<모든 데이터를 수치형으로 변환해주는 전처리 작업>
특히, object형을 대상으로 한다.
1. Label Encoding
: n개의 범주형 데이터를 0부터 n-1까지의 연속적 수치 데이터로 표현하는 것이다. 인코딩 결과가 수치적인 차이를 의미하진 않는다.
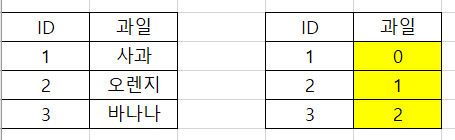
위와 같이 레이블 인코딩은 문자열 값을 숫자형 카테고리 값으로 변환해주는 것이다. 한편, 이를 ML알고리즘에 적용할 경우 예측 성능이 떨어지는 경우가 있어 선형 회귀 등의 알고리즘에는 적용하지 않는다. (트리 계열의 알고리즘은 괜찮음)
예시
from sklearn.preprocessing import LabelEncoder
item_label = ['b','a','c','d','a','b']
encoder = LabelEncoder() #labelencoder함수를 가져온다.
encoder.fit(item_label) #내가 가지고 있는 데이터에 학습시킨다
digit_label = encoder.transform(item_label) # transform으로 변환한다
print(encoder.classes_) #unique하게 바꿀 대상을 컴퓨터가 선별한다
print(digit_label) # 글자 >숫자 인코딩
print("*"*40)
print(encoder.inverse_transform(digit_label)) #변환했던 것을 다시 변환.(문자로)🔶 label encoding을 여러 개의 컬럼에 적용시킬 때는 for문을 사용한다.
label = ['Sex', 'Cabin', 'Embarked']
for i in label:
encoder = LabelEncoder()
encoder.fit(train2[i])
train2[i]= encoder.transform(train2[i])
train22. One-Hot Encoding
One-Hot Encoding은 말 그대로, 하나만 Hot 하고, 나머지는 Cold한 데이터이다.
새로운 컬럼을 추가해, 고유값에 해당하는 컬럼에만 1을 표시하고 나머지 컬럼에는 0을 표시한다.

🔶변환하기 전, 모든 데이터는 숫자로 구성되어 있어야 하며 null값이 없어야 한다. 또한 입력값은 2차원 이상이어야 한다. (reshape으로 조정!)
from sklearn.preprocessing import OneHotEncoder
item_label = ['b','a','c','d','a','b']
item_label = np.array(item_label).reshape(-1,1) #np.reshape(item_label,(-1,1))도 가능
encoder = OneHotEncoder()
encoder.fit(item_label) #내가 가지고 있는 데이터에 학습시킨다
digit_label = encoder.transform(item_label) # transform으로 변환한다Pandas에도 One-Hot Encoding을 할 수 있는 함수, get_dummies( )가 있다. 이는 sklearn의 One-Hot Encoding보다 코드가 쉬우므로 get_dummies( )를 추천한다.
3. pd.get_dummies( )
#music_genre 컬럼에 대해서만 one-hot encoding 수행한다
df=pd.get_dummies(df,columns=['music_genre']) 위 코드를 실행하면 다음과 같다.
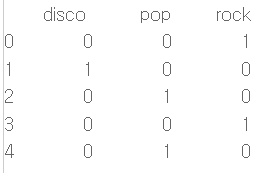
결측값을 제외하고 0과 1로 구성된 더미값이 만들어진다. dummy_na = True 옵션을 추가하면 결측값도 인코딩하여 처리한다.
pd.get_dummies는 컬럼이 무수히 늘어나기 때문에, 모델링 직전에 해주면 가공할 때 컬럼을 보기에 편하다.
