PyCaret은 AutoML을 해주는 파이썬 라이브러리로, scikit-learn 패키지를 기반으로 하고 있다.
1) 데이터셋 준비: setup()
2) 모델 성능 비교 및 모델 생성: compare_models(),create_model()
3) 모델 튜닝 및 블랜딩: tune_model(),blend_models()
4) 예측: predict_model()
5) 평가: check_metric()
1) 데이터셋 준비
from pycaret.utils import check_metric
from pycaret.datasets import get_data
from pycaret.classification import *
from pycaret.regression import *
reg_lunch=setup(data=df,target='중식계',train_size=0.8,imputation_type='simple',
data_split_shuffle=False,session_id=1414,fold_strategy='kfold',
fold=10,fold_shuffle=False,verbose=True,silent= True)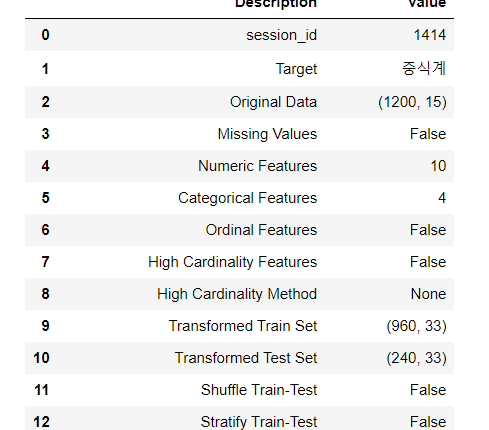
#모델 확인
models()
2) 모델성능 비교
top3_model=compare_models(sort='MAE',n_select=3,round=4,cross_validation=True,verbose=True,errors='ignore')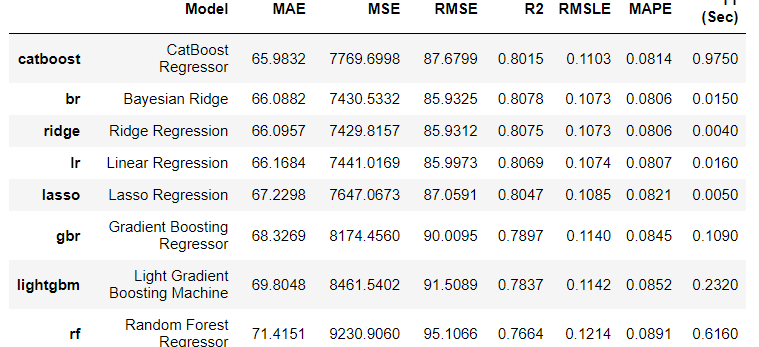
3) 모델 생성
rf_model=create_model('rf',fold=5)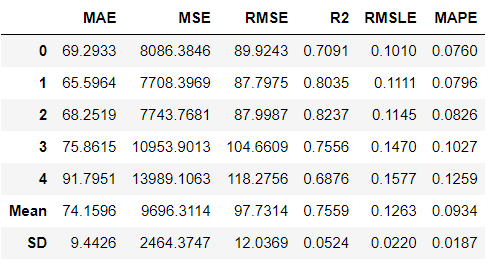
4) 모델 튜닝, blending
tuned_top3_model=[tune_model(i) for i in top3_model]
ens_model=blend_models(estimator_list= tuned_top3_model, fold=5, optimize='MAE',round= 4,verbose=True)5) 모델 학습 및 예측
# 모델 최종 확정, 전체 데이터 학습
final_model = finalize_model(ens_model)
#predict(X_val) 0.2
pred_holdout = predict_model(ens_model)
#test셋 predict
pred= predict_model(final_model, data=test_lunch) 6) 모델 평가
check_metric(pred_holdout['중식계'], pred_holdout['Label'], metric='MAE')* 평가결과 시각화
plot_model(rf_model)
plot_model(rf_model,plot = 'error')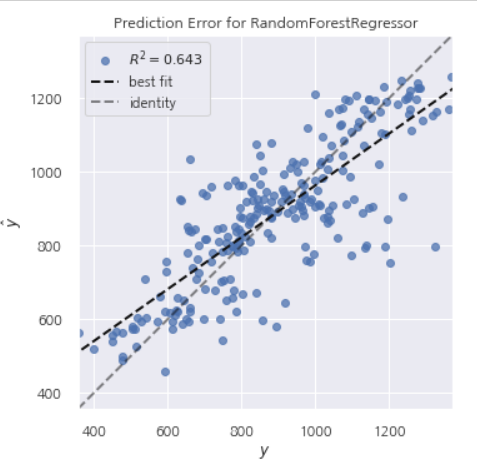
plot_model(rf_model, plot='feature')
