안녕하세요, :)입니다. 저도 1월에 영상처리에 관한 책을 읽은 이후로 2월부터 본격적으로 CV에 관심을 갖게 되었는데요, 지난 달 단순 CNN부터 시작해서 AlexNet, VGGNet, ResNet 등의 architecture을 공부한 뒤, 최근 object detection과 segmentation에까지 관심을 갖게 되었습니다.
다른 논문 리뷰는 사실 리뷰가 아니라 거의 한국어 해석에 가까운 느낌을 받아서, 저는 주관적인 멘트가 좀 들어가는 리뷰를 작성해볼 계획입니다. 다시 말씀드리지만, 이 논문에 대한 '번역'이 아닌 '리뷰' 목적이니 참고해주세요 :)
미리 말씀드릴 사항이 두 가지 있는데요,
1. 이 글을 읽으시는 분이 어느정도 computer vision 분야에 지식이 있다는 가정 하에 쓴 글입니다 (최대한 쉽게 썼지만).
2. 논문의 흐름을 그대로 따른 리뷰기 때문에, 파트별로 함께 보시면 훨씬 효과적일 것입니다.
시리즈에 추가해서 논문 리뷰는 시간이 날 때마다 틈틈이 할 생각인데, LeNet같은 기초 architecture 논문부터 통시적으로 정리해야할지, 지금처럼 이벤트성으로 할지는 고민중이네요.
Abstract
 Semantic segmentation에서는 한 이미지 내에서 full-image의 context를 잡아내는 것이 정말 중요합니다. CCNet은 그러한 contextual information을 효율적으로 잡아내기 위한 방법으로, 십자형 (Criss-Cross) attention module을 모든 pixel에 대해서 적용하게 됩니다.
Semantic segmentation에서는 한 이미지 내에서 full-image의 context를 잡아내는 것이 정말 중요합니다. CCNet은 그러한 contextual information을 효율적으로 잡아내기 위한 방법으로, 십자형 (Criss-Cross) attention module을 모든 pixel에 대해서 적용하게 됩니다.
Attention Module이란 말 그대로, '중요한 부분에 집중하는 방법론'을 뜻합니다. Object detection 같은 분야에서 정말 중요한 개념이죠. 허허벌판에 개미 한 마리가 있는 그림에서 개미를 검출하려면 개미가 있는 부분에 'attention' 해야하니까요.
CCNet은 다음 세 가지 장점을 내세우고 있습니다;
- 기존보다 11배 낮은 GPU 사용량을 요구합니다.
- RCCA 과정은 기존의 full image dependency에 대한 계산을 획기적으로 줄입니다.
- 예술적인 정확도를 자랑합니다.
(모든 논문에서 내세우는 장점)
특히, 2. 에서의 RCCA라는 과정은 3. Approach에서 상술됩니다.
1. Introduction
Semantic segmentation에서는 각 화소에 대한 class label을 부여하는데, 여러분도 아시다시피 이에 대해서 많은 연구가 이뤄지고 있죠. 특히 FCN (Fully Convolutional network)가 이 분야에 있어서 굉장히 성공적이지만 맹점이 있다고 말합니다.
 바로, 구조상 'local한 receptive field와 context-short한 정보에 국한된다는 점' 입니다.
바로, 구조상 'local한 receptive field와 context-short한 정보에 국한된다는 점' 입니다.
이 리뷰가 FCN을 포함한 다른 method를 위한 리뷰는 아니기 때문에, 중요하지 않은 '왜?'는 일단 생략하겠습니다.
Receptive field 는 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기입니다.
일반적인 convolution에서 receptive field 는 좌측 입력레이어의 중앙 진분홍색 공간이 됩니다.
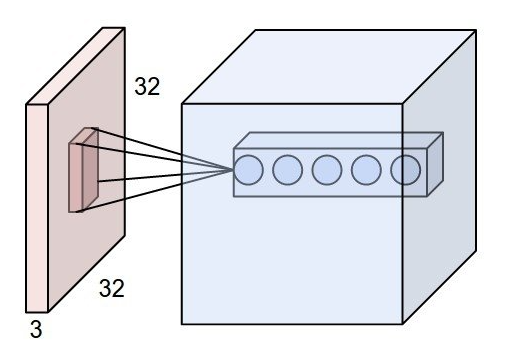
이를 개선하기 위해 나온 것이 ASPP(Atrous Spatial Pyramid Pooling)입니다. 이로 인해 wide receptive field와, 얕은 층을 얻을 수 있게 되었습니다.
Astrous는 dilated (팽창된)과 동의어로, conv의 kernel을 dilate시키는 방법입니다.
※Morphology에서의 dilation과는 관련이 없습니다.
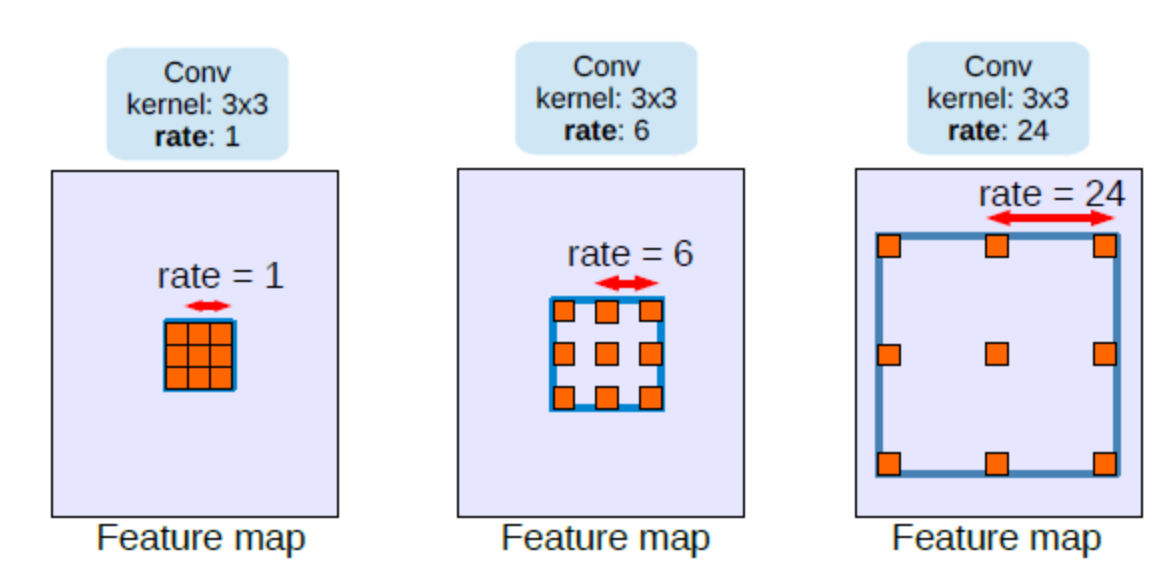
하지만 kernel이 dilated 되어버리니 인접한 화소 중 대부분을 놓치고, dense contextual information을 잡아내지 못하게 됩니다. 결론적으로,
kernel이 sparse하면 receptive field가 넓어지지만 context를 잃고,
kernel이 dense하면 정보의 손실이 거의 없으나 모든 이미지 화소를 고려해야해서 효율이 떨어지게 됩니다.
이에 대한 도전장으로 dense하면서 pixel단위 context까지 잡아낼 수 있는 방법을 PSANet이 고안했으나, O((HxW)X(HXW)) (Big O 표기법)라는 비효율적인 GPU 연산이 단점입니다.
CCNet은 결국, feature map이 dense하지 않으나 dense한 효과를 얻고, GPU 연산이 효율적이며 contextual information을 잡아낼 수 있는 모델을 제시한다는 스토리텔링이 되겠네요.
※ Feature map : input에 conv filtering을 적용하여 나온 결과
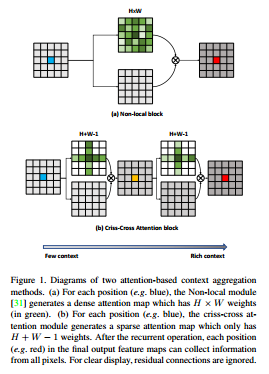 하지만 CCNet은 (H+W-1)이라는 feature map의 모든 위치에서 sparse한 connection을 가진 attention module을 두 개 사용함으로써 O((HxW)X(HXW)) -> O((HxW)X(HXW-1))로 Big O를 단축하게 됩니다.
하지만 CCNet은 (H+W-1)이라는 feature map의 모든 위치에서 sparse한 connection을 가진 attention module을 두 개 사용함으로써 O((HxW)X(HXW)) -> O((HxW)X(HXW-1))로 Big O를 단축하게 됩니다.
이 논문의 꽃인 십자형(CC, Criss-Cross)이 나오네요. 위 그림의 (b)를 보면, feature map(파란점이 있는)에 H+W-1의 가중치를 가진 십자형 attention module이 적용되어 attention map(주황점이 있는)을 1차 생성한 뒤, 같은 과정을 한 번 더 반복하여 최종 attention map(빨간점이 있는)을 생성합니다.
※ Attention map은 좀 생소하실 수 있는데요,
 결론적으로 feature map인데 attention하는 부분이 있는 map입니다!
결론적으로 feature map인데 attention하는 부분이 있는 map입니다!
여기서 Big O 내부가 고작 -1 차이라 와닿지 않을 수 있는데요, H와 W는 spatial dimension, 즉 가로 세로 길이입니다. 보통 가로 세로가 몇백 이상인 점을 감안하면, GPU 연산에선 큰 차이를 가져올 수 있다고 생각이 들었습니다.
또한 masking에서 아이디어를 얻은 기법이라는 확신이 드는게, 사실 서술한 대로 sparsity와 context만 문제였다면 x (대각선 방향) 모양이나, 중간이 뚫린 사각형 모양 등을 고안했을 법 한데 (두 개를 연속으로 붙이면 sparsity와 each pixel에 대한 고려문제 모두 해결되는건 마찬가지기 때문에) 굳이 십자형을 선택했네요.
아무래도 edge detection이나 blurring 등에서 사용하는 마스크가 Criss-Cross 형태가 보편적이라는 점에서 착안한 것 같습니다.CNN은 영상 영상 처리의 연장선상이니까요.
마지막으로, 두 가지 장점을 강조하고 있네요.
- Full-image dependencies에서 contextual information을 효율적으로 추출
- Cityscapes와 ADE20K 데이터셋에서 훌륭한 스코어 (mIoU)
사실 segmentation dataset에는 COCO 등 유명한게 많고 논문 뒷편에도 많이 언급되어 있는데, 이 두 가지에서의 mIoU만을 강조하는 점은 비판적으로 볼 필요가 있습니다.
2. Related Work
탄생 배경에 가까운 파트라 코멘트를 달게 딱히 없어 요약하고 넘어가겠습니다.
<Semantic segmentation>
FCN이 선조격으로 semantic segmentation에 붐을 가져왔습니다.
이후 FCN-based method들이 dilated convolution을 사용하면서도 dense함을 유지하기 위해, 마지막 두 개의 downsample layers를 삭제했습니다.
Unet, DFN 등이 low-level과 high-level layers에서 정보를 종합할 수 있도록 encoder-decoder 구조를 사용하기 시작했습니다.
SAC 등이 객체의 손실을 방지하기 위해 convolutional operator를 개선시켰습니다.
CRF-RNN, DPN 등이 인접 화소와의 관계를 파악하는 법을 배우기 시작했습니다.
BiSeNet은 실시간 sematic segmentation의 장을 열었습니다.
<Contextual information aggregation>
Deeplabv2는 서로 다른 dilation convolutions를 이용하여 contextual information을 종합하는 ASPP 모델을 제시했습니다.
DenseASPP는 ASPP에 dense connection을 안겨주었습니다.
PSPNet이 contextual information을 종합하기 위해
pyramid pooling 방식을 채택했습니다.
GCN은 pyramid pooling의 적용 영역을 global로 넓혔습니다.
Liu et al.은 장기 dependencies를 잡아내기 위해 RNNs도 활용했습니다.
CRF와 MRF 또한 semantic segmentation을 위한 장기 dependencies를 잡아내는 데에 주력했습니다.
<Attention model>
Squeeze-and-Excitation Networks가 attention mechanism에서 채널 단위 관계 파악에 대한 설명력을 개선했습니다.
DenseASPP는 ASPP에 dense connection을 안겨주었습니다.
Vaswani et al.은 self-attention model을 기계 번역에 도입했습니다.
Wang et al.이 correlation matrix 계산을 통해 attention map을 구함으로써 contextual information을 종합하는 non-local module을 제시했습니다.
PSA는 attention map을 학습하여 적응적/구체적으로 각 포인트에 대한 contextual information을 종합했습니다.
<CCNet vs. Non-Local vs. GCN>
GCN (Graph Convolutional Network)은 contextual information을 종합하지만, 오직 중심화소만 모든 픽셀에 대한 정보를 종합할 수 있습니다.
반면, Non-local Network와 CCNet은 각 화소가 모든 픽셀에 대한 정보를 담고 있음을 보장하고 있습니다.
GCN도 CCNet처럼 가로-세로 단위로 convolutional operation을 하긴 하지만, CCNet처럼 십자형이 아닌 가로, 세로로 분리되어있기 때문에 덜 효율적이라 주장합니다.
결론적으로, CCNet은 Non-local Network의 전체 context에 대한 이점과 GCN의 효율적인 가로-세로 연산이라는 이점을 챙겼다고 볼 수 있겠네요.
3. Approach
계속 이 논문이 강조하는 부분은 바로 'CCNet은 십자 모양 attention module을 통해서, dense하면서도 global한 contextual information을 캐치할 수 있다' 입니다.
이 파트에선 CCNet의 전반적인 구조에 대해서 이야기하게 됩니다.
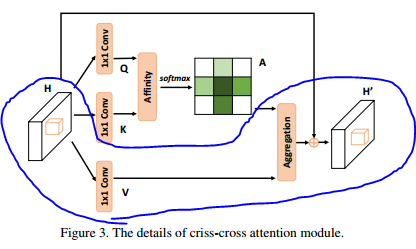
3.1 Network Architecture
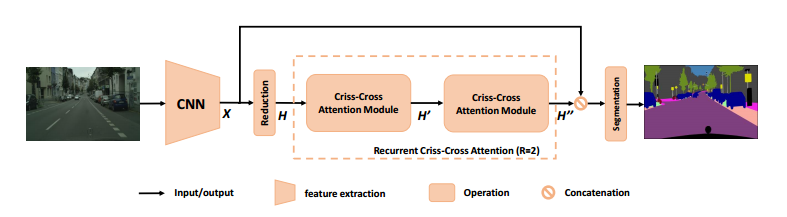 CCNet의 overview입니다. 논문에서도 세 단락으로 구분지어 설명하고 있기 때문에 저도 단락 기준으로 설명드리겠습니다.
CCNet의 overview입니다. 논문에서도 세 단락으로 구분지어 설명하고 있기 때문에 저도 단락 기준으로 설명드리겠습니다.
1. Feature Map Creation
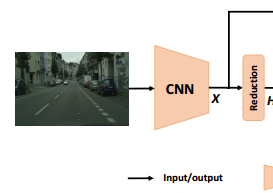
Segmentation하고자 하는 이미지를 input으로 CNN cell에 넣으면, feature map X가 산출됩니다. X의 spatial size는 H x W입니다.
Dense feature maps는 유지하면서 효율적으로 계산하기 위해, 마지막 두 개의 downsampling operations는 제거하고 이어지는 dilated convolutional layer를 통해 사이즈가 1/8로 줄어들도록 (Reduction) 했습니다.
(솔직히 downsampling operations 제거는 FCN을 모방한 티가 너무 나네요)
2. RCCA
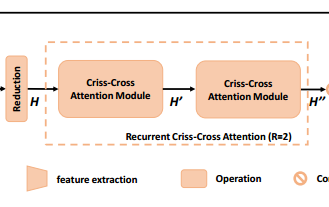
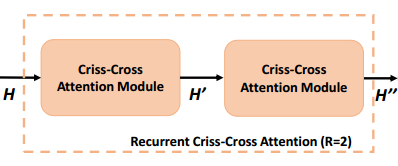
CCNet에서 가장 중요한 파트로, Criss-Cross attention module이 직접적으로 사용되는 과정입니다. Module 두 개를 consecutive하게 이어붙였기 때문에 이를 RCCA (Recurrent Criss-Cross Attention)이라고 부릅니다.
위에서 dimension reduction된 feature maps는 H입니다.
이제, H는
- criss-cross attention module로 들어간 뒤
- 십자 방향에 있는 각 픽셀들이 contextual information을 종합하는 feature maps H'을 생성합니다.
H를 넣어 H'을 생성한 것과 마찬가지로, H'을 다시 넣어 H''을 생성하게 됩니다. 이로써, H''은 모든 픽셀에 대한 정보를 종합하게 됩니다.
3. Segmentation
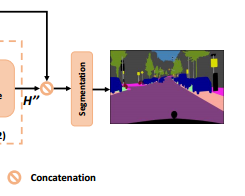
이제 feature map H''를 local representation feature인 X와 concatenate(연쇄)합니다. 이후에는 batch normalize나 activation function layer를 추가하고 마지막에 segmentation layer를 추가하는 일반적인 마무리를 하게 됩니다.
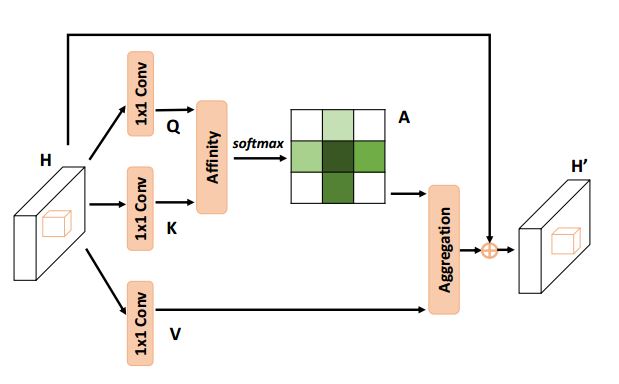
3.2 Criss-Cross Attention
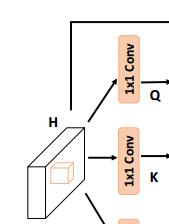
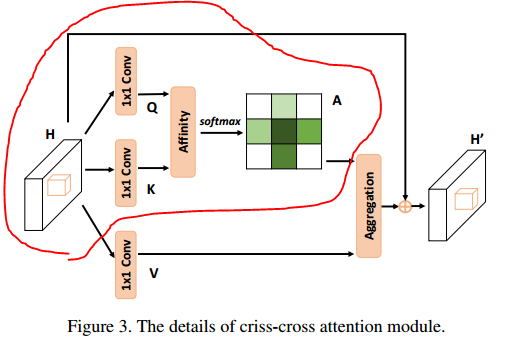 빨간색으로 둘러싸인 부분을 먼저 설명하겠습니다.
빨간색으로 둘러싸인 부분을 먼저 설명하겠습니다.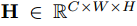 위 조건을 만족하는 feature maps H를 시작으로,
위 조건을 만족하는 feature maps H를 시작으로,
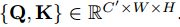 1x1 convolutional layer에 통과시켜 위 조건을 만족시키는 새로운 feature maps Q, K를 생성합니다.
1x1 convolutional layer에 통과시켜 위 조건을 만족시키는 새로운 feature maps Q, K를 생성합니다.
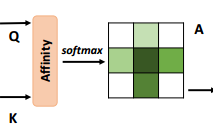
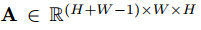 Feature maps Q와 K의 Affinity 연산을 통해, 위 조건을 만족시키는 attention maps A를 생성합니다.
Feature maps Q와 K의 Affinity 연산을 통해, 위 조건을 만족시키는 attention maps A를 생성합니다.
※이 부분에서 말하는 'Affinity operation'은 Affine transformation과는 무관하다는 점 유의하시길 바랍니다.
Affinity operation이란,
Feature maps Q의 vector인 Qu와, Feature maps K의 feature vectors인 Ωu의 i번째 원소인 Ωi,u를 transpose(전치)한 것을 내적하는 연산입니다.
이렇게 계산하게 되면 di,u는 feature Qu와 Ωi,u 사이의 상관계수 정도를 나타내는 지표가 됩니다.

이 di,u가 속한 집합인 D에 channel dimension으로 softmax layer을 적용하면 attention map A를 계산하게 되는 것입니다.
파란색으로 둘러싸인 부분을 보면,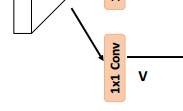
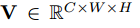 1x1 convolutional layer에 통과시켜 위 조건을 만족시키는 새로운 feature maps V를 생성합니다. 이 V는 위의 Q, K와는 역할이 조금 다른데요, feature adaptation을 위해 따로 생성되는 것입니다.
1x1 convolutional layer에 통과시켜 위 조건을 만족시키는 새로운 feature maps V를 생성합니다. 이 V는 위의 Q, K와는 역할이 조금 다른데요, feature adaptation을 위해 따로 생성되는 것입니다.
Feature adaptation이라는 용어가 저도 생소해서 따로 찾아봤는데, 그 어디에도 일반적인 레퍼런스가 없었습니다. 이 정도면 어떤 개념인지 살짝 설명하고 갔으면 좋았을텐데 하는 아쉬움이 있네요.
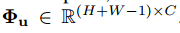 Φu는 V의 feature vectors의 collection set입니다. 이제, 마지막으로 Aggregation을 하게 됩니다.
Φu는 V의 feature vectors의 collection set입니다. 이제, 마지막으로 Aggregation을 하게 됩니다.
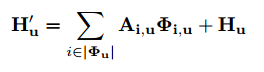 빨간색 파트에서 attention map이었던 A와,
빨간색 파트에서 attention map이었던 A와,
파란색 파트에서 feature vectors의 collection set이었던 Φ가
'위치 u에 대해서' '곱의 형태'로 'i번째 채널에 대한 시그마'로 표현되었습니다.
따라서 H'u는 feature maps H'의 위치 u에 대한 feature vector가 되겠군요.
Local feature인 H도 위치 u에 대해서 더해지고 있는데, 이는 지역성과 픽셀 단위의 대표성을 증강시키기 위함이라고 합니다.
어디까지나 H라는 feature map에서 본인들이 제시한 criss-cross attention modul을 사용하여 H'라는 feature maps를 만들기 위한 연산의 과정을 풀어쓴 것이라는 것을 기억하셔야 합니다.
Feature maps라는 것이 사실 feature vector의 집합으로 이루어진 것이니 논문에선 내부 연산을 보이기 위해서 위치 u에 대한 vector 연산으로 설명을 했는데, 결론적으로 저 H'u와 Hu에 대한 관계식은 H -> H'에 대한 관계식을 대표적으로 설명한 것이라고 볼 수 있습니다.
확실히 segmentation에 대한 지식이 있어도 attention에 대한 개념이 부족하면 이해하기 힘든 논문이네요 ㅜㅜ
3.3 Recurrent Criss-Cross Attention (RCCA)
3.1 Network Architecture파트에서 사실상 이미 다뤘던 RCCA입니다.
방금 봤던 Criss-Cross Attention가 다음과 같이 연속으로 붙어있는 구조였죠.
 조금 수학적으로 따지고 들어가보겠습니다 ㅎㅎ
조금 수학적으로 따지고 들어가보겠습니다 ㅎㅎ
 A는 attention map이죠. 이때, x', y'로부터 Ai,x,y라는 가중치로의 'mapping' function은 다음과 같습니다.
A는 attention map이죠. 이때, x', y'로부터 Ai,x,y라는 가중치로의 'mapping' function은 다음과 같습니다.
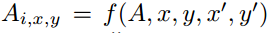
순간 mapping function이 뭔가 했습니다만, 영상처리에서 image를 평행이동하거나 회전할 때 사용하는 용어 'mapping'과 같은 맥락이라는 것을 깨우쳤습니다.
한국어로는 '(순방향/역방향) 사상'이라고 하는데요, x',y' -> x,y로의 mapping은 순방향 사상입니다.
결론적으로는 A(attention map), x&y(사상 후 좌표), x'&y'(사상 전 좌표)을 변수로 갖는 함수 f를 통해 Ai,x,y라는 가중치를 알 수 있다는 것입니다.
이 부분은 마지막 이론 부분이면서, 제가 유일하게 이 논문에서 이해하지 못한 파트입니다. 고수분들의 날카로운 지적을 부탁드리겠습니다! ㅜㅜ
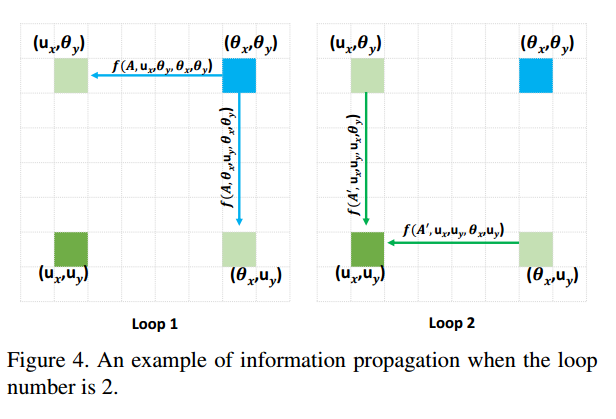
u와 θ를 각각 H''와 H에서의 어느 위치라고 두면,
<u와 θ가 같은 row or column에 있을 때>
<u와 θ가 다른 row or column에 있을 때>
이를 그림으로 나타내보면 다음의 information propagation의 과정이라고 합니다.
하하,, 정말 수십 번을 들여다 봤는데 2021년 03월 09일의 안준영은 모르겠다고 합니다. N일 뒤의 안준영이 와서 해결해주길 바랍니다 ㅜㅜ
4. Experiments
하드한 이론 부분이 다 끝나고 이젠 score 자랑만 남았습니다 :)
이 부분은 전반적으로 편하게 그렇구나 하고 읽으시면 되겠습니다!
4.1 Datasets and Evaluation Metrices
Datasets
- Cityscapes (도시 segmentation을 위한 데이터, 2975/500/1525 순으로 training, validation, testing)
- ADE20K (150개의 카테고리 레이블을 가진 최근 장면 데이터, 20K/2K/3K 순으로 동일)
- COCO (instance segmentation에서 굉장히 도전적인 데이터, 115K/5K/20K 순으로 동일)
Evaluation Metrics : mIoU (mean of Intersection over Union)
4.2 Implementation Details
SGD와 mini-batch를 트레이닝에 사용했습니다.
1e-2의 learning rate를 사용했으며, momentum은 0.89에 decay는 0.0001이었습니다.
Cityscapes 데이터에 한해서, 0.75부터 2까지 random-scaling을 진행했습니다.
ADE20K에 대해서는 Mask-RCNN과 같은 설정을 사용했습니다.
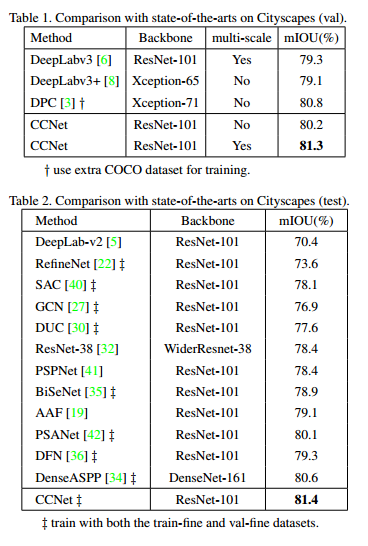
Cityscapes Score
Backbone의 역할이 명확하지 않네요..
 아래는 context aggregation에 대한 평가입니다.
아래는 context aggregation에 대한 평가입니다.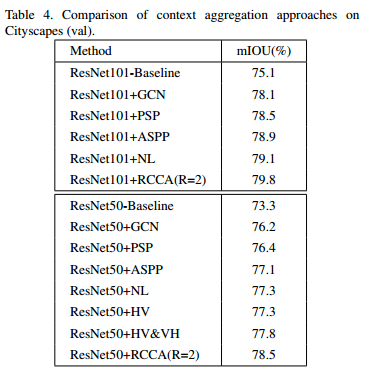
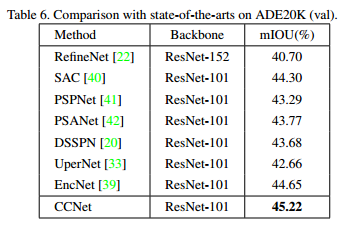
ADE20K Score
COCO Score
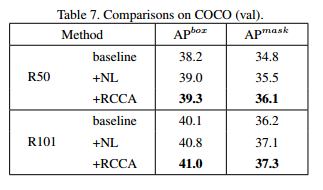
솔직히 전 분야에서 score 자체는 크게 차이가 나지 않습니다. ILSVRC 대회도 아니고, mIoU가 0.xx 차이나는 정도면 사실 low-computational load를 요구하는 모델을 사용하는 것이 맞겠네요.
Big O 표기법을 봤을 때 CCNet이 기존의 FCN보단 뛰어남을 확인했으나, 다른 모델과도 추후 비교가 필요한 부분인 것 같습니다.
5. Conclusion and Future Work
놀랍게도 본인들의 RCCA가 혁신적임을 강조하고 끝이 나버립니다.
결론
CCNet은 확실히 기존의 density 때문에 효율성을 놓치거나, sparsity 때문에 local하거나 contextual한 information을 놓치는 경우들을 많이 보고 개선시킨 모델이라고 생각이 듭니다.
Criss-Cross attention module을 사실 한 번만 사용하면 나중에 큰일이 날 수도 (sparsity 개선이 안되기 때문에) 있었는데, 영리하게 두 번을 사용함으로써 전 pixel에 대한 정보를 가져오면서 Big O time comsumption은 줄였습니다.
생각보다 Related Work 파트에서 CCNet을 GCN, Non-local block과 함께 엮어서 스토리텔링한 부분이 마음에 들었습니다.
Runtime까진 아니더라도 본인들이 computational efficiency를 어필한 만큼 그것에 관한 comparison table도 좀 있었어야 하지 않나 싶네요.저자들이 의도적으로 숨긴 것일 수도 있지만요.
제 semantic segmentation 입문 논문이기 때문에 전반적으로 마음에 듭니다. 다음에 한 번 써봐야겠네요 :)
++ 여담으로,,,
같은 1층짜리 CNN을 짜도, 깊이는 사람에 따라 엄청 차이가 나는 것 같습니다.
누구는 stride, padding의 역할을 완벽히 이해하고 여러가지 parameter를 세심히 조절하는 반면,
누구는 평소 습관대로 filter는 64정도에 kernel size도 (3, 3)으로 대충 둬버릴 지도 모릅니다.
CNN이 자신의 당면한 문제를 해결하기 위한 임시방편정도라면 후자의 길도 나쁘지 않을 지도 모릅니다.
하지만 CNN을 통해서 정말 많은 것을, 깊이 이루고 싶다면 전자를 추구해야하지 않을까요?
이 포스트는 전자의 성향에 가까우나, 결국은 전자와 후자 사이 그 어딘가에 있는 사람들을 위한 것입니다.
CCNet은 십자 모형의 attention module 두 개를 연속적으로 사용하는 segmentation model이라는 것 정도만 알고, python에서 코드만 작성하실 줄 아셔도 될 지도 모릅니다.
그러나 CCNet의 세밀한 분석을 통해 CCNet 그 이상의 것을 얻을 수도 있지는 않을까요?
이 포스트가 여러분에게 CCNet에 대한 정보전달 뿐만 아니라 학습에 대한 '태도'에까지 영향을 줄 수 있길 바라며, 포스트를 마쳐보겠습니다. 감사합니다 :)
Citation
Huang, Z., Wang, X., Huang, L., Huang, C., Wei, Y., & Liu, W. (2019). Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 603-612).

https://bothbest.amebaownd.com/
https://bambooflooring.alboompro.com/blog
https://bambooflooring.shopinfo.jp
https://bamboochopsticks.storeinfo.jp
https://chinabamboo.therestaurant.jp/
https://bamboodecking.themedia.jp/
https://bambooplywood.localinfo.jp/
https://bambooplywood.localinfo.jp/posts/57493303
https://bamboodecking.themedia.jp/posts/57493294
https://chinabamboo.therestaurant.jp/posts/57493283
https://bambooflooring.univer.se/
https://bambooflooring.univer.se/blog-post
https://bambooflooring.theblog.me/
https://bambooflooring.theblog.me/posts/57484393
https://japanbamboo.storeinfo.jp/
https://japanbamboo.storeinfo.jp/posts/57484082
https://bambooflooring.omeka.net/
https://bambooflooring.omeka.net/items/show/1