불균형 데이터(Imbalanced data processing)
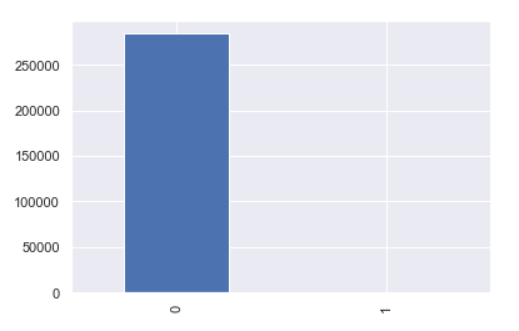
위와 같이, 데이터에서 각 클래스가 갖고 있는 데이터의 양에 차이가 큰 경우를 말한다. 신용사기 검출의 경우, 정상 거래인 경우가 비정상 거래보다 훨씬 많은 것이다. 클래스 불균형 데이터를 이용해 분류 모델을 학습하면 분류 성능이 저하되는 문제가 발생한다.
이때 데이터 클래스의 균형을 맞추기 샘플링 기법들을 사용한다.
1. 언더 샘플링(Under sampling)
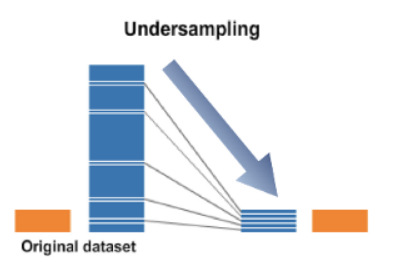
: 다수 범주의 데이터를 소수 범주의 데이터 수에 맞게 샘플링하는 것이다. (다수의 데이터를 줄이는 방법)
NearMiss
from imblearn.under_sampling import NearMiss
nearmiss=NearMiss()
under_X,under_y = nearmiss.fit_resample(X,y)under sampling을 할 경우, 일반적으로 recall값이 낮아지기 때문에 over sampling을 주로 사용한다.
2. 오버 샘플링(Over sampling)
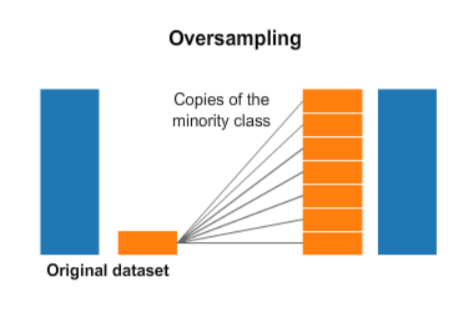
: 소수 범주의 데이터를 다수 범주의 데이터 수에 맞게 늘리는 방식이다.
SMOTE
소수 데이터의 sample에 KNN을 적용 후, 샘플과 이웃간의 사이에 random하게 데이터 생성한다.
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
over_x,over_y = smote.fit_resample(X,y)이상치 제거
전체 프레임 대상이 아니라, 주요 feature 대상으로 진행한다.
1) boxplot 만들기, 이상치 확인
plt.figure(figsize=(10,10))
sns.boxplot(x=X["V11"])
plt.show()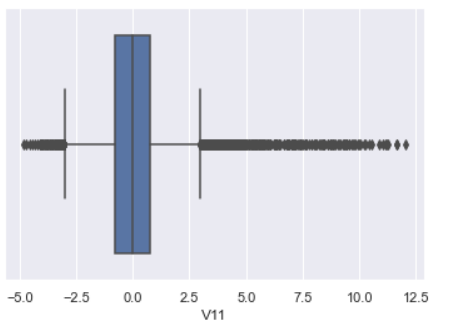
2) 이상치 제거
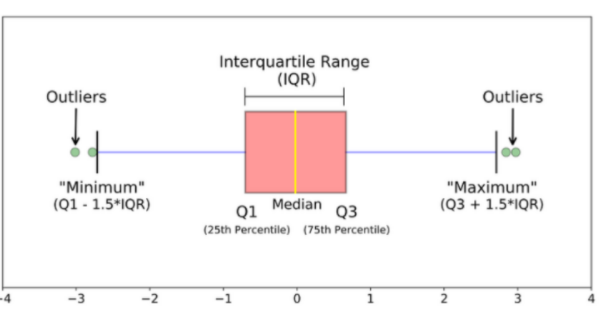
import numpy as np
#25%에 위치한 값 구하기
q1 = X["V11"].quantile(q=0.25)
#75%에 위치한 값 구하기
q3 = X["V11"].quantile(q=0.75)
#IQR구하기
IQR = q3-q1
#quantile_25보다 1.5 * IQR 작은 값 구하기
min = q1-(1.5*IQR)
#quantile_75보다 1.5 * IQR 큰 값 구하기
max = q3+(1.5*IQR)
# min보다 작거나 같고, max보다 크거나 같은 값들만 추출한 후 drop
drop_idx = X[(X["V11"]<min) | (X["V11"]>=max)]["V11"].index.to_list()
X["V11"].drop(drop_idx,axis=0,inplace=True)
-- 아예 min보다 크거나 같고, max보다 작거나 같은 값만 추출 가능
#이상치 개수 세기
train.shape[0]-drop_idx.shape[0]