
Anomaly detection (이상치 탐지)
일상에서 사람들은 특성 물체를 바라볼때 그 물체의 패턴을 파악하고 있어 이상치가 발견 되었을 때 빠르게 찾아낼 수 있는 능력을 가지고 있습니다. 여기서 중요한 점은 그 이상치가 어떤 것이냐를 판단하는것이 아닌 원래 물체로부터 벗어나는 부분을 찾아내는데에 있는데 이건 일반적인 segmentation과 다른 부분이라고 할 수 있습니다.
SPADE
SPADE에서는 크게 3가지 방식으로 이상치를 탐지해 냅니다.
- image feature extraction
- K nearest neighbor normal image retrieval
- pixel alignment with deep feature pyramid correspondence.
Feature Extraction
feature extraction은 두가지 용도로 사용되는데 하나는 normal 이미지 feature와 target이미지 feature 간의 비교(image-wise comparison) 그리고 두번째는 픽셀들간의 비교를 위한 (pixel-wise comparison)을 하게 됩니다.
Image-wise
SPADE의 가장 첫번째 방법으로는 이미지의 특성(feature)을 뽑아내면서 시작하게 됩니다. 여기서 사용된 방법은 이미 ImageNet으로 pretrained 되어있는 ResNet 계열 모델에서 마지막 avg pool 부분을 통과한 부분의 feature를 뽑아내게 됩니다. 그리고 이 feature을 통해 target값과 KNN 형식으로 거리를 재 target을 분류하게 됩니다.
Pixel-wise
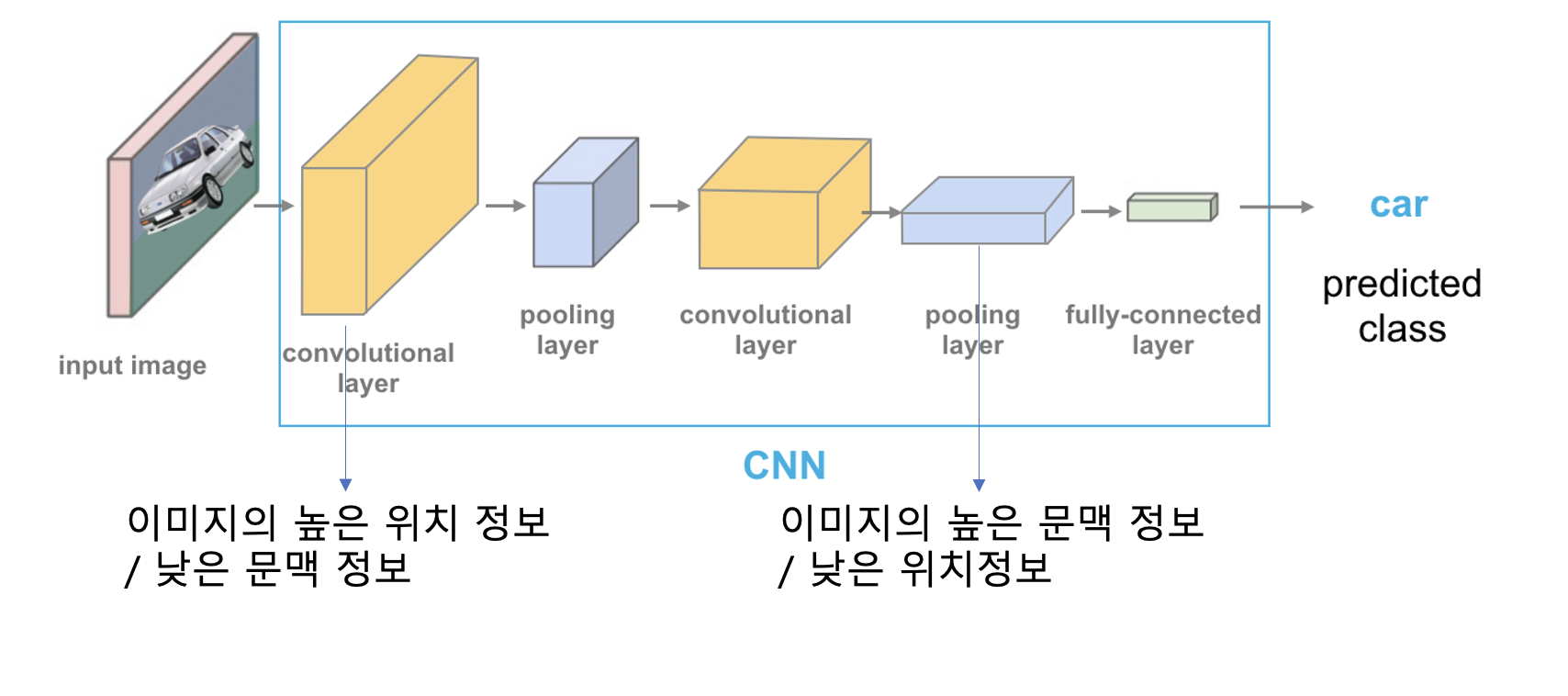
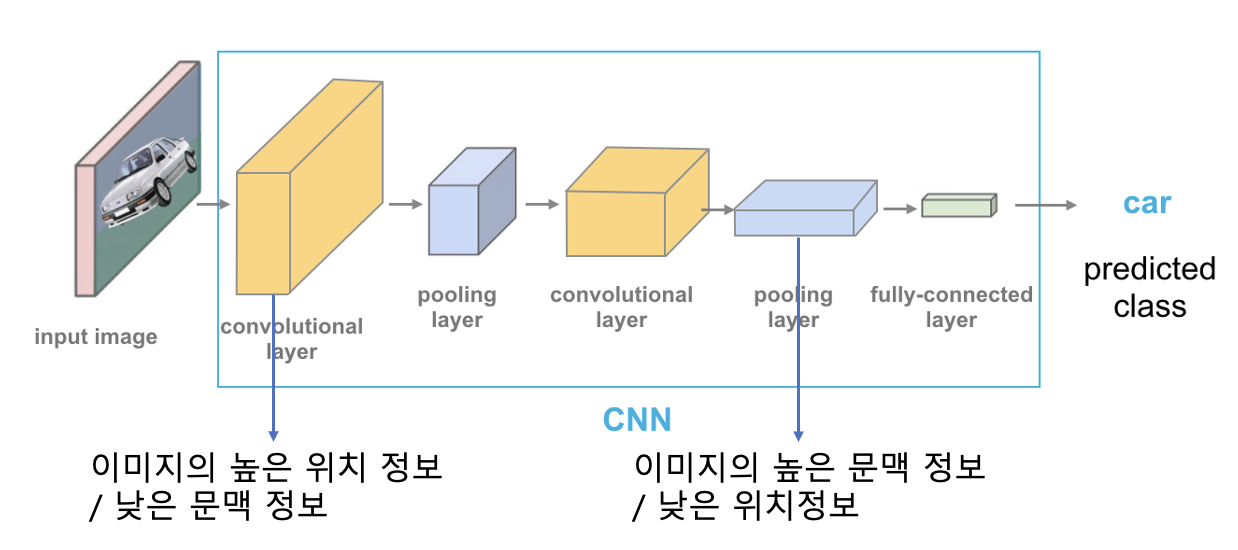
pixel wise comparison을 하기 위해서는 모델에서 모든 layer마다 feature을 추출해 총 M개를 뽑습니다. 이렇게 여러개를 뽑는 이유는 Image-wise처럼 마지막 global pooling 이후 feature로만 하게 된다면 크게 효과가 안나타나기 때문입니다. global pooling은 모델 가장 마지막단에 일어남으로 이미지의 문맥적인 정보는 잘 가지고 있지만 대체로 공간적인 정보는 적게 가지고 있습니다. 정확한 위치를 잡아내야 하는 pixel간의 비교에서는 효과가 떨어 질 수 있기 때문에 모델의 여러단의 layer의 feature을 concatenation 한 후 비교를 하게 됩니다.
K nearest neighbor normal image retrieval
SPADE에서 normal 이미지들의 feature을 뽑아내고 나면 KNN 방식을 통해 target이미지와 normal 이미지간의 거리를 재고 평균을 내어 anomaly score을 구합니다. 여기서 중요한 점은 sub-image, 즉 pixel-wise 비교를 할 때는 feature pyramid matching이라는 방법을 통해 anomaly score을 구한다는 점입니다.
Pixel alignment with deep feature pyramid correspondence
image-level stage 이후 anomalous로 분류가 되었다면 목표는 이미지 안에서 이상치 부분을 정확히 캡처하는 것입니다. 이를 해내기 위해 픽셀이 여러개의 이미지와 일치하는지를 확인해야 하는데 해당하는 모든 픽셀들의 feature들의 gallery를 만들고 타겟 feature와 거리를 계산하고 평균을 내 anomaly score을 구하게 됩니다.
