선택을 가능하게하고 품질과 견고성을 보여주는것
3. domain 이동 문제에 대한 model tuning을 능가
4. prompt ensembling을 제안하고 효과를 보여줌
Prompt Tuning
Prompt Tuning은 모델이 예측값을 생성하는 동안 모델에게 추가적인 정보를 더하는 방법이다.
이를 통하여 매개변수는 고정하면서 올바른 예측값에 가깝도록 한다.
최적의 prompt를 찾기위해선 수동 검색 또는 미분 불가능한 검색을 통해서 찾아야한다.
prompt tuning은 prompt p가 에 의해 매개변수화된다는 제한을 제거 대신 prompt 에는 업데이트 할 수 있는 전용 parameter가 존재한다.
prompt 설계는 고정된 임베딩의 고정된 어휘에서 prompt token을 선택하는 것을 포함하지만 prompt tuning은 이런 prompt token의 임베딩만 업데이트 될 수 있는 특수 토큰의 고정된 prompt를 사용하는 것으로 생각 할 수 있다.
- prompt design : 고정된 임베딩, 고정된 어휘에서 prompt token을 선택
- prompt tuning : 임베딩만 업데이트 되는 특수 토큰의 고정된 prompt를 사용
논문에서 모델은 예측값을 최대화 하도록 훈련 되었지만 prompt parameter들만 업데이트 된다.
Design decisions
설계 고려사항 1
prompt 표현을 초기화하는 방법들
1. 무작위 초기화
2. prompt token을 모델 어휘에서 가져온 임베딩을 초기화
3. 출력 클래스를 열거하는 임베딩으로 prompt를 초기화
설계 고려사항 2
prompt의 길이
prompt의 길이가 짧을 수록 tuning 해야하는 매개변수가 줄어든다
-> 성능이 좋은 최소 길이를 찾는것이 목표가 된다.
Unlearning Span Corruption
GPT-3 : Auto regressive model
T5 : encoder-decoder model을 사용하며 span corruption objective를 사용
T5는 sentinels token으로 표시된 입력 텍스트에서 masking 된 span을 재구성 한다.
대상 출력 텍스트는 sentienl과 final sentinel로 구분된 모든 masking된 내용으로 구성된다.
논문에서는 frozen model이 생성하는데 적합하지 않다고 본다
-> span corruption을 위해 사전 훈련된 T5 모델은 natural input text를 본적 없으며, natural 한 output을 예측하라는 요청도 받은 적 없다.
(input, output 둘다 natural 하지 못하다)
T5는 span corruption의 전처리 세부 사항으로 pre training target은 sentinel로 시작된다.
이러한 것을 고려 하여 본논문에서는 3가지 설정으로 실험을 하엿다.
1. span corruption : T5의 기존 모델을 frozen 모델로 사용하고 downstream 작업에 대해 예상되는 텍스트를 출력하는 능력 확인
2. span corruption + sentinel : 동일 모델을 사용하지만 모든 downstream 앞에 sentinel을 추가
3. LM adaptation : T5의 self supervised training을 계속 하지만, 입력으로 natural prefix가 주어지면 output으로 자연스러운 텍스트를 연속으로 생성해 내야한다.
이전에 얼마나 성공적인지 알려지지 않았기에 본 논문에서는 최대 100K까지 다양한 길이의 적응을 실험한다.
Result
frozen model의 모든 크기의 사전학습된 T5모델 위에서 구축된다.
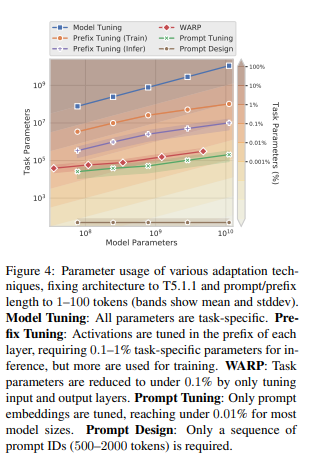
모든 네트워크 계층에서 활섬함수를 overwriting 하는 것과 달리 입력계층만 이용하기 때문에 매개변수를 적게 사용한다.
또한 실험을 통해 모델 크기가 증가함에 따라 더 짧은 prompt가 실행 가능하다는 것을 알게 되었다.
8가지 영어 이해 작업 모음인 SuperGLUE benchmark로 성능을 측정
T5의 standard cross-entropy losss를 사용하여 30000단계의 prompt를 학습 check point는 early stopping을 통해 선택하게 된다.
Closing the Gap
T5모델의 기본 hyperparameter를 사용하여 T5를 tuning한다.
논문에서는 2가지 기준을 고려한다.
1. model tuning : apples-to-apples 비교를 위해 개별적으로 tuning을 한다.
2. model tuning(multitask) : T5의 multitask tuning을 사용하여 경쟁력 있는 기준을 달성
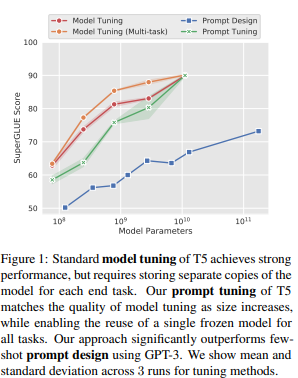
규모가 증가함에 따라 prompt tuning이 더 경쟁력이 있게 됨을 알 수있다.
(figure 1 참고)
해당 부분의 결과는 prompt tuning을 진행한 결과는
prompt tuning T5 small model - GPT-3 XL과 일치
prompt tuning T5 Large model - GPT-3 175B을 능가
Ablation Study
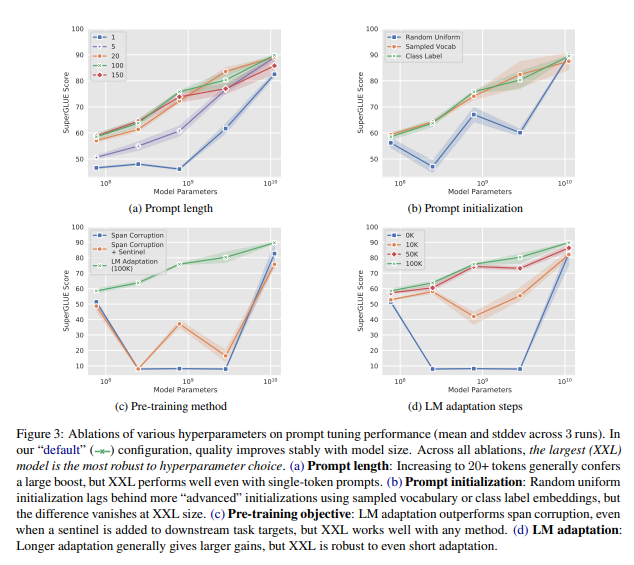
Prompt Length
{1, 5, 20, 100, 150}의 prompt길이를 변경하고 ㄷ른 설정은 기본 구성으로하여 모델 크기에 대한 prompt 훈련을 진행
Figure3(a)를 보면 prompt 길이가 길어질수록 성능이 올라간다.
Prompt Initialization
다른 hyperparameter를 기본값으뢰 고정하면서 모든 크기의 모델을 훈련하여 prompt intialization의 효과를 완화한다.
random initialization의 경우 [-0.5,0.5]범위 내에서 균일하게 추출
sampling된 언어에서 초기화 할때는 T5의 sentencepiece 어휘에서 가장 일반적인 token 5000개로 제한
class label initialization의 경우 downstream 작업에서 각 클래스의 문자열 표현에 대한 임베딩을 가져와 prompt에서 token 중 하나를 초기화 하는데 사용
- prompt 길이가 길면 모든 prompt token을 초기화 하기 전에 class label이 부족해지는 경우도 생긴다. -> prompt를 채우기 위해 sampling 된 vocab 전략을 사용한다.
figure3(b)는 모델 크기에 걸쳐 initialization 전략의 절제를 보여주며, 클래스기반 초기화가 성능이 좋음을 보여준다.
Pre-training Objective
figure3(c),figure3(d)에서 pretraining objective가 prompt tuning 품질에 영향을 미치는 것을 볼 수 있다.
span corruption - frozen model을 훈련하기에 적합X
span corruption -> Language modeling으로 변환하려면 훈련자원의 투자가 필요하다. 그리고 본 실험에서는 XXL 모델만 span corruption에도 좋은 성능을 제공하였다.(XXL 모델이 robust함을 알 수있다.)
최적이 아닌 span corruption 설정에서 작은 모델이 큰 모델보다 성능이 우수 했다.
실험 결과 span corruption를 목표로 사전학습된 모델은 5개중 2개만 잘 동작했지만 LM adaped 모델은 모든 모델에서 잘 동작하였다.
Comparison to Similar Approaches
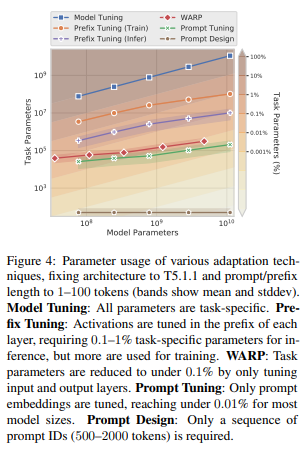
위의 그림을 통해 알 수 있듯이 prompt tuning은 10억개이상의 parameter를 가진 모델에 대해 0.01%미만의 작업별 parameter를 필요로 하는 가장 parameter 효율적인 방법이다.
Prefix-tuning : Activation 각 레이어의 prefix에서 조정되며 추론을 위해 0.1~1%의 parameter가 필요하지만, 학습에는 더 많이 사용됨
-> 모든 transformer layer에서 prefix sequence를 학습한다.
- prompt tuning과 차이점
- prefix tuning은 GPT-2와 BART를 설계선택에 사용하지만
prompt tuning은 T5모델을 설계 선택에서 사용 - prefix tuning은 인코더와 디코더 모두의 prefix를 포함하지만,
prompt tuning은 인코더의 prompt만을 필요로 한다.
WARP : prompt parameter에 추가되는 방식, [MASK]토큰과 학습 가능한 출력 layer에 의존하여 mask를 클래스 logit에 투영하는 masking 언어 모델과 함께 작동한다.
P-tuning : 인간 설계에 기반한 패턴을 사용하여 학습가능한 연속 prompt가 내장된 입력 전반에 걸쳐 interleave되는 방식
좋은 성능을 얻으려면 P-tuning을 model tuning과 같이 사용해야한다.
- 논문에서 지적하는 단점
model은 prompt와 parameter를 공동으로 업데이트 해야한다.
soft words : pretrain된 LM에서 지식을 추출하기 위해 soft words를 이용하여 prompt를 학습, 학습된 parameter가 각 계층에 포함되어 cost는 모델의 깊이에 따라 조정된다.
task prompt에 대한 일반적인 작업(Adapter 기법) :
훈련 네트워크 계층 사이에 어댑터 작업과 일치
어댑터는 BERT-Large를 frozen 할때 full fine-tuning할때랑 가까운 성능을 달성하였으며, 소량의 parameter만 추가하였다.
둘의 차이점
adapter는 주어진 계층에서 활성화를 다시 쓸수 있게하여 입력 표현에 작용하는 실제 함수를 수정
prompt tuning은 함수는 고정된 상태에 후속 입력 처리 되는 방식에 영향을 줄 수 있는 표현을 추가
Resilience to Domain Shift
prompt tuning은 model의 parameter를 동결하여 model의 일반적인 이해를 수정하지 않는다.
대신 prompt representation은 입력의 표현을 간접적으로 변조
-> 과적합 모델의 능력감소, 가짜 상관관계를 기억 -> domain 이동에 대한 견고성 강화
-
test(zeroshot transfer)
QA와 paraphrase detection 두 작업에 대해 zero-shot tranfer를 조사
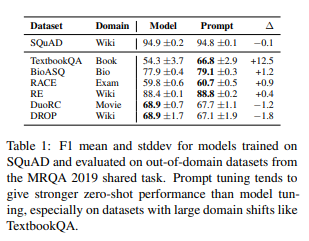
격차가 있는 대부분의 도메인 외부 데이터셋에서 model-tuning을 능가하는걸 보여준다. -
test(robust)
GLUE의 두가지 parapharase detection
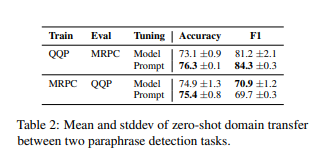
QQP 데이터에서 경량 prompt를 train하고 MRPC에서 평가하는 것이 전체 model을 tuning하는것보다 더 좋은 성능이 나왔다.
prompt tuning은 정확도가 약간 향상되고, F1은 살작 감소 되었다.
model-tuning이 과도하게 매개변수화 될 수 있고 훈련 작업에서 더 적합할 가능성이 높다는 견해를 뒷받침 한다.
Prompt Ensembling
동일 데이터에 대해 서로 다른 초기화에서 훈련된 모델 앙상블은 작업 성능 향상을 위해 널리 관찰 되며 모델 불확실서 추정에 유용
-> 비실용적, 많은 비용 소모
prompt tuning은 사전 훈련된 언어 모델의 여러 적응을 앙상블 하여 좋은 성능이 나온다.
동일 작업에 대해 N개의 prompt를 교육
핵심 언어 모델링 매개변수를 전체적으로 공유하며 N개의 모델을 만든다
-> 빠른 앙상블이 가능(하나의 예에 N개의 배치를 적용하여 해결)
-> 단일 전진패스라서 빠르게 처리가됨
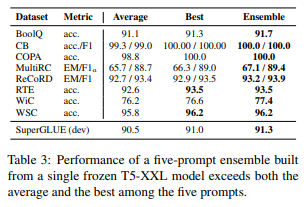
위의 표를 통해서 앙상블 예측이 단일 prompt를 능가하고 개별 최상위도 능가함을 보여준다.
Interpretability
prompt가 모델이 동작을 잘하게끔 유도하는 자연어로 만들어져야한다.
prompt tuning은 연속 임베딩 공간에서 동작하기에 prompt 해석이 더 어려워진다. 학습된 soft prompt해석 가능성을 테스트 하기위해 각 prompt token에 가까운 이웃을 계산한다.
논문에서는 prompt token에 대해 가장 가까운 상위 5개 이웃이 긴밀한 의미 클러스터를 형성하는 것을 찾아내었다고 한다.
-> word-like 표현을 학습함을 알 수 있다.
class label 전략을 사용하여 prompt를 초기화 할때 종종 class label이 train을 통해 유지가 된다.
prompt token이 주어진 label로 초기화 되는 경우 해당 label은 tuning 후 가장 가까운 이웃에 속하는 경우가 많다
Random uniform 이나 sampled vocab을 method로 초기화 할때 class label은 prompt의 가장 가까운 이웃에서 찾을 수 있다.
-> model이 prompt에 예상 출력 클래스를 참조로 저장하는 방법을 학습한다
더 긴 prompt를 검사할때 종종 가까운 동일한 이웃 prompt token을 발견한다.
-> prompt에 과잉 용량이나 순차적 구조가 없어서 특정 위치로 정보의 지역 정보를 구하는 것이 어렵다.
Conclusion
본 논문에서는 prompt tuning이 frozen adaptation을 위한 경쟁력있는 기술임을 보여 주었다.
- prompt tuning의 장점
향상된 일반화
특정 도메인에 과적합 되는것 방지
효율적인 서비스
효율적인 고성능 prompt 앙상블 가능
잘못된 부분있으면 가르쳐주세요
