교차검증
: Test test를 평가하기 전에, Training set와 Test set에서 알고리즘을 학습하고 평가하는 것이다. 즉 train과 test를 8:2 혹은 7:3으로 분할해서 70~80% 데이터만 학습하는 것이 아닌, 모든 데이터를 최소한 한 번씩 다 학습하자는 것이다. (학습데이터 증강)
또한 과적합(overfitting)을 막기 위해 교차검증을 한다.
*과적합의 문제
-Training set을 가장 잘 맞히는 머신은 Test set에서는 잘 동작하지 않을 수 있다.
-Training error는 error를 과소추정하는 성향이 있다.
1. k-겹 교차 검증 (K-Fold Cross Validation)
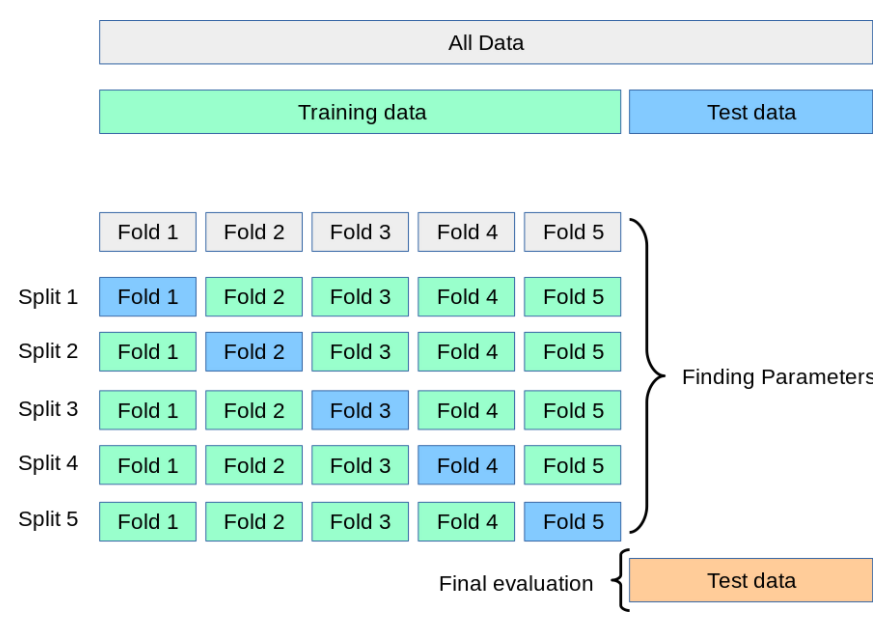
일반적으로 사용되는 교차 검증 방법 중 하나로, Training set과 Validation을 여러번 나눈 뒤 모델의 학습을 검증한다.
보통 회귀 모델에 사용되고, 데이터가 독립적이고 동일한 분포를 가질 때 사용한다. 위 그림에서는 데이터를 K등분(5등분)한 뒤, 1/5를 검증데이터로 나머지 4/5를 학습데이터로 나누다. 각각의 1/5를 검증데이터로 바꾸며 성능을 평가한다. 그 결과 총 5개의 성능 결과가 나올 것이고 5개의 평균을 학습 모델의 성능이라 판단한다.
from sklearn.model_selection import KFold
# 앞에서 모델 구축한 후 진행
# train_test_split하지 않고 train set 전체 사용
#폴드 세트 설정
kfold = KFold(n_splits=5) #5개로 split, 임의로 정할 수 있음
#for문에서 train과 test데이터의 인덱스 추출
f1_list = []
for train_index,test_index in kfold.split(X,y) #y를 안넣어도 됨
X_train,X_test = X.iloc[train_index],X.iloc[test_index]
y_train,y_test = y.iloc[train_index],y.iloc[test_index]
#학습과 예측 수행 후 성능 반환
model.fit(X_train,y_train)
pred = model.predict(X_test)
f1 = f1_score(y_test,pred,average='macro') #f1 score
f1_list.append(f1)
print(f" f1 평균점수 : {np.array(f1_list).mean():.4f}") 2. 계층별 k-겹 교차 검증 (Stratified k-fold cross validation)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
이 경우, 데이터셋을 나열 순서대로 k개의 폴드로 나누는 것은 항상 좋지만은 않으므로 계층별 k-겹 교차검증을 활용한다. 즉 k-겹 교차검증은 k-fold가 원본 데이터 집합의 레이블 분포를 학습 및 검증 데이터 세트에 제대로 분배하지 못하는 문제를 해결하며, target에 속성값의 개수를 골고루 넣는다. Stratified k-fold는 분류 모델에 적용된다.

90%가 클래스 A, 10%가 클래스 B인 데이터라면 계층별 교차 검증은 각 폴드에 9:1 비율대로 만든다.
from sklearn.model_selection import StratifiedKFold
# 앞에서 모델 구축한 후 진행
# train_test_split하지 않고 train set 전체 사용
#폴드 세트 설정
skfold = StratifiedKFold(n_splits=5)
#for문에서 train과 test데이터의 인덱스 추출
f1_list = []
for train_index,test_index in skfold(X,y)
X_train,X_test = X.iloc[train_index],X.iloc[test_index]
y_train,y_test= y.iloc[train_index],y.iloc[test_index]
#학습과 예측 수행 후 성능 반환
model.fit(X_train,y_train)
pred=model.predict(X_test)
f1 = f1_score(y_test,pred,average='macro')
fl_list.append(f1)
print(f" f1 평균점수 : {np.array(f1_list).mean():.4f}") 3. cross_val_score( )
사이킷런에서는 교차 검증을 쉽게 수행할 수 있는 API인 cross_val_score( )를 제공한다.
- 주요 파라미터

estimator: 모델 / X: feature data set / y: label data set / scoring : 예측 성능 평가 지표 / CV : 교차 검증 fold 수
from sklearn.model_selection import cross_val_score
# 앞에서 모델 구축한 후 진행
# train_test_split하지 않고 train set 전체 사용
X= train[train.columns.difference(['credit'])
y= train['credit']
arr_score = cross_val_score(model,X,y,scoring='f1_macro',cv=5)
print(f'cv5 평균점수 : {arr_score.mean():.4f}")4. GridSearchCV( )
: 교차검증과 하이퍼 파라미터 튜닝을 동시에 할 수 있다. 하이퍼 파라미터를 순차적으로 입력해 학습하고, 측정하면서 가장 좋은 파라미터를 알려준다. 즉 매개변수 튜닝을 통해 모델의 성능을 높인다.
- 주요 파라미터

estimator: 모델 / param_grid: 튜닝을 위한 파라미터, 파라미터를 dictionary형태로 만들어서 넣음 / scoring : 예측 성능 평가 지표 / refit: 디폴트 True, 최적의 하이퍼 파라미터를 찾아서 재학습 / CV : 교차 검증 fold 수
X= train[train.columns.difference(['credit'])]
y= train['credit']
# random_state 인자는 수행시마다 동일한 결과를 얻기 위해 적용
X_train,X_test, y_train, y_test=train_test_split(X,y,test_size =0.2, random_state=42)
model = RandomForestClassifier(n_estimators=10,random_state=42)
from sklearn.model_selection import GridSearchCV
# gridsearch가 찾을 파라미터 정의
# n_estimators: 반복 수행하는 트리의 개수
# min_samples_split: 노드를 분할하기 위한 최소한의 샘플 데이터 수
myparam = {'n_estimators': [10,20], 'min_samples_split':[1,2,3,4]}
gcv_model = GridSearchCV(model,param_grid=myparam,scoring='f1_macro',refit=True, cv=5)
gcv_model.fit(X_train,y_train)
print(gcv_model.best_score_) #학습된 데이터들 중 best score
print(gcv_model.best_params_) #학습된 데이터들 중 best_params
#print(gcv_model.cv_results_) #학습된 데이터들 중 cv_results#gridsearchCV를 이용해 최적으로 학습된 estimator로 예측 수행
pred=gcv_model.best_estimator_.predict(X_test)
f1=f1_score(y_test,pred,average='macro')
print(f1)