기계학습에 있어서 모델성능을 평가하는 방법은 모델의 결과값과 실제값을 비교하는데서 나옵니다. 하지만 어떤 기준으로 봐야하는가에 따라 달리 해석할 수 있고 이에 따른 방법 2가지(Precision, Recall)를 알아보고 이어 더 해석할 수 있는 방법 몇가지를 소개하겠습니다.
모델의 예측값 / 실제값
모델의 예측값을 True/False로 나누고 실제값 또한 True/False로 나눴을때 아래 2x2 표는 해당 관계를 나타내 줍니다
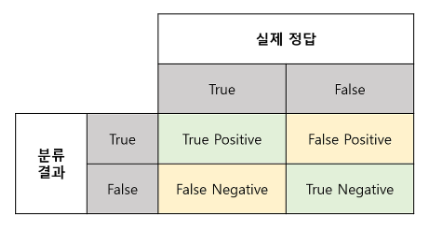
정답
- True Positive(TP): 실제 True인 정답을 True라고 예측 (True)
- True Negative(TN): 실제 False인 정답을 False로 예측 (True)
오답
- False Positive(FP): 실제 False인 값을 True라고 에측 (False)
- False Negative(FN): 실제 True인 값을 False라고 예측(False)
여기서 앞단어 True, False는 정답, 오답의 유무를 나타내며 Positive/negative는 예측값을 나타낸다
Precision, Recall
위 표를 가지고 가장 많이 사용하는 지표가 Precision과 Recall입니다.
Precision(정밀도)
- 모델이 True라고 분류한 것들 중 실제 True인 것들의 비율
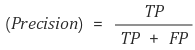
Recall(재현율)
- 데이터의 입장에서 정답을 정답이라고 맞춘 경우
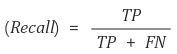
예를들어 설명해 보겠습니다. 사과와 배를 구별하는 모델을 만드려고 합니다. 그리고 데이터에는 사과 9장 배 1장과 모델 A, B가 있습니다.

모델의 관점
A 모델은 모든 값을 '사과'라고 예측 했습니다. 때문에 TP: 9, FP: 0으로 1의 정밀도를 갖습니다. B 모델은 모든 값을 TP가 8, FP: 2로 0.8의 정밀도를 갖게 됩니다.
여기서 데이터가 사과에 편중되있는 바람에 모델이 전부 '사과'로 예측해버린다면 모델 A가 모델 B보다 정밀도가 좋습니다.
데이터의 관점
하지만 데이터의 관점에서 보자면 모델 A는 TP: 9, FN: 1이므로 재현율이 0.9 입니다. 반면에 모델 B는 TP: 8, FN:0 이므로 재현율이 1이 되게 됩니다.
데이터의 관점으로 보자면 모델 B가 편중되어있는 데이터 속에서 배의 데이터가 한개만 있는데도 불구하고 배를 맞추었습니다. 때문에 재현율로써는 성능이 올라갔다고 볼 수 있습니다.
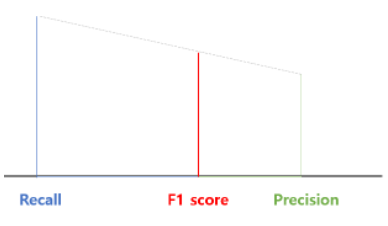
F1 Score
F1 score는 Precision과 Recall의 조화평균
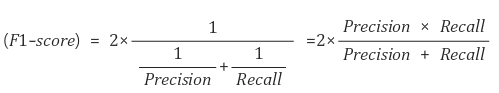
F1 score는 데이터 label이 불균형 구조일 때, 모델의 성능을 정확하게 평가 할 수 있습니다. 단순 평균이라기보다는 작은 길이 쪽으로 치우치게 됨으로써 큰 비중이 끼치는 bias가 줄어듭니다.