
안녕하세요, JJun입니다. 감사하게도 지난 포스트였던 Deepfake의 원리가 많은 분들의 성원 덕에 Velog Trending 3위까지 올랐습니다.
많은 분들께서 응원과 격려의 메세지를 보내주셨고, 또 virtual human 분야 기업 단위로도 많은 관심을 받게 되어 정말 영광이었습니다.
그러나 이번 포스트는 반대로 Deepfake의 탐지에 관한 것으로, 이전엔 virtual human platform이나 live streaming platform에 도움이 되는 내용이었던 것과 달리, 불법 Deepfake를 어떻게 탐지하는 지에 대해서 다루게 됩니다 (처음부터 Deepfake Generation/Detection을 하나의 시리즈로 작성하기로 계획했습니다).
오늘 포스트에서는, deepfake를 (ViT)Vision Transformer라는 deep learning 모델을 사용하여 탐지하는 방법과 원리를 주로 소개해드리려 합니다.
- 지난 포스트와 달리, deepfake detection은 상대적으로 덜 대중적이며 전공지식이 많이 필요한 기술로 deep learning에 대한 지식이 있으신 분들을 대상으로 작성했습니다.
※ Transformer의 구조를 정확히 이해하고 있으신 분이라면, 이 포스트를 읽으시는 데에 큰 무리는 없으실 것이라 생각됩니다.
- 본 포스트는 Deepfake의 원리: 당신의 예상보다 훨씬 쉽고, 대단한 기술 포스트와 시리즈를 이루고 있으므로, 기술의 등장 배경과 같은 중복되는 스토리텔링을 대부분 삭제했습니다.
Deepfake - Pros and Cons
다시 한 번 deepfake의 장점과 단점에 대해서 짚어보겠습니다. 분명히 알고 넘어가야할 점은, 단점이 크게 조명되었을 뿐 수많은 장점들 또한 일상 생활에 녹아있다는 사실입니다.
Pros
다음은 우리가 잘 몰랐던 deepfake의 장점입니다.

- 엔터테인먼트 및 창작 분야 활용 : Deepfake는 영화나 TV, 쇼 등의 산업에서 배우의 연기나 특정 인물의 모습을 재현하여 창의적인 작품을 만드는 데 사용될 수 있습니다. 또, virtual human이나 avatar를 통해서 live streaming을 하는 virtuber나 virtual Idol의 예시를 볼 수 있습니다.
- 사회 문제 및 교육용 도구 : Audio deepfake는 발음이나 언어 능력을 개선하는 데 활용될 수 있습니다. 언어학 연구나 문화 교육 등에서 발음이나 억양을 연구하기 위해 사용될 수 있습니다. 또한, 일부만 남은 과거의 기록을 현대의 모습으로 복원할 수도 있습니다.
- 프라이버시 보호 및 보안 기술 : 엔터테인먼트 목적이 아니더라도, 신상 공개를 원하지 않거나 위협으로부터의 신변 보호를 원하는 사용자가 deepfake를 통해서 안전하게 활동할 수 있습니다.
Cons
그러나 다음과 같은 단점들이 있습니다.

- 합성 포르노 : Deepfake의 부정적인 인식에 가장 크게 기여한 기술입니다. 연예인들의 얼굴을 무단 도용하거나, 심지어 일반인 지인의 얼굴까지 사용하여 불법 포르노를 제작하는 것은 피해자에게 큰 정신적 고통을 줄 수 있습니다.
- 사기와 사회적 위험 : Deepfake는 사기나 사회적 혼란을 야기하거나, 허위 정보를 만들어내어 사회적 불안정을 유발할 수 있습니다. 푸틴과 오바마의 예시처럼, 정치적으로 조작된 가짜 뉴스나 비디오가 확산되어 혼란을 야기할 수 있습니다.
- 사생활 및 저작권 침해 : 누군가의 얼굴이나 목소리를 사용하여 가짜 영상이나 오디오를 만들 수 있기 때문에 사생활 침해의 위험이 커질 수 있습니다. 또 deepfake를 사용하여 유명인의 얼굴이나 목소리를 무단으로 사용하는 경우, 해당 인물의 저작권이 침해될 수 있습니다.
가장 이상적인 발전 방향은 deepfake의 장점만 발달시키는 것이겠지만, 현실적으로 이를 악용하는 사례가 많기 때문에 deepfake detection을 통해서 이러한 악용을 예방/후처리하게 됩니다.
특히, 유명인 및 일반인 합성 포르노가 가장 대두되고 있는 문제점인 만큼, image deepfake detection뿐만 아니라 video deepfake detection에도 관심을 가질 필요가 있습니다.
Prerequisites
① Basic knowledge on image processing
본 포스트는 독자를 'deep learning 중에서도 computer vision 분야에 지식이 있는 사람'이라고 가정하고 있습니다.
Deepfake의 결과물은 image 형태로, 이를 탐지하는 기술은 결국 image processing과 CNN 계열 모델에 대한 지식이 있어야만 이해할 수 있습니다.
또, 다음 공식이 보여주는 convolution 연산에 대한 이해도 필수입니다. 더 자세한 설명은 위키독스를 참고하시길 바랍니다.
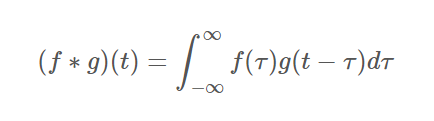
② Deepfake Principle Post (Optional)
Deepfake의 탐지 자체는 생성 이후의 image에 대하여 행하는 것이기 때문에, 생성 원리를 꼭 알아야할 필요는 없다고 생각하실 수 있습니다.
하지만, 우리가 real/fake를 분류하고자 하는 image의 특성에 대해서 잘 알고 있다면, 분명 detection 전반에 대한 이해도가 높아지고 성능 개선이 용이해질 것을 기대할 수 있습니다. 따라서 필수적이진 않으나, 앞선 Deepfake의 원리 포스트를 앞서 읽어보시는 것을 추천드립니다.
③ Transformer
'AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE' 라는 제목의 논문에서 소개된 ViT (Vision Transformer)는, NLP를 타겟팅한 Transformer의 encoder 부분을 차용한 뒤 이전/이후 구조를 조금 변형하여 computer vision task에서 사용할 수 있도록 한 모델입니다.
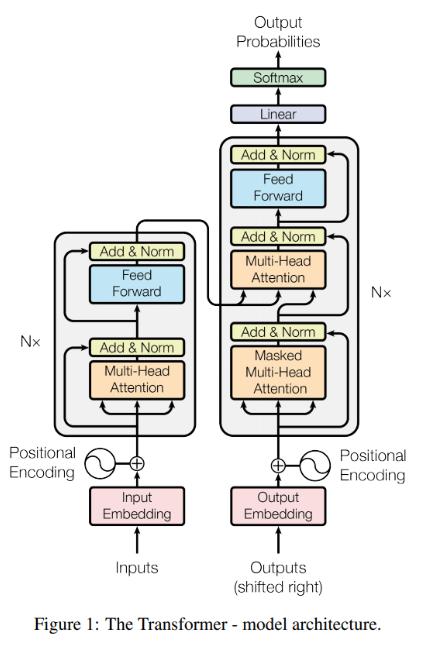
오늘 소개드릴 Tranformer 기반의 두 모델 모두 정확히는 ViT의 형태를 띄고 있지만, 최소한 Transformer에 대해서는 알고 계셔야 포스트를 이해하실 수 있습니다.
※ 추후에 ViT에 대한 설명 또한 Transformer를 베이스라인으로 두고 설명합니다!
Deepfake Detection
이렇게 생성된 deepfake를 탐지하는 작업에서는, 대부분의 기업이 deep learning (대중이 AI라고 부르는 것)을 활용하고 있습니다. 그러나, 물론 deep learning을 사용하지 않고 컴퓨터의 빠르고 양적으로 우월한 연산 능력에 기반한 탐지 방법도 있습니다.
지난 포스트에서도 언급된 facial landmarks를 100개 이상으로 포인트화한 뒤 정밀하게 비교하는 방법도 있습니다.
또, MIT Media Lab에서 컴퓨터의 도움 없이 일반인이 직접 deepfake를 구별할 수 있는 전략들을 정리한 메뉴얼을 공개하기도 했습니다.

하지만 대부분의 성능이 높은 탐지 방법은 모두 deep learning을 사용하고 있습니다. 바로 test image에 대해서 real/fake binary classification을 진행하는 간단한 시스템으로 만드는 것입니다. 이제 소개해드릴 Transformer-based detection 두 종류가 이와 같은 방식을 따르고 있습니다.
Non-Transformer-based로 소개되는 Intel사의 FakeCatcher는 image 자체에 대해서 deep learning을 하진 않지만, 영상으로 수집한 바이오 데이터를 deep learning으로 분석해 real/fake를 분류합니다.
부정적인 파급력이 높은 deepfake는 보통 image가 아닌 video 형태이기 때문에 이에 대해서 탐지하는 경우가 더 많지만, video도 결국은 image frame의 연속이므로 간단하게 image를 기준으로 설명하겠습니다. 실제로는 input이 video로 쓰이는 경우가 대부분이라는 점을 알고 넘어가주셔야 합니다!
Transformer-Based
※ 사실상 computer vision task에서 쓰이는 Transformer가 ViT이기 때문에, 이 둘을 구분없이 혼용하고 있습니다.
① ViT + EfficientNet
첫 번째는 Combining EfficientNet and Vision Transformers for Video Deepfake Detection라는 논문에서 소개된, ViT와 EfficientNet을 함께 사용한 deepfake detection 방법입니다. 우선, 오늘 포스트에서 핵심 소재인 ViT에 대해서 설명을 하겠습니다.
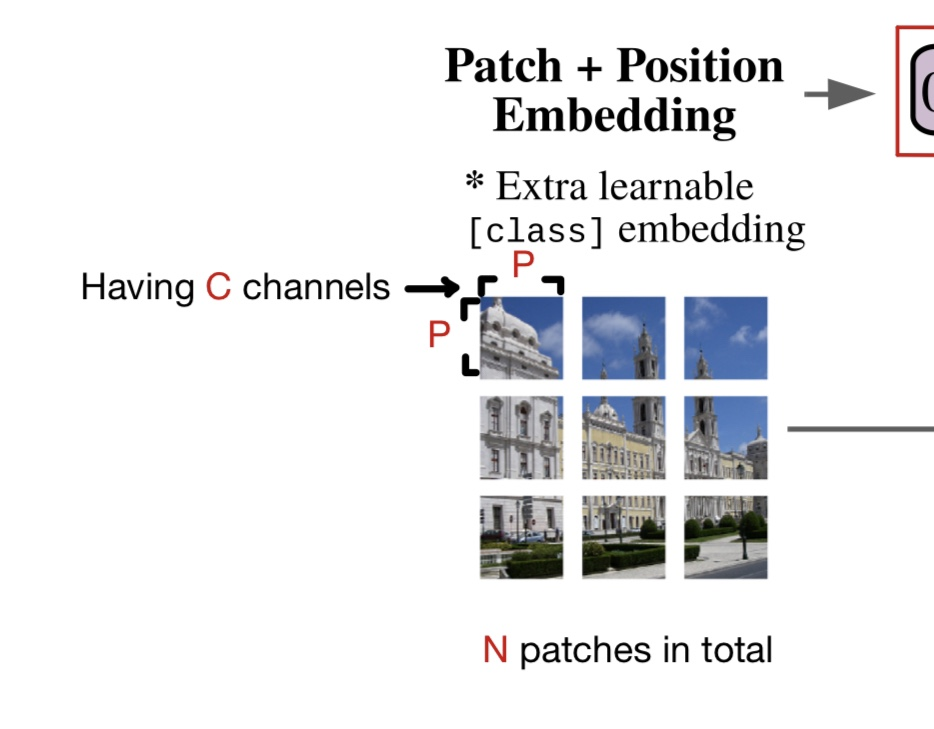
다음은 ViT의 구조입니다. Input으로 이미지를 받고, 이 이미지를 N개의 patch로 자른 뒤, 각각을 flatten하고 linear projection (linear transformation, 여기에선 feature map같은 역할을 하는 feature patch로 변형시키는 과정이라고 보셔도 무방합니다)을 하는 것입니다.
여기엔 각각 Transformer에서처럼 Position Embedding가 각 patch에 병렬적으로 붙고, Encoder에 투입됩니다.
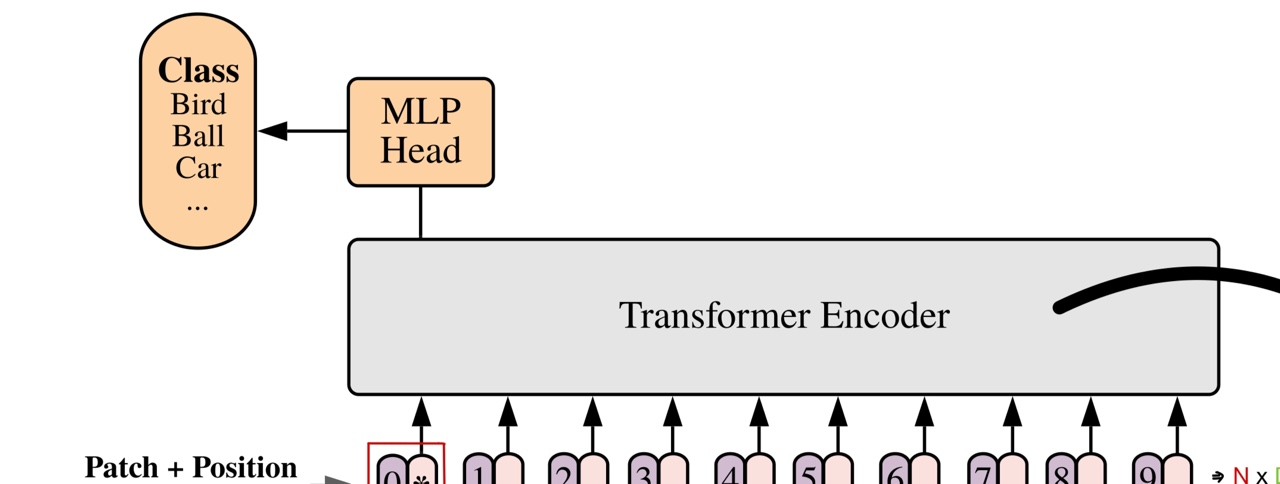
Encoder의 output으로 나온 matrix는 MLP Head에 다시 들어가서, 최종적으로 일반 classification task로 마무리하는 것입니다. 주의할 점은 제가 이전 포스트에서 backbone, neck 그리고 head에 대해서 설명한 것처럼, head는 마지막 classification을 위한 파트만 말하는 것이라는 점입니다.
파트별로 조금 더 상세하게 설명을 해보겠습니다 :)
원본 이미지의 해상도를 H x W라고 했을 때, 이를 P x P의 patch들로 나눈다면 총 N(= (HW/P^2))개의 patch들이 생성됩니다. 이후 Transformer에서와 마찬가지로 각각에 대한 position embedding을 생성합니다.
각각의 패치는 C개의 channel을 갖고 있습니다. 따라서, 전체 patch의 shape는 N x (P^2 X C)입니다. 이 patch matrix는 linear projection을 거쳐, N X (D)라는 2D-shaped patch matrix로 변환됩니다. N개의 각 patch는 구분되어 transform되었기 때문에, 다시 분리하여 각각에 이전에 언급한 position embedding을 붙여줄 수 있습니다.
Position Embedding이 붙어도 결국 shape는 2D matrix이기 때문에, 이를 Transformer의 Encoder로 투입한 뒤, output으로 나온 matrix를 다시 MLP Head에 투입하여 결과적으로 마지막에 softmax를 사용한 multiclass classficiation을 진행합니다.
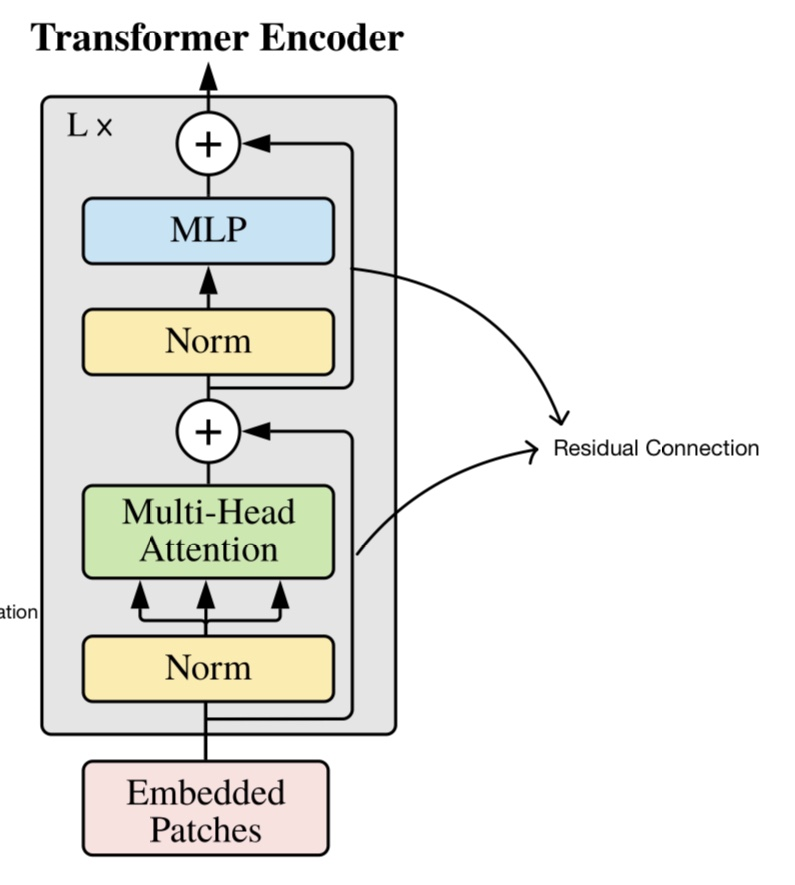
이 때 사용한 Transformer의 encoder는 어떻게 생겼는지 살펴보겠습니다.
Norm layer를 거치고, multi-head attention layer를 거친뒤의 결과를 최초의 input과 residual connection을 사용한 output을 냅니다. 이는 같은 방법으로 norm layer와 MLP layer를 거치게 됩니다.
아시다시피, 이 하나의 큰 unit을 총 L번 반복합니다. 결국 마지막에 있는 layer가 MLP layer이기 때문에, encoder를 거치고 나오면 encoded embedded patches라고 불릴 수 있는 것의 matrix가 output으로 나오게 됩니다.

이와 같은 배경지식을 가지고, 이제 ViT + EfficientNet 논문에 소개된 모델의 architecture를 보겠습니다.
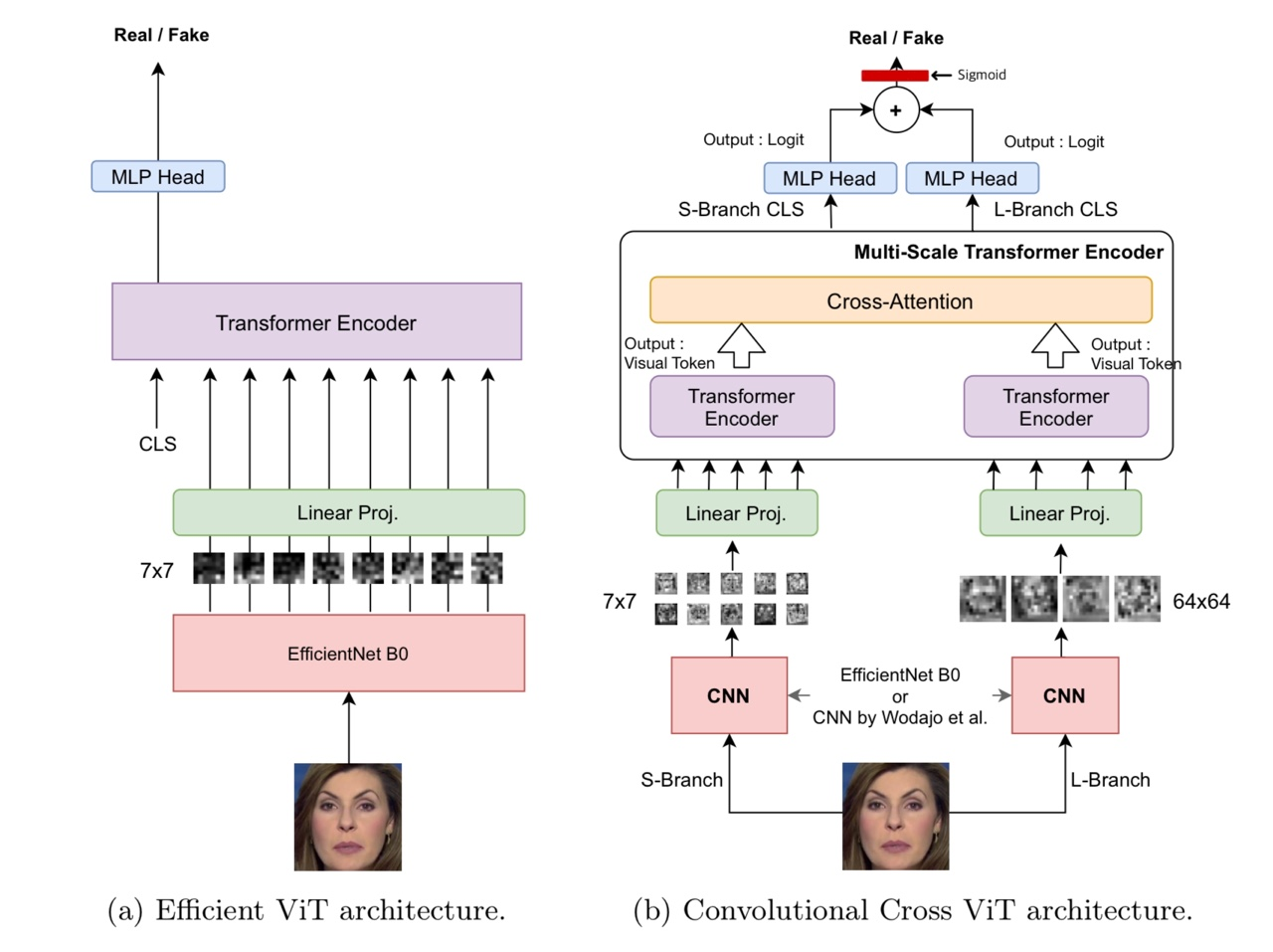
Figure (a)와 (b)의 차이점은, 명시된 대로 cross 되었는지의 여부입니다. (A)에서는 단일 ViT의 구조를 차용했는데, 이 때 patch를 나누는 과정에서 기존대로 동일 규격으로 자르는 것이 아닌, **EfficientNet B0**를 사용해서 추출하였습니다.
만약 이 과정에서 EfficientNet B0을 생략한다면, ViT를 통한 binary classification이 되는 것입니다. 따라서 EfficientNet은 patch를 이미지 슬라이스가 아닌 feature map으로 대체하기 위한 convolutional extractor로 채택된 것입니다.
다른 CNN 계열 모델로 바꾸어도 성능 면에서 크게 차이가 없을 것으로 보여지기 때문에, EfficientNet에 대한 설명은 생략하겠습니다.
이제 Figure (b)의 cross 구조만 남았습니다. Architecture를 다시 보겠습니다.
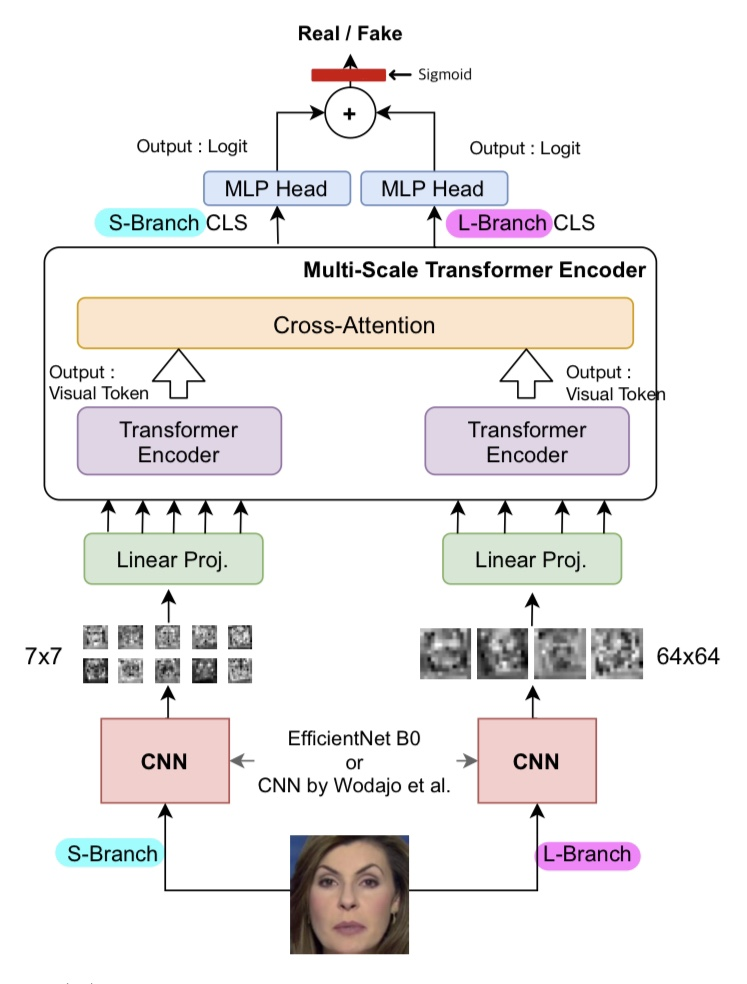
S-Branch와 L-Branch로 나뉘어서 병렬적으로 진행되는데,
- 1) 각 branch별로 patch의 크기가 다릅니다.
- 2) 서로 다른 두 개의 결과를 cross attention을 통해서 합친 뒤,
- 3) 서로 다른 CLS를 부여하여 나온 두 개의 output을 sum합니다.
각 스텝에 대하여 더 자세하게 보겠습니다.
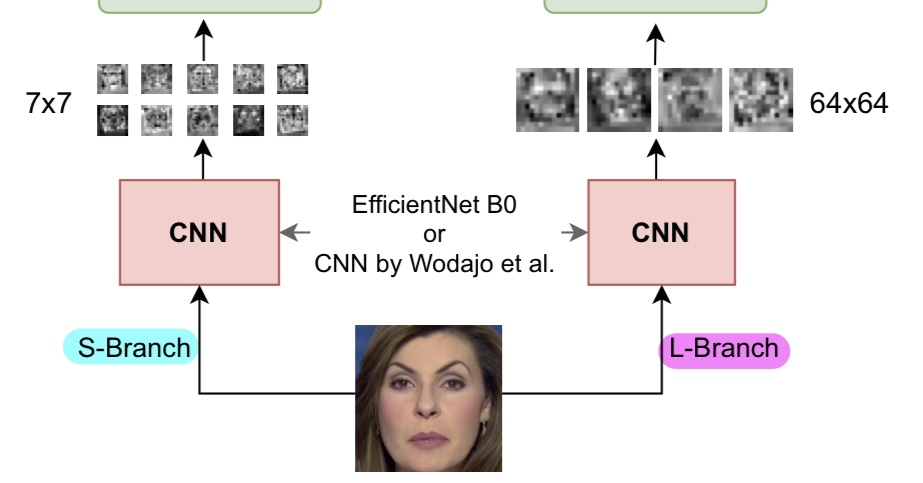
1)
논문에선 각각 EfficientNet B0과 Wodajo라는 분에 의해 구상된 CNN을 사용하여 S-Branch와 L-Branch를 구성하고 있습니다.
각각의 patch size에 대해서 다른 SOTA 모델을 써도 된다는 것이 제 의견이지만, 7 x 7과 64 x 64 크기에 대해서 꽤 최적화된 두 모델을 제시한 것으로 보여집니다.
 논문에서는, S-branch는 더 작은 patch를 다루고, L-branch는 더 넓은 receptive field를 다루기 위해 더 큰 patch를 다루는 branch라고 설명합니다.
논문에서는, S-branch는 더 작은 patch를 다루고, L-branch는 더 넓은 receptive field를 다루기 위해 더 큰 patch를 다루는 branch라고 설명합니다.
다음 과정은 또 어떻게 다른지 보겠습니다.
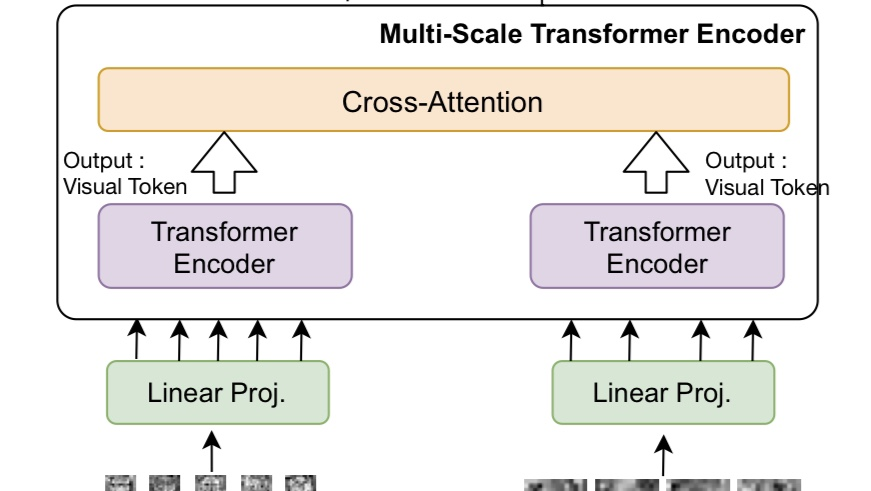 2)
2)
각각 linear projection과 encoder 투입도 병렬적으로 진행한 뒤, output으로 나온 visual token들을 cross-attention 연산을 통해 하나로 합칩니다. 논문에선 이 cross-attention으로 나오는 output이 무엇인지 정확히 명시하지 않았으나, 이어질 구조를 보면 weight vector일 것으로 예상됩니다.
다음은 마지막 스텝입니다.
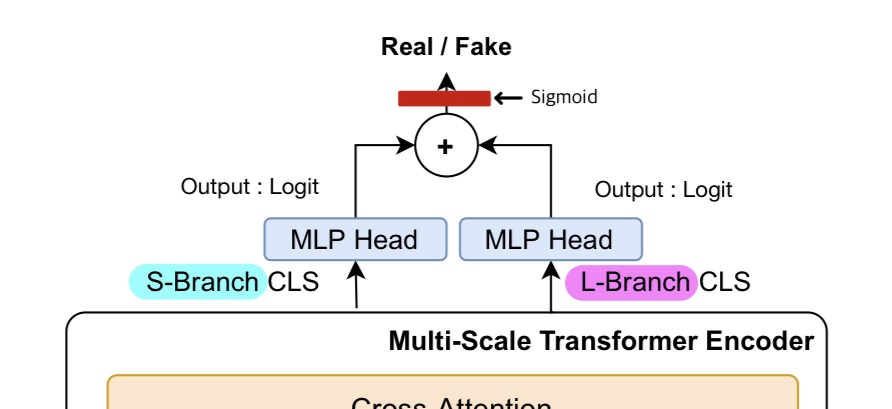
3)
2)에서의 output인 cross-attention vector에 각각 S-Branch CLS와 L-Branch CLS를 이용해 각각 logit을 구합니다. 이 때, 논문에선 언급되지 않았으나 이 CLS 토큰들은 다른 embedded patch들과 마찬가지로 encode되었을 것입니다.
Logit이란, 우리가 확률을 지칭하는 p의 범위는 [0, 1]이나, machine learning에서의 예측값은 이 범위를 따르지 않습니다. 따라서 이 값을 확률로 표현하기 위한 식에서, 다음과 같은 공식을 가집니다.
이 공식은 우리가 logistic regression에서 사용하는 공식이며, 이 때의 L이 logit입니다.
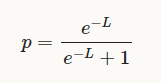
CLS token은 "Classification"을 나타내는 약어입니다. 이 토큰은 input sequence의 맨 처음에 추가되며, 모델은 이 토큰의 표현을 활용하여 전체 input sequence에 대한 의미를 요약하거나 추상화합니다.
즉, encoded CLS token은 성공적으로 input sequence(= embedded patches)에 대한 정보를 요약했을 것이고, 이를 cross-attention의 output에 제공함으로서 각각의 branch에 해당하는 logit을 추출하는 것입니다.

논문에서는, 이렇게 각 branch에 해당하는 logit을 구하고 나면 단순 덧셈을 한 뒤 위의 공식을 따라 sigmoid를 통해 확률을 구한다고 합니다. 이 확률을 통해, 주어진 image에 대해서 fake/real을 classify하게 되는 것입니다.
② ICT

ICT는 Identity Consistency Transformer의 약자로, 중국의 대학과 MS가 협업하여 개발한 deepfake detection approach입니다. Unite.AI에서 Identifying Celebrity Deepfakes From Outer Face Regions라는 타이틀의 기사로 소개하였습니다.
이름에서 알 수 있듯이, Transformer (ViT)를 활용하여 identity가 일치하는지 확인하는 방법으로 real/fake를 분류하는 접근법을 사용합니다.

Unite.AI는 '기존의 deepfake generation의 SOTA인 DeepFaceLab과 FaceSwap조차 outermost area(얼굴의 외곽 부분)을 무시한다'고 주장합니다.
-
Deepfake 모델을 학습시키는 것은 시간과 자원이 무척 많이 들기 때문에, 연산량을 줄이기 위해서입니다.
-
비용 문제 이전에, SOTA 모델조차 볼과 턱과 같은 얼굴의 끝 부분을 복제하는 데에는 제한이 있기 때문입니다.
즉, 반대로 말해서 기존의 deepfake는 outermost area에 약점이 있어 쉽게 검출되는 경향이 있었다는 의미입니다.
하지만, ICT는 이를 방지하기 위해 inner face와 outer face의 identity를 동시에 학습합니다.
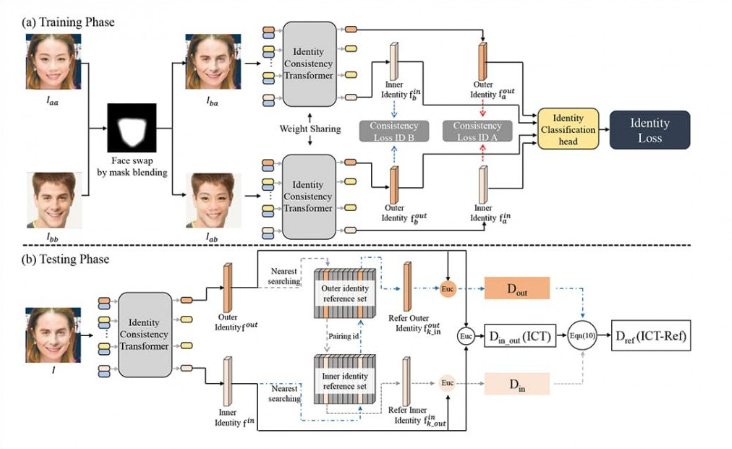
위는 ICT의 architecture입니다. ICT 논문 리뷰가 아니기 때문에, ViT의 역할을 제외한 나머지 부분은 가볍게만 설명하겠습니다. 우선 (a) Training Phase를 먼저 보겠습니다.
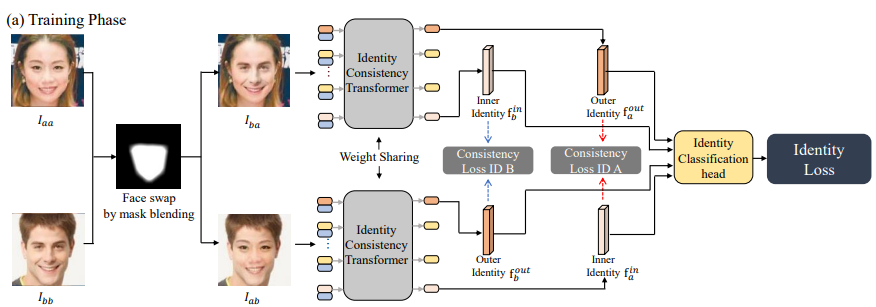
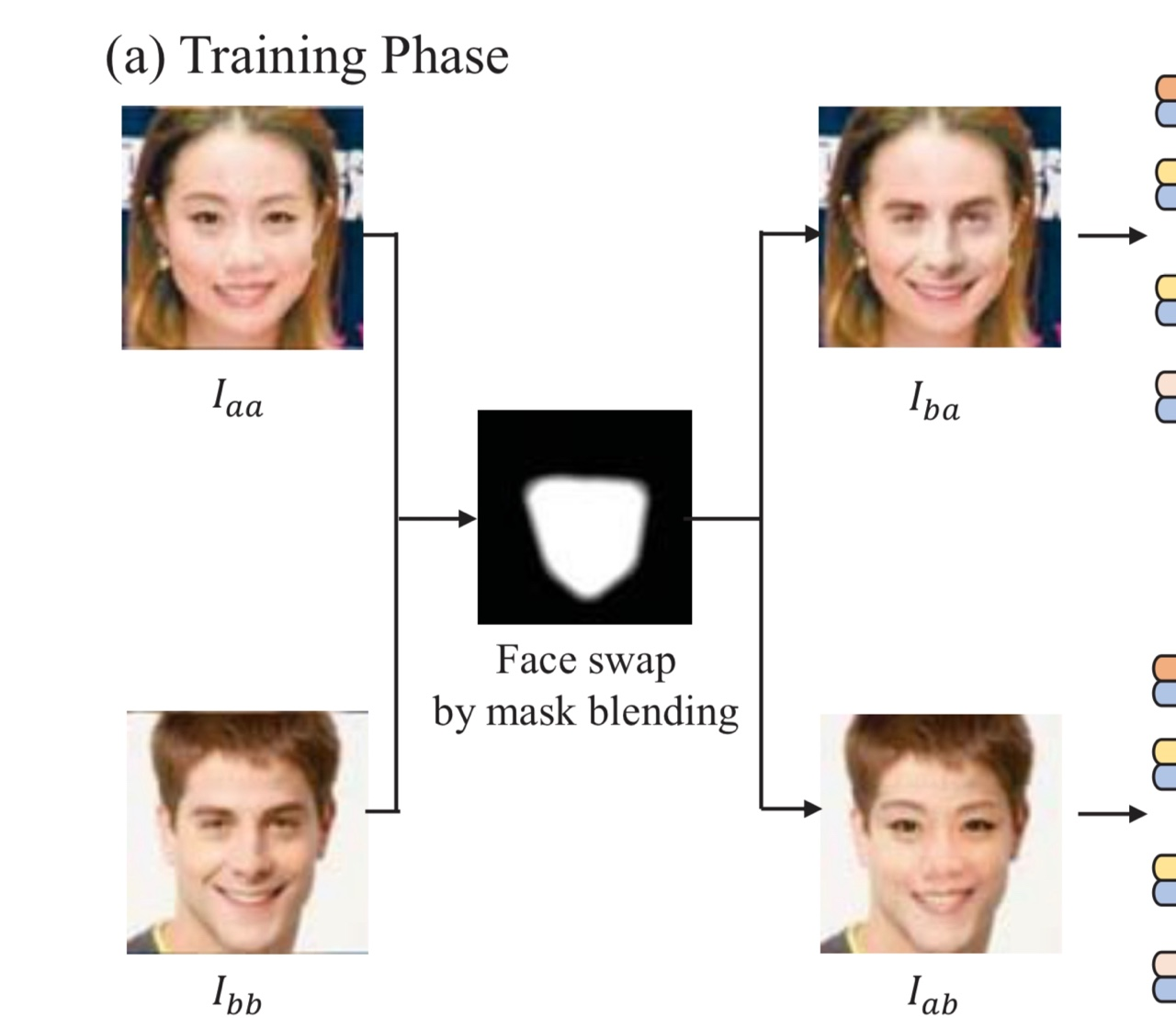
학습 시에는 I-aa와 I-bb라는 실제 인물의 사진 두 장을 Mask blending을 통하여, identity가 뒤바뀐 I-ba와 I-ab로 변환시킵니다.
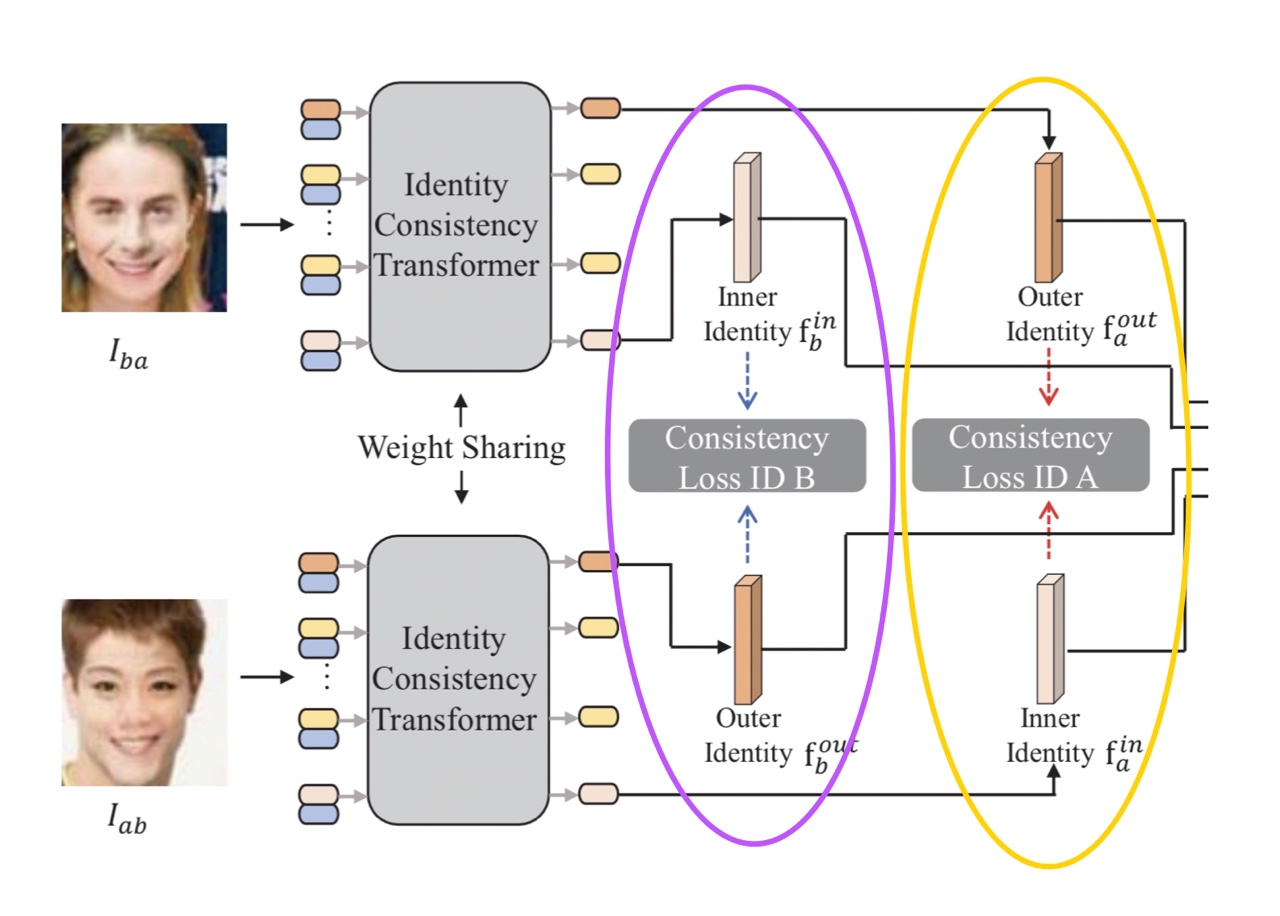 I-ba와 I-ab 각각을 ViT (정확히는 ICT이지만, 구조 설명 전까지는 ViT라고 하겠습니다) 에 투입한 뒤, 결과로 나온 encoded embedded patch 중 첫 번째와 마지막 patch를 각각 outer identity와 internal identity에 대한 representative로 이용합니다.
I-ba와 I-ab 각각을 ViT (정확히는 ICT이지만, 구조 설명 전까지는 ViT라고 하겠습니다) 에 투입한 뒤, 결과로 나온 encoded embedded patch 중 첫 번째와 마지막 patch를 각각 outer identity와 internal identity에 대한 representative로 이용합니다.
ICT는 얼굴의 내부(inner)와 외부(outer)를 함께 고려할 수 있도록 학습하는 것을 목표로 하기 때문에, 위와 같이 두 개의 inner identity - outer identity 쌍에 대하여 consistency loss를 계산합니다.
Consistency Loss ID B : I-ba의 inner identity와 I-ab의 outer identity간의 일치도
Consistency Loss ID A : I-ba의 outer identity와 I-ab의 inner identity간의 일치도
ICT는 deepfake 결과물의 얼굴 안쪽과 바깥쪽의 일치도에 주목하기 때문에, 두 장의 input image를 inner, outer만 반대로 합성한 I-ba와 I-ab에 대해서 모두 학습하기 위해서 두 개의 loss를 사용하는 것입니다.
이후 head 파트에서 real/fake를 classification합니다. 이제 편의상 ViT라고 언급한 ICT의 architecture를 보겠습니다.
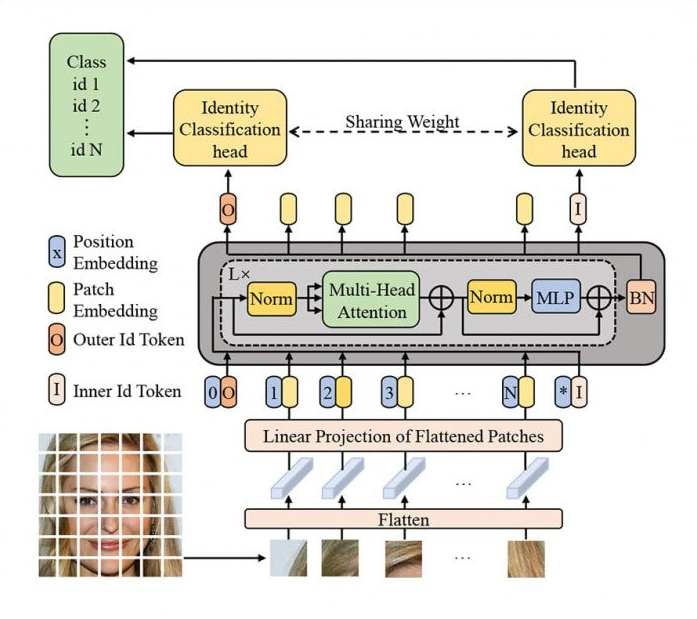
ViT와 유일하게 다른 점은, CLS token 하나가 아닌 inner id token과 outer id token 총 두 개를 넣는다는 것입니다. 요약해야할 정보가 두 개가 되었으니, 자연스러운 구조 변경입니다.
이제 (b) Testing Phase를 보겠습니다.
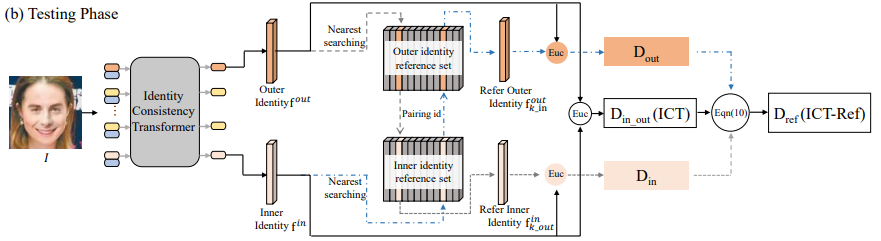
Testing Phase가 조금 어려우실 수 있는데, 논문 리뷰가 아니기 때문에 복잡한 연산에 대한 설명은 생략하고 아이디어에 대해서만 설명하겠습니다.
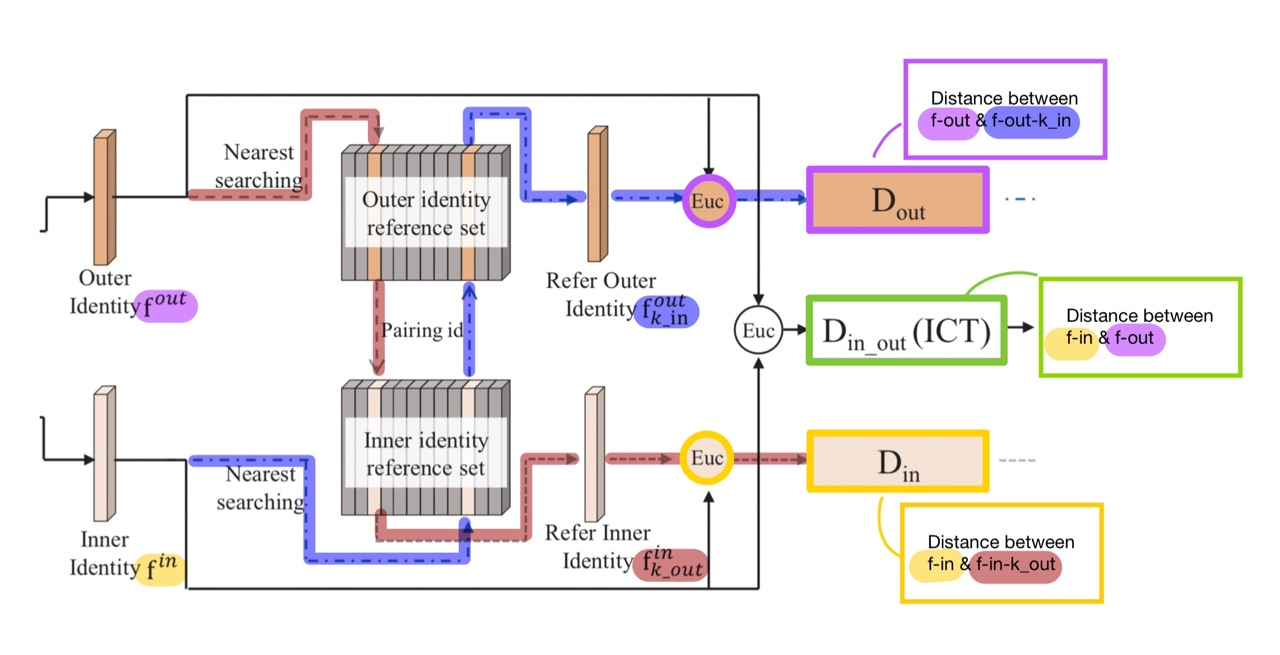
- f-out : Outer identity를 대표하는 feature
- f-in : Inner identity를 대표하는 feature
Identity reference set은 주어진 id에 대하여, 유사도를 비교할 N개의 후보 real face images를 담은 reference set입니다.
이 때, k_in과 k_out의 identity reference set에서의 정확한 정의는 다음과 같습니다.
즉, k_in은 f-in에 대하여 reference set 중 가장 distance가 작은 (= 유사도가 큰) f-in-n (reference set 중 하나)의 index를 가리킵니다. K_out도 같은 이치입니다.
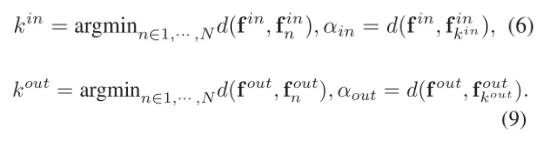
그렇다면, 다음 두 개는 이렇게 이해할 수 있습니다.
- f-out-k_in : f-out에 대한 reference set에서, k_in이라는 index를 사용하여 (architecture에서의 pairing id) 접근한 real face의 identity vector
- f-in-k_out : f-in에 대한 reference set에서, k_out이라는 index를 사용하여 접근한 real face의 identity vector
- D-out : f-out과 f-out-k_in 사이의 distance
- D-in : f-in과 f-in-k_out 사이의 distance
- D-in_out : f-in과 f-out 사이의 distance
※ Distance function은 유클리드(Euc) 거리가 아닌, 사전에 미리 정의된 거리 함수
이제 이 값들이 최종적으로 어떻게 되는지 보겠습니다.
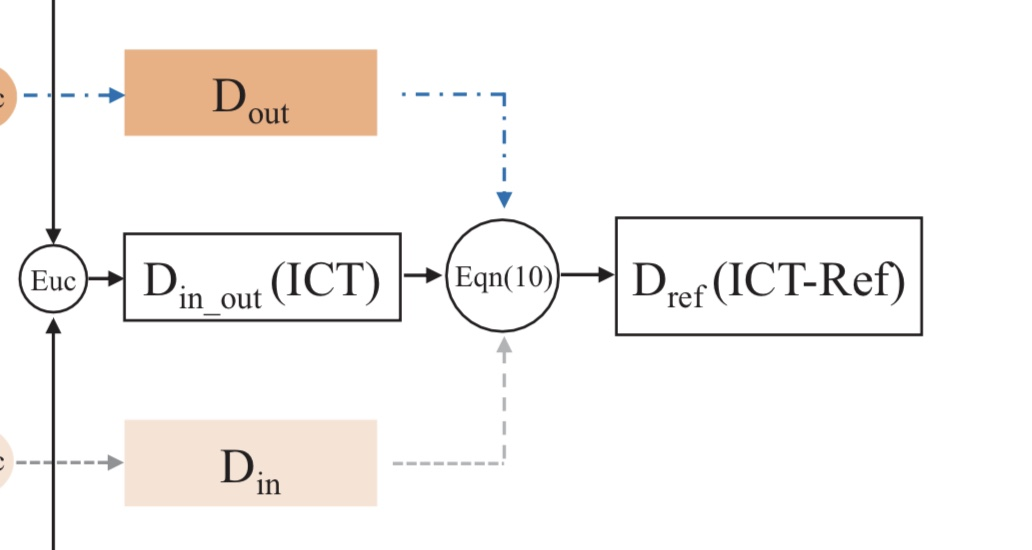
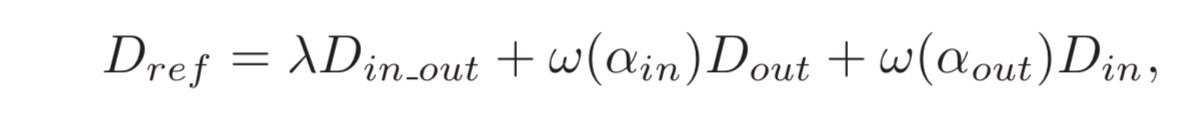
- ω : 해당하는 distance의 중요도를 나타내는 Weigh function
- λ : Balancing parameter
- D-ref : 모든 distance값을 고려하여 계산되는 최종 reference-assisted identity consistency값
논문을 읽어보신 뒤에도 이 파트를 이해하는데에 어려움이 있으시다면 편하게 댓글이나 이메일로 질문해주세요!
이렇게 해서, ICT는 inner face와 outer face의 consistency를 두 개의 loss를 이용하여 학습하고, inference에서는 reference set을 이용하여 inner face와 outer face가 서로 얼마나 잘 어울리는지를 넘어서 각각이 '실제 image의 자연스러움과 비교했을 때 얼마나 차이가 나는가'까지 참고해, 정밀하게 deepfake detection을 수행할 수 있다고 보여집니다.
Non-Transformer-Based
다음은 Transformer는 아니지만, AI를 사용한 모델들입니다. 사실 일반 AI를 사용한 detection 방법은 셀 수 없이 많아서, 현재 성능이 가장 높다고 여겨지는 Intel사의 FakeCatcher와, 한때 object detection의 SOTA였던 YOLO를 사용한 모델 두 가지를 소개해드리려 합니다.
FakeCatcher
Intel사에서는 지난 해 12월 실시간 탐지로 96%의 정확도를 보이는 놀라운 모델인 FakeCatcher를 소개했습니다.

"딥페이크 영상은 이제 어디에나 있다. 당신은 아마 이미 그것들을 보았을 것이다; 자신들이 실제로 한 적도 없는 말이나 행동을 하는 연예인들의 영상을 말이다."
-Ilke Demir, senior staff research scientist in Intel Labs
Intel사는 이전부터 deepfake의 기술적 가치와 동시에 위험성에 대해 꾸준한 관심을 보이면서, 연구팀을 꾸려 적지 않는 분석 논문 및 기사를 대중에게 공개해왔습니다.
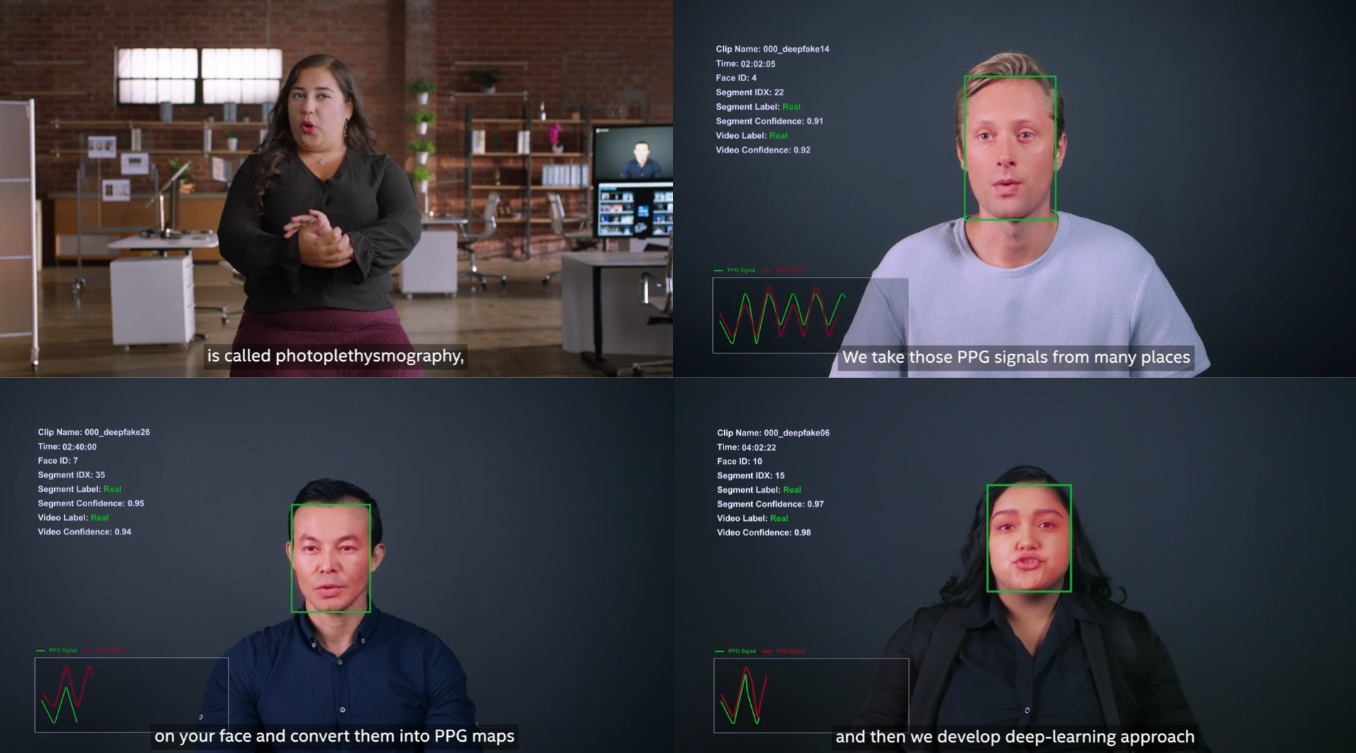
FakeCatcher는 blood flow(혈류)의 분석을 통해서 deepfake를 탐지합니다. 인간은 감정적으로 조금이라도 변화가 생기면, 정맥의 피가 펌핑되어 색변화를 나타내게 됩니다. 이는 인간의 눈으로는 파악하기 어렵지만, Intel은 photoplethysmography(PPG, 광혈류 측정법)을 통하여 혈류 변화라는 바이오 데이터를, computer vision을 통하여 수집하고 분석합니다.
PPG란, 혈중 산소 포화도(SPO2) 측정에 널리 사용되고 있는 기술입니다. 발광기(light emitter)를 사용해서 인체에 빛을 쏜 다음에, 반사되거나 흡수되지 않은 광량을 수광기를 사용해서 측정합니다.
수집한 데이터를 PPG map(PPG 데이터에 대한 시공간 지도)로 처리한 뒤, 이를 deep learning으로 분석하는 것입니다. 이는 image 자체가 아닌, 인간의 특성에 기인한 접근법이라는 점에서 deep learning의 불완전함을 보완한 훌륭한 기술이라고 평가할 수 있을 것 같습니다.
(FakeCatcher에 관한 더 자세한 정보는 Intel Introduces Real-Time Deepfake Detector 기사를 참고하시길 바랍니다.)
YOLO-Face
YOLO-Face를 사용한 비슷한 구조의 논문이 몇 가지 있는데, 제가 설명할 구조는 citation이 10밖에 되지 않는 Deepfake video detection: YOLO-Face convolution recurrent approach라는 논문에서 소개된 구조입니다.
미리 말씀드리자면 one-stager로 사용해도 감당하기 어려운 deep learning 모델을 3개(XGBoost Classifier까지 4개)나 사용하고 있어 실용성은 떨어지나, 아이디어가 재밌고 취지에 맞는 기술이라 여겨져 소개해드립니다.
-
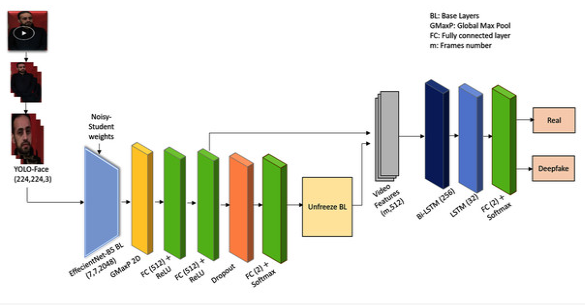
Task를 real/fake classification으로 두고, input image로부터 YOLO-Face을 통해 얼굴 부분만 추출합니다.
-
이를 약간의 변화를 준 EfficientNet-B5에 Global Max Pooling을 한 뒤 FC를 겹겹이 이어붙입니다.
-
Transfer learning을 위하여 unfreeze model을 이어붙임과 동시에, 마치 skip connection처럼 그 전의 FC layer에서의 output을 함께 참고하여 feature를 생성합니다.
-
Low-level feature가 되면서 잃은 temporal consistency를 복구하기 위해, Bidirectional LSTM cell을 추가해줍니다.
-
Head에서 real/fake를 분류합니다.

구조에 대한 설명 전문을 첨부해드립니다 :)
YOLO-Face는 여러분이 아시는 object detection의 SOTA였던 YOLO의 face detector 버전입니다.
다른 논문들도 이러한 구조를 똑같이 따르지만, 아래와 같이 EfficientNet-B5를 ResNet으로 바꾸거나 LSTM cell과 head를 단순 XGBoost Classifier로 대체하는 등 조금씩 변화를 준 정도입니다.
(논문 링크 : A New Deep Learning-Based Methodology for Video Deepfake Detection Using XGBoost)
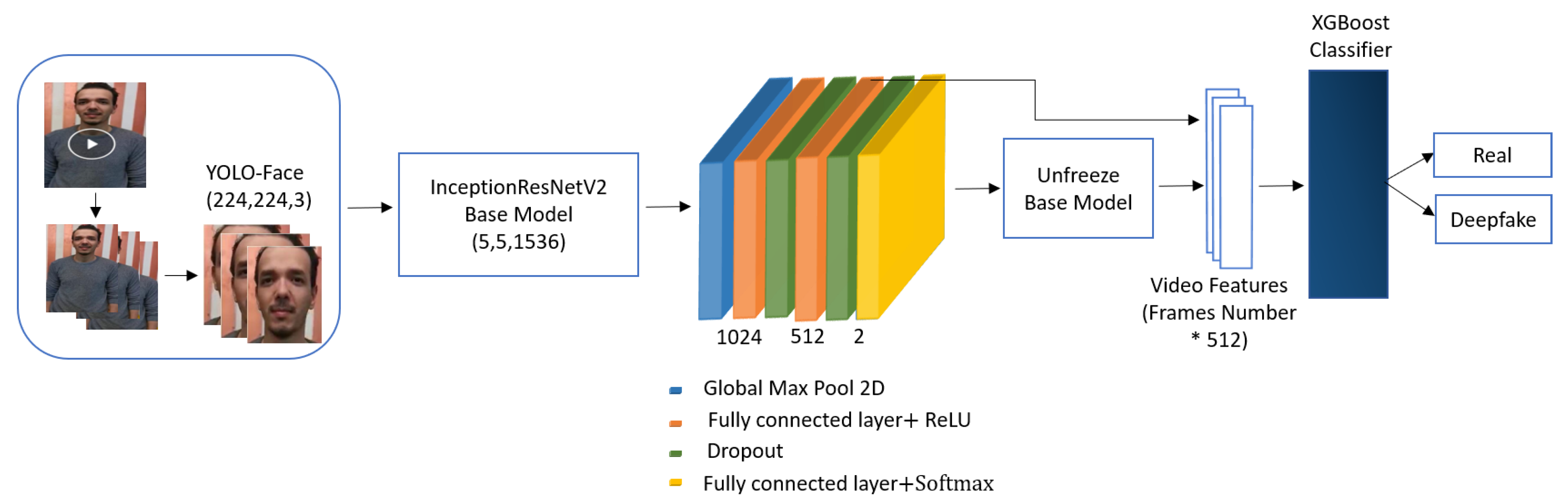
그래도 무작정 여러 모델과 layer을 이어붙이기만 한 것은 아닙니다.

위와 같이 YOLO-Face의 bounding box를 22% 키우거나, EfficientNet의 top layer를 제거하는 등 꽤나 설명력이 있는 시도들이 많아서 흥미로운 구조인 것 같습니다.
관심이 있으신 분들은 추가로 논문을 읽어보시는 것도 추천드립니다!
(논문 링크 : Deepfake video detection: YOLO-Face convolution recurrent approach)
Conclusion
- 비록 Transformer-based approach를 주로 소개하긴 했으나, 인간이 이미 높은 수준의 기술력을 보유한 바이오 데이터 분석과 deep learning의 최대 장점만 살리는 방향으로 접목한 Intel의 FakeCatcher가 가장 좋은 예시라고 개인적으로 생각합니다.
결국 deep learning은 black box 문제를 갖고있기 때문에, 어떤 부분에서 deep fake라고 느꼈는지에 대한 명확한 근거를 제시하기 어렵습니다. 동시에 deep learning 관련 분석력은 bio 데이터 분석력에 비해 축적된 지식이 현저히 적습니다. 따라서 Transformer-based approach들처럼 deep learning architecture을 모델이자 동시에 하나의 시스템으로 만들어버리는 것은 위험하다고 생각합니다.
- 특히 YOLO-Face를 사용한 detection이나 ViT + EfficientNet같은 접근이 아이디어의 가치에 비해 fakecatcher보다 저평가되는 주요한 요인 바로 deep learning의 연산 부하입니다. 단일 모델이 아닌 multi-stagers로서 학습 비용이 엄청나기 때문입니다.
연산 부하만 해결되는 날이 진정으로 AI가 도래하는 날이라고 저는 생각하고 있습니다. 그래서 사실 deep learning 연구원 못지 않게 반도체 업계 종사자분들도 중역을 맡고 계신 것 같습니다.
지난 포스트에서와 마찬가지로, deepfake detection 혹은 딥페이크 탐지라는 키워드로 검색을 하면 셀 수 없는 포스트와 영상이 쏟아져나오지만, principle(원리) 키워드만 붙여서 검색해도 자료의 수는 현저히 줄어듭니다.
Deepfake principle과 마찬가지로 deepfake detection principle (딥페이크 탐지 원리)를 분석한 한국어 자료는 논문이나 저널 아래의 레벨에서는 거의 찾지 못했습니다.
이 글이 deepfake에 관심이 있는 분께 좋은 공부자료가 되었으면 좋겠습니다. 또, deepfake의 악용 사례에 맞서는 정의감에도 불씨를 지폈으면 좋겠습니다 :)
코드를 제공하는 Try It! 파트는 생략하였습니다. 지난 글을 마지막으로 사실상 다시 완전한 전공자를 위한 포스트를 작성하기 시작했기 때문에, 여러분은 papers with code에서 SOTA 모델의 코드를 쉽게 사용해볼 수 있음을 아시리라 생각하기 때문입니다.
Outro
다음 포스트에서는 ViT 논문 자체를 자세하게 리뷰할지, 혹은 Transformer의 파생 계열인 Swin Transformer, Bert 등을 한 번에 설명할지 고민 중입니다.
또, 많은 분들이 chatGPT를 사용은 하면서 정확한 원리는 모르고 있어 이의 근본 모델인 GPT-3에 대한 포스트를 작성할까도 싶습니다.
혹시라도 이러한 주제에 대해서 의견이 있으신 분들은 편하게 댓글이나 개인 이메일 등으로 연락 부탁드립니다!
제가 작년 겨울에 진행했던 영어회화 스터디에서 한 분이 'AI가 인류의 위협이 되어가는데도 계속 개발하는 이유'에 대해서 여쭤보신 적이 있습니다. 저는 다른 여러가지 이유를 말하기 전에, '예술적이기 때문이다'라고 답했던 기억이 납니다.
Perceptron은 인간의 neuron으로부터 생체 모방 기술. 또 Seq2Seq과 같은 RNN으로부터 Transformer로의 대변혁의 역사, attention의 아이디어 등. 이 모든 것이 아름답다고 생각합니다. 이 포스트를 작성하게 된 것도, Transformer 하나가 여러 갈래로 변형되어 deepfake 분야에 기여하는 모습이 예술적이라 느꼈기 때문입니다 ෆ
다음은 제가 군 입대 2주일 전인 2021년 3월에 작성한 Movie Recommender System 포스트의 마지막 문구입니다.
블로그에 첫 포스트를 남겼을 때 했던 생각인데요,
"내가 5시간을 투자해서 쓴 글을 통해서 단 한 명이라도 4시간을 아낀다면 성공이다."
저 한 사람이 이 내용을 까먹은 미래의 저가 될 수도 있기 때문에, 결론적으로 모든 글은 '저'를 위한 저장소의 느낌입니다.
이제는 하나의 글을 쓰는 데에 수십 시간이 걸리지만, 이전보다 더 많은 분들이 도움을 받고 계시다는 점에서 뿌듯함을 느낍니다.
언제나 제 포스트를 끝까지 읽어주신 분들께 진심으로 감사드립니다. 좋은 하루 되세요! :)


안녕하세요 준영님, 비전공자지만 포스팅 재밌게 잘 읽었습니다. 전공에 대한 애정과 열정이 느껴져 자극 받고 갑니다. 늘 응원하겠습니다 :):)