
이번 글에서는 Distilling the Knowledge in a Neural Network(2015)을 리뷰하겠습니다.
본 논문에서는 teacher 모델의 지식을 student 모델에게 전달하는 방법을 제시합니다.
- 이 방법을 통해 학습한 student 모델이 teacher 모델과
비슷한 성능을 달성하였으며, - 이에 더해
모델의 일반화 성능을 향상시키는 데도 효과적임을 검증하였습니다.
앞으로 복잡하고 무거워서 배포할 수 없는 큰 모델을 Teacher model이라 칭하고, 단순하고 가벼우며 Teacher model의 지식을 학습할 모델을 student model이라 칭하겠습니다.
teacher 모델은 이미 대규모의 데이터셋으로 학습하여 테스트에서 높은 성능을 달성한 모델입니다. 다만 구조가 복잡하고 무거워서 연산량과 메모리 사용량이 많습니다. 또한 추론에 걸리는 시간이 오래 소요되기 때문에 실제 배포할 수 있는 모델은 아닙니다. 그러나 이 모델은 배포될 수는 없어도 선생님이 될 순 있습니다(^u^). 자신이 습득한 모든 지식을 아무것도 모르는 학생 모델에게 전수하는 역할을 담당합니다.
student 모델은 teacher 모델에게 전담 과외를 받는 학생입니다. 모델 구조가 단순하고 가벼워야 합니다. 그래야 배포할 수 있겠죠? 이 학생은 선생님으로부터 지식을 전달받고 습득하여 자신의 것으로 만듭니다. 이를 토대로 청출어람하는 모델입니다.
teacher 모델의 지식을 어떻게 student 모델에게 전달할 수 있을까요?
(1) "지식"을 모델의 logits을 soft하게 변환시킨 값(=soft targets)으로 상정합니다.
(2) soft하게 변환시킬 때 T(temperature)라는 매개변수가 사용됩니다.
soft targets
논문에선 teacher 모델의 지식인 soft targets을 student 모델에게 전달합니다.
student 모델이 soft targets을 맞추도록 학습하는 방식입니다.
soft targets은 teacher 모델의 logits을 soft하게 만든 값입니다.
먼저 모델의 logits이 어떻게 생겼는지 확인해보겠습니다.
-
teacher 모델의 logits입니다. 예시는 1000개의 클래스를 분류하는 멀티 클래스 태스크입니다. 모델의 출력 logits shape은 (1, 1000)입니다. 모델은 1000개의 클래스 각각에 정답일 확률을 부여합니다. logits 배열 0번째 인덱스에 있는 값인 8.1744.. 는 모델이 "0번 클래스가 정답일 확률은 8.1744.." 라는 논리로 할당한 값입니다.
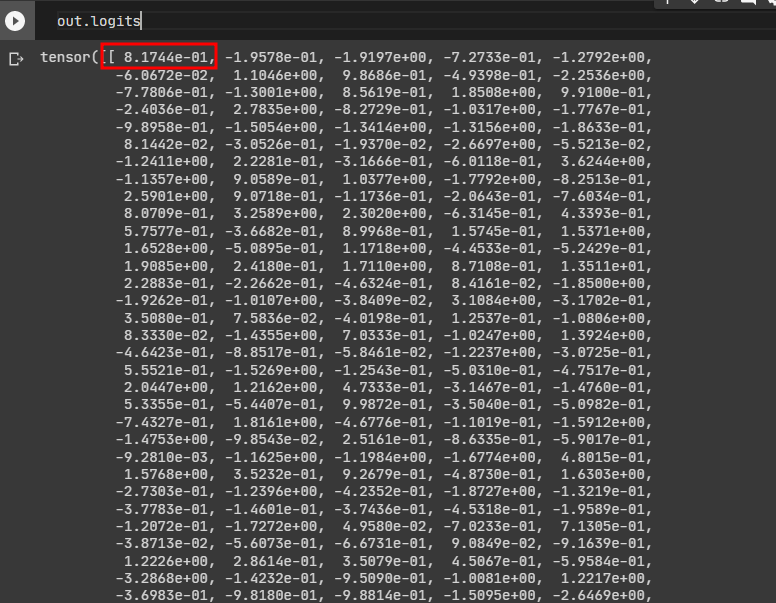
-
logits을 더 soft하게 만들기 위해 softmax 함수를 통과시키겠습니다.
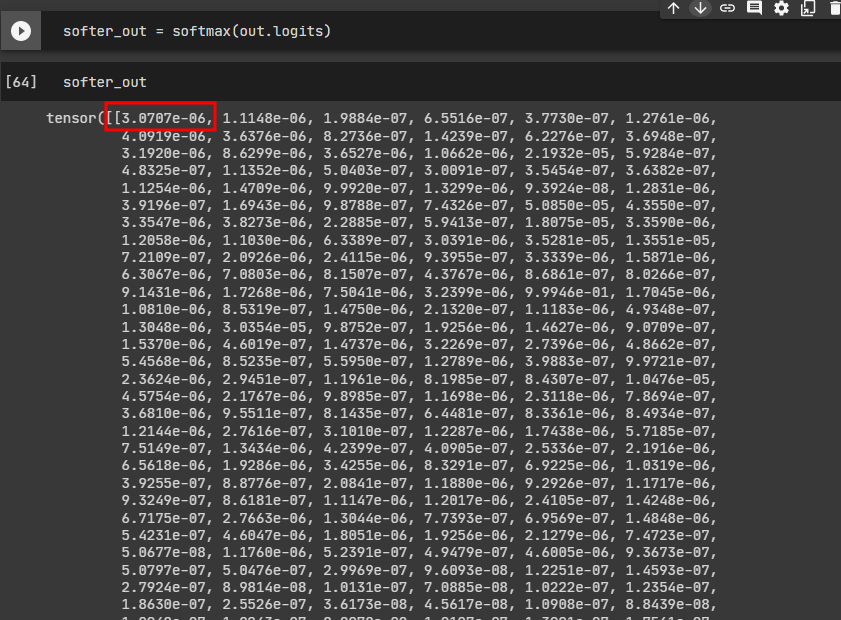
기존 logits 값과 softmax를 통과한 logits값 간의 차이를 직관적으로 확인하겠습니다.
- 분포가 어떻게 변했는지 확인하기 위해 각 배열에서 가장 큰 값과 가장 작은 값의 차이를 비교하겠습니다.

softmax를 통과하기 전, logits 배열에서 가장 큰 값과 가장 작은 값의 차이는 17.87입니다.
softmax 통과 후, logits 배열에서 가장 큰 값과 가장 작은 값의 차이는 0.99입니다.
softmax 통과 후 각 클래스 간의 확률(정답일 확률) 차이가 줄어들었습니다. 분포가 부드러워졌음(soft)을 확실히 알 수 있습니다.
T(Temperature)
T가 적용된 softmax output 공식입니다. 위에서 언급하였듯이, teacher model의 지식인 soft targets은 softmax 함수를 통과합니다. 단순히 softmax를 통과하는 것이 아니라, T라는 매개변수를 적용하여 "얼마나 soft하게 만들지"를 결정합니다.
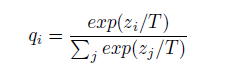
기존의 softmax output과 다른 점은, T로 값을 나눈다는 점입니다. 논문에서 T는 온도(temperature)로 표현됩니다. T가 낮을 수록 더 hard한 분포를 생성하고 T가 높을 수록 더 soft한 분포를 생성합니다.
-
T가 높을 때엔 logits을 zero-mean 처리한 것과 같아집니다. 데이터들의 상대적 위치 관계를 더욱 명확히하는 효과를 얻을 수 있습니다.
-
T가 낮을 때엔 목적 함수는 다른 로짓에 비해 훨씬 값이 작은 로짓에는 집중을 하지 않습니다. 논문에서는 낮은 T를 권장하는데요, 그 이유는 다른 로짓에 비해 값이 훨씬 작은 로짓의 경우 오히려 잡음이 되기 때문입니다. 매우 낮은 로짓값들은 모델이 학습하는 동안 매우 불안정하거나 노이지한 값을 가질 수 있습니다. 특히 모델이 학습하는 데 중요하지 않은 정보를 나타낼 수 있기에, 값이 큰 로짓에 더 많은 비중을 두어 모델의 학습을 안정적으로 유지하는 것이 더 나은 선택일 수 있습니다.
-
적정한 T 값은 경험적이기 때문에 시도해보아야 알 수 있습니다. (논문에선 T=2일 때 가장 좋은 성능)
목적 함수
목적 함수 부분이 DeiT 모델 리뷰와 직접적으로 연관됩니다.
모델은 object function을 통해 학습을 합니다. object function은 실제 정답값과 모델이 예측한 출력값 간의 loss(오차)를 최소화하는 방향으로 학습을 진행합니다. object function의 값이 작다는 것은 오차가 작다는 것을 뜻합니다. 오차가 줄어들 수록 정답을 잘 맞추고 있음을 뜻합니다.
disitllation은 두 개의 object functions을 사용합니다.
최종 목적함수 = 목적함수 A + 목적함수 B
(1) 첫 번째 목적 함수 (A)
실제 정답값과student 모델의 예측값간의 오차를 줄여나가는 방향으로 전개됩니다.- teacher model의 지식을 공부하는 역할
(2) 두 번째 목적 함수 (B)
- 실제 정답값이 아닌 teacher model의 추론값을 soft하게 만든
soft targets과student 모델의 예측값간의 오차를 줄여나가는 방향으로 전개됩니다.
최종 목적 함수는, 두 목적 함수를 가중 평균하여 계산됩니다. 가중 평균을 할 때 각 목적 함수의 가중치를 어떻게 조정하느냐도 중요합니다. 두 번째 목적함수에 대한 가중치를 낮게 설정하는 것을 권장합니다. 그래야만 첫 번째 목적함수가 더 중요하게 작용하기 때문입니다.
두 번째 목적 함수는 아무 것도 모르는 student 모델이 true labels를 맞추는 데 애쓰는 것이지만 첫 번째 목적 함수는 이미 똑똑한 teacher 모델의 추론값을 가지고 student 모델이 공부를 하는 것이기 때문에 더 효율적일 겁니다. 그렇기에 두 목적함수 간의 가중치를 어떻게 조정하느냐도 하이퍼 파라미터가 되겠습니다.
최종 목적 함수를 최소화하는 방향으로 학습이 진행되면서 student 모델이 teacher 모델의 지식을 잘 전달받고 더 나은 성능을 보이게 됩니다. 실제 정답값에 대한 정보(두 번째 목적함수)와 soft targets에 대한 정보(첫 번째 목적함수) 모두 보존하며 학습하기 때문입니다.
중간 정리
DeiT는 이 논문에서 제시하는 대로, teacher model의 soft targets을 student model에게 전수합니다. 온도 T를 사용하여 logits을 soft하게 만들며, 두 개의 목적함수를 사용하여 학습을 진행하는 distillation 기법을 사용합니다. student 모델은 teacher 모델의 추론값(지식)과의 오차를 줄이는 방향으로 학습을 합니다.
여기서부터는 DeiT와는 직접적으로 연관이 없는 부분입니다.
앙상블 모델 지식 증류
Teacher model은 단일 모델이 될 수도 있고 , 여러 모델을 앙상블한 앙상블 모델일 수도 있습니다. 모델을 앙상블하는 것은 너무 많은 컴퓨팅 자원과 테스트 시간을 요구합니다. 논문에서는 앙상블 모델 훈련에 소요되는 컴퓨팅 자원을 줄일 수 있는 방법을 제시합니다.
knowledge distillation과 transfer learning을 구분하고 넘어가겠습니다.
- knowledge distillation은 같은 도메인에서 모델 A가 모델 B에 지식을 전달
- transfer learning은 다른 도메인에서 지식을 전달(예시-사전학습 모델 fine tuning)
we show how learning specialist models that each focus on a different confusable subset of the classes can reduce the total amount of computation required to learn an ensemble.
specialist models
knowledge disitllation은 같은 도메인 내에서 지식을 전달합니다. 따라서 같은 도메인 내에서 혼동되기 쉬운 class 그룹들을 각각의 모델에 할당하여 학습시킵니다. 그러면 그 모델은 자신이 할당받은 class 분류에 특화된 'speacialist model'이 됩니다.
앙상블 모델은 한 개의 generalist model과 다수의 specialist models의 조합입니다.
generalist model은 도메인의 모든 데이터를 학습한 모델이며,
specialist models은 각기 다른 데이터셋으로 전문 특화된 모델입니다.
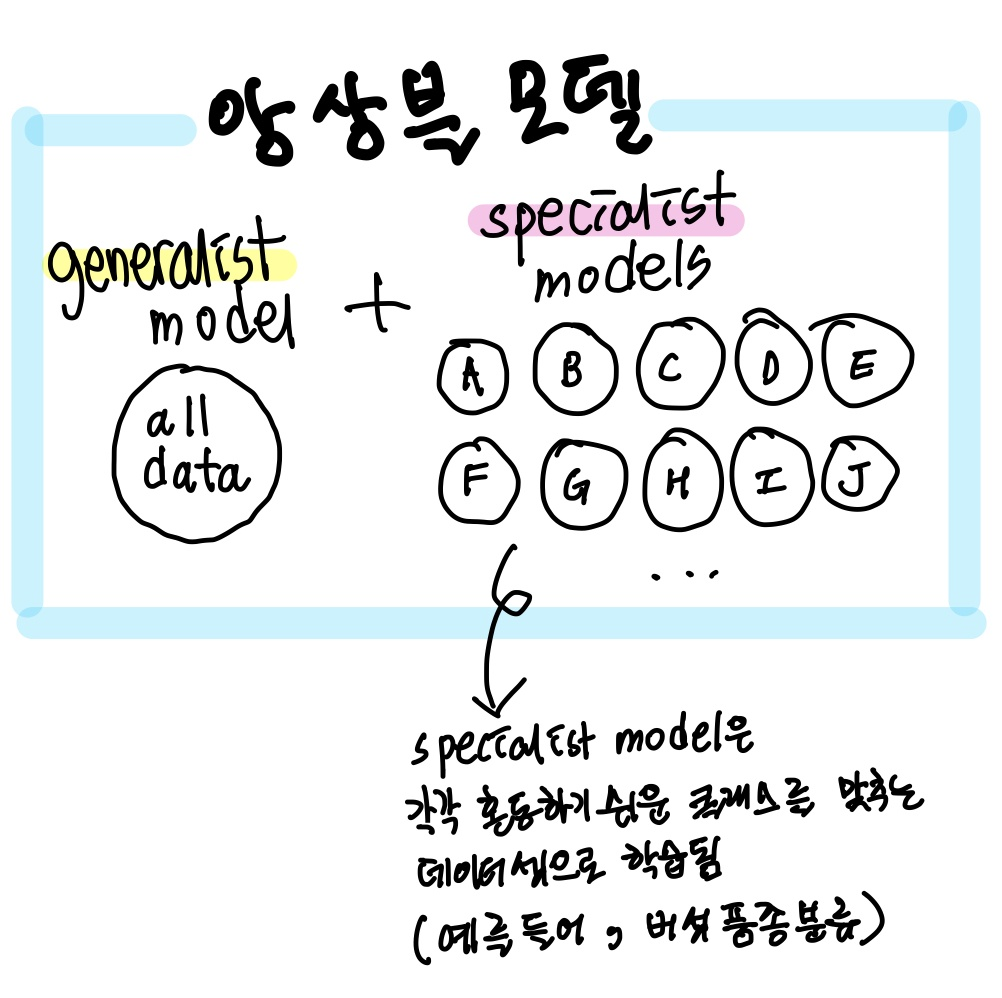
confusable subset
위 인용구에서 의미하는 cofusable subset이란, generalist model이 쉽게 혼동하는 class를 의미합니다. 연구에서는 이를 그룹화하기위해 클러스터링 알고리즘을 적용합니다.
- generaliset model의 preds(예측값)을 k-means와 혼동행렬을 적용하여 클러스터링을 진행하여 그룹화
- 유사도가 높게 클러스터링된 각각의 그룹
- 이 그룹은 specialist model의 targets이 됨
speacialist model은 모두 독립적으로 훈련되었으며, 연구에서는 총 61개의 specialist model을 학습시켰습니다. specialist model들은 각각 300개의 클래스를 구분하는 태스크를 수행했습니다. 모델들이 공부할 부분을 분업한 것이죠.
다음 글에서 DeiT 관련 논문 시리즈의 두 번째 논문인 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(2020)을 리뷰하며 DeiT와 모델 구조가 동일한 ViT 모델에 대해 이해하겠습니다.

3개의 댓글


The "Distilling the Knowledge in a Neural Network" paper proposes a method called knowledge distillation, where a smaller network is trained to mimic the behavior of a larger network. This method can improve the efficiency and generalization of the smaller network. Aetna Medicare Login
이렇게 멋있으면 난 몰랑 ~😣