
안녕하세요, JJun입니다. 활동명을 :)에서 JJun으로 바꾼 뒤 처음으로 작성하는 포스트라 기분이 새롭네요 ! 제 닉네임이 이모티콘과 겹치다 보니 대화할 때나 소개할 때 불편한 사항이 있어서 바꾸게 되었습니다.

위 사진처럼, 공공시설 출입 시에 방문객이 마스크를 썼는지 안썼는지 판단해주는 장치를 보신 적이 있을 겁니다.
이는 AI가 얼굴에 있는 마스크라는 객체를 감지하는 object detection 기술인데, YOLO는 실시간 object detection의 선두주자인(SOTA라고 하죠) 모델입니다.
이번 논문 리뷰는 리뷰보다는 요약 및 해설에 조금 더 치중할 예정입니다.
제가 YOLOv1을 읽은 목적이 yolo의 기본 작동 원리를 파악하고 싶어서였기 때문에, 이를 중점적으로 다루며 타 모델과의 성능 비교(논문 후반부)는 생략하게 됩니다.
※ Deep Learning (특히 CNN) 중 object detection 기술에 대한 전반적인 이해만 있으면 이해할 수 있도록 작성하였습니다. 또한 YOLO 논문과 같은 목차 순서로 작성했으니, 논문과 함께 읽으면 이해하기 좋습니다.
Abstract
기존의 object detector들은, classifier를 detection을 수행하기 위한 목적으로 사용했습니다. (R-CNN에서 CNN을 거친 feature map들이 SVM을 통해 분류되는 것이 예시입니다.)
하지만 YOLO는 object detection을 1) 공간적으로 분리된 bounding box, 2) 이와 연관된 class probability를 계산할 수 있도록 regression 으로 간주합니다.
또한, 단일 네트워크를 가진 모델로서 end-to-end 방식으로 직접 최적화될 수 있습니다.
Localization이 조금 떨어질 수 있지만, 배경에 대해 Type 1 error(false positive)를 범할 가능성이 낮으며 속도와 mAP(mean Average Precision)또한 당시 타 모델에 비해 월등했습니다.
1. Introduction
YOLO 이전의 detector였던 DPM, R-CNN과 어떻게 다른지 설명합니다.
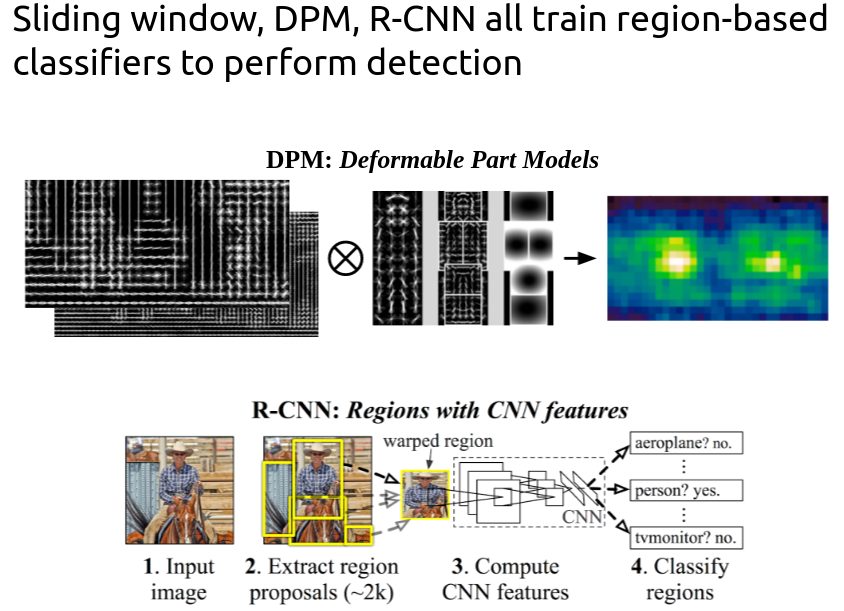
<DPM과 R-CNN의 outline>
DPM은 sliding window 방식으로

이미지 픽셀 (특정 픽셀을 건너뛰고)마다 sliding window 방식으로 bbox를 그립니다. 이렇게 되면 classifier가 똑같은 크기의 공간을 (원문 - evenly spaced locations) 모두 돌아야 하는데, cost가 너무 많이 나가겠죠.
이후 대표적인 2-stage detector인 R-CNN은 sliding window의 문제점을 보완하기 위해, region proposal 방식을 도입합니다.
<2-stage detector란?>
- Region proposal
- Region classification <- 이와 같이 2중 구조를 띄고 있는 탐지기
Region proposal 중에서도 selective search를 사용합니다.
Segmentation의 개념까지 들어가는 방식이라 설명하기엔 복잡해져서 하이퍼링크를 달아두었습니다.
쉽게 말하자면 많은 bbox를 우선 생산한 뒤, greedy algorithm을 사용해서 객체가 담긴 큰 bbox로 merge시키는 방식입니다.
하지만 이 방법도 각 요소를 개별적으로 학습시켜야하기 때문에, 최적화가 어렵고 파이프라인 자체가 매우 느려진다는 단점이 있습니다.
YOLO는 이러한 단점이 없는 one-stager입니다.
독특한 점은, obejct detection 문제를 classification이 아닌 regression에 해당하는 문제로 치환한다는 것입니다.
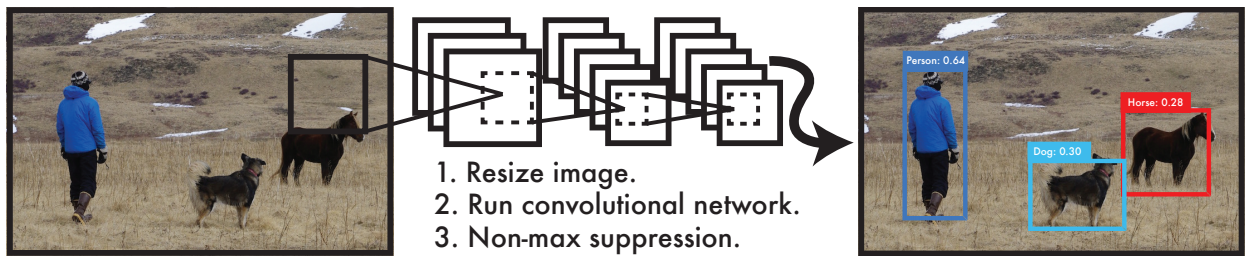
위 그림에 나와있듯이, YOLO는
- 이미지를 448x448로 morph하고
- 단일 conv net을 돌려 bbox들과 그에 대한 class probability를 예측 (regression),
- NMS(Non-Maximum Suppression)를 통해 최종 detection을 수행
따라서 동작 시간이 매우 빠르고, sliding window나 region proposal과 같은 context 손실도 없으며 객체의 generalizable representation을 학습합니다 (= train과 사뭇 다른 도메인의 이미지로 test를 해도 잘 예측).
2. Unified Detection
 다시 강조하고 시작하는 것은 이미지를 통째로 넣음으로서 global한 특성을 반영하여 detection할 수 있다는 점입니다.
다시 강조하고 시작하는 것은 이미지를 통째로 넣음으로서 global한 특성을 반영하여 detection할 수 있다는 점입니다.
이제 YOLO가 어떻게 동작하는지 설명하겠습니다.
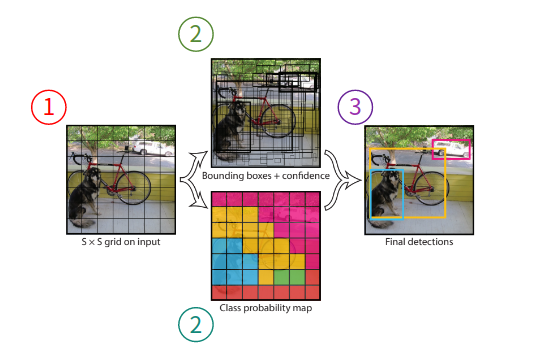

1. S x S grid on input
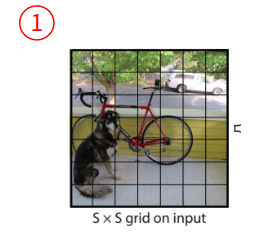
우선, input image 위에 가로 및 세로로 각각 S개의 격자를 그리게 됩니다.

각 격자는 1) bbox와 2) 각 bbox에 대한 신뢰도 점수를 예측합니다.
신뢰도 점수는 1) bbox가 객체를 포함하는지에 대해 신뢰성이 있는지와 2) bbox가 얼마나 정확한지를 반영합니다.
위 공식을 통해 confidence score가 객체의 존재 여부와 bbox의 정확도를 동시에 평가하는 지표가 됨을 알 수 있습니다.
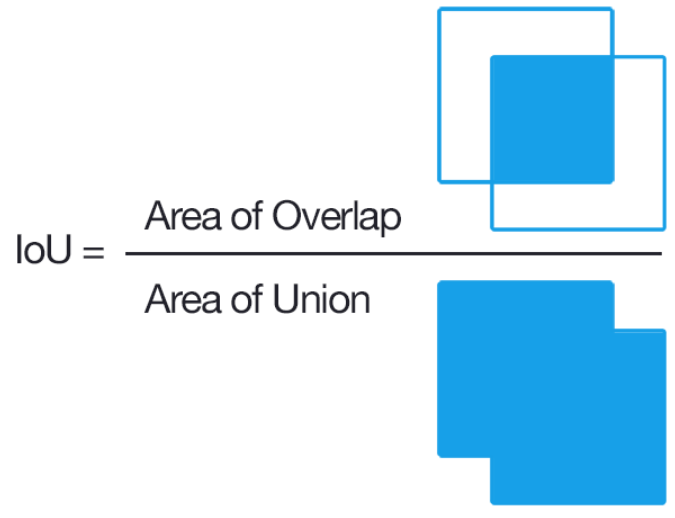
※IoU는 Intersection over Union으로서 bbox의 위치 정확도 평가 지표
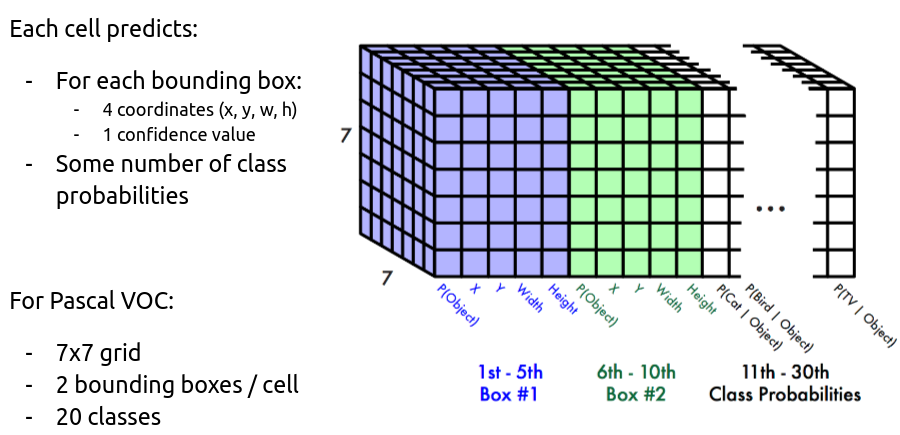
2. Bbox + confidence & class probability
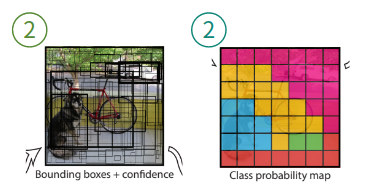 이전 단계에서 언급했듯이, 각 grid cell은 bbox와 confidence score을 예측합니다. 여기에 더해서 class probability까지 예측하게 됩니다.
이전 단계에서 언급했듯이, 각 grid cell은 bbox와 confidence score을 예측합니다. 여기에 더해서 class probability까지 예측하게 됩니다.
 bbox는 중심인 (x, y) 좌표, 높이와 너비 (w, h) 정보, 그리고 IoU 총 5개의 변수에 대한 예측을 진행합니다.
bbox는 중심인 (x, y) 좌표, 높이와 너비 (w, h) 정보, 그리고 IoU 총 5개의 변수에 대한 예측을 진행합니다. 2.1 Network Design에서 상세하게 설명됩니다
 더불어 '객체가 있다고 가정할 때, 특정 객체 (class)일 확률'이라는 조건부 확률을 예측합니다. YOLO는 20개의 class를 지원하기 때문에 C1 ~ C20까지 총 20개의 확률 정보를 담고 있습니다.
더불어 '객체가 있다고 가정할 때, 특정 객체 (class)일 확률'이라는 조건부 확률을 예측합니다. YOLO는 20개의 class를 지원하기 때문에 C1 ~ C20까지 총 20개의 확률 정보를 담고 있습니다. 역시 2.1 Network Design에서 상세하게 설명됩니다
Test를 할 때에는, 특정 클래스에 대한 신뢰도 점수를 구하기 위한 공식을 사용합니다.
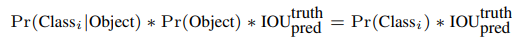
3. Final detections
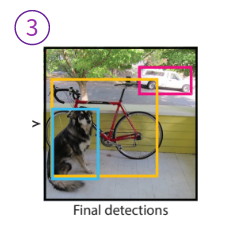
마지막으로 NMS를 통해 최종 detection을 결정내립니다. 여기까지가 YOLO가 어떻게 작동하는지를 개략적으로 설명한 파트고, 이번 포스트의 핵심인 network design으로 넘어가보겠습니다.
2.1 Network Design
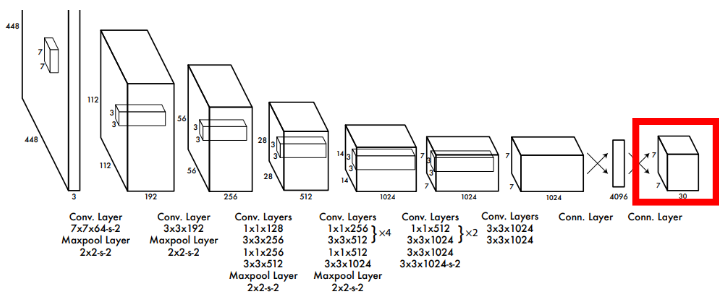
네트워크는 총 24개의 convolution layer와 2개의 fully connected layer로 구성 되어있습니다.
중간중간에 max-pooling layer와 feature map의 demension을 줄이기 위한 (= parameter 수를 줄이기 위한) 1 x 1 convolution layer가 있습니다. 빨간 테두리로 감싼 output을 자세히 보겠습니다.
우선 output의 정보가 곧바로 input image에 대해 해석될 수 있도록 S x S (=7 x 7) size로 맞춥니다. 이렇게 하면 output을 각 grid cell에 대한 output으로 나눌 수 있게되는 셈이니 위치 정보를 효과적으로 보존하게 됩니다.
※예를 들어, output tensor의 (2, 5, 17)에 해당하는 정보는 input image의 (2, 5)에 해당하는 cell이 예측한 7번째 class probability (= 객체가 7번째 class에 해당할 확률)를 나타냅니다.
2. Unified Detection 파트에서 각 grid cell은 B (=2)개의 bbox와 C (=20)개의 class probability를 예측한다고 했습니다. 따라서 output의 depth를 (5 x B + C)인 30으로 맞춰준 것입니다.
참고로, 위 그림처럼 일반적인 conv layer 계산법으로는 parameter를 계산할 수가 없습니다. 예를 들어서 YOLO Network의 가장 첫 layer를 보면 7 x 7 conv layer (stride = 2)인데, input size가 448 x 448인 것을 생각하면 (448 - 7 + 2P) / 2 + 1로 계산될텐데, P는 자연수기 때문에 결과가 소수로 나옵니다.
이는 zero padding를 양쪽에서 주는 대신 한 쪽만 (asymmetrically) 주는 방식으로 해결합니다.
(448 - 7 + P) / 2 + 1

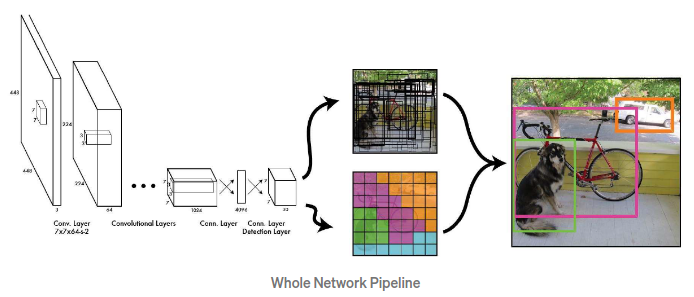 전체적인 파이프라인은 위와 같습니다.
전체적인 파이프라인은 위와 같습니다.
2.2 Training
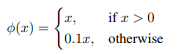 Layer들에 ReLU대신 Leaky ReLU를 사용했습니다.
Layer들에 ReLU대신 Leaky ReLU를 사용했습니다.
가장 중요한 Loss function에 관한 이야기입니다.
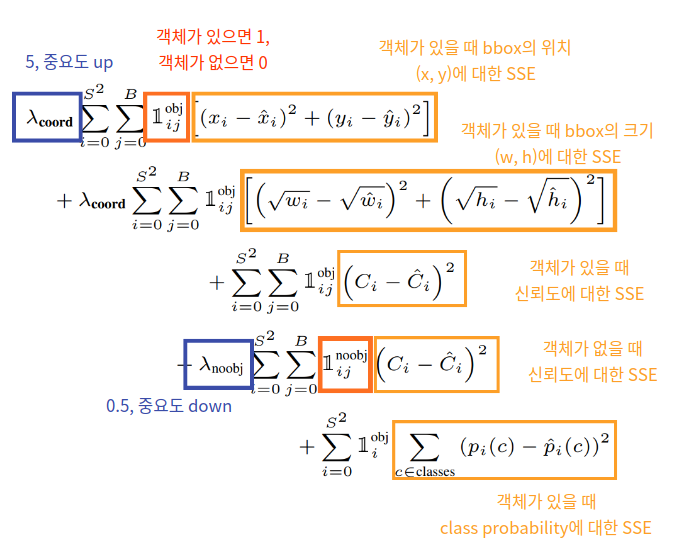
단순화하면, bbox의 위치와 관련된 파트는 5를 곱하고, 객체가 없는 상황에 대한 파트는 0.5를 곱해서 더해줌으로써 중요도를 loss에 반영하는 것입니다. 또한 총 5종류의 SSE를 고려하고 있으니 위 사진을 참고하시길 바랍니다.
ETC.
모델의 작동 원리에 해당이 되지 않는 PASCAL 데이터에 대한 스코어나 타 모델과의 비교 부분은 생략했습니다.
NMS(Non-Maximum Suppression)에 대한 자세한 설명을 생략했는데, 크게 어려운 개념은 아니어서 제가 과거에 설명해두었던 링크를 첨부했습니다.
혹은 지난 포스트인 Canny Edge detection에도 같은 개념이 설명되어있으니 참고하시길 바랍니다.

Summary
YOLO는 1-stage detector로, 448 x 448 x 3 size의 이미지를 input으로 받아 7 x 7 x 30 size의 tensor를 output으로 내놓는 CNN을 중심으로 하는 모델입니다.
만약 class가 20개가 아닌 C개를, 각 grid cell이 bbox를 2개가 아닌 B개를 예측하도록 하고싶다면, 위에서 network를 이해한 것을 바탕으로 fine tuning하거나 새롭게 짜면 됩니다 (output tensor가 7 x 7 x (2 x B + C)가 되도록).
빠르고, contextual information을 잡아낼 수 있는 대신 localization이 조금 떨어진다는 단점이 있습니다.
배경에 대해 Type 1 error를 범할 가능성이 낮으며 mAP이 높지만, 반대로 Type 2 error 가능성은 조금 높습니다.
이는 모두 YOLO v1. 기준이며, 추후 YOLO v5.까지 publicize되면서 각 version마다 개선사항이 있습니다.
군 복무를 하면서 수학 공부나 프로그래밍 공부만 하다보면 집중력이 떨어져서.. 학습 시간의 일부를 할애하여 포스트를 작성하는 방식으로 바꿔봤는데, 확실히 진행 속도는 느려졌지만 글을 쓸 때마다 높은 집중력으로 즐겁게 작업할 수 있었네요 :)
최근에는 YOLO를 넘어서는 SOTA도 많이 나왔지만, obect detection에선 꼭 알아야 할 모델이기에 많은 학생들이 원리까지 이해할 수 있도록 글을 작성해봤습니다.
다음에 또 다른 주제의 포스트로 찾아뵙겠습니다. 감사합니다!
Reference
https://arxiv.org/pdf/1506.02640.pdf
https://nuggy875.tistory.com/21
https://towardsdatascience.com/yolov1-you-only-look-once-object-detection-e1f3ffec8a89

5개의 댓글

output을 각 grid cell에 대한 output으로 나눌 수 있게되는 셈이니 위치 정보를 효과적으로 보존하게 됩니다.
이 부분이 잘 이해가 되지 않습니다ㅠ

https://bothbest.amebaownd.com/
https://bambooflooring.alboompro.com/blog
https://bambooflooring.shopinfo.jp
https://bamboochopsticks.storeinfo.jp
https://chinabamboo.therestaurant.jp/
https://bamboodecking.themedia.jp/
https://bambooplywood.localinfo.jp/
https://bambooplywood.localinfo.jp/posts/57493303
https://bamboodecking.themedia.jp/posts/57493294
https://chinabamboo.therestaurant.jp/posts/57493283
https://bambooflooring.univer.se/
https://bambooflooring.univer.se/blog-post
https://bambooflooring.theblog.me/
https://bambooflooring.theblog.me/posts/57484393
https://japanbamboo.storeinfo.jp/
https://japanbamboo.storeinfo.jp/posts/57484082
https://bambooflooring.omeka.net/
https://bambooflooring.omeka.net/items/show/1
SUMMARY 에서 bounding box 가 '2개가 아닌 B' 이후에 (2XB) 가 아니라 (5XB) 인것 같네용 bbox당 5개 피쳐맵을 갖는다는 내용과 식(5XB+C)은 위에 있는걸 보아, 오타겠네요!
좋은 글 감사합니다!!!