PaDiM
개요
최근 anomaly localization과 한개 클래스의 detection분야의 방법이 여러가지 소개가 되었습니다. 하지만 이 방법은 딥러닝 training을 요구하거나 KNN알고리즘을 사용하게됩니다. KNN을 사용하게 되면 inference시 모든 training 데이터를 참조하게 되어 높은 시간/공간 복잡도를 가지게 됩니다. 떄문에 산업 현장에 배포하기엔 여러가지 어려움이 따르며 이걸 해결하기 위해 나온 논문이 PaDiM입니다.
설명
PaDiM은 SPADE와 같이 CNN 아키텍쳐에서 pretrained된 feature을 사용합니다. 그리고 첫번째로 다변수 가우시안 분포를 통해 각 patch의 위치가 정해집니다. 두번째는 pretrained된 CNN모델에서 서로 다른 semantic level의 관계를 파악한다는 점입니다.
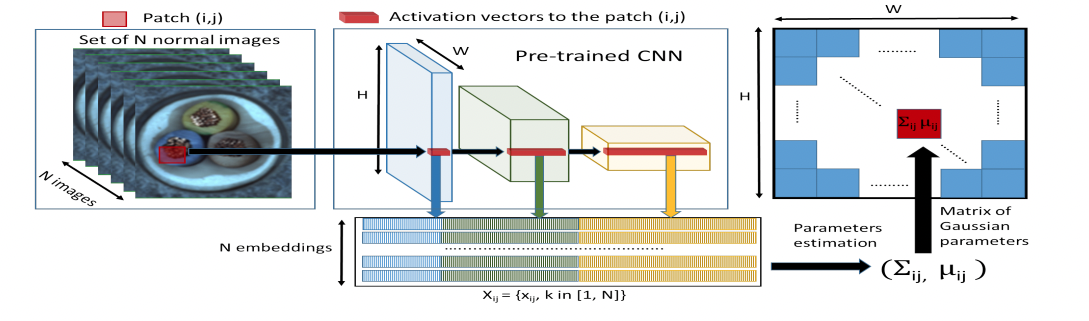
Training
- PaDiM에서의 학습은 모든 이미지에 대해 먼저 pretrained 모델을 거치고 나온 feature을 저장합니다.
- 모든 레이어에서 나온 embedding vector를 concat해 하나의 feature로 통일합니다.
- 그렇게 나오게된 embedding vector 중 랜덤한 하나의 차원을 고르고 다변수 가우시안 분포를 계산합니다.
- 그렇게 나온 평균과 covariance를 저장합니다.
Testing
- 마찬가지로 test 데이터에서 pretraiend모델을 거쳐 나온 feature을 concat 하고 랜덤으로 차원을 하나 뽑습니다
- 그리고 training 값의 평균과 covariance와 1에서 나온 embedding vector를 mahalanobis 거리를 통해 계산합니다.
- 그 거리를 통해 scoremap을 구하고 img-level-score, pixel-level-score을 구합니다.
결론
PaDiM은 기존 KNN알고리즘의 선형적 시간/공간 복잡도를 줄여 기존 SPADE 모델보다 더 산업에 적용되기 쉽게 만들었습니다. 또한 뿐만 아니라 training freature와 testing feature간의 mahalanobis거리를 게산해 더 정확도를 높혔습니다.
