Covariance(공분산)

Covariance란..
로 주로 정의되는 이녀석은 무엇일까?
Covariance는 한국말로 공분산이다. 어떠한 랜덤 변수 X, Y가 있을때 이들의 의존성을 구하기 위해 주로 공분산이라는 개념을 많이 활용한다.
- 여기서 , 는 이다.
수학적 정의의 의미
여기서 잘 살펴보면 식에서 와 는 각각 의 편차와 의 편차이다. 따라서 이것을 곱하고 평균을 낸것이 공분산이라는 개념인데..
햇갈릴 수도 있지만 두 랜덤 변수간의 관계성을 추론하기엔 완벽한 식이다. 잘 생각해 보면 편차란 평균으로부터 해당 값이 얼마나 떨어져 있는가를 나타내기 때문에 가 평균으로부터 어느정도 떨어져 있을때 해당 관계를 유추하는것이 된다. 따라서 두 분산을 곱하게 되면 어떠한 값이 나올 것인데 양수가 나온다면 가 큰값을 가지게 되면서 또한 큰값을 가지게 되었다는 것으로 상관관계가 있다고 말할 수 있다. 다만 값이 0으로 나오게 된다면 와 의 관계성이 없다고 볼 수 있다.
짚고 넘어가야할 점
Covariance가 의 편차, 의 편차의 곱의 평균이고 서로의 의존성을 파악하는 식이라는것은 알았다. 그렇다면 이 의존성은 무엇일까? 예를 들어 와 의 관계가 2차함수 형식을 따른다고 가정해보자.
이 함수는 가 증가함에 따라 그의 제곱만큼 가 증가하므로 서로가 의존 관계에 있다고 말할 수 있지만 Covariance에서의 의존성은 선형적 의존성을 말한다.위 식을 Covariance로 계산해보면 0이 나오게 된다. 그렇다면 서로가 Covaraiance에서 말하는 의존관계를 가지고 있지 않다고 말 할 수 있다. 서로가 독립하진 않지만 선형적 의존관계를 파악하는 것이 Covariance이다.
Iris 데이터셋의 Covariance 예제
Irist data에서의 SepalLengthCm과 PetalLengthCm의 관계를 Covaraiance로 나타내 봅시다.
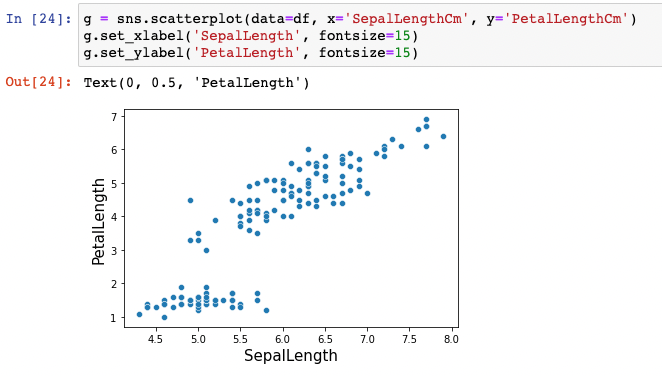
대충 눈대중으로 보기에도 SepalLength와 PetalLength간의 의존도가 있어 보입니다. 따라서 covariance를 구해보겠습니다.
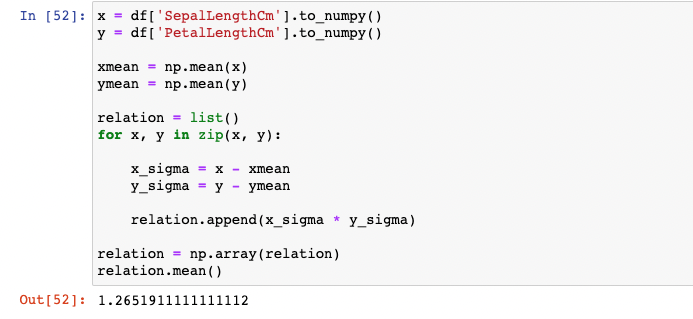
1.26519.. 가 나옴으로 양의 상관관계를 가지고 있고 SepalLength가 증가하면 PetalLengthe도 증가하는것을 확인할 수 있었습니다.
