[DeiT 관련 논문 리뷰] 03-AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
논문리뷰

이번 글에서는 AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(2021)을 리뷰하겠습니다.
본 논문에서는 Vision Transformer(ViT) 모델을 소개합니다. ViT는 DeiT와 동일한 모델 구조를 갖습니다. DeiT 설명과 연결되는 부분만 짚고 넘어가겠습니다.
Vision Transformer
ViT는 vision transformer 모델로, 이름 그대로 vision 분야에서 transformer 아키텍쳐를 이용하여 이미지를 처리하는 모델입니다. Transformer 아키텍처는 자연어 처리 분야에서 뛰어난 성능을 보였는데요, [DeiT 관련 논문 리뷰] 1회에서도 언급했듯이 아쉽게도 vision 분야에서는 Transformer-based 아키텍쳐가 convolutional 아키텍처를 뛰어넘지 못했습니다.
그러나 ViT는 바로 이 한계를 극복한 모델입니다. 단순하게 요약하면 NLP(자연어처리)에서 Transformer를 사용하는 방식과 동일하게 Vision에서도 Transformer를 사용한 모델입니다.
NLP와 Transformer라니.. BERT가 연상되죠? ViT와 BERT는 공통점이 많습니다.
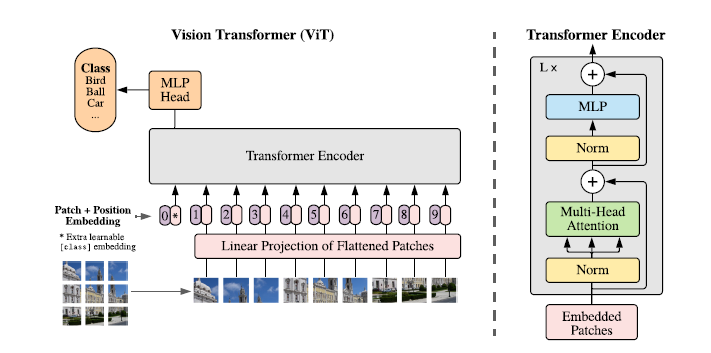
- Transformer encoder 사용
- 입력데이터(text, img)를 일정 크기(text=> token, img=> patch)의 patch로 나누어 처리
- 입력 패치 간의 위치 정보를 embedding하여 모델에 입력
BERT와 동일하지만 단지 입력으로 text data 대신 image patch가 들어간다고 생각하면 편합니다. 물론 차이점도 많습니다. BERT는 masked self-attention을 사용하지만, ViT는 masking을 사용하지 않습니다. 이외에도 더 있지만 이번 글에서는 넘어가겠습니다.
이미지 데이터 transformer 입력 형식으로 변환
텍스트 데이터와 이미지 데이터는 엄연히 형식이 다릅니다. 어떻게 transformer에 이미지를 입력할 수 있을까요?
Linear Projection of Flattened Patches
transformer를 사용할 거면 transformer 입력 형식에 맞게 변환을 해줘야합니다.
텍스트 데이터는 1d array인 반면, 이미지 데이터는 h, w, c라는 3개의 정보를 갖습니다(png라면 1개 더 추가됩니다). 이를 선형적으로 만들어주기 위해 다음의 절차를 거칩니다.
1) 입력 이미지를 고정된 사이즈로 겹치지 않게 decompose
2) 이미지 패치를 flatten하여 linearly projection
3) 이미지 패치에 위치 정보를 더하여 embedding
self-attention은 알아서 위치 정보를 찾아낼 수 없습니다.
위치 정보를 주지 않으면 그저 단순한 행렬곱셈, 내적연산일 뿐입니다. 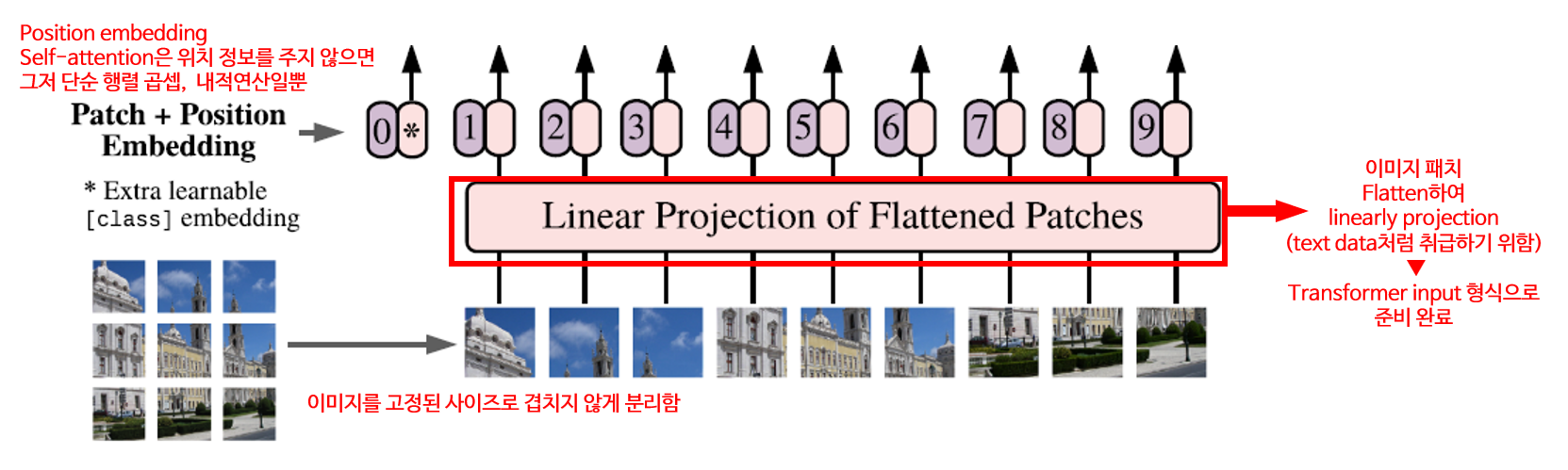
class token
저희가 새롭게 주목해야할 부분이 하나 있습니다. 바로 class token입니다. ViT는 이미지 분류 태스크를 위해 설계된 모델입니다. class token은 모델의 '분류'를 돕습니다.
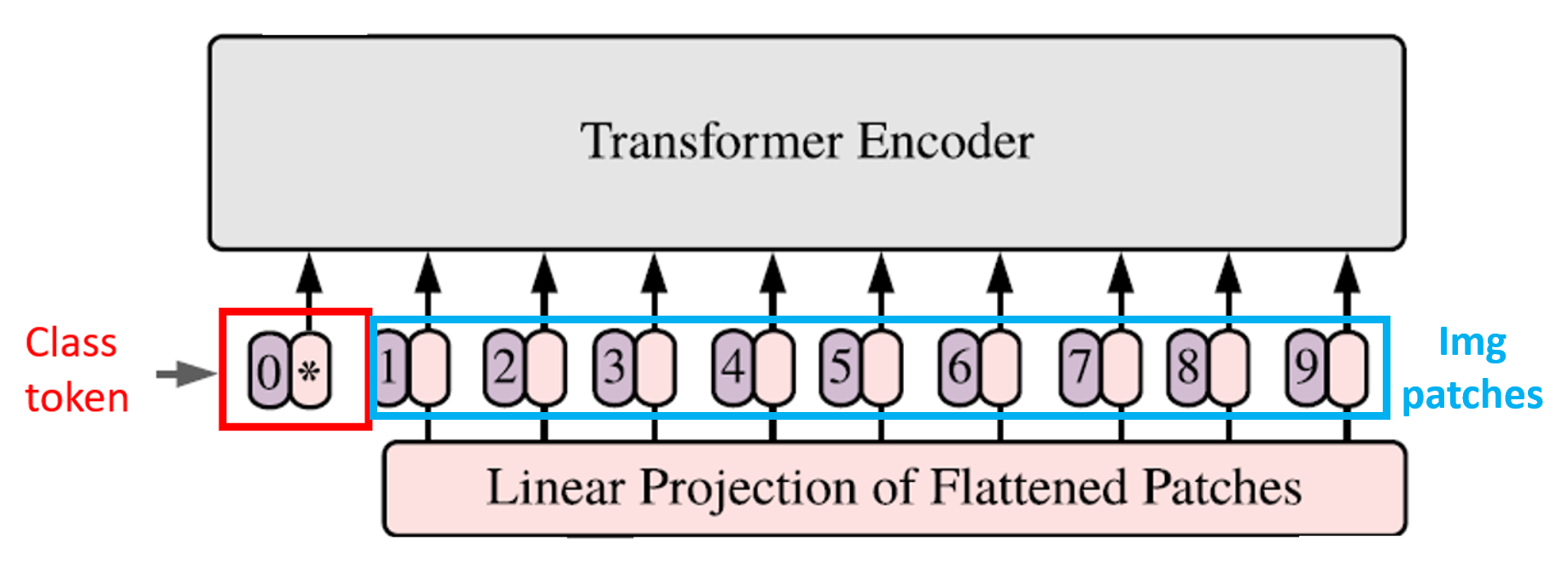
In order to perform classification, we use the standard approach of adding an extra learnable “classification token” to the sequence
0 번째로 들어가는 토큰은 classification token(cls)입니다. BERT 모델이 떠오르지 않나요? BERT도 분류를 위해 cls token을 사용합니다.
image patch는 입력 이미지 전체의 부분들이기에, 모든 층을 다 거치고 난 후 이미지 전체의 일부인 자기 자신에 대한 정보를 더욱 뚜렷하게 갖게 됩니다. 함께 입력된 다른 값과 비교하였을 때 어떤 특징을 가지고 있는지를 표현하게 되는 거죠.
반면 cls token은 입력 이미지의 부분이 아닙니다. 랜덤하게 초기화된 학습 토큰입니다.
torch.nn.Parameter를 사용하면 초기에 모두 zero(0)으로 채워진 행렬이 학습 가능한 파라미터로 초기화하면서 랜덤한 값이 부여됩니다. 학습 가능한 가중치를 갖기 때문에 Transformer를 통과하면서 학습됩니다.
cls 토큰은 transformer 입력 이전에는 엄밀히 말하면 이미지에서 독립적입니다. 그러나 이미지 패치들과 함께 transformer 전체 층을 통과하게 됩니다. cls 토큰은 transformer 전체 층을 다 거치고 나면, 입력 전체를 결합한 의미를 갖게 됩니다.
즉 원래의 입력 이미지 전체에 대한 정보를 가장 잘 표상하는 토큰이 됩니다.이를 통해 모델은 입력 이미지에 대한 분류를 수행할 수 있습니다.
낮은 데이터 효율성
ViT는 데이터 효율성이 낮은 모델입니다. 왜일까요?
높은 성능을 얻기 위해선 무조건 대규모 데이터셋으로 학습해야하기 때문이죠.
ViT를 중간 규모(ImageNet) 데이터셋으로 훈련할 경우 CNN 아키텍처인 ResNet보다 성능이 낮습니다. 이는 다시 Transformer 아키텍처가 vision분야에서 cnn을 뛰어넘지 못했음을 상기시킵니다.
Transformer 아키텍처가 CNN의 inductive bias를 뛰어넘으려면 large scale training 대규모 훈련이 필요합니다. 논문에서도 계속해서 이 모델은 대규모 데이터셋으로 훈련해야 좋은 성능이 나온다고 강조하고 있습니다.
do not generalize well when trained on insufficient amounts of data. However, the picture changes if the models are trained on larger datasets (14M-300M images). We find that large scale training trumps inductive bias. Our Vision Transformer (ViT) attains excellent results when pre-trained at sufficient scale and transferred to tasks with fewer datapoints. When pre-trained on the public ImageNet-21k dataset or the in-house JFT-300M dataset, ViT approaches or beats state of the art on multiple image recognition benchmarks. In particular, the best model reaches the accuracy of 88:55% on ImageNet, 90:72% on ImageNet-ReaL, 94:55% on CIFAR-100, and 77:63% on the VTAB suite of 19 tasks.
ViT를 중간 규모(ImageNet) 데이터셋으로 훈련할 경우 ResNet보다 성능이 낮습니다. 이는 다시 Transformer 아키텍처가 vision분야에서 cnn을 뛰어넘지 못했음을 상기시킵니다. Transformer 아키텍처가 CNN의 inductive bias를 뛰어넘으려면 large scale training 대규모 훈련이 필요합니다. 반면 Convnet구조의 RegNet을 Teacher 모델로 학습한 DeiT는 데이터 효율이 높기 때문에 규모가 작은 데이터셋에서도 좋은 성능을 발휘합니다.
다음 글에서는 본 시리즈의 main인 DeiT 논문을 리뷰하도록 하겠습니다.




이해하려고 읽어봤으나 머리에 과부하가 왔네요 ... Oops 👀