[LLM] DeepSeek-R1 논문 분석 (DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning)
Paper
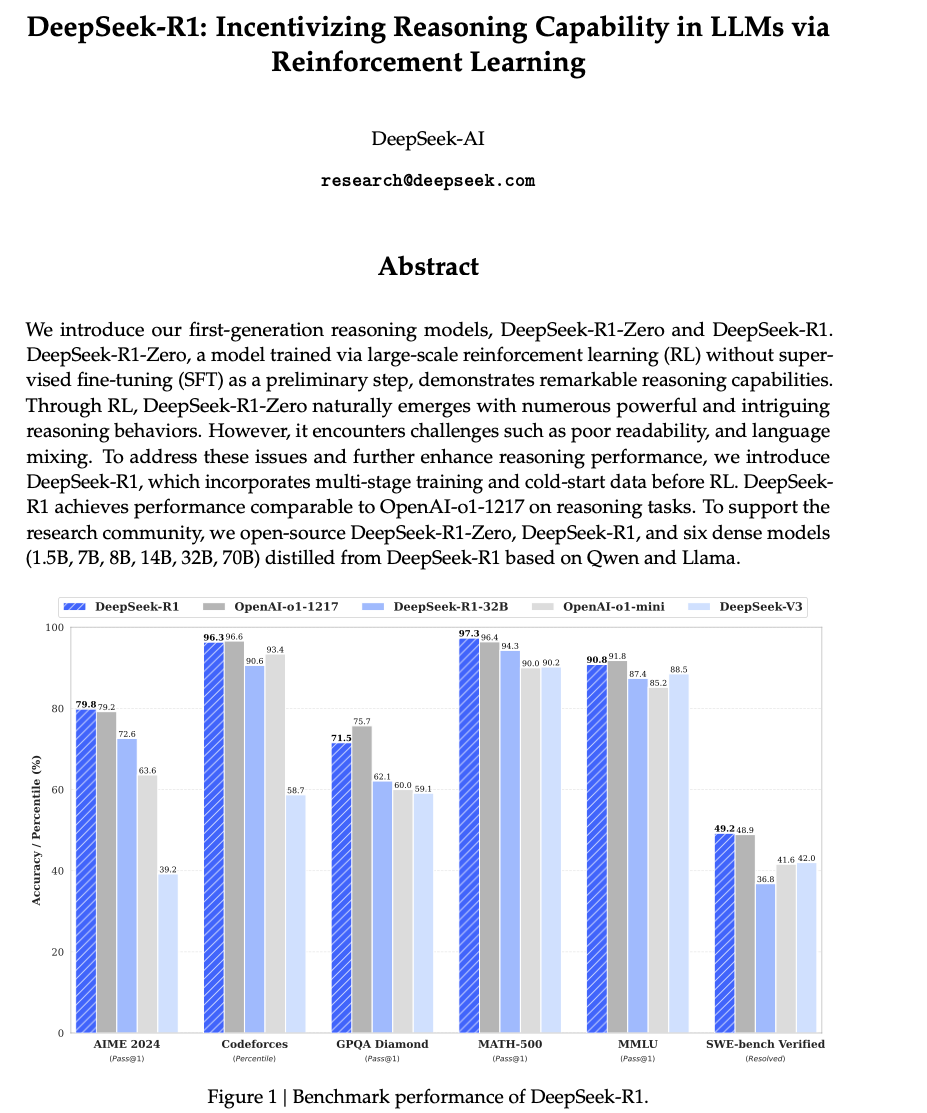
DeepSeek-R1 논문의 주요 논점 정리
- 순수 강화학습(RL) 기반 추론 모델 개발
- DeepSeek-R1-Zero는 초기 감독 학습(SFT) 없이 순수 강화학습을 통해 추론 능력을 습득한 첫 번째 모델
- 모델이 자체적으로 Chain of Thought (CoT) 패턴을 학습하여 문제 해결 능력을 발전시키는 과정을 관찰
- DeepSeek-R1의 다단계 학습 과정
- DeepSeek-R1은 RL 전에 "cold start data"를 활용하여 학습 초기의 불안정성을 해소
- 이후 강화학습과 감독 학습(SFT)을 조합한 다단계 학습으로 성능을 더욱 향상시킴
- 대형 모델의 추론 능력을 소형 모델로 증류(Distillation)
- DeepSeek-R1에서 추론 데이터를 생성하고 이를 Qwen 및 Llama 모델군에 적용하여 다양한 크기의 모델을 학습함
- 지식 증류된 14B 모델은 기존의 QwQ-32B보다 우수한 성능을 보이며, 32B 및 70B 모델은 오픈소스 밀집 모델 중 새로운 최고 성능을 기록
- 벤치마크 평가에서 OpenAI-o1-1217과 대등한 성능 달성
- DeepSeek-R1은 AIME 2024(79.8% Pass@1)와 MATH-500(97.3% Pass@1)에서 OpenAI-o1-1217과 유사한 성능을 보였다.
- 코드 컴퓨팅(Codeforces)에서는 96.3% 백분위수에 도달하는 등 강력한 코드 해석 및 수학적 추론 능력을 입증
- 강화학습과 증류의 비교 분석
- RL을 직접 적용한 Qwen-32B 모델(DeepSeek-R1-Zero-Qwen-32B)은 증류된 DeepSeek-R1-Distill-Qwen-32B보다 성능이 낮음
- 이를 통해 대형 모델에서 증류를 통해 소형 모델을 학습하는 것이 더 효과적일 수 있음을 보여즘
- 강화학습 적용 과정에서의 한계점 분석
- 프로세스 보상 모델(PRM), 몬테카를로 트리 탐색(MCTS)과 같은 방법론이 적용되었으나, 복잡한 토큰 생성 과정에서 기대만큼의 성능 향상을 보이지 못함
- 특히, PRM은 보상 해킹 문제와 높은 계산 비용이 문제가 되었고, MCTS는 검색 공간이 너무 크고 국소 최적화 문제에 빠지는 한계가 있음
DeepSeek-R1-Zero 방법론 (Approach)
- DeepSeek-R1의 접근 방식은 크게 네 가지 핵심 단계로 구성됨
[1] DeepSeek-R1-Zero : 순수 강화학습을 활용한 추론 능력 향상
[2] DeepSeek-R1 : 콜드 스타트 데이터(cold start data)를 활용한 다단계 학습
[3] Rejection Sampling (거부 샘플링)및 Supervised Fine-Tuning(SFT) 적용
[4] 추론 능력을 소형 모델에 증류 (Distillation)
[1] DeepSeek-R1-Zero : 순수 강화학습을 활용한 추론 능력 향상
- Supervised Fine-Tuning, SFT) 없이 순수 강화학습(Reinforcement Learning, RL)만으로 추론 능력을 발전시키는 것이 목표
- 기존에는 LLM을 학습할 때 보통 먼저 SFT를 한 후 RL을 적용했는데, 여기서는 RL을 바로 적용해서 모델이 자체적으로 추론 능력을 개발할 수 있는지 실험
(1) Group Relative Policy Optimization (GRPO)
- 기존의 RL 알고리즘보다 더 효율적으로 학습할 수 있도록 GRPO라는 최적화 기법을 사용
- 기존 방법(PPO)처럼 크리틱(critic) 모델을 사용하지 않고, 답변 그룹의 상대적 우수성을 평가하는 방식으로 보상을 계산
- 이렇게 하면 RL 비용을 절감하면서도 강력한 추론 성능을 확보
(2) 보상 함수 (Reward Model) 설계
- DeepSeek-R1-Zero에서는 두 가지 보상 기준을 설정 (1) 정확도 보상(Accuracy Reward)
-
수학 문제처럼 정답이 명확한 문제에서는 답이 맞으면 높은 보상을 주고, 틀리면 낮은 보상을 줌.
-
예를 들어, 코딩 문제에서는 테스트 케이스를 통과하는지를 확인하고 보상을 설정했어.
(2) 형식 보상(Format Reward)
-
모델이 생각 과정을 명확하게 표현하도록 유도하기 위해 특정 형식(CoT)을 따를 경우 보상을 부여.
-
예를 들어,
<think>추론 과정</think><answer>최종 답변</answer>형태로 출력을 하면 보상을 더 높여줌.
-
결과
- 초기에는 성능이 낮았지만, 학습이 진행되면서 모델이 자체적으로 "생각하는 방법"을 발전시키는 현상
- 특히, RL만으로 CoT 방식을 스스로 학습했다는 점이 흥미로운 결과
- 하지만, 문장 가독성이 떨어지고, 다국어 혼합 문제가 발생하는 단점
[2] DeepSeek-R1 : 콜드 스타트 데이터(cold start data)를 활용한 다단계 학습
- DeepSeek-R1-Zero의 문제점을 해결하고, 더 강력하고 읽기 쉬운 추론 모델을 만들기 위해 새로운 접근 방식을 도입
- 이 모델에서는 "콜드 스타트 데이터(cold start data)"를 활용해서 초기 학습을 안정화하는 방법을 사용.
(1) 콜드 스타트 (Cold Start) 단계 도입
- DeepSeek-R1-Zero의 초기 RL 과정이 불안정하다는 점을 개선하기 위해, 먼저 몇 천 개의 CoT 데이터를 학습시키고 시작
- 콜드 스타트 데이터는 다음과 같은 방식으로 수집
- 기존 LLM에게 긴 CoT 예제를 생성하도록 유도
- 사람이 직접 검토하여 읽기 쉬운 데이터를 선정
- DeepSeek-R1-Zero가 만든 CoT 중 읽기 좋은 것만 선별
- 후처리를 통해 불필요한 부분을 정리
- 이렇게 학습된 DeepSeek-V3-Base 모델을 초기 RL의 출발점으로 선정
(2) 언어 혼합(Language Mixing) 문제 해결
- RL 과정에서 모델이 여러 언어를 혼합해서 출력하는 문제 발생
- 이를 해결하기 위해 "언어 일관성(Language Consistency)" 보상 함수를 추가
- 특정 언어(예: 영어)로 응답하면 보상을 높이고, 여러 언어가 섞이면 보상을 낮추는 방식
(3) 1차 RL: 추론 능력 강화
- 콜드 스타트 데이터를 학습한 모델을 바탕으로, 다시 한 번 RL을 수행
- 이 과정에서 DeepSeek-R1-Zero와 같은 방식으로 보상을 적용하여 더욱 강력한 추론 모델을 만듦
[3] Rejection Sampling (거부 샘플링)및 Supervised Fine-Tuning(SFT) 적용
- RL 이후에도 모델이 완벽하지 않기 때문에, 거부 샘플링(Rejection Sampling)과 Supervised Fine-Tuning(SFT)을 추가해서 모델을 다듬음
(1) 거부 샘플링(Rejection Sampling)
- RL이 끝난 후, 모델이 생성한 다양한 답변 중에서 가장 좋은 답변을 선택하는 과정
- 예를 들어, 한 문제에 대해 모델이 10개의 답변을 만들었다면, 그중에서 가장 논리적이고 정확한 답을 선택해서 새로운 학습 데이터로 활용 → 이렇게 하면 모델이 더 좋은 답변을 생성하는 방향으로 발전
(2) Supervised Fine-Tuning(SFT)
- 거부 샘플링(Rejection Sampling)으로 만든 데이터를 바탕으로 모델을 다시 한 번 Supervised Fine-Tuning(SFT)진행
- 이 과정에서 추론뿐만 아니라 일반적인 질문응답, 문서 요약, 창작 등 다양한 태스크도 포함시켜서 모델을 다목적으로 사용할 수 있도록 만듦
[4] 추론 능력을 소형 모델에 증류(Distillation)
-
DeepSeek-R1의 강력한 추론 능력을 소형 모델에도 적용할 수 있도록 증류(distillation) 기법을 활용
-
기존의 대형 모델을 소형 모델로 변환할 때 성능이 급격히 떨어지는 문제가 있었는데 이 방법으로 해결하려고 함
-
Qwen2.5 및 Llama3 모델을 대상으로 DeepSeek-R1에서 생성한 80만 개의 학습 데이터를 활용하여 소형 모델을 학습시킴
-
소형 모델도 기본적인 추론 능력을 가질 수 있도록 CoT 학습을 강화함
-
14B 모델이 기존의 QwQ-32B 모델보다 더 나은 성능을 기록
-
32B, 70B 모델은 기존 오픈소스 모델 중 최고의 성능을 기록
: DeepSeek-R1의 학습 과정은 순수 RL → 콜드 스타트 데이터 추가 → RL + Supervised Fine-Tuning 결합 증류를 통한 소형화로 이어지는 체계적인 접근 방식이. 이를 통해 OpenAI-o1-1217과 대등한 성능을 갖춘 모델을 개발함. 이 접근 방식의 강점은 강화학습과 파인 튜닝한 지도 학습 모델의 장점을 모두 활용하면서, 모델을 효과적으로 발전시킴
논문의 뛰어난 점
- 순수 RL을 통한 모델 학습 가능성 입증
- 기존의 대부분의 LLM이 감독 학습을 필요로 했던 것과 달리, DeepSeek-R1-Zero는 RL만으로 강력한 추론 능력을 학습할 수 있음을 입증함
- 강화학습과 감독 학습을 조합한 다단계 학습 기법
- 단순한 RL을 넘어 콜드 스타트 데이터와 다단계 학습을 결합하여 더 안정적인 성능을 확보한 점
- 오픈소스 모델과의 성능 비교 및 증류 방법 제시
- 기존 오픈소스 모델(Qwen, Llama 등)과의 비교 분석을 통해 DeepSeek-R1이 실질적인 성능 향상을 제공함을 입증
- 특히, 증류 기법을 활용하여 소형 모델의 성능을 향상시키는 방법론을 제시
- 벤치마크 성능의 우수성
- 다양한 수학 및 코딩 벤치마크에서 OpenAI-o1-1217과 대등하거나 뛰어난 성능을 기록
- 특히, AIME 2024와 MATH-500에서 우수한 점수를 기록하며 강력한 추론 능력을 입증
논문의 부족한 점
- 비추론(Non-Reasoning) 작업에서의 성능 한계
- DeepSeek-R1은 추론 능력에서는 뛰어나지만, 대화형 AI에서 중요한 기능 호출(Function Calling), 다중 턴 대화(Multi-turn), JSON 출력 등의 작업에서 DeepSeek-V3보다 성능이 낮음
- 이러한 일반적 언어 모델 기능을 강화할 필요가 있음
- 언어 혼합(Language Mixing) 문제
- DeepSeek-R1은 중국어와 영어를 주요 학습 언어로 삼았으나, 다국어 지원이 부족하여 언어 혼합 문제가 발생할 수 있음
- 예를 들어, 비중국어·비영어 입력을 받았을 때, 영어로 응답할 가능성이 큼
- 프롬프트 민감성
- DeepSeek-R1은 프롬프트 구성에 따라 성능 변동이 크며, 특히 Few-shot 프롬프트에서 성능이 감소하는 경향이 있음
- 보다 강건한 프롬프트 엔지니어링 기법을 연구할 필요가 있음
- 소프트웨어 엔지니어링 관련 성능 개선 필요
- 코드 해석과 수학 문제 해결 능력은 뛰어나지만, 실제 소프트웨어 엔지니어링 문제에서는 OpenAI-o1-1217 대비 부족한 성능을 보임
- 이는 RL 과정에서 소프트웨어 엔지니어링 데이터를 충분히 반영하지 않았기 때문이며, 향후 개선이 필요
후속 연구 제안
- 비추론 작업에서의 성능 향상 연구
- 기능 호출, 대화 흐름 관리, JSON 출력과 같은 태스크에서 DeepSeek-R1의 성능을 개선할 필요
- 이를 위해 RL 과정에서 비추론 태스크를 강화하거나, 다중 목적 최적화(Multi-objective Optimization)를 고려
- 다국어 지원 강화
- 현재 DeepSeek-R1은 영어와 중국어에 최적화되어 있어, 다른 언어에서도 균형 잡힌 성능을 내도록 학습 데이터와 보상 모델을 조정할 필요
- 프롬프트 엔지니어링 연구
- DeepSeek-R1의 프롬프트 민감성을 줄이기 위해 보다 정교한 프롬프트 엔지니어링 기법을 도입할 필요성
- Few-shot 환경에서도 성능이 유지되도록 적응형 학습 기법 연구의 필요성
- 소프트웨어 엔지니어링 성능 개선
- RL 학습 데이터에 더 많은 소프트웨어 개발 관련 태스크를 포함하여 실제 개발 환경에서의 성능을 개선할 필요가 있음
- 코드 생성 및 수정 태스크에서 RL을 효과적으로 적용하는 방법을 연구할 수 있음
- 강화학습과 증류의 결합 최적화
- RL과 증류를 조합하는 최적의 방법론을 연구하여, 더 작은 모델에서도 강력한 성능을 발휘할 수 있도록 개선할 필요가 있음
- 예를 들어, RL 과정에서 생성된 데이터를 활용한 하이브리드 증류 모델을 개발할 수 있음
