
여러분은 'deepfake(딥페이크)'라는 말을 듣는 것만으로도 거북하실 겁니다. 하지만 정작 어떤 기술인지는 모르고 있진 않으신가요?
안녕하세요, jjun입니다. 지난 포스트인 stable diffusion을 비교적 대중적으로 작성했었는데, 반응이 너무 좋아서 개인적으로 정말 흐뭇했었던 기억이 있습니다. 감사합니다 :)
그래서 오늘은 stable diffusion보다도 대중적이면서, 기술적으로 가치가 매우 높은 deepfake 기술의 원리를 설명드릴까 합니다. 여러분은 딥페이크 기술이 수많은 사람들을 괴롭히고, 한시라도 빨리 사라져야할 기술이라고 생각하시나요?
아니면 단순히 얼굴을 바꿔주는 엔터테이닝 프로그램 정도로 생각하고 계신가요? 이번 포스트로 여러분의 생각을 바꿔드리겠습니다.
이번 포스트는 (죄송하게도) 여러분의 이해를 돕기 위해서, 저와 차은우님의 딥페이크를 통해서 설명하게 됩니다.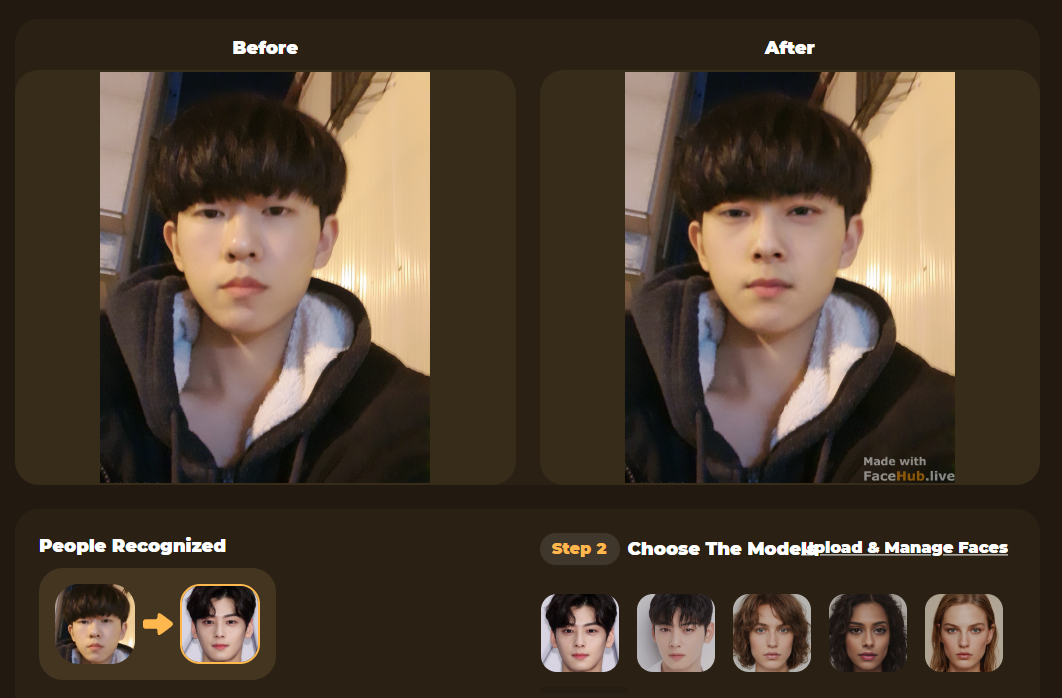
※ 이번 포스트는 기술 소개 시리즈로서 여러분의 배경 지식에 관계 없이 최대한 deepfake에 대해 이해시켜드리는 것을 목적으로 하기 때문에, '최대한' 불필요한 영어 표현은 삭제했습니다.
추가적으로, 입문 독자와 숙련 독자를 구분하기 위해서, 각 목차별로 간단화된 설명을 우선 진행한 뒤 세부 사항으로 넘어갑니다. 입문 독자분들께서는, 순서대로 이해가 가는 데까지 쭉 읽어주시면 됩니다!
반면 deepfake의 대략적인 배경을 이미 이해하고 기술적 분석이 목표이신 숙련 독자분들께서는 바로 Deepfake - the Old Generation 파트로 넘어가주셔도 무방합니다.
대신 딱 두 가지만 부탁드리겠습니다.
- 각 목차마다 난이도의 내림차순으로 쓰여있기 때문에, 이해가 잘 안되시더라도 파트 끝부분까지 는 꼭 읽어보시길 바랍니다.
- 영어 표현을 최소화한 만큼, 포스트 내 기본적인 축약어(후에 나올 deepfake->DF, DeepFaceLab->DFL)나 용어(후에 나올 segmentation) 정도는 꼭 힘을 써서라도 외워주세요.
이 두 가지를 다 지키신다면, 여러분은 한국 최초로 deepfake의 발달 과정 및 기술적 분석을 함께 담은 포스트를 온전히 흡수하시게 됩니다.
Introduction
Snapchat, a rising star
지난 몇 년간, SNS가 유행하면서 인스타그램, snapchat같은 카메라 필터도 함께 유행하기 시작했습니다. 특히, snapchat은 외국에서 정말 많이 사용하는 앱으로 더욱 재밌는 필터 제작을 위해 생각보다 훨씬 엄청난 영상 합성 기술이 발달하기 시작했습니다. 얼굴 사진으로 재밌는 것을 만들기 위해서는 우선 얼굴을 컴퓨터가 인식할 수 있어야 했습니다. 따라서 object detection이나 얼굴의 landmarks를 추출하는 기법 (눈, 코, 입 등의 포인트를 landmark로 간주)을 통해서 기본적인 환경이 갖추어졌습니다.
얼굴 사진으로 재밌는 것을 만들기 위해서는 우선 얼굴을 컴퓨터가 인식할 수 있어야 했습니다. 따라서 object detection이나 얼굴의 landmarks를 추출하는 기법 (눈, 코, 입 등의 포인트를 landmark로 간주)을 통해서 기본적인 환경이 갖추어졌습니다.
시작은 피부 보정, 간단한 얼굴 늘리기 정도였으나, 얼굴 바꾸기 (face swapping)가 만들어지면서 위 사진처럼 동물의 얼굴과 합성하거나, 장신구를 자동으로 달아주는 등 고도화된 기술이 접목되기 시작했습니다.
이 재밌는 기술은 사람들은 Elon Musk와 같은 유명인에게 사용하여 meme을 만들기 시작했고, 유명인에 대한 영상 처리 기술 사용이 점점 당연시되어 세계 각종 사이트와 미디어에 돌아다니기 시작햇습니다.
Some bad news spread

그런데, 언젠가부터 안좋은 소식이 들려오기 시작했습니다. 이러한 영상 처리 기술들이 포르노 배우들과 유명인의 얼굴을 합성하거나, forging(위조)에 사용되어 범죄에 일조하는 데에 쓰인다는 기사가 나오기 시작했습니다.
AI 개발자들은 이때부터 deep learning + faking이라는 의미에서, 이러한 기술 - 특히 인물의 얼굴을 다른 사람의 얼굴과 합성(초창기엔 swapping)하는 - 을 deepfake라고 부르기 시작했습니다.
점점 경각심은 커져만 갔고, 심지어 deepfake가 포르노 합성에 악용될 수 있다는 이유로 세계 최대 코드 공유 사이트인 github에도 올리지 않는 사람들이 대부분이었습니다. 보통은 상업적인 문제로 저작권을 지키기 위해 올리지 않는 경우인데, 윤리적인 문제로 github에 코드를 공유하지 않는다는 것은 sensational한 일이었습니다.
Three major advantages
그렇다고 장점이 사라진 것이 절대 아닌데도 말입니다. 지금 세상에 무척 많이 녹아있는 기술들이 deepfake가 아닌 다른 이름으로 알려져있으나, 실제로는 deepfake와 같은 뿌리를 가지는 경우가 많습니다.
-
여러분이 자주 사용하시는 face swap (얼굴 바꾸기)는 당연히 deepfake의 일종입니다.
-
유튜브에서 얼굴을 가리기 위해 필터를 쓰시거나 AI 마스크 혹은 탈을 쓰고있는 분들도 deepfake 덕분에 방송을 진행할 수 있습니다.
-
드라마 '검은 태양'에서는, 실시간으로 deepfake를 해서 범인을 속이고 피해자를 구출하는 장면도 나왔습니다. (제가 군 복무중일때 생활관에서 봤었는데, 그 장면을 못찾겠네요 ㅜ 나중에 첨부하겠습니다)
대다수의 무지와 자극적인 기사때문에 어두운 면만 세상에 드러나있는 지금, 밝은 면을 드러내고 세상에 알리는 역할은 이제 여러분의 역할입니다. 다음은 본격적으로 deepfake를 기술적으로 파헤쳐보겠습니다.
Prerequisites
이 글은 일반인도 이해할 수 있게 하는 것이 목표로, 비교적 세세한 설명까지 다루게 됩니다. 따라서 여러분이 AI 측면까지 어느정도 이해하기 위해선, 기본적인 준비물이 아래와 같이 필요합니다.
이 부분은 하나하나 설명하지 않고, 간단히 설명한 뒤 참고 자료를 링크로 달아놓았습니다.
※ 기본 중 기본으로, 행렬 연산에 대한 이해가 있어야합니다. 만약 없으신 분들은, 기술적으로 파고드는 파트들을 이해하려 하기보단 과감히 넘기고, 전반적인 글의 흐름을 통해서 AI에 대한 흥미를 고취시키길 권장합니다.
① Basic knowledge on image processing
기본적으로 영상 처리가 어떻게 이루어지는지를 알아야 합니다.
 여러분 모두 아시듯, 모든 이미지는 사실 숫자로 이루어져있습니다. 영상 처리 (face swapping, blurring(피부 보정), sharpening(고해상도 변환))은 이러한 숫자 이미지, 즉 행렬에 행렬곱을 연속적으로 하여 다른 이미지로 변신시키는 것과 같습니다.
여러분 모두 아시듯, 모든 이미지는 사실 숫자로 이루어져있습니다. 영상 처리 (face swapping, blurring(피부 보정), sharpening(고해상도 변환))은 이러한 숫자 이미지, 즉 행렬에 행렬곱을 연속적으로 하여 다른 이미지로 변신시키는 것과 같습니다.
가장 중요한 것은, 이미지에 어떤 변화를 주던간에 그것은 결국 행렬의 연속적인 연산을 통해서 이루어진 것이라는 점을 알고 계시면 됩니다.
② Fundamental math
꼭 알아야할 수학적 연산이 있는데, 바로 convolution(합성곱)이라는 연산입니다.
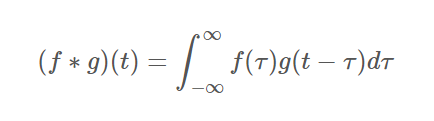
짜잔!
겉보기엔 어려워보이지만, 사실 그렇지도 않을 뿐더러 영상 처리에서 쓰이는 convolution은 훨씬 직관적으로 이해가 가능합니다.
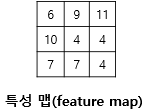
입력이 5x5 행렬이라고 했을때, 3x3 행렬 (kernel, 커널)을 convolution해보겠습니다. 일반적인 행렬곱이라면, 5x5와 3x3은 행렬곱이 불가합니다. 하지만 convolution은 kernel을 input 행렬에 투영한 뒤, 같은 자리에 있는 값끼리 곱한 후 모두 더한 값을 output 행렬의 원소로 넣습니다.
(1x1) + (2x0) + (3x1) + (2x1) + (1x0) + (0x1) + (3x0) + (0x1) + (1x0) = 6
.. 한 칸 옆으로 가서 (stride),
(2x1) + (3x0) + (4x1) + (1x1) + (0x0) + (1x1) + (0x0) + (1x1) + (1x0) = 9.. 이런 식으로 계산이 끝나고 output으로 나온 matrix를, feature map이라고 합니다. 입력 행렬의 원소들을 커널의 각 값들과 결합하여 서로 다른 비율로 반영된 행렬이라는 뜻입니다.
Input matrix의 사이즈는 kernel을 통해서 줄이면서, output matrix이 input matrix의 특성을 반영할 수 있도록 하는 것입니다. 각 원소 값이 어떤 비율로 반영되는지는 kernel의 원소에 따라 달라지고, 때문에 kernel의 원소들을 가중치라고 부릅니다. 특정 자리의 원소가 다른 것들보다 2배 중요하면 다른 원소보다 2배 많이 참고해야하기 때문에, 2를 넣는다라고 생각하시면 됩니다.
Convolution에 대한 더 자세한 설명은 위키독스를 참고하시길 바랍니다.
Convolution이 어떻게 진행되는지를 아신다면, 제 깃허브에 있는 masking으로 개념을 확장해보시길 바랍니다. 특히 masking은 추후 deep learning model 부분에서 다시 나오기 때문에 이해하고 가시는 것이 좋습니다. 축약된 정보들로 분석을 하면 처리해야하는 일의 양이 줄어들기 때문에, deepfake 도중에도 Convolution을 여러번 사용하게 됩니다.
③ CNN & GAN knowledge (advanced)
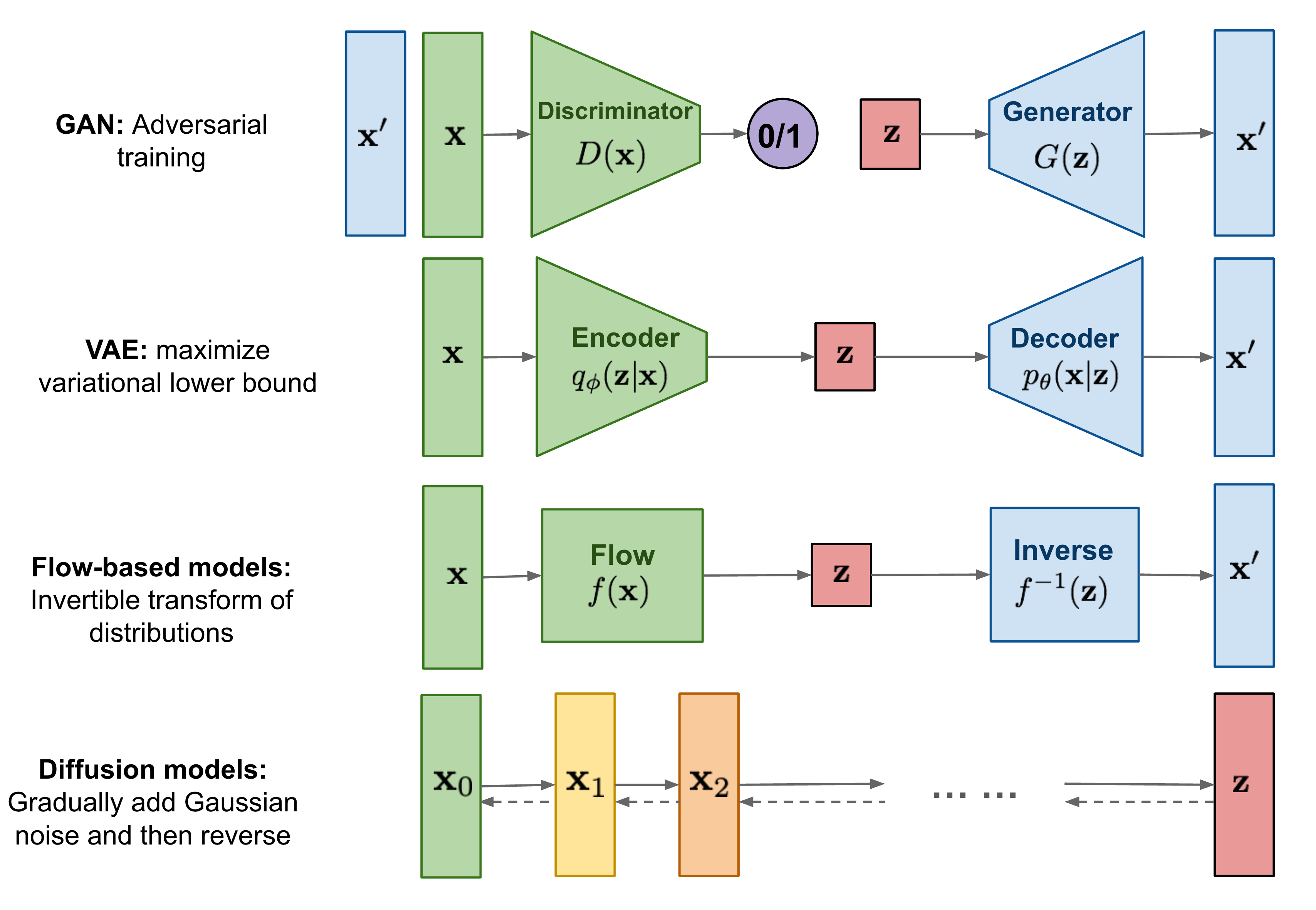
만약 deepfake가 AI 측면으로 어떻게 구성되어있는지 정확히 파악하기 위해서는, deep learning 기법의 근간이 되는 CNN과 GAN에 대해서 알아야 합니다. CNN은 Convolutional Neural Network로, ②에서의 convolution을 여러 겹 쌓은 딥러닝 구조를 뜻합니다. GAN은 Generative Adversarial Network로, generator와 discriminator가 각각 지폐위조범과 경찰처럼 서로 잡고 잡히지 않기 위해 발달하는 원리를 차용한 딥러닝입니다.
이 두 가지에 대한 지식은 추후 나올 모델들의 구조까지 모두 공부하실 advandced readers께서만 갖추시면 됩니다.
제 지난 포스트에서 소개되었던 GAN과, VAE의 원형인 AE(AutoEncoder)가 이번 포스트에서 자세히 다뤄집니다. AE는 내부적으로 CNN, 정확히는 convolution 층으로 이루어져있기 때문에 GAN과 CNN의 개념을 알고 계시면 됩니다.
이에 더해서 object detection이나, image segmentation같은 computer vision의 기본적 활용 정도를 아시면 문제 없이 이해하실 수 있습니다.
Old Generation DF - DeepFaceLab
이 파트부터는 사담은 거의 제외하고, 정확한 정보 전달을 목표로 합니다. 추가로 편의상 deepfake는 DF로, DeepFaceLab은 DFL로 축약하겠습니다.
초반의 딥페이크는, "얼굴을 뜯어내고 그 부분을 다른 얼굴과 바꿔치기하는 방식"이었습니다.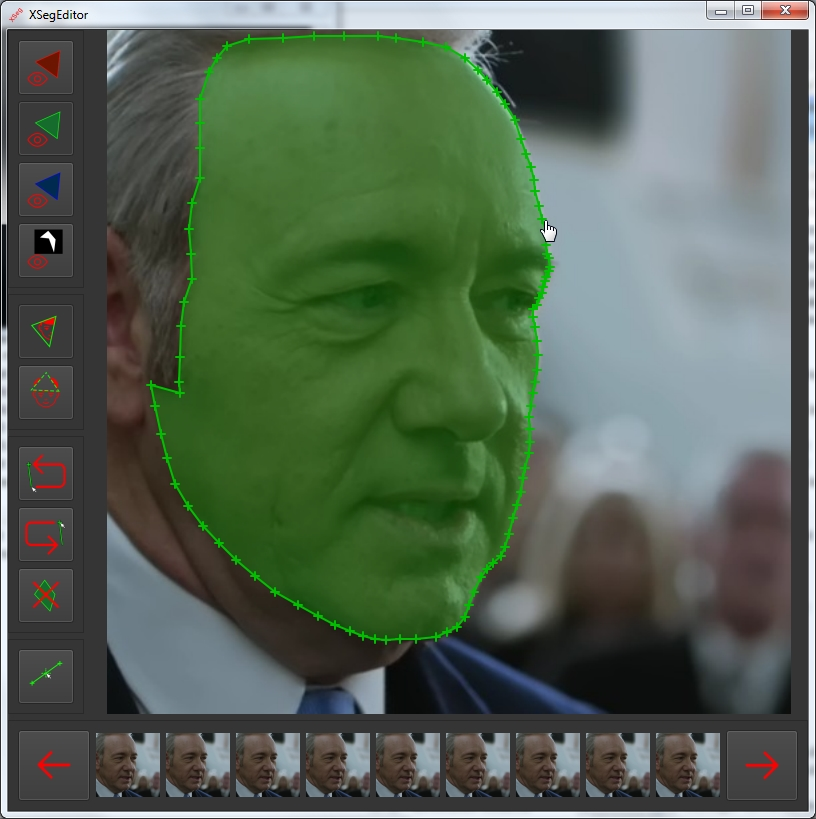
초창기 딥페이크로는 Synthesizing Obama, FSGAN, FaceShifter 등이 있었으나 역시 윤리/상업 문제로 코드를 공개하지 않았습니다.
하지만 DeepFaceLab은, 완벽한 딥페이크를 위한 오픈소스 pipeline(설계도 정도로 보시면 됩니다)을 깃허브에 공유했습니다.
DFL은 완벽한 딥페이크를 위해선 다음과 같은 과정이 필요하다고 설명합니다.
- Face detector module (탐지 모듈)
- Face recognition module (인식 모듈)
- Face alignment module (정렬 모듈)
- Face parsing module (분석 모듈)
- Face blending module (혼합 모듈)
즉, 사진에서 얼굴을 찾은 후(detect), 정확히 어떻게 얼굴이 구성되어있는지 인식하고(recognize), 사진상 정면 사진이 되도록 조정하고(align), 분석하여(parse) 다른 얼굴과 잘 섞는(blend)하는 과정을 세분화한 것입니다.
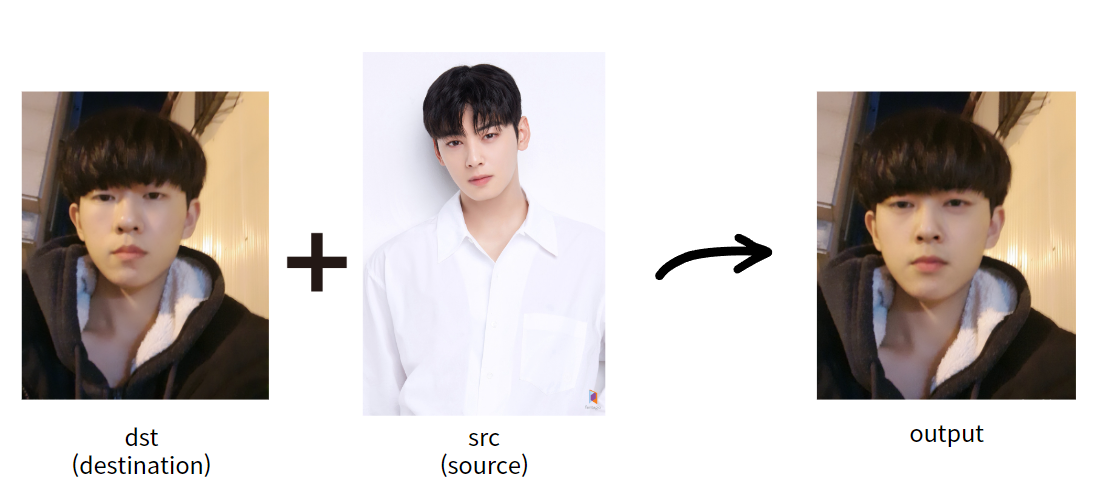
짜잔! 현실감을 위해 제 모습을 차은우(님)과 합성해보았습니다. 역시 구시대의 딥페이크라 결과물이 시원찮네요 ㅎㅎ ㅜㅜ나름 3년 전 사진인데 말이죠
중요한 것은 용어입니다. 얼굴 외의 특성을 가지고 갈 인물 사진을 destination 줄여서 dst라고 부르고, 얼굴 부분만 잘라낼 인물 사진을 source 줄여서 src라고 부릅니다.
섹션 도입부에서 말씀 드렸듯 '얼굴을 잘라내고 바꿔치기' 해야합니다. 즉 dst인 제 사진에서, 얼굴 부분을 인식해서 도려내는 extraction 과정으로 시작하게 됩니다.
① Extraction
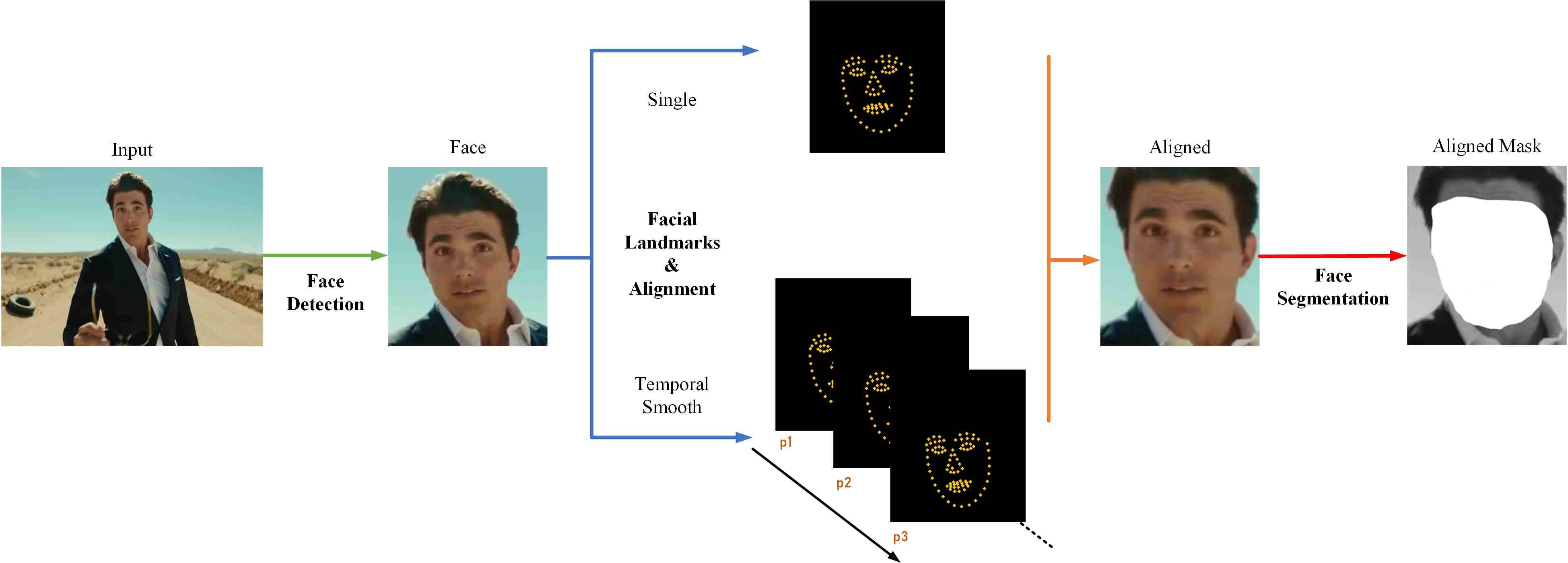
우선, object detection을 위해서 S3FD(Single Shot Scale-invariant Face Detector)를 많이 사용합니다. 이외에도 RetinaFace나 MTCNN을 사용할 수도 있습니다.
이후, face object만 crop된 사진에서 facial landmarks를 찾고, 조정합니다.
Facial landmark란, 아래 사진과 같이 얼굴 내에서도 특징이 되는 부분들을 포인트화 시켜서 나타낸 것입니다.
2DFAN, PRNet 등을 사용하여 검출합니다.
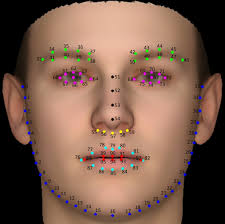
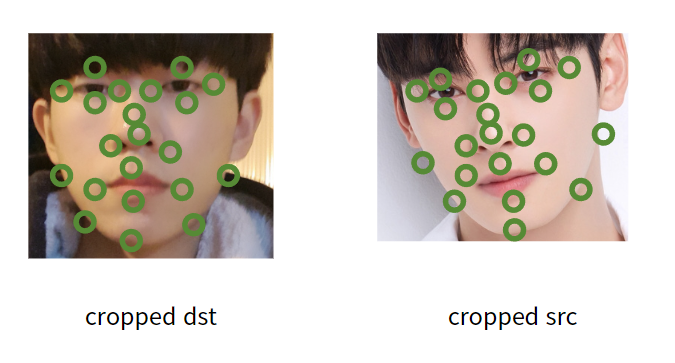 제가 가상으로 이해를 돕기 위해 찍어본 facial landmarks입니다. 같은 개수의 landmarks를 찍었음에도 불구하고, 유사하지만 조금 다른 사진 구도 때문에 각 landmarks set간의 구조 차이가 있습니다.
제가 가상으로 이해를 돕기 위해 찍어본 facial landmarks입니다. 같은 개수의 landmarks를 찍었음에도 불구하고, 유사하지만 조금 다른 사진 구도 때문에 각 landmarks set간의 구조 차이가 있습니다.
이를 조정하는 alignment의 일환으로 Umeyama algorithm이라는 것을 사용합니다. 선형대수학에서의 Isomorphism 중 하나인 affine transformation과 비슷한 느낌이기 때문에, 어느 정도 선형대수 지식이 있으신 분이라면 Umeyama까지 이해하고 넘어가보시길 권장합니다.
Landmarks들의 각도 조정까지 끝났다면, 끝으로 landmarks를 통해서 인식한 얼굴 면을 뜯어내야하기 때문에 face segmentation을 진행합니다. TernausNet이나, XSeg를 사용합니다.
Face segmentation은 semantic segmentation을 얼굴 이미지에 대해서 진행하는 것입니다. Semantic segmentation은, 입력으로 들어온 이미지에 대하여 서로 특성이 다른 부분을 분할하는 기술입니다.
Face segmentation의 경우, 얼굴만 들어있는 사진 자체가 입력이기 때문에 그 내부에 있는 눈, 코, 입, 피부 등으로 분할하게 됩니다.


결국, 제 사진에서 extraction 파트가 완전히 끝났을 때의 결과물은 아래 사진의 초록색 부분과 같을 것입니다. Landmarks를 기준으로 잡은 얼굴 모양을 segmentation을 통해 통째로 색칠하듯 가져오게 되었습니다.

② Training
데이터가 준비되었으면, 학습을 하는 것이 deep learning의 진리입니다. 이제 deepfake를 위해서, 위에서 설명한 DFL pipeline의 5가지 모듈 중 4번째에 해당하는 'face parsing module'에 해당하는 파트인 deep learning model을 소개합니다.
Faceswap-GAN
※ 초보자 분들께서는 도입부가 어려워도 끝까지 읽어주시면, 아주 간단화된 좋은 예시를 들어보았으니 조금만 힘내주시길 바랍니다 :)
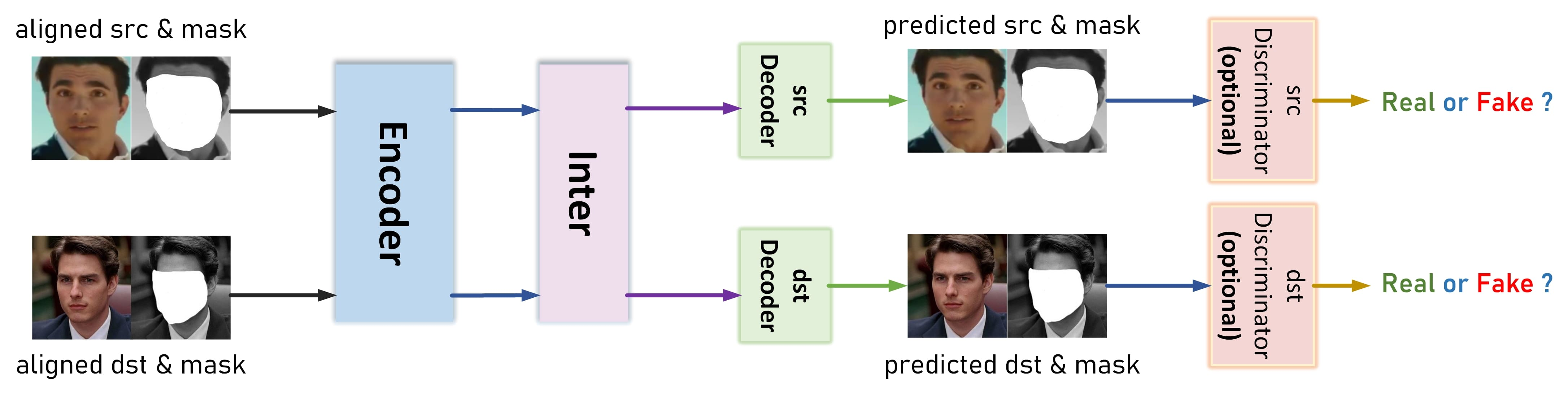
Faceswap-GAN은 말 그대로 face swap을 진행하기 위한 AE(Autodencoder, encoder-decoder쌍)를 GAN 방식으로 학습하는 것입니다. 우선, AE 파트의 구성 비AI적으로 설명하겠습니다.
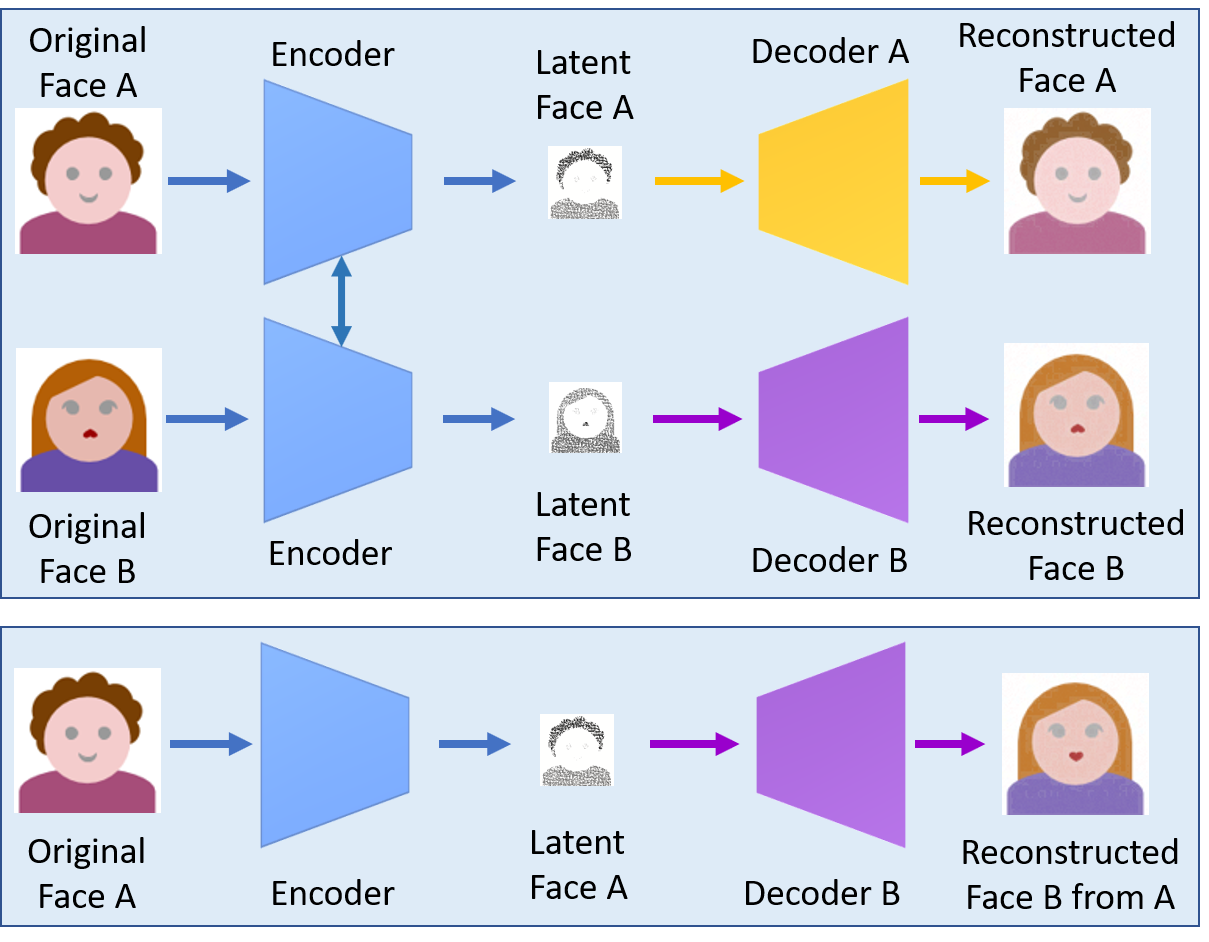 그림의 윗 부분은 AE의 training, 아랫 부분은 deepfake 생성 파트에 해당합니다. Training이 종료되면, deepfake 생성 파트처럼 동작한다는 뜻입니다.
그림의 윗 부분은 AE의 training, 아랫 부분은 deepfake 생성 파트에 해당합니다. Training이 종료되면, deepfake 생성 파트처럼 동작한다는 뜻입니다.
Encoder와 decoder는 각각 암호화/복호화를 해주는 부분으로, 쉽게 생각해서 압축/압축 해제로 보시면 됩니다.
첫 번째 사진에서 A라는 사람의 이미지(행렬)를, encoder를 통해 feature vector z(벡터)로 압축합니다. 이후 decoder로 복구(압축 해제)를 시켰을 경우, 결과 사진이 똑같이 나오도록 학습합니다.
Deepfake 중에는 feature vector z를 latent face(vector)라는 이름으로도 부를 수 있습니다. Latent vector란, 지난 포스트에서 설명했던 latent space에 있는 vector입니다.
더 쉽게는, 우리가 키가 150cm가 넘나 안넘나와 몸무게가 50kg 이상이다 아니다를 각각 0과 1로 표현한다면, latent space는 x축이 (키 150cm 이상), y축이 (몸무게 50kg 이상)인 공간이며 안준영이라는 사람이 (0, 1)라는 위치에 있을때, (0, 1)은 안준영이 150cm는 넘으며 50kg 미만임을 나타내는 latent vector (특성을 나타내는 벡터)가 되는 것입니다.
두 번째 사진도 마찬가지로, B라는 사람의 사진을 학습 데이터로 사용하여 압축-압축 해제를 거쳤을 때 똑같은 사진을 나오는 것을 목표로 학습합니다.
이후 B라는 사람의 얼굴에 A의 얼굴을 넣고싶다면, Y의 사진을 똑같이 encode한 뒤 decode는 A의 사진을 위해서 학습된 것을 사용하는 것입니다.
조금 더 쉽게 설명해보자면, Youtube 채널 中 Computerphile의 영상에서 이를 잘 시각화하고 있습니다.

A의 사진으로 학습된 encoder-decoder 쌍을 각각 A-en, A-de라고 하고 B의 사진으로 학습된 쌍은 각각 B-en, B-de라고 하겠습니다.
B의 사진을 B-en으로 압축하고, 복구는 A-de로 시킴으로써 B의 전반적인 형태에 A의 얼굴을 담는 것, 이것이 바로 deepfake입니다.
더더욱 간단한 예시를 들어보겠습니다.
X 친구에게는 레고 배틀쉽 에디션을 준 뒤, 해체한 후 다시 그대로 조립하는 연습을 계속 시킵니다.
Y 친구에게는 레고 눈사람 에디션을 준 뒤, 해체한 후 다시 그대로 조립하는 연습을 계속 시킵니다.
수많은 연습이 이뤄지고 나면, X는 어느 순간부터 최적의 방법을 깨닫고 똑같은 방법으로 해체하고 조립하기를 반복할 것입니다. Y도 마찬가지입니다.
하지만 갑자기 X에게 레고 배틀쉽 에디션을 해체시킨 뒤, Y에게 조립을 맡긴다면 어떤 작품이 나올까요? 부품은 배틀쉽 에디션것이기 때문에 전반적으로 배틀쉽의 특징(포탄, 갑판)들때문에 전체적으론 배틀쉽같이 보일 수 있으나, 가장 중요한 '결국 어떻게 생겼나?'는 눈사람에 가까울 것입니다.
Deepfake도 비슷한 원리이지만, 직관적으로 설명한 예시이기 때문에 완벽한 설명이 절대 아닙니다. 어떤 느낌인지만 파악하시길 바랍니다.
Encoder architecture
Layer가 어떤 식으로 쌓여있는지는 아래 사진에서 완벽히 설명되었기 때문에, 몇 가지 설명만 첨부합니다.
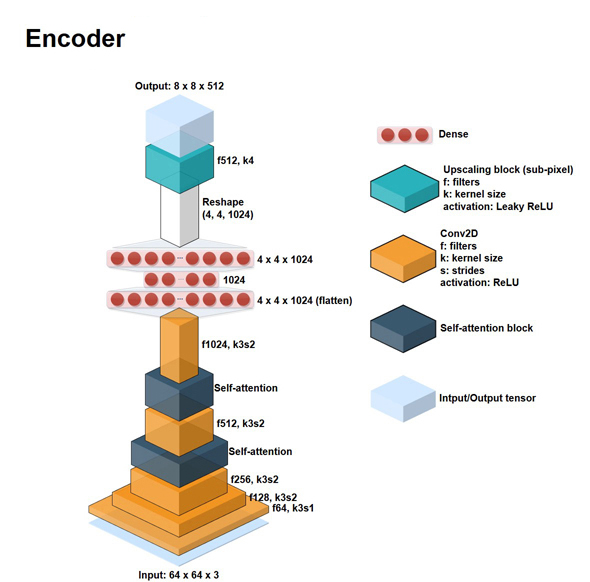
Input은 64 x 64 x 3의 사진, 즉 64 x 64짜리 color image입니다. 64 x 64사이즈인 이유는, 이미 DFL pipline 중 extraction 부분을 거치고 얼굴만 잘린 사진이기 때문입니다.
Kernel(초반부 Prerequisites 파트 中 convolution의 설명 부분)의 크기는 3, stride(한 번 연산을 마치고 몇 칸 띄어서 옆으로 갈지)는 2로 조절함으로써, input이 Conv2D layer를 통과할수록 2D shape가 작아지게 됩니다. 하지만 filter 수는 64, 128 .. 1024까지 늘리면서, 채널은 더욱 깊어지게 됩니다.
중간중간에 self-attention layer를 사용함으로써 연산량과 속도를 최적화합니다. 아주 잘 설명된 블로그가 있어 링크를 첨부하겠습니다.
CNN의 output size 계산 공식을 이용하면 마지막 Conv2D 이후 tensor는 4 x 4 x 1024 사이즈의 3차원인데, 이를 dense layer를 통해 1차원 vector로 flatten(평탄화)시킵니다. 이를 1024개의 cell이 있는 dense layer과 연결한 후, 4 x 4 x 1024개의 cell이 있는 dense layer을 이어붙인 뒤 다시 4 x 4 x 1024의 tensor로 reshape합니다. 최종적으로, upscaling block을 통해서 기존 input에 비해 과하게 축소된 사이즈인 4 x 4에서 8 x 8로 확대해줍니다. 이 때, 채널 수는 절반으로 줄어든 512입니다.
따라서, 8 x 8 x 512의 output tensor는 latent face가 되겠습니다.
Decoder architecture
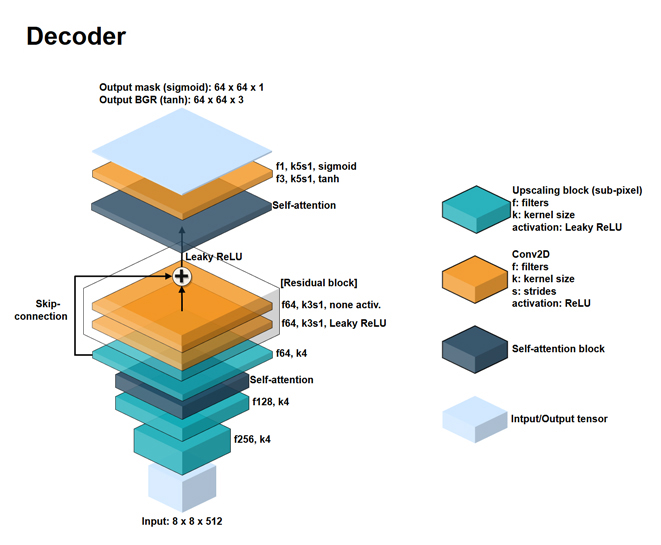
Encoder의 결과로 나온 latent face는 decoder를 통해서 복구되어야 합니다. 전반적으로 encoder와 반대로 확대하는 방향으로 연산하는 것을 볼 수 있습니다.
Upscaling block을 여러 개 붙이며 사이에 self-attention layer를 끼워넣습니다. 연속된 upsampling 과정에서 gradient exploding이나 vanishing이 일어나지 않도록, residual block을 이용한 skip-connection 즉 residual connection을 사용했습니다.
Gradient는 deep learning model의 학습에서 굉장히 중요한 역할을 합니다. 이러한 gradient는 layer가 많이 쌓일 수록 문제가 일어나기 쉽기 때문에, 또 다른 학습 경로를 부여한다고 보시면 됩니다. A 도로가 고장나면, B 도로로도 갈 수 있도록 하는 느낌입니다!
※ 다른 첨부 링크는 넘어가더라도, deep learning이 학습 중 사용하는 방법인 gradient descent(경사하강법)은 꼭! 꼭! 알고 넘어가셔야 합니다!
Leaky ReLU를 쓰는 것부터 구조 자체가 gradient 문제에 굉장히 많은 신경을 쓰고 있음을 알 수 있습니다. 이후 self-attention layer를 거치고, 아주 중요한 파트가 나옵니다.
보시면 output이 한 개가 아닌 두 개입니다. 하나는 64 x 64 x 1짜리 mask라고 써있고, 하나는 64 x 64 x 3짜리 output BGR라고 써있습니다. 각각의 activation function은 sigmoid와 tanh입니다.
이름과 activation을 보면 쉽게 알 수 있습니다. Output mask는, 각 pixel 별로 얼굴에 속하는 부분인지 아닌지를 0과 1로 표현한 행렬입니다. 값을 0과 1로만 이루어지게 하게 하기 위해서, 직전 tensor에 depth = 1, activation = sigmoid인 conv2D layer를 취한 것입니다.
Output BGR은 64 x 64 x '3'인 것에서 알 수 있듯이, decode된 사진 그 자체입니다. 색상 시스템 중 BGR을 따른 다는 의미에서 쓰인 이름입니다.
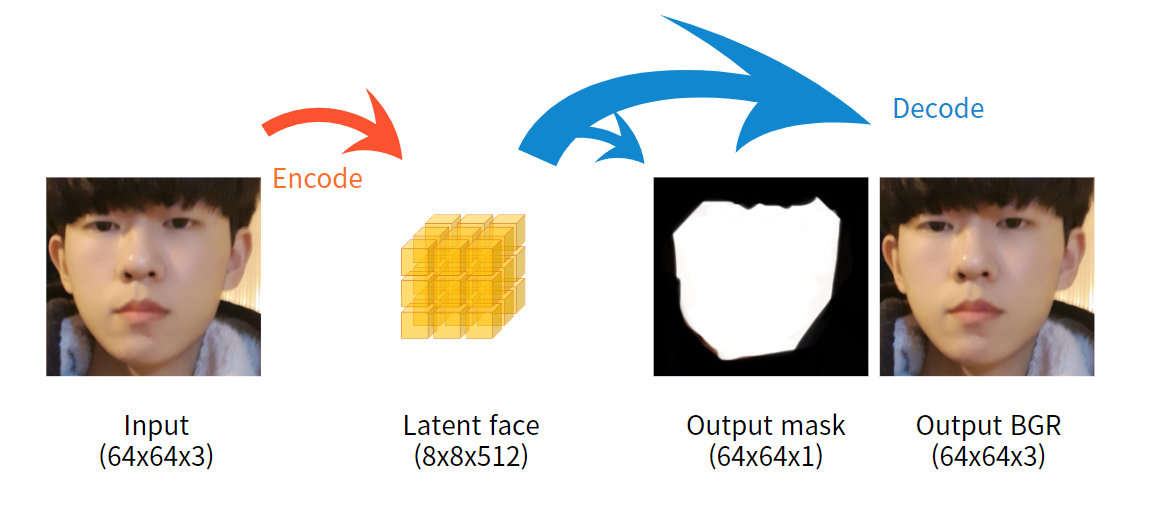
이과인 제 손에서 태어난 걸작입니다
결론적으로 위와 같은 과정을 겪는다고 보시면 됩니다 :)
Discriminator architecture
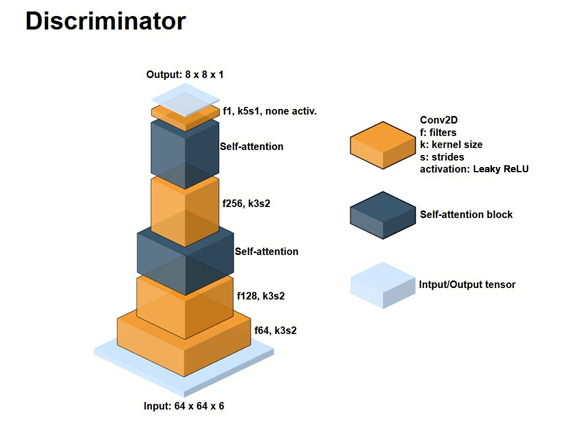
구세대의 deepfake는 GAN에서의 discriminator 부분을 차용했다고 말씀드렸습니다. Generator와 discriminator가 서로 경쟁하며 발전하는 것처럼, deepfake에서의 AE(AutoEncoder)와 discriminator가 서로 경쟁하는 것입니다. 그런데, 왜 갑자기 input이 64 x 64 x 6일까요? 분명히 decoder의 output size는 64 x 64 x 3과 64 x 64 x 1이었습니다.
 이는 Output BGR 혹은 Output mask가 단독적으로 다시 쓰이는 것이 아니라, 둘이 masking 연산을 통해서 masked face를 만들기 때문입니다. 각 화소 단위로 원소끼리 곱하는데, output BGR을 각각 output B, output G 그리고 output R로 분리한 뒤 (각각 사이즈는 64 x 64 x 1로 output mask과 동일) masking하게 됩니다.
이는 Output BGR 혹은 Output mask가 단독적으로 다시 쓰이는 것이 아니라, 둘이 masking 연산을 통해서 masked face를 만들기 때문입니다. 각 화소 단위로 원소끼리 곱하는데, output BGR을 각각 output B, output G 그리고 output R로 분리한 뒤 (각각 사이즈는 64 x 64 x 1로 output mask과 동일) masking하게 됩니다.
주의하실 점은, 여러분의 이해를 돕기 위해 output mask와 masked face의 얼굴 부분을 흰색으로 칠하고 output mask의 배경을 검은색으로 칠했으나, 실제로는 반대라는 점입니다.
컴퓨터에선 흰색이 1을 뜻하고 검은색이 0을 뜻하기 때문에, mask를 image에 씌우면 얼굴 부분의 pixel들은 모두 0과 곱해서 사라지고, 나머지 배경은 1과 곱해서 살아나기 때문입니다. 한 마디로 실제로는 output mask는 얼굴 부분이 검은색(0)/배경이 흰색(1)이며, 결과인 masked face의 얼굴부분 또한 검은색으로 화소값은 B, G, R에서 모두 0입니다.
 Discriminator 즉 판별자는 무엇을 판별해야할까요? Decode된 얼굴과 (=deepfake된 얼굴) 원본 얼굴의 배경 쌍을 보면서 이 얼굴이 진짜인지를 판단한다는 겁니다.
Discriminator 즉 판별자는 무엇을 판별해야할까요? Decode된 얼굴과 (=deepfake된 얼굴) 원본 얼굴의 배경 쌍을 보면서 이 얼굴이 진짜인지를 판단한다는 겁니다.
아주 중요한 점은, 위 사진은 training 상황을 가정했을 때 - 거의 학습이 완료된 AE가 input을 성공적으로 encode-decode한 사진이므로, output임에도 input과 거의 똑같은 사진을 만드는데 성공했고 discriminator에 들어가서 true image로 판별될 예정이라는 점입니다.
그렇다면 AE의 training이 끝난 뒤, discriminator와 경쟁하기 위해서 본격적으로 새로운 이미지를 생성(=deepfake)하는 중이라면 이 때 discriminator의 input은 어떻게 될까요?
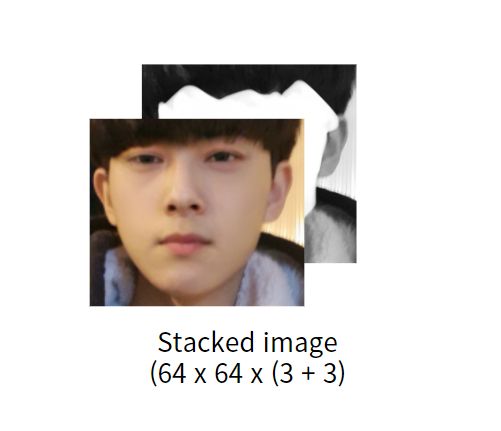
AE를 통해 실패작에 가까운 output이 나왔을 것이고, 이것이 masked face와 쌍으로 discriminator의 input으로 들어가게 될 것입니다. 당연히 이 정도라면 성능 좋은 DF라면 false image로 판별할 것이고, "아하 이렇게 만들면 걸리는구나" 싶어서 AE는 더 열심히 새로운 DF를 만들게 되는 것입니다.
※ Training은 그림의 윗부분처럼 하지만, generating때(=deepfaking)는 아랫부분처럼 동작한다는 점을 다시 한번 상기시켜드립니다.
DeepFaceLab
또 다른 가능한 모델로는, deepfacelab이 있습니다.
.. 네. 똑같습니다. Encoder를 똑같은 것을 쓰고, decoder를 분리하는 것도 똑같습니다. GAN 구조도 똑같고, deepfake를 만들 때 decoder를 섞어서 쓰는 것도 똑같습니다.
유일하게 다른 점은 Encoder의 input 당시부터 데이터를 image-mask쌍으로 넣는다는 점인데, mask는 encode-decode 이후에도 거의 변화가 있기 어렵기 때문에 큰 의미는 없다고 보여집니다.
결론적으로, 구세대의 deepfake들은 전부 faceswap-GAN이나 DeepFaceLab - DFL pipeline과는 별개의 의미로 언급한 모델입니다 - 처럼,
- AE를 두 개 준비한다.
- 하나는 src image를 위해 학습시키고, 다른 하나는 dst image를 위해 학습시킨다.
- 이제 GAN 구조 작동을 위해, 새로운 image를 generate 한다.
= Deepfake를 만든다.
= Dst image를 dst encoder에 넣고, decode는 src decoder를 사용함으로써 두 사람이 혼합된 deepfake image를 만든다.
- 이제 GAN 구조 작동을 위해, 새로운 image를 generate 한다.
- Discriminator에게 넘겨주고, 진짜인지 가짜인지 판별을 부탁한다.
- 초반엔 계속 가짜인 것이 들통나겠지만, AE (generator 파트)는 점점 교묘하게 만드는 법을 깨우친다.
- 언젠가부터 discriminator는 대부분 속기 시작하고, 어느 정도 됐다 싶으면 끝낸다.
- 언젠가부터 discriminator는 대부분 속기 시작하고, 어느 정도 됐다 싶으면 끝낸다.
Drawbacks
이 방법이 버려진 데에는 굵직한 이유가 몇 가지 있습니다.
첫 번째로, autoencoder를 각각 src와 dst에 대하여 학습시킨다는 것은 너무 비효율적입니다.
예를 들어, 제 얼굴과 차은우님의 얼굴을 위해서 만든 deepfake model은, 다른 그 누구와도 deepfake를 할 수 없습니다. 대개 deep learning은 한 번 학습하는데에 굉장한 시간이 들고, 심지어 image는 데이터 중에서도 용량이 큰 편이라 굉장히 구시대적인 방식입니다.
두 번째로, 너무 많은 별개의 단계를 거치다 보니, 다른 부분이 훌륭하더라도 한 부분만 잘못된다면 완전히 잘못된 결과를 얻게 됩니다. 특히, 꽤나 중요한 face extraction조차 다른 파트와 완전히 독립적입니다. Extraction에서 사용하는 모델로 TernausNet과 XSeg라는 tool을 소개했었는데, 이는 deep learning model과는 완전히 무관한 파트로 한 번에 조율하기가 굉장히 어렵습니다.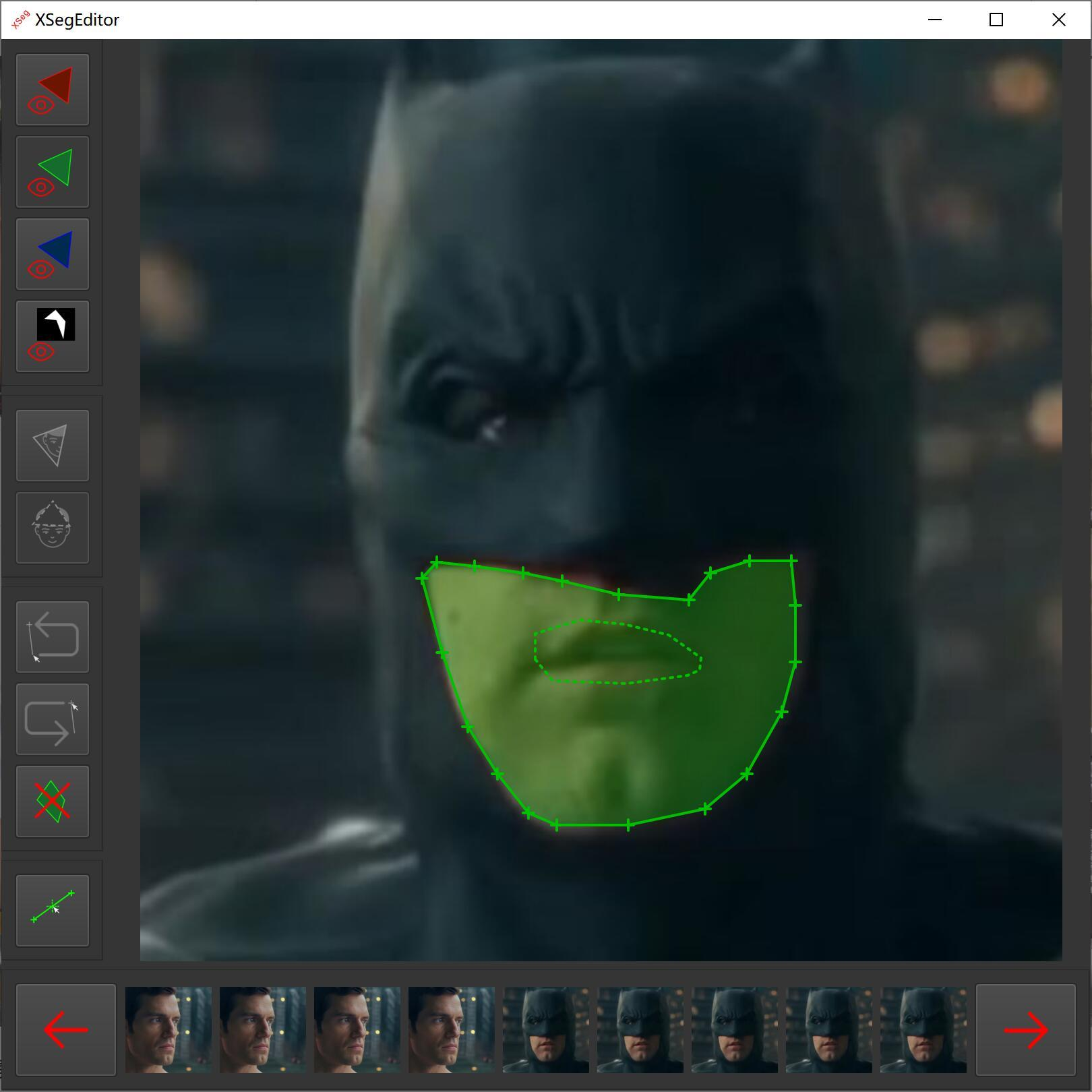
마지막으로, 얼굴을 통째로 뜯어내고 붙인 뒤 이를 자연스럽게 만드는 blending 과정 자체가 결함이 많습니다. 예를 들어서, 흑인과 백인을 deepfake한다고 생각해보겠습니다. 분명히 한 쪽의 얼굴을 뜯어내고 다른 쪽의 얼굴을 붙인다면, 아무리 교묘하게 오려낸 사진이어도 분명 피부색의 차이가 티가 날 것입니다.
좀 더 수학적으로는, 화소값 간의 discontinuity(불연속)이 생겨 자연스럽지 못하다는 점입니다. 이 때 사용하는 blending 기법으로 color transfer가 있는데, 공식은 아래와 같습니다.
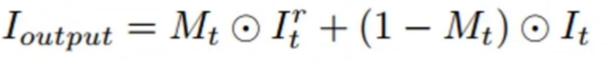 Deepfake는 사람도 속일 정도로 교묘해야하는데, 정해진 수학 공식에 따라서 edge 부분의 색끼리만 섞어내는 기법으로는 여전히 티가 많이 났습니다.
Deepfake는 사람도 속일 정도로 교묘해야하는데, 정해진 수학 공식에 따라서 edge 부분의 색끼리만 섞어내는 기법으로는 여전히 티가 많이 났습니다.

이외에도 sharpening을 하는 등 추가 작업을 통해 해결해보려 했지만, 보장된 품질의 deepfake를 매번 만들어내기에는 역부족이었습니다. 세상은 완전히 새로운 기법을 필요로 했습니다.
Deepfake - the New Generation
2019년, FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping
라는 논문에서 등장한 Faceshifter는 기존의 방식을 완전히 깨부수고 새로운 구조를 들고 왔습니다. 심지어 성능도 눈에 띄게 개선되어 매우 자연스러운 DF를 제작했음을 아래 사진을 통해 알 수 있습니다.
Faceshifter
Faceshifter는 두 가지 파트로 나뉘어있습니다.
- AEI-Net(Adaptive Embedding Integration Network) <- 합성 이미지 생성
- HEAR-Net(Heuristic Error Acknowledging Refinement Network) <- 합성 이미지 정제
이렇게 두 단계로 나뉜 모델은 보통 2-stager라고 불립니다. HEAR-Net은 결국 AEI-Net의 작동 이후에 남은 부족한 부분을 조금 채워주는 역할이므로, 상대적으로 더 중요한 AEI-Net의 구조에 집중하여 설명하겠습니다.
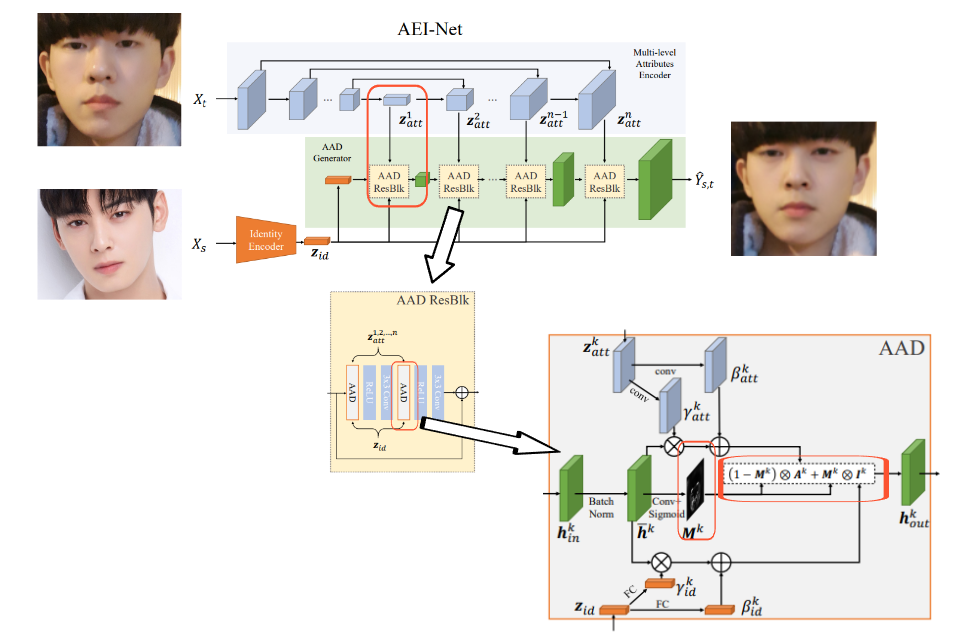
AEI-Net

Deepfake 과정에서의 deep learning 모델을 faceswap-GAN에서 AEI-Net으로 바꾸기만 해도, 위 사진에서와 같은 성능 개선이 일어났습니다.
AEI-Net은 얼굴 부분을 뜯어내고 재조합하는 것을 넘어서, target(dst와 같은 의미)에서는 attributes(자세, 조명, 배경 등)을 가져오면서 src에서는 identity(얼굴)을 가져와 합치는 high-fidelity face swap을 제안합니다.
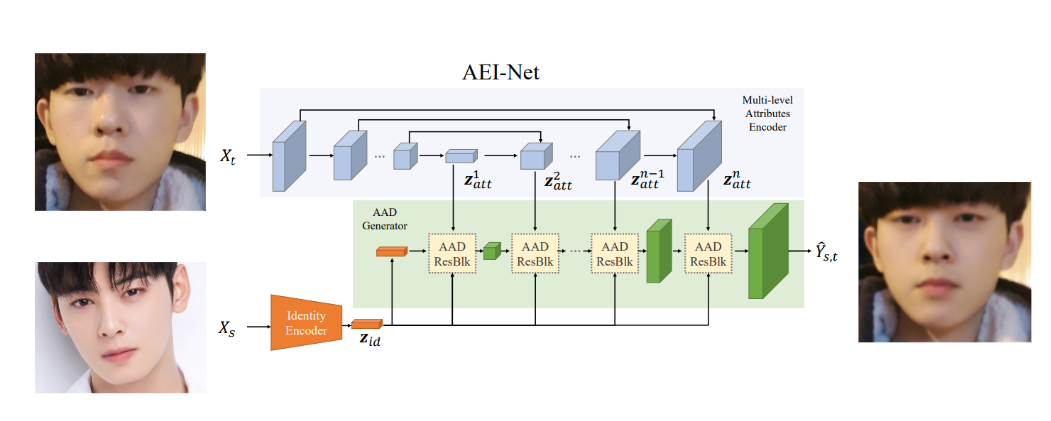
입력은 X-t와 X-s로, 각각 target image와 source image입니다. 두 입력이 각각 어떻게 처리되는지 확인해보겠습니다.
X-t

X-t(target image)가 multi-level attributes encoder를 통해서 압축되었다가 다시 팽창합니다. Deep learning을 잘 아시는 분이라면 눈치 채셨겠지만, 전형적인 U-Net에서의 구조입니다.
다음은 논문의 일부입니다.
Z-att-k는, U-Net decoder에서 k번째 feature map입니다. U-Net은 decode를 할 때 단순히 upsampling만 하는 것이 아니라, encoder에서 대칭 부분에 있는 tensor를 참고하는 lateral concatenation을 사용합니다. 이로써 압축과 팽창 과정에서 일어나는 정보 손실을 막을 수 있는데, 그림에서 볼 수 있듯 이렇게 만들어진 Z-att-1 ~ Z-att-n을 각각 다시 어딘가에 concatenate시키게 됩니다.
X-s
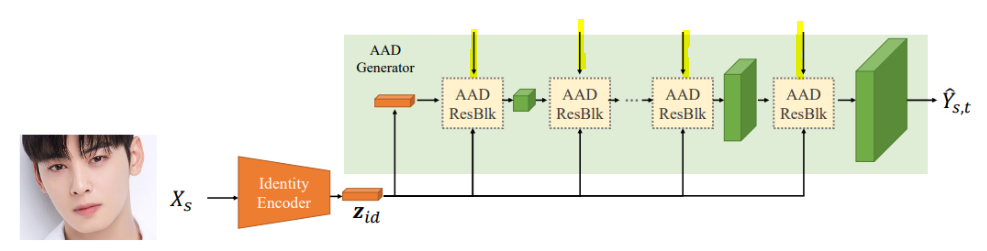
우선, X-s가 encoder를 통해서 z-id(X-s의 identity를 담은 latent vector z)라는 vector로 압축됩니다. 이후, 연속된 AAD Resblock이라는 것에 여러 번 통과되어 최종적으로 output인 deepfake를 만들게 됩니다.
※ 형광색으로 칠한 부분을 잘 보시면, 각 AAD Resblock이 X-t 처리 과정에서 생긴 각각의 Z-att들과 연결되고 있습니다. 조금 뒤에 설명드릴테니, 잘 기억해주시길 바랍니다.
AAD Resblock의 내부 구조를 살펴보겠습니다.!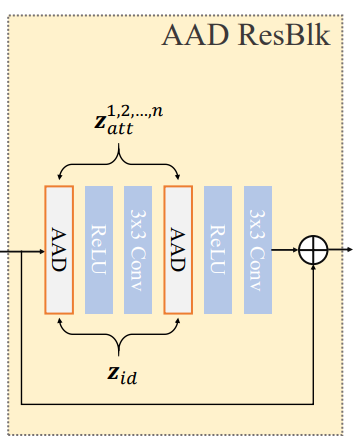
AAD layer를 거친 뒤 activation을 ReLU로 하고, 3x3 conv layer를 거치는 과정을 2번 반복하고, 이 결과를 AAD Resblock을 거치기 이전의 입력과 concatenate합니다.
이번엔 AAD layer가 어떻게 생겼는지 확인해보겠습니다.
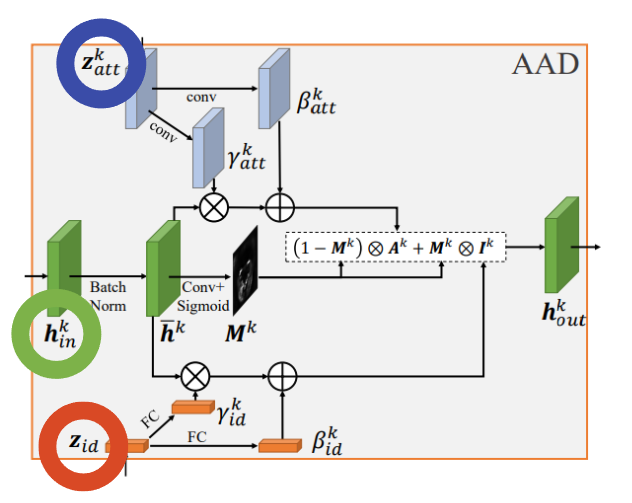
위에서 각 AAD Resblock이 X-t 처리 과정에서 생긴 각각의 Z-att들과 연결된다는 점을 주목해주시길 부탁드렸습니다.
-
AAD에서 위쪽 Z-att-k(파란색)가 연결되는 방식은, 우선 각각 conv layer를 거쳐 gamma-att-k와 beta-att-k를 만듭니다.
-
아래쪽에서는, z-id(주황색)가 fully connected layer를 거쳐 gamma-id와 beta-id를 만들어냅니다. 각 gamma들은 추후 element-wise 곱연산, beta들은 element-wise 합연산이 됨을 그림에서 알 수 있습니다.
중앙에 있는 초록색 부분이 이것들과 어떻게 연결되는지 보겠습니다. 초록색 tensor는 h-in-k로, k번째 AAD Resblock에 input으로 들어오는 tensor라는 뜻입니다.
h-in-k는 batch normalization 이후 h-hat-k을 만들어냅니다.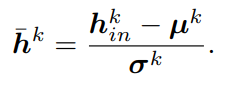
h-hat-k에 conv layer와 activation으로 sigmoid를 씌워 attention mask인 M-k를 만들어냅니다.
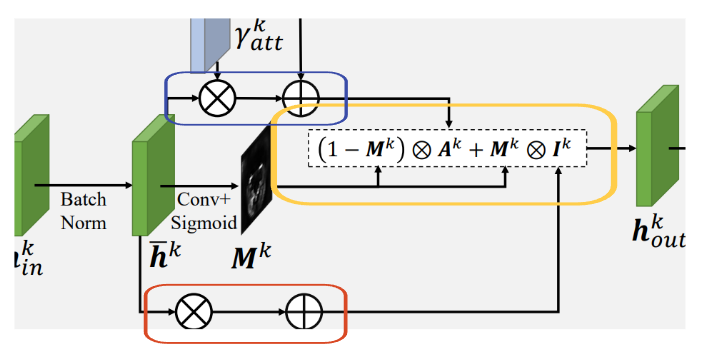
다음은 이 그림 속 공식 그대로 처리됩니다.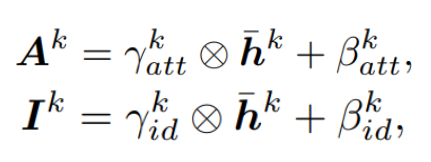
- A-k는 gamma-att-k와 h-hat-k을 element-wise multiplication한 뒤, beta-att-k를 더한 tensor입니다.
- I-k는 gamma-id-k와 h-hat-k을 element-wise multiplication한 뒤, beta-id-k를 더한 tensor입니다.
이해가 잘 안되신다면, 포스트 자체에 집중하시느라 구조의 큰 흐름을 놓치셨을 가능성이 높습니다.
결국
- A-k는 k번째 AAD Resblk에다가 attribute(=target)와 관련된 정보를 가져다주는 tensor
- I-k는 k번째 AAD Resblk에다가 identity(=source)와 관련된 정보를 가져다주는 tensor
라는 것입니다. 지금까지 concatenation을 하고, layer를 거치고... 했던 모든 일들은 이 두 가지를 만들어내기 위해서입니다.
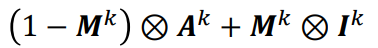
재밌는 점은, 이 공식의 표현이 마치 우리가 고등 수학에서 배운 내적같다는 점입니다. (1-M) x A + M x I로 단순화 했을 때, 마치 A와 I를 (1-M)과 M의 비율로 더하는 계산과 같아보입니다.
그런데, 저 합성곱 표시는 단순 곱이 아닌 element-wise 연산이라고 말씀드렸습니다. 또한, M-k은 attention mask로서 sigmoid를 지나쳤기 때문에, 모든 화소가 0 혹은 1입니다. 이렇게 되면, 결국 M값에 따라서 A와 I를 1:0으로 내적하거나, 0:1로 내적 - 즉, M값에 따라서 A값를 그대로 쓸지, I값을 그대로 쓸지 결정하게 됩니다.
※ M-k의 예시 - 얼굴 부분은 화소값이 1, 아닌 부분 (배경 등)은 화소값이 0
M, A, I 모두 사이즈가 똑같기 때문에 같은 위치에 있는 i번째 화소를 생각해보겠습니다. 만약 이 화소의 위치가 attribute에 해당하는 값이라면, M의 i번째 화소 값은 0일 것입니다. (1-M) x A + M x I에 따라서, output tensor의 i번째 화소의 값은 1 x A + 0 x I, 즉 A(attribute)의 화소값을 그대로 가지게 됩니다.
만약 이 화소의 위치가 identity에 해당한다면 반대로 M의 i번째 화소 값은 1 -> output tensor의 i번째 화소의 값은 0 x A + 1 x I, 즉 I(identity)의 화소값을 그대로 가지게 됩니다.
각각, identity에 해당하는 화소와 attribute에 해당하는 화소 예시입니다.
예시를 들기 위해 canny edge detection을 사용한 사진이며, 실제로는 머리카락이나 목 부분 등도 제외한 얼굴 내 landmarks들만 흰색으로 칠해져있게 됩니다.

HEAR-Net
AEI-Net은 완벽해보입니다. Faceswap-GAN처럼 얼굴을 뜯어내고 집어넣느라 생기는 부자연스러움도 없고, 2-stager라는 간단화된 구조덕분에 오류의 가능성도 적습니다.
하지만, 애초에 deepfake를 시도한 target 이미지가 문제가 있다면 어떨까요?

안경을 쓰거나, 몽콘을 쓰고 있고 이러한 장신구들이 얼굴을 침범하게 되면 딥페이크 시에 장신구가 아예 사라질 수도 있습니다. 이렇게 딥페이크 중 성공적인 합성을 방해하는 요소같은 것들을 occlusion이라고 합니다.
HEAR-Net은, 이러한 occlusion을 없애는 데에 사용합니다. 따라서, 만약 target에 occlusion이 없다면 HEAR-Net은 사용하지 않아도 됩니다.

좌측의 각각 src image와 tgt image가 있습니다. AEI-Net의 output으로 나오는 것은, 맨 오른쪽에 있는 y-hat-s, t입니다.
세 번째 줄에 해당하는 y-hat-t, t는 AEI-Net의 input으로 둘 다 target image를 넣었을 때의 결과입니다.
당연히, target image와 거의 유사하게 생겼으나, occlusion은 사라져버렸습니다 - 좌측을 덮은 머리, 이마의 체인이 AEI-Net을 통과하며 유실.
그런데, 의미 없어보이는 y-hat-t, t을 target image에서 빼면, 다음과 같은 결과가 나옵니다.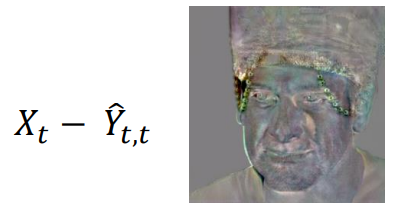
마치 attention map처럼, occlusion 부분의 weight값이 높아 두드러져 보입니다. 이 값을 ∆Yt라고 부릅니다.
HEAR-Net은 ∆Yt와 y-hat-s, t를 U-Net의 input으로 넣어 refined image를 얻어내는 구조입니다.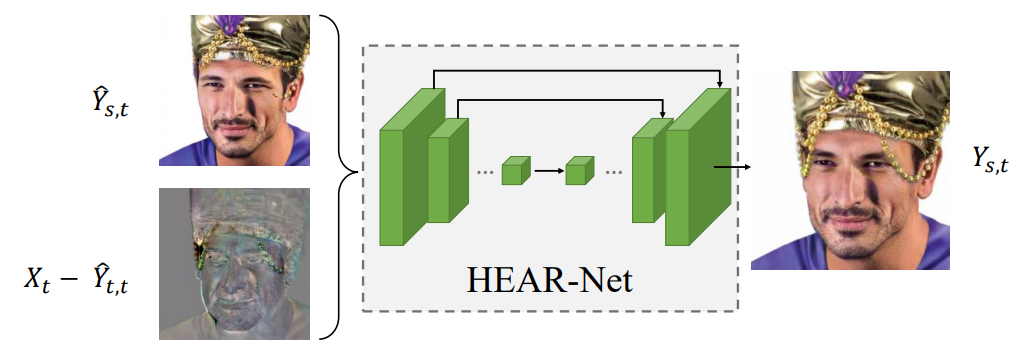
짜잔!
Summary
-
X-t에서 머리카락, 배경, 빛 배경 등의 '특성'(att)을 추출하기 위해 U-Net에 넣고, 여러 단계에 걸쳐 특성을 내포하고 있는 feature map인 z-att-k을 n개 (decoder 내에서만) 만들어냅니다.
-
X-s를 encoder에 넣어 '정체성'(id)을 내포하고 있는 latent vector인 z-id를 만들어냅니다.
-
이 z-id는 AAD ResBlk을 연속적으로 통과하는데, 각 AAD ResBlk은 (1 AAD layer + ReLU + 1 3x3 conv) x 2로 구성되어있습니다. 중요한 것은, AAD layer에서 일어나는 일입니다.
-
AAD를 한 번 통과할 때마다, 1) 초반에 n개 생성했던 z-att-k 중 하나와 2) z-id를 함께 연산합니다.
-
AAD의 input로부터 세 가지를 만들어냅니다 - 1) attention mask에 해당하는 M-k, 2) z-att-k로부터 파생된 gamma와 beta를 input과 각각 element-wise 곱/합연산한 A-k 그리고 3) z-id-k로부터 파생된 gamma와 beta를 input과 각각 element-wise 곱/합연산한 I-k
-
M-k의 각 원소값은 identity인지 attribute인지 0과 1로 나타내고 있기 때문에, 이 값에 따라 조건화되어 output의 원소는 A-k 그대로 혹은 I-k 그대로를 갖게 됩니다.
-
이 말은 즉, AAD module은 attention mask가 '정체성'과 '특성'을 나눈 대로 똑같이 z-id와 z-att를 배합한 tensor를 output으로 낸다는 것입니다.
Attention mask가 한 번에 완벽하게 만들어질 순 없기 때문에, AAD Resblock을 연속적으로 통과시킴과 동시에 매번 다른 attribute용 latent vector를 참고하는 것입니다.
여러 번 거친 뒤에는, attention mask가 잘 추출될 것이고, 이를 통해서 나온 마지막 AAD Resblock의 output - 즉 faceshifter의 output 또한 잘 만들어진 deepfake가 되는 원리입니다.
지난 모델들을 다루면서, 일부러 training loss들에 대해서는 다루지 않았습니다. 여기서 간단하게 각 모델 별로 어떤 loss를 썼는지 확인하고 넘어가겠습니다!
<AEI-Net>
1. Adversarial loss
- Y-hat-s, t를 사실적으로 만들기 위한 loss
- Downsampled output image에 multi-scale discriminator loss
- Identity preservation loss
- Identity가 src image와 같도록 학습
- Identity embedding의 cosine 유사도상으로 유사하면, 0에 가까워지도록 학습
- Attributes preservation loss
- Attriburtes가 target과 같도록 학습
- Output image와 target image의 attribute embedding을 구하여 L2 distance가 가깝도록 학습
- Reconstruction loss
- 학습할 때 source와 target이 같다면, reconstruction error가 0이 되도록 함
- AEI-Net loss
- 위 4개의 loss를 1:10:5:10의 비율로 통합하여 학습
<HEAR-Net>
- Identity preservation loss
- Source image의 identity를 유지하기 위한 loss
- Identity embedding의 cosine 유사도상으로 유사하면, 0에 가까워지도록 학습
- Change loss
- AEI-Net의 결과와, HEAR-Net의 결과가 너무 차이가 나지 않도록 하는 loss
- Reconstruction loss
- 학습할 때 src와 target image가 같다면, reconstruction error가 0이 되도록 학습
- HEAR-Net loss
- 위 세 loss를 1:1:1 비율로 통합한 loss
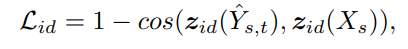
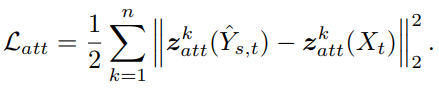
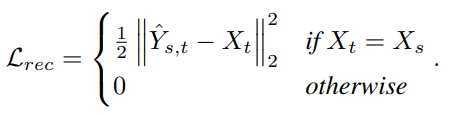
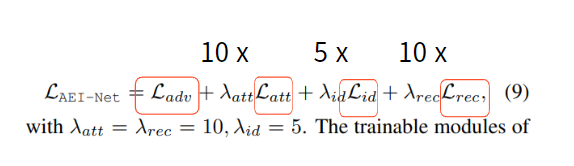
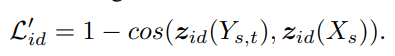
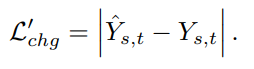
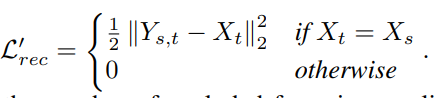
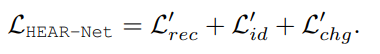
Try it!
가장 고민이 많았던 파트입니다.
Stable diffusion 포스트처럼 python 코드와 web demo 둘 다 공유할까? Web demo만 공유할까?
제 포스트를 자세히 볼 정도의 열정과 실력이 있으신 분이라면 아시겠지만, 사실 python 코드라고 해봤자 package의 실행법을 알려드리는 것 뿐입니다. 반대로 개인인 제가 deepfake의 full code를 작성하여, package 없이 from scracth로 작성하는 것은 사실상 불가능하고, 미친 짓에 가깝습니다.
게다가 DeepFaceLab의 코드는 정말 정말 깁니다... 일일이 세보진 않았으나, 1000줄이 넘을 것 같아서 첨부할 수 없었습니다.
실행 코드는 글의 여기까지 읽으신 여러분이라면 구글에 단 한 줄의 영어 검색을 통해서 쉽게 찾을 수 있습니다. Github, papers with code 혹은 포스트에 널려있습니다. 직접 코드를 찾아나서는 단계를 통해 한 번 더 학습 의지를 불태우셨으면 좋겠습니다.
제가 예시로 들었던 차은우님과 저의 deepfake 사진은 FaceHub에서 제작되었습니다.
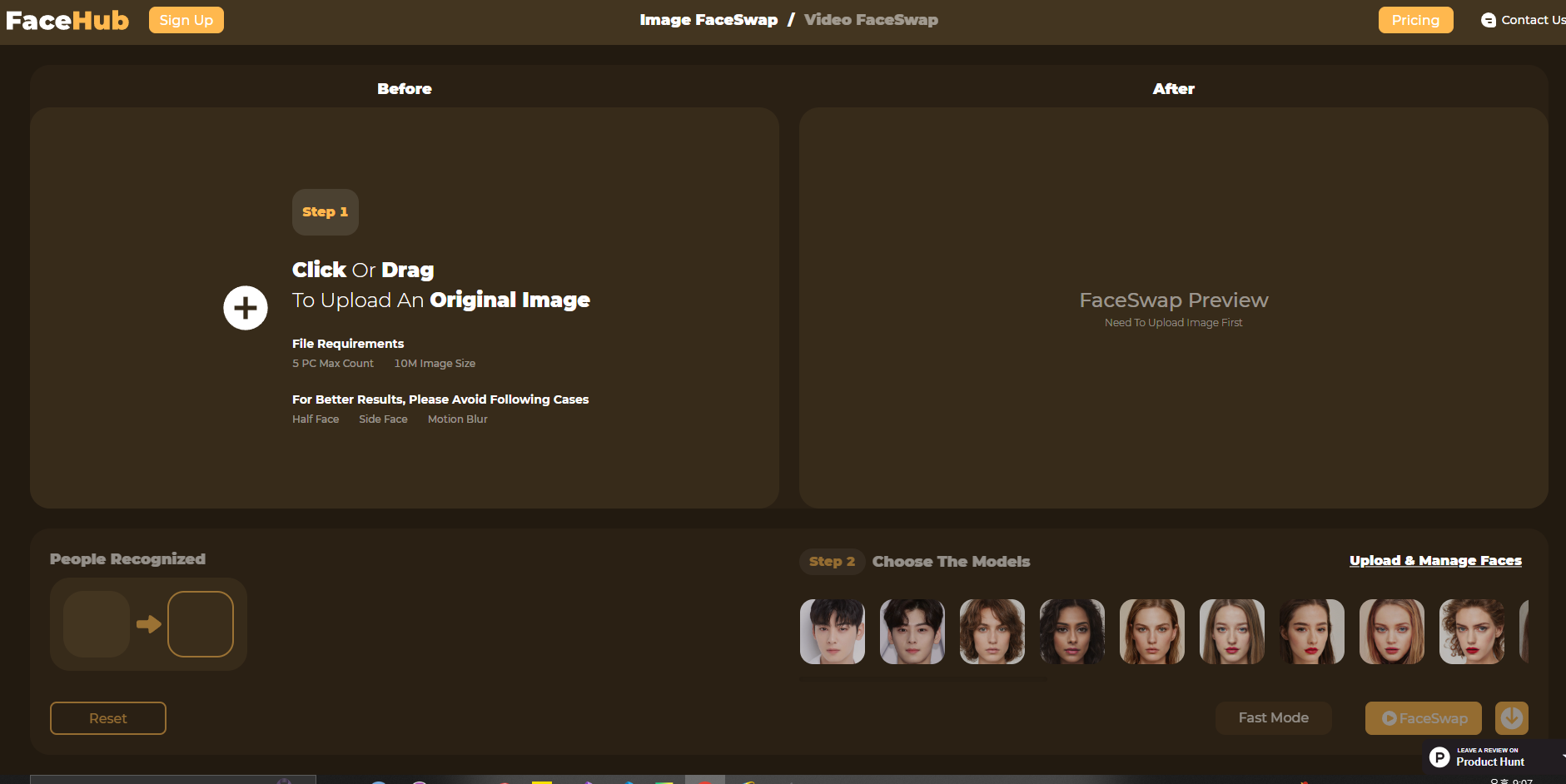
좌측 Before에 본인 혹은 외형만 유지할 사진(dst)을 넣으시면, 포스트 내에서 설명드린대로 face detection과 face recognition를 거쳐 crop된 사진이 등록됩니다.
Src, 즉 얼굴만 가져오고 싶은 사진은 우측 하단 Choose The Models에서 사전에 등록된 모델들을 사용하거나, 그 바로 위 Upload & Manage Faces를 클릭하여 직접 추가하실 수 있습니다.
FaceHub 말고도 영상을 대상으로 하는 deepfake 사이트, 실시간 카메라에 filter로서 연결해주는 deepfake 앱 등 여러 가지 활용이 가능합니다.
Conclusion
Don't avoid this technology
포스트 완성 직전, 한 플랫폼에 "딥페이크에 관한 포스트를 준비했다. 매우 놀라운 기술이다"는 글을 남겼었습니다.
 많은 사람들이 의아해했고, 한 친구는 나쁜 것이 아니냐는 질문을 던졌습니다.
많은 사람들이 의아해했고, 한 친구는 나쁜 것이 아니냐는 질문을 던졌습니다.
이 기술 자체가 선영향만 낳는 기술은 절대 아닙니다. 본질적으로 포르노 양산에 가장 크게 기여한 기술이 맞습니다. 하지만 문제는 거기까지만 알고 마음의 문을 닫아버리니 장점이 커져갈 여지가 전혀 없다는 것입니다.
Face swapping -얼굴 바꾸기- 가 deepfake의 일종이라는 것조차 아는 지인이 많지 않았습니다. 한국에 흔히 존재하는 버튜버에 대해서, 한창 유행했던 말 머리 snapchat filter 등의 기술이 deepfake와 어떻게 연관이 있는지는 궁금해하려고 하질 않습니다.
1년 반 전 훈련소에서, 문득 화상을 입은 사람들을 위해 실시간으로 마스크를 씌워주는 deepfake를 적용해보면 어떨까 고민했었는데, 상병이 되고 유튜브에 버튜버들이 이미 뜨기 시작했습니다. 하지만 그럼에도, 뉴스에는 99% 비판적인 기사 뿐이었습니다.
이 기술은 이미 존재하고, 음지에서 너무나 발전했습니다. 양지에서 발전하려는 노력이 몇 편의 논문과 함께 계속되고 있으나, 사람들은 여전히 마음의 문을 닫고 있습니다.
존재를 부정한다고 그들이 멈추지는 않습니다. 항상 진실을 정확히 알고, 비판하거나 개선할 방법을 찾는 것은 그 다음이라고 생각합니다. 여기까지 읽어주셨다면 이제 여러분의 몫이기도 합니다.
🐣 꼭 드리고 싶은 말씀
안타깝게도 eepfake를 직접 해보는 것에 얼마나 도움되는가를 생각해보면 이 포스트는 후순위일 지도 모릅니다. Deepfake tutorial, how to make deepfake, deepfake in python, deepfake 사용법, 딥페이크 만들기 ... 유튜브나 구글에서 검색하면 수백 수천 개의 훌륭한 자료들이 쏟아집니다.
그런데, 검색어를 조금 바꿔서 deepfake principle 혹은 딥페이크 원리라고 쳐보면 갑자기 자료의 양이 현저히 줄어듭니다. 기대감을 가지고 들어가면, 얕은 지식만을 겉핡기로 다뤄 거의 도움이 되지 않았습니다. Encoder와 Decoder를 두 쌍을 학습시키고 decoder만 서로 바꾼다는 내용은, 사전 조사 기간동안 수천 번도 넘게 보았습니다.
저도 deepfake의 architecture를 쳐다보는 것보단 직접 써보고 노는 것이 훨씬 재밌습니다. 하지만 세상에는 누군가는 해야할 일이 있다고 생각해서, 미뤄왔던 그 지겨운 일을 1주일에 걸쳐 해내고 이 포스트를 작성하는 데에 성공했습니다.
저는 제 블로그가 유명해지거나 후에라도 수익성이 되는 것에는 놀랍게도 조금의 관심도 없습니다. 단 하나 바라는 것은, 매 포스트마다 글의 conclusion까지 읽어주시는 분들이 조금씩이라도 늘어나는 것입니다.
평소엔 엄청 까불고 노는거 좋아하는데 꼭 데이터사이언스가 엮이면 너무 진지해지는 것 같네요 ㅋㅋㅋㅋㅋ 여기까지 읽어주신 분들은 댓글 꼭 달아주세요 :) 제가 한 분 한 분 감사인사 드리고 싶습니다 너무 고생하셨고, 여러분이 대한민국 AI의 현재이자 미래입니다!!! ~~
물론 저도 포함 ><
아, conclusion의 이름을 빌려 제가 하고싶은 얘기를 하는건 제 주특기입니다. 저는 정보를 전달했으니 각자의 멋진 결론을 만들어주세요 ㅎㅎㅎ
+솔직히 faceshifter은 논문을 너무 잘 쓴 것 같습니다. 이 복잡한 구조가 한 번 읽고 바로 이해가 되었을 정도입니다. 원문도 꼭 한 번 읽어보셨으면 좋겠네요!
+이번 포스트와 관련된 질문은 얼마나 복잡한지에 상관없이 언제든 환영입니다! 꼭 하루 안에 바로 답변해드리겠습니다 :)

15개의 댓글


안녕하세요 인공지능에 관심이 많은 고등학생입니다 ! 글이 이해하기 쉽게 되어있어 도움이 많이 되었습니다.
혹시 학교 발표자료에 인용해도 될까요 ??

혹시 원본 사진(인풋)에 딥페이크를 적용시킬 때 딥페이크 성능이 저하되어 이상한 아웃풋이 나오게 하는 방법도 있을까요? 예를 들면 원본 사진에 품질 영향 없이 어떤 데이터나 노이즈를 삽입한다던지요

혹시 이제 2학년이신가요? 정말 대단하십니다