- 데이터 결합
- 2개 이상의 data set을 결합하여 한 개의 data set으로 만드는 과정
- 세로 결합과 가로 결합 형태가 있다.
- 세로 결합 : data set의 변수가 동일 할 경우 사용
- 가로 결합 : 공통된 변수를 두고 결합 할 경우 사용
- 세로 결합
- https://github.com/newstars/HelloR/blob/master/Data/Sample2_m_history.xlsx
- https://github.com/newstars/HelloR/blob/master/Data/Sample3_f_history.xlsx
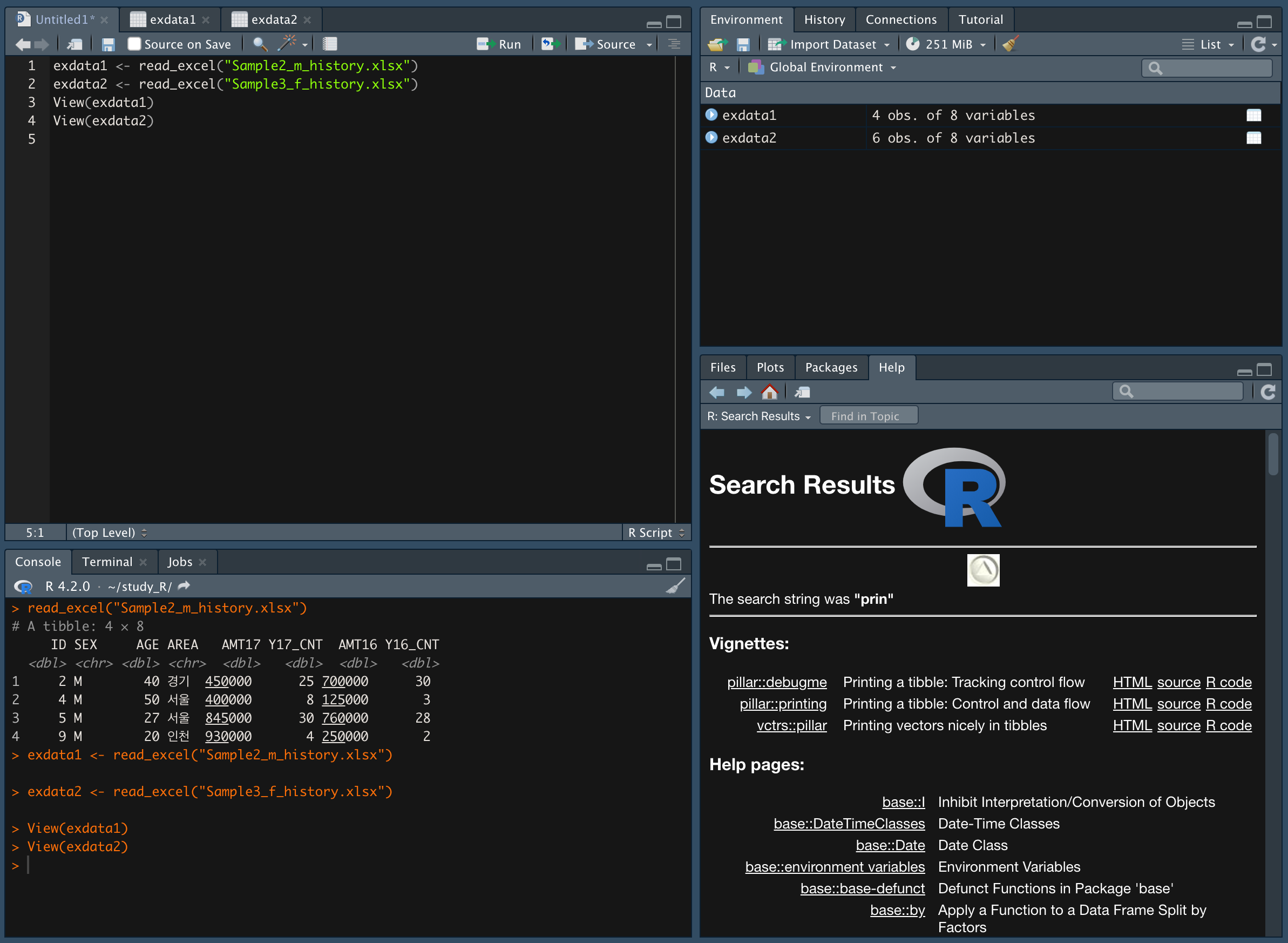
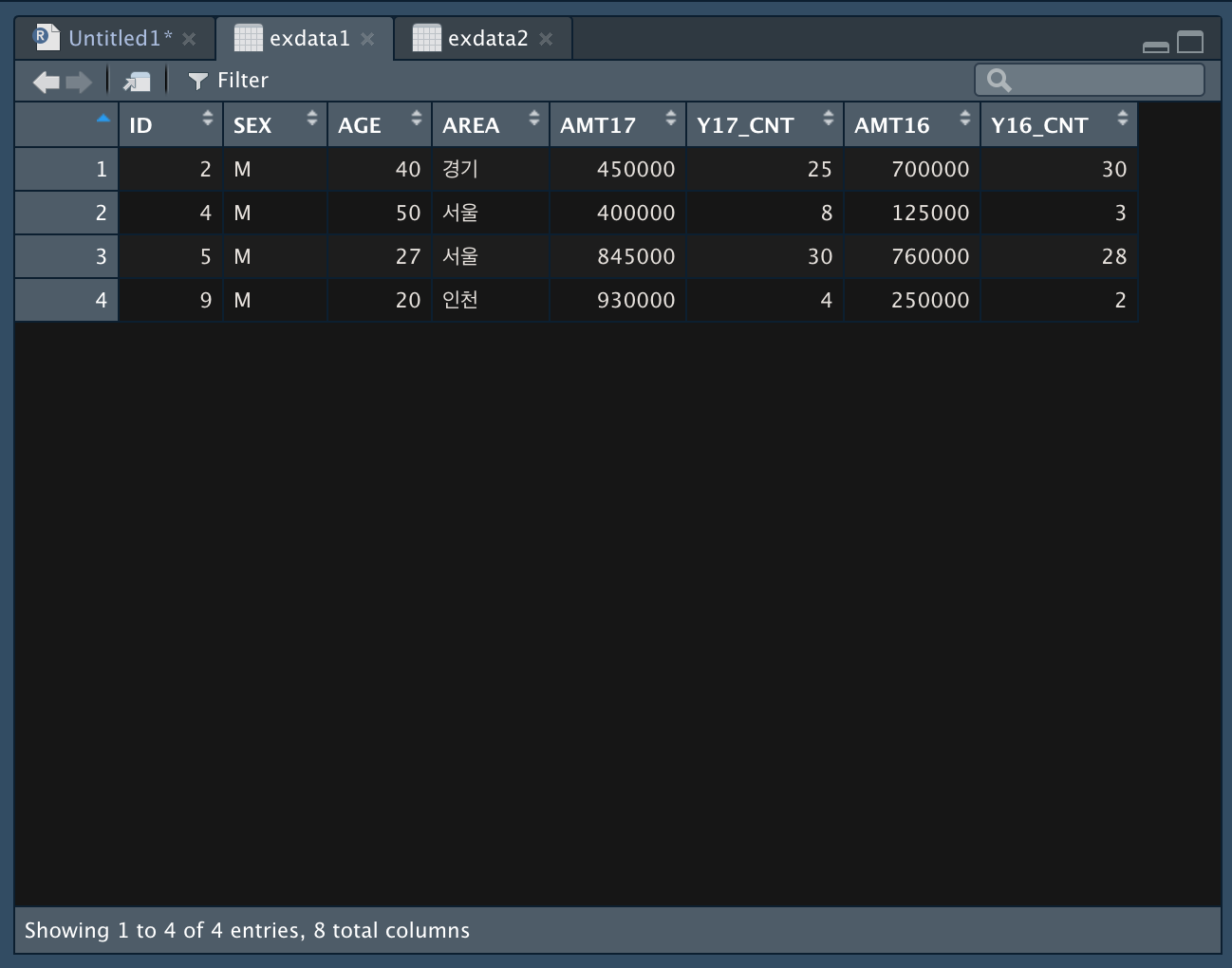
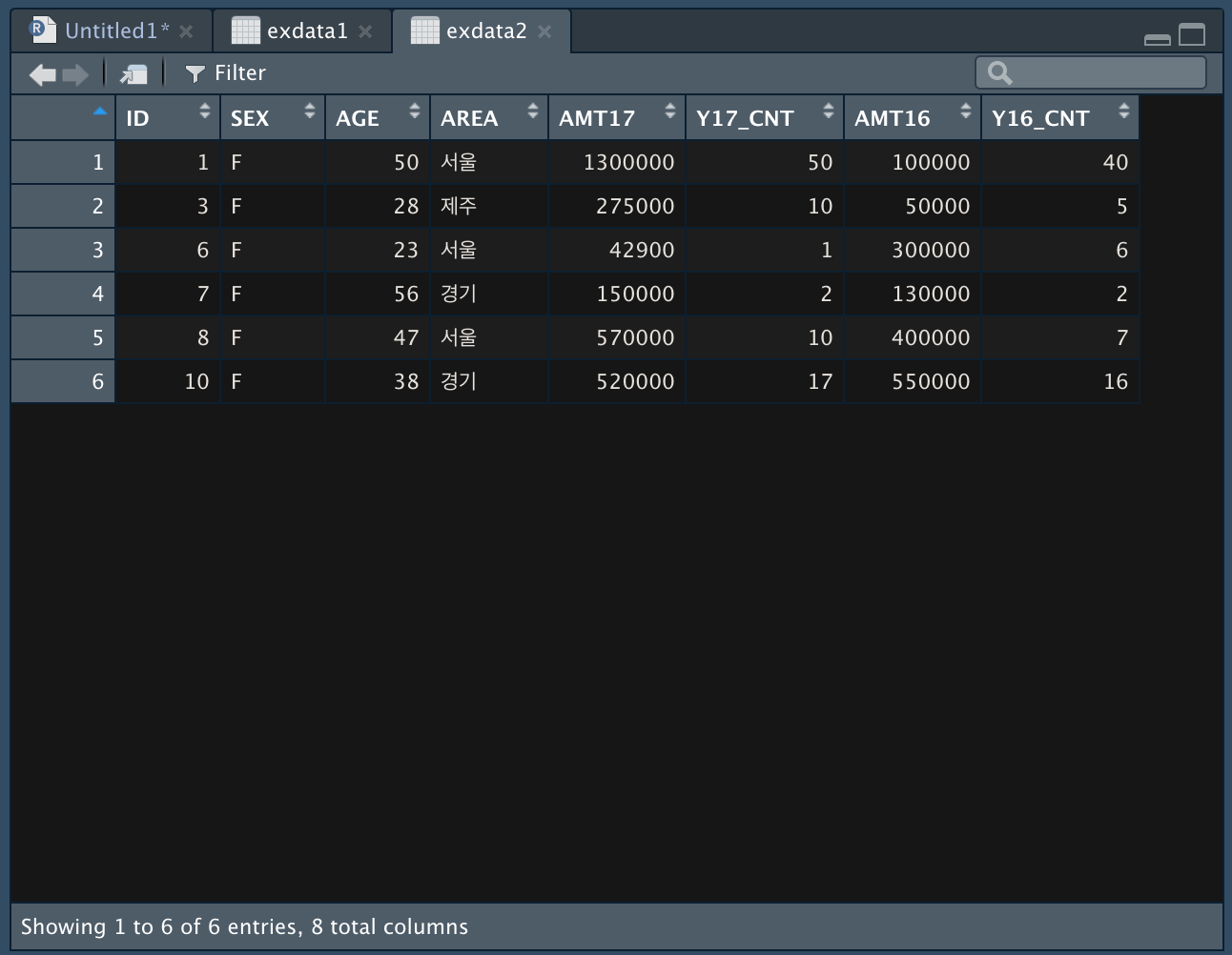
두 개의 자료를 받아서 실습한다.
-
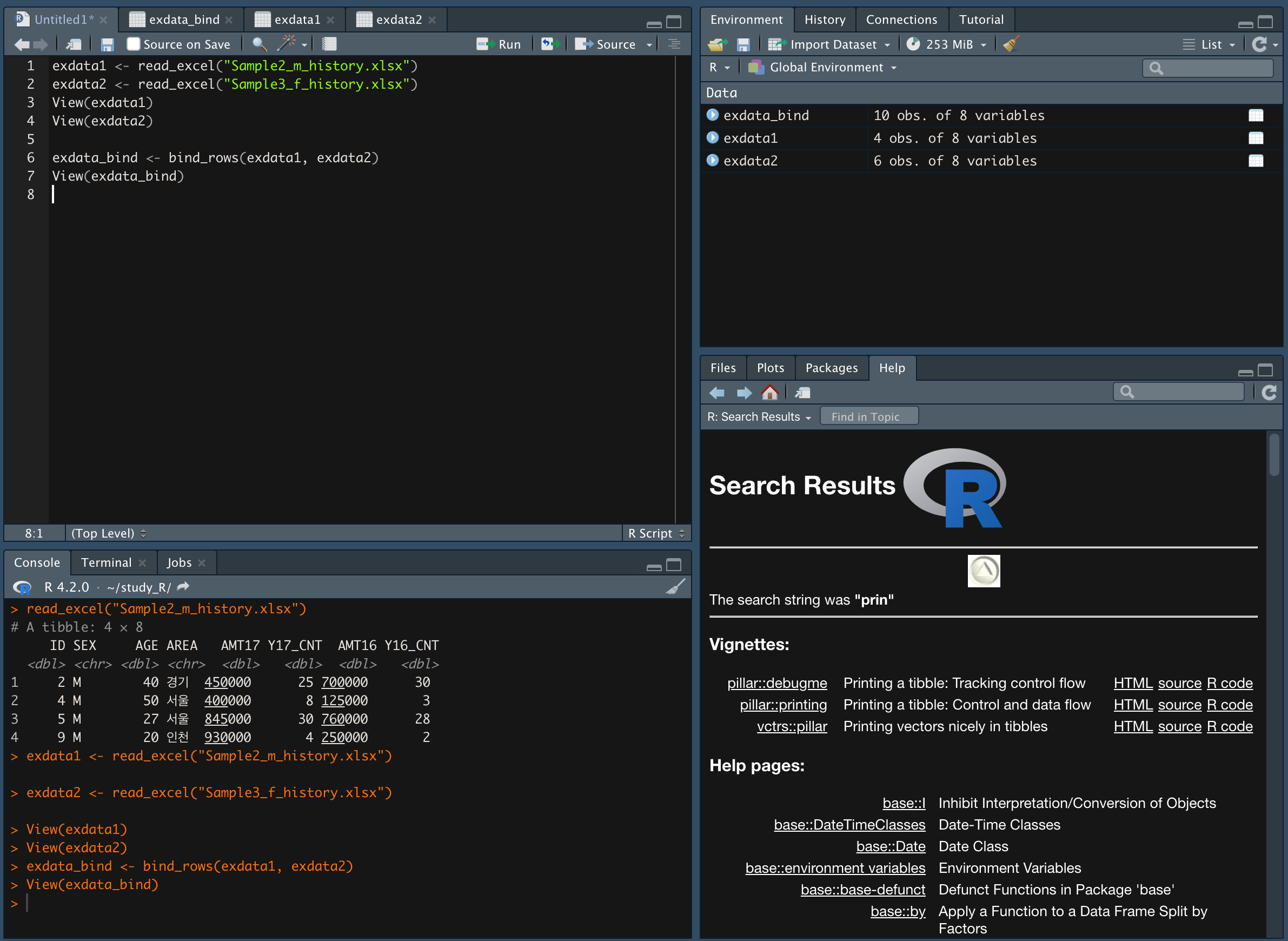
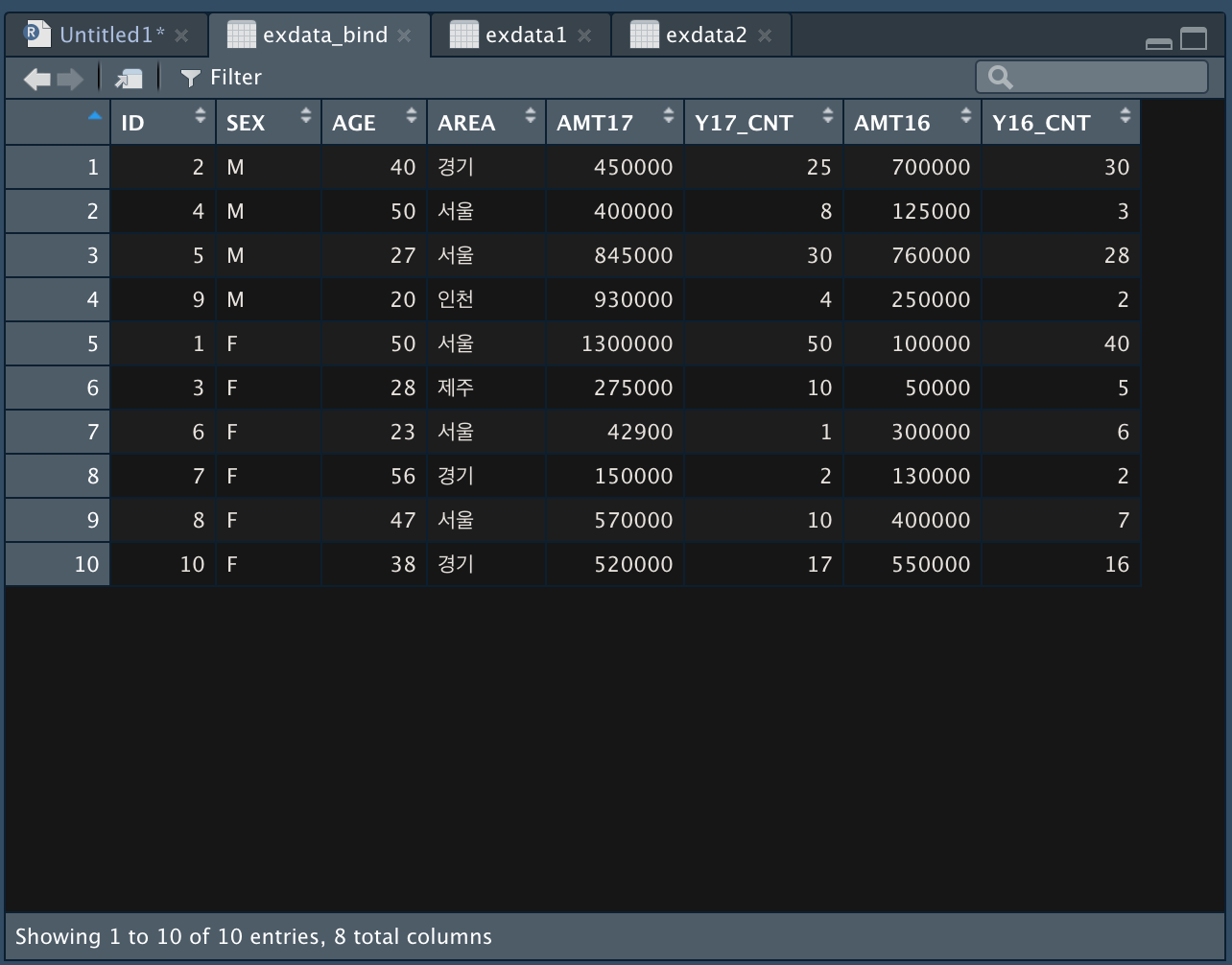
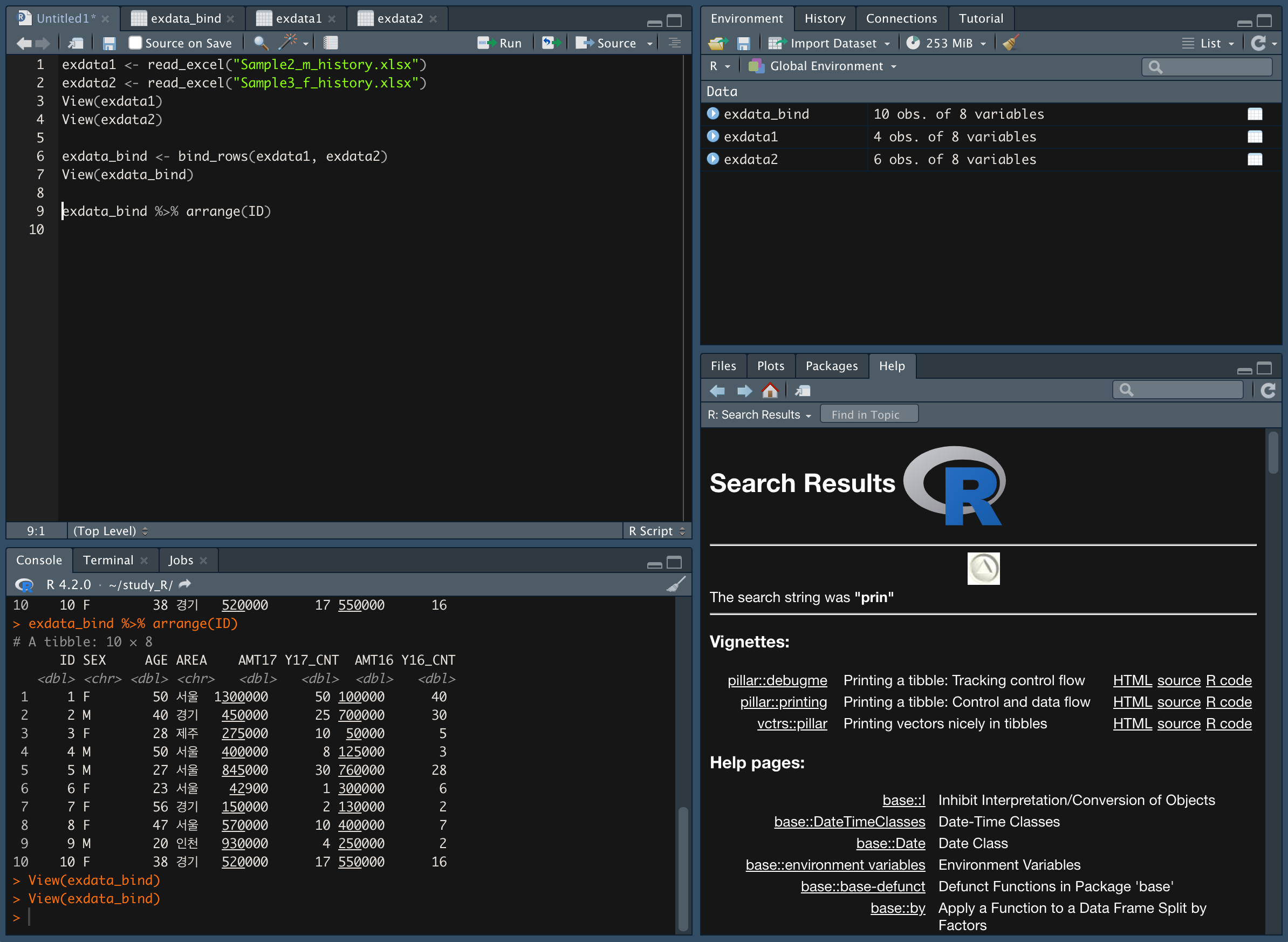
bind_rows() 함수를 이용한다.
-
exdata_bind %>% arrange(ID) 를 이용해 ID 항목을 기준으로 오름차순 배열한다.
- 가로 결합

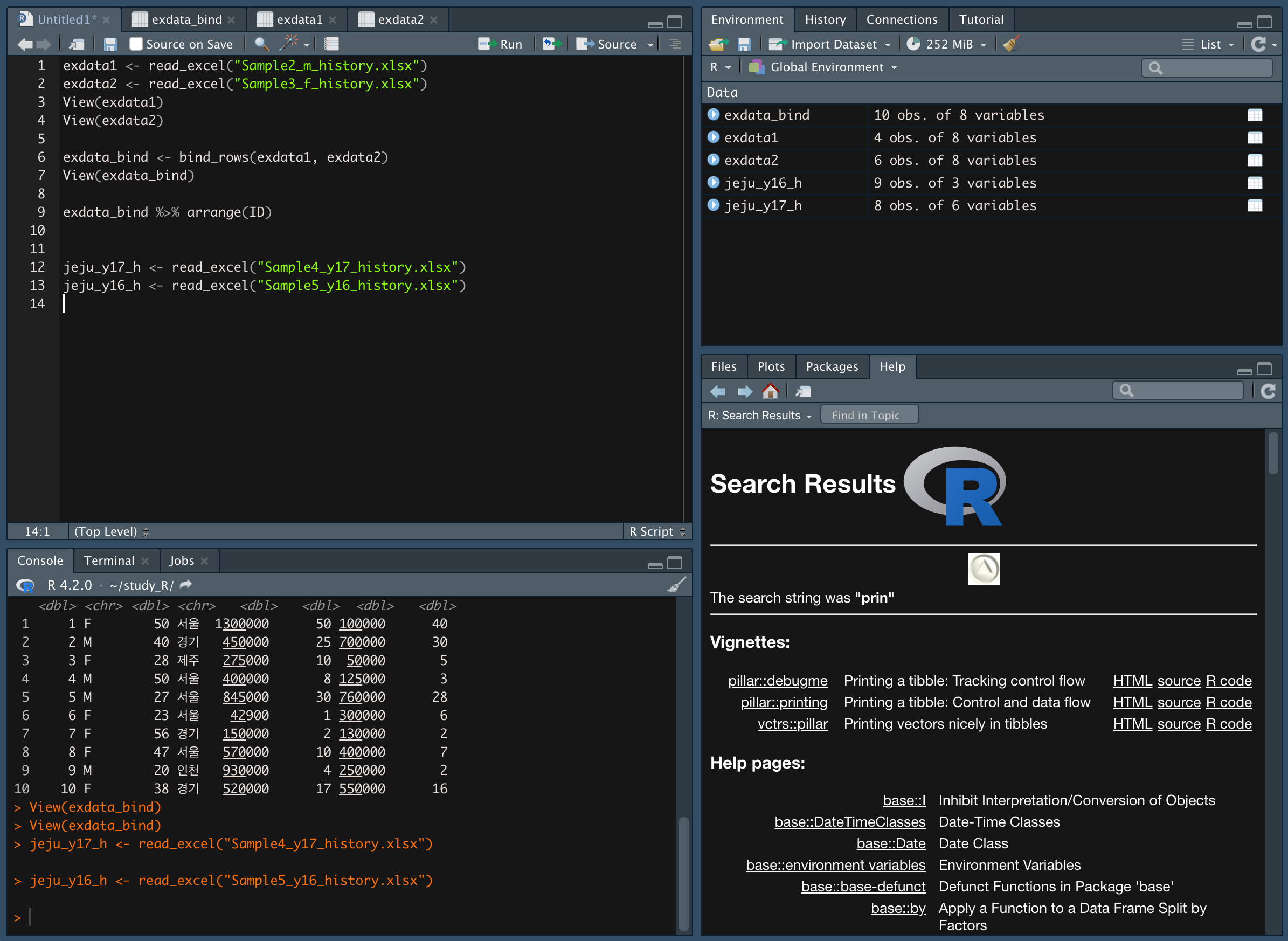
- https://github.com/newstars/HelloR/blob/master/Data/Sample4_y17_history.xlsx
- https://github.com/newstars/HelloR/blob/master/Data/Sample5_y16_history.xlsx
두 개의 자료를 받아서 실습한다.
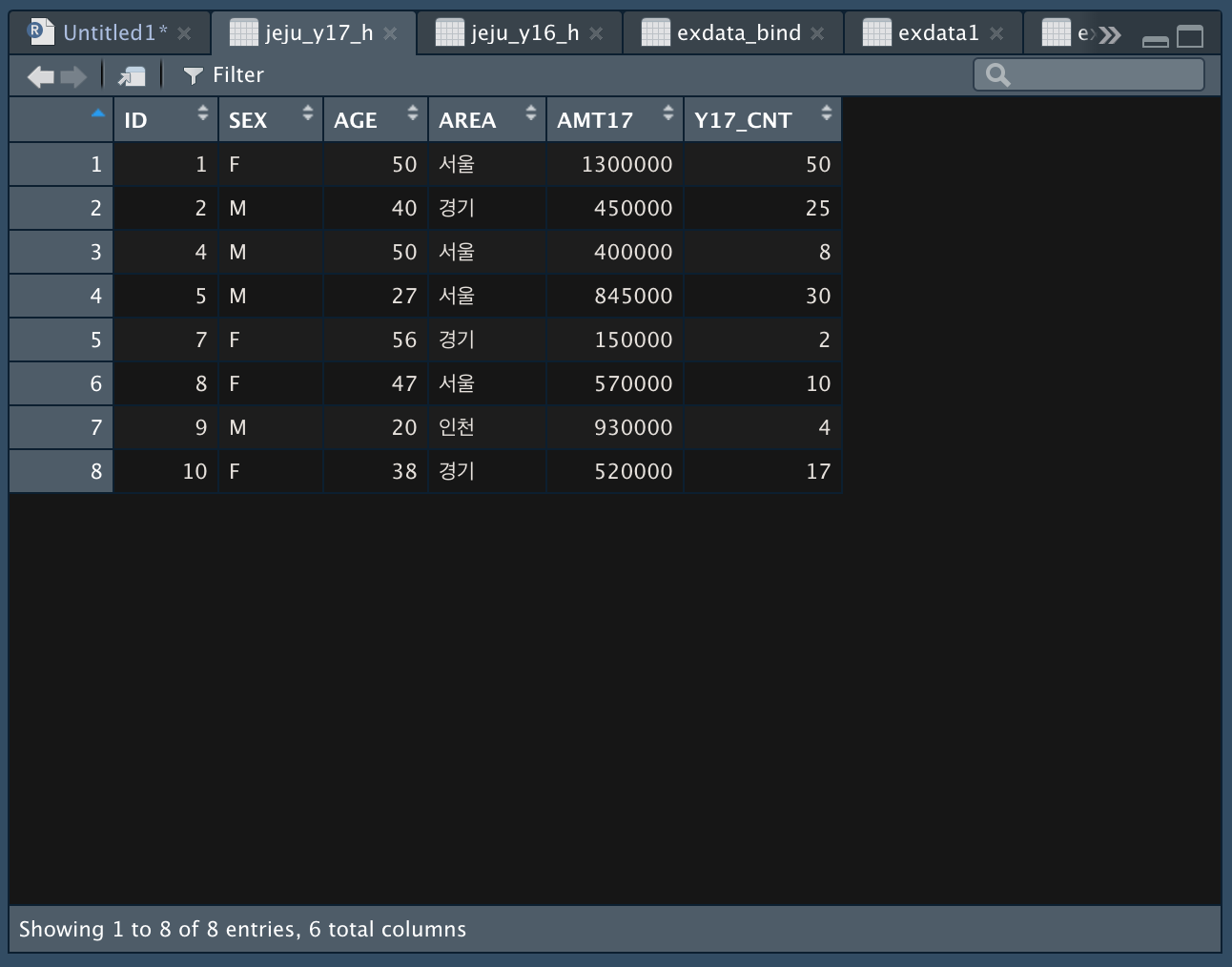
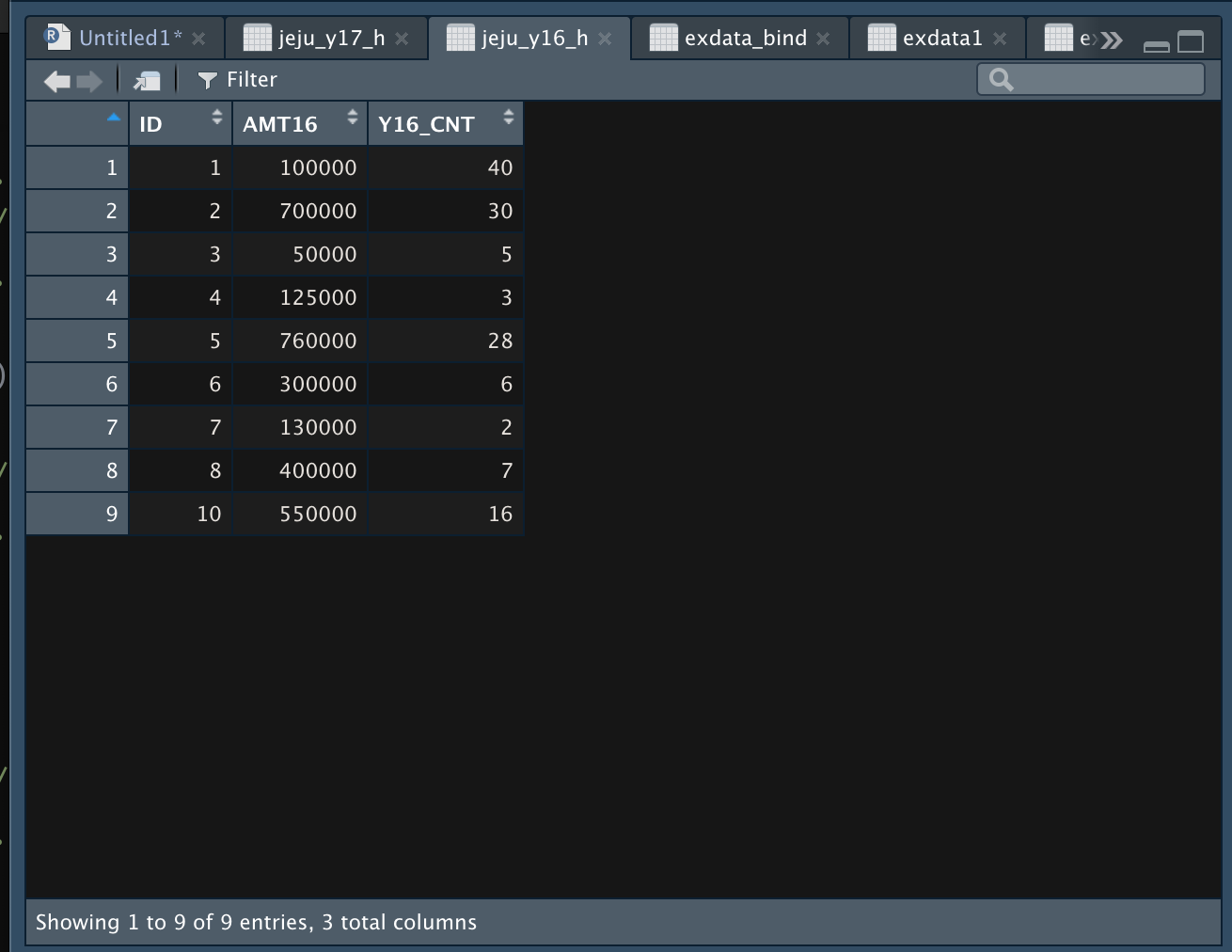
- 3번, 6번 아이디가 비어 있다.
- 9번 아이디가 비어있다.
- left_join()
*dplyr packages 사용
-
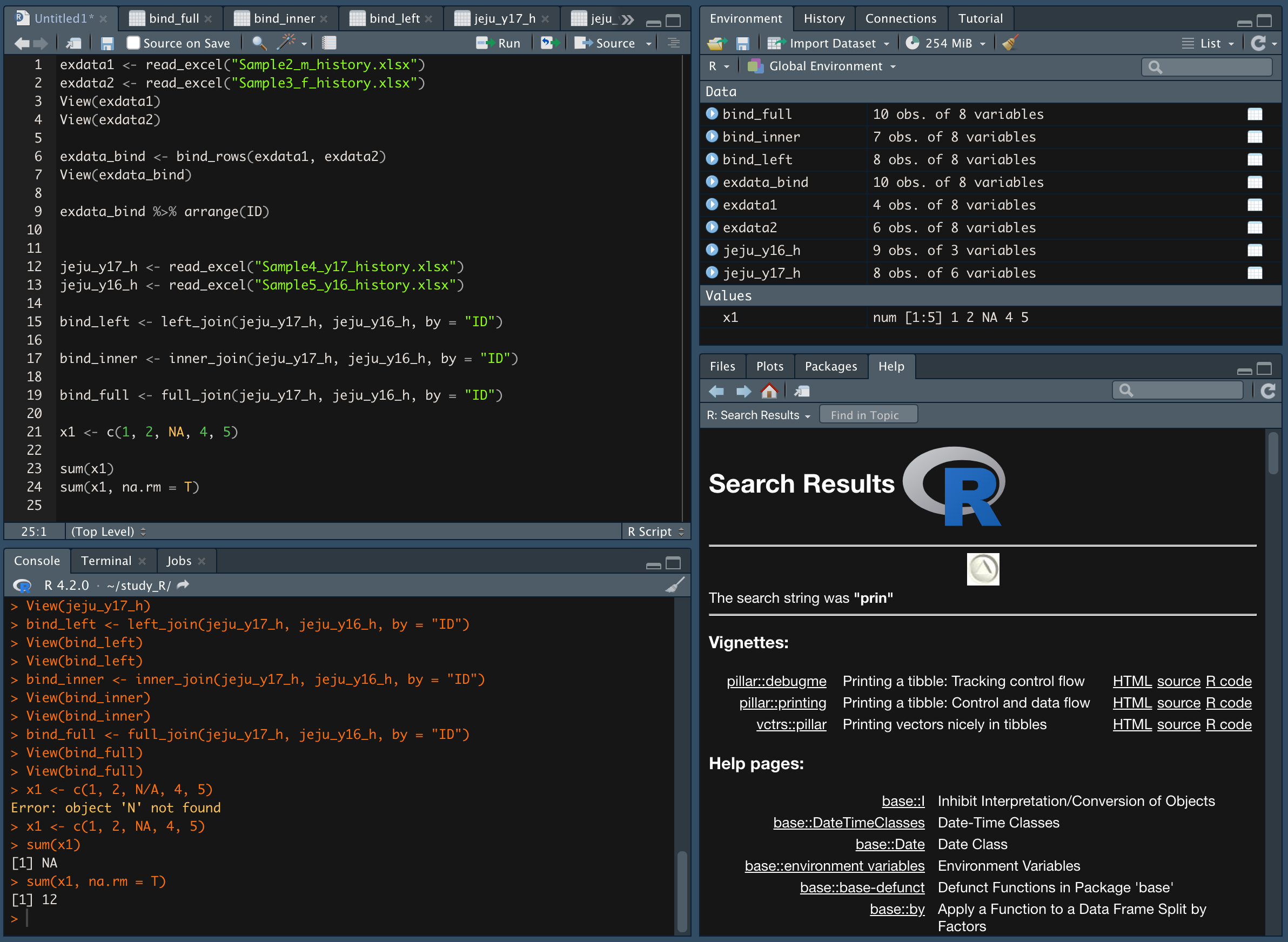
bind_left <- left_join(jeju_y17_h, jeju_y16_h, by = "ID")
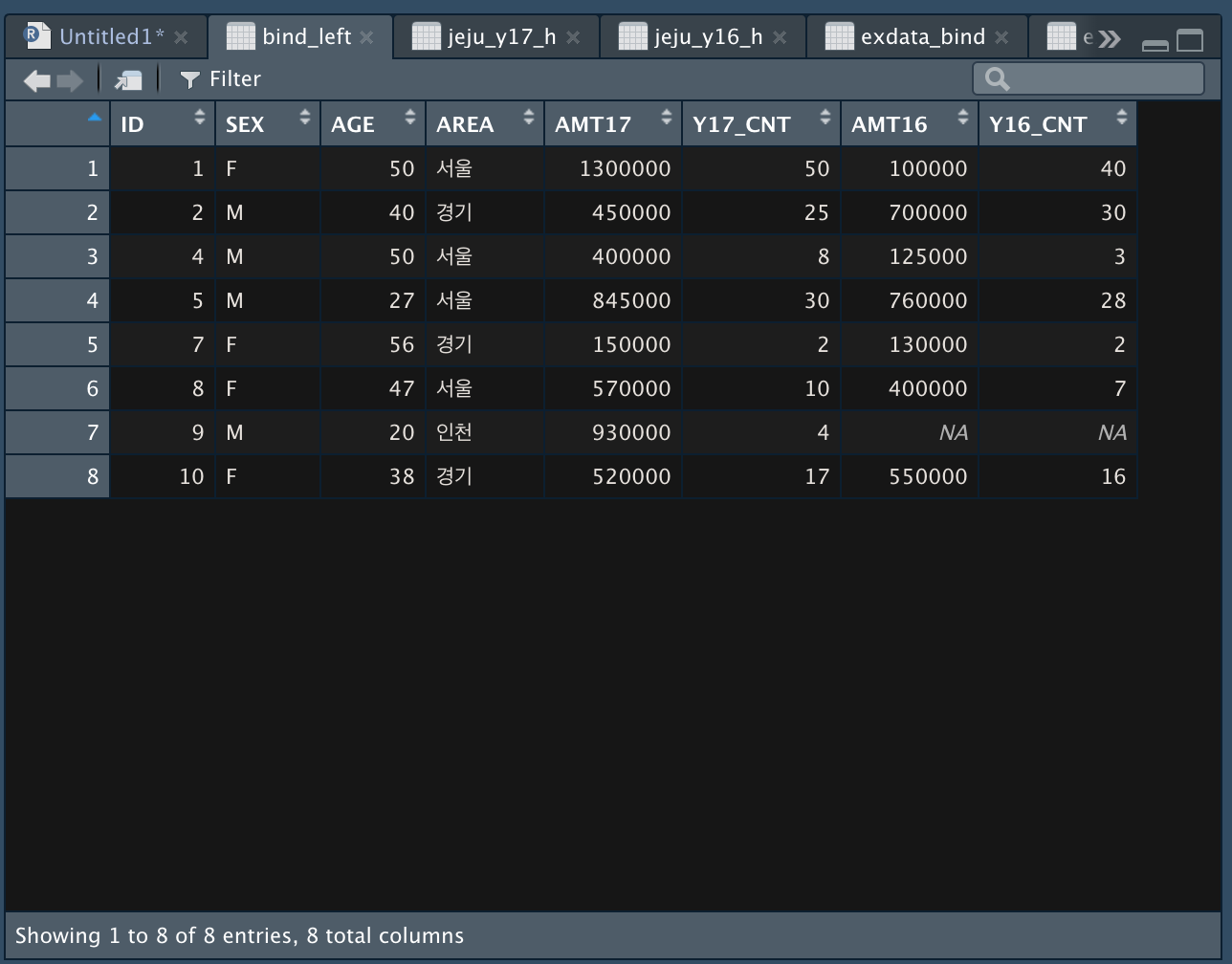
-
data set 1번을 기준으로 data set 2번 항목을 맞춘다.
(3, 6 항목이 없다.)
(data set 2번에는 ID 9번 항목이 없기 때문에 결합 데이터 세트에서 9번의 16년도 데이터는 N/A 로 표시한다.)
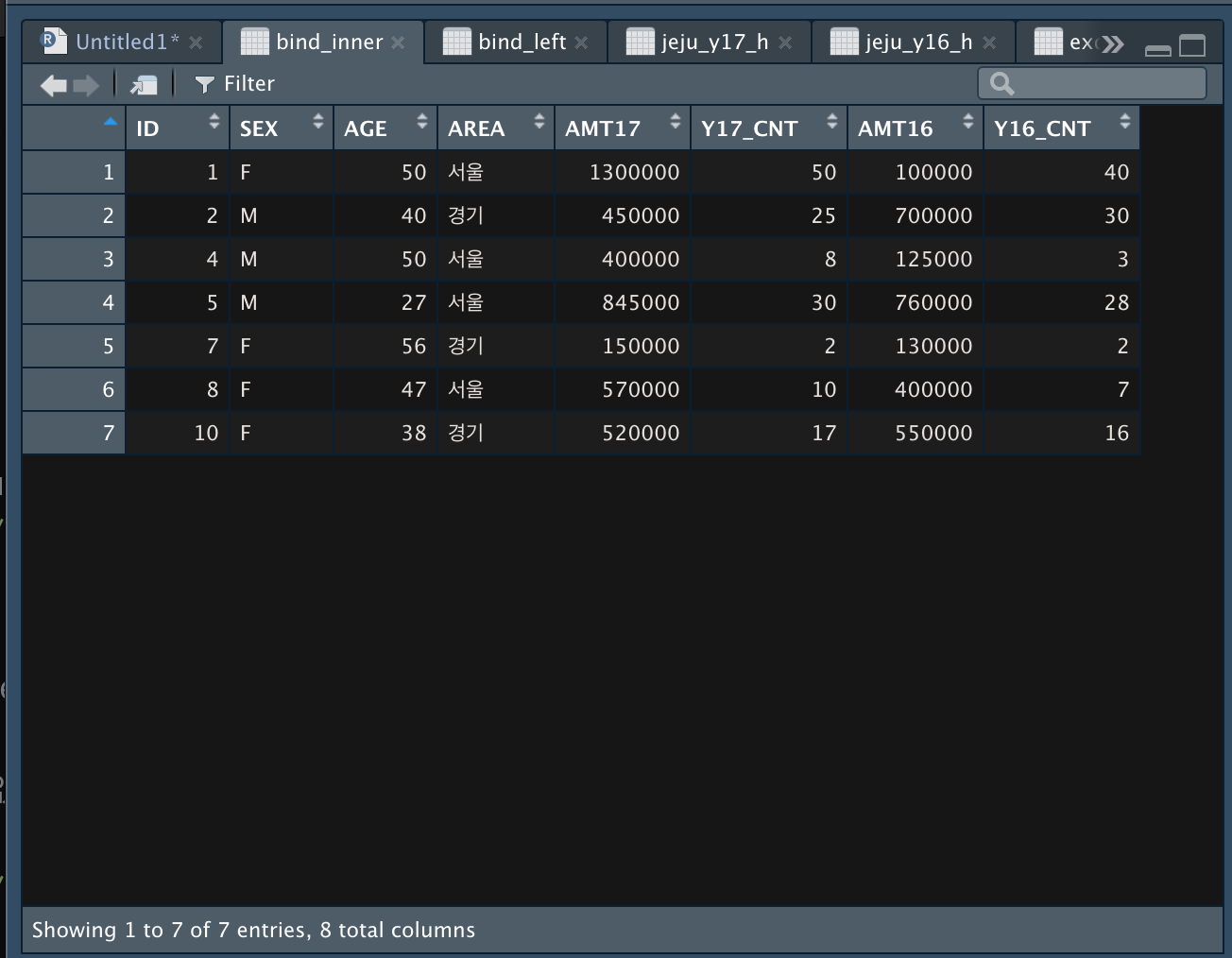
- inner_join()
*dplyr packages 사용
-
bind_inner <- inner_join(jeju_y17_h, jeju_y16_h, by = "ID")
-
data set 1번과 data set 2번에 공통된 항목만 결합한다.
(3, 6, 9 번 항목이 없다.)
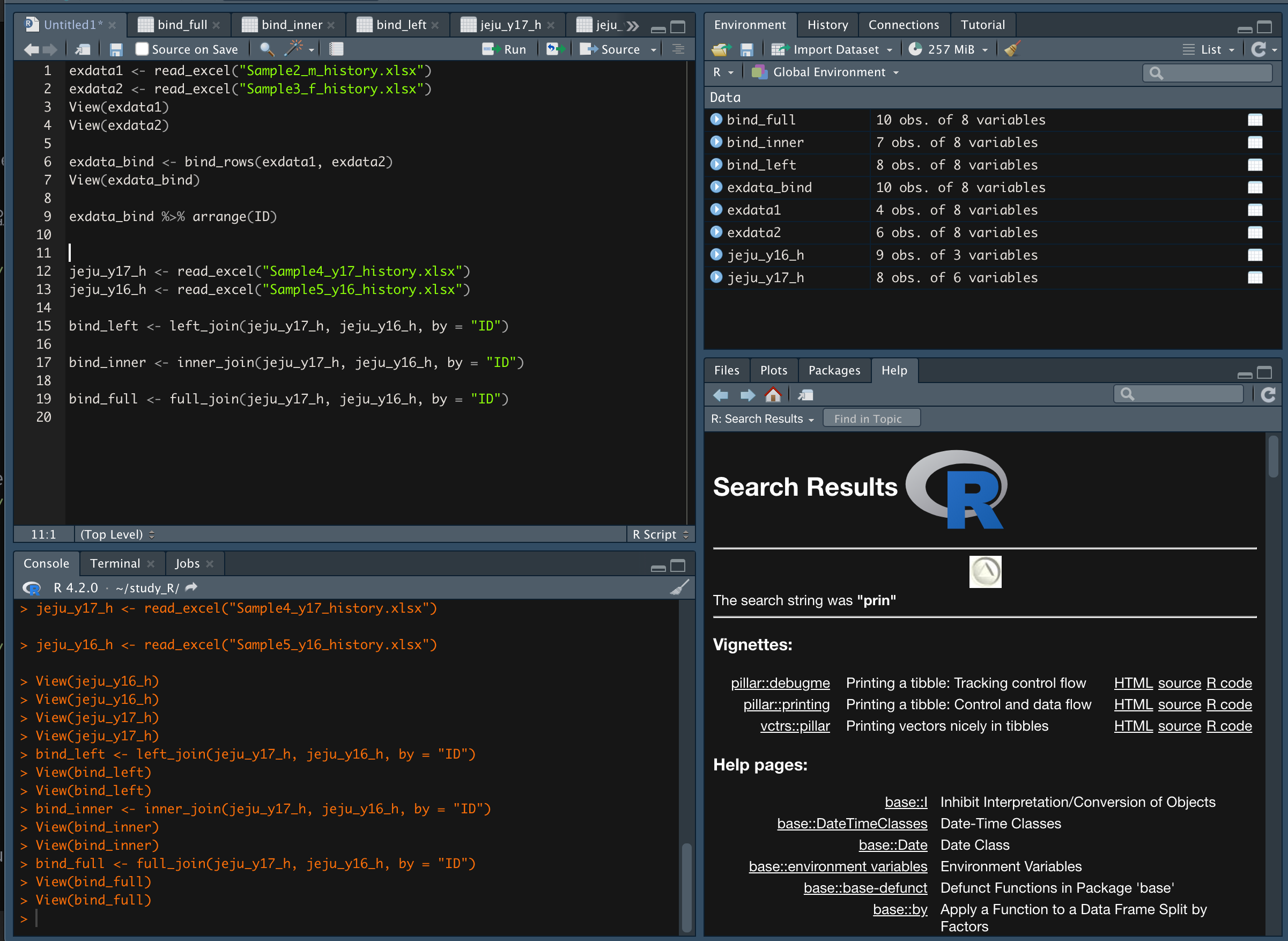
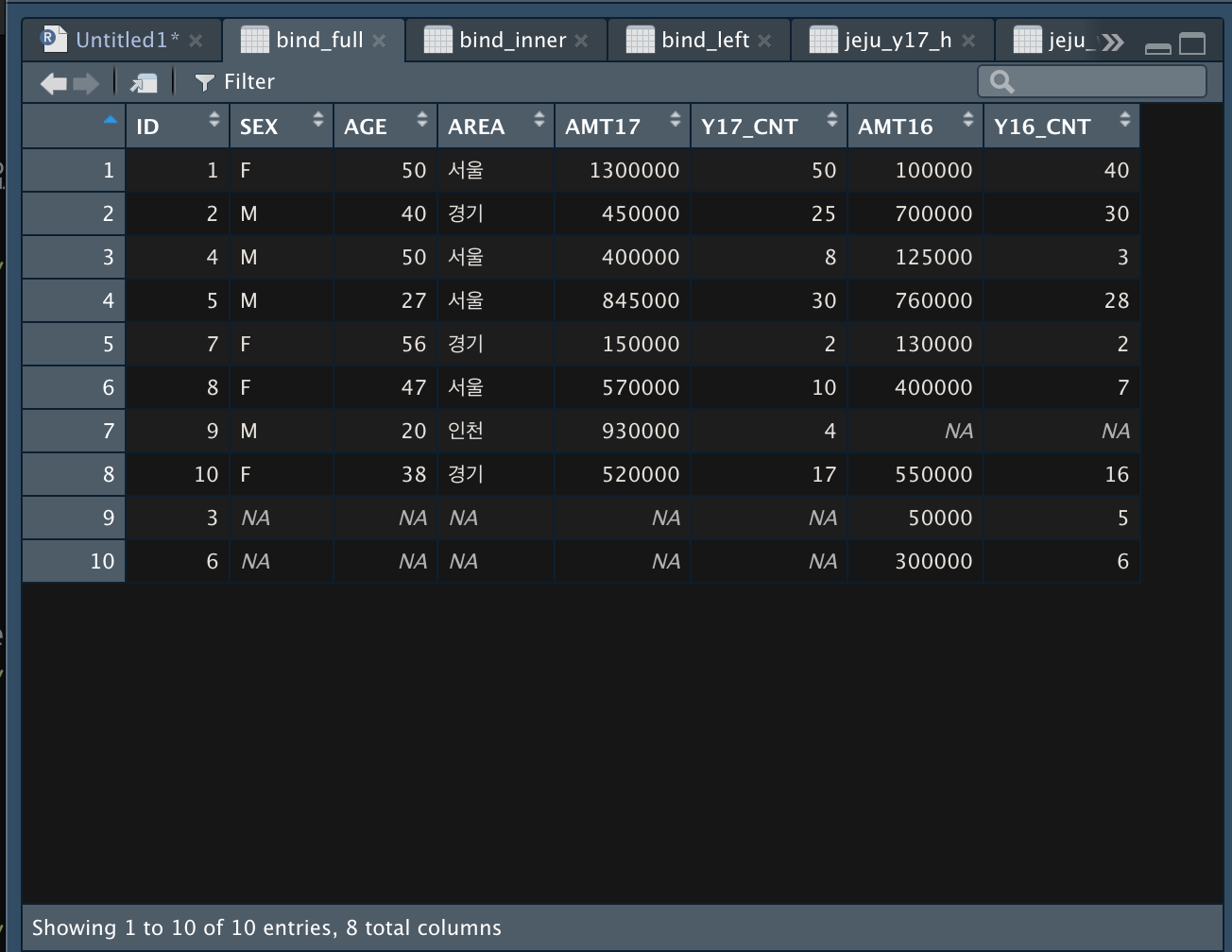
- full_join()
*dplyr packages 사용
-
bind_full <- full_join(jeju_y17_h, jeju_y16_h, by = "ID")
-
data set 1번과 data set 2번 모든 항목을 결합한다.
(data set 1번이 기준이기 때문에, 2번 항목은 1번항목 뒤에 추가되는 형태로 나타난다.)
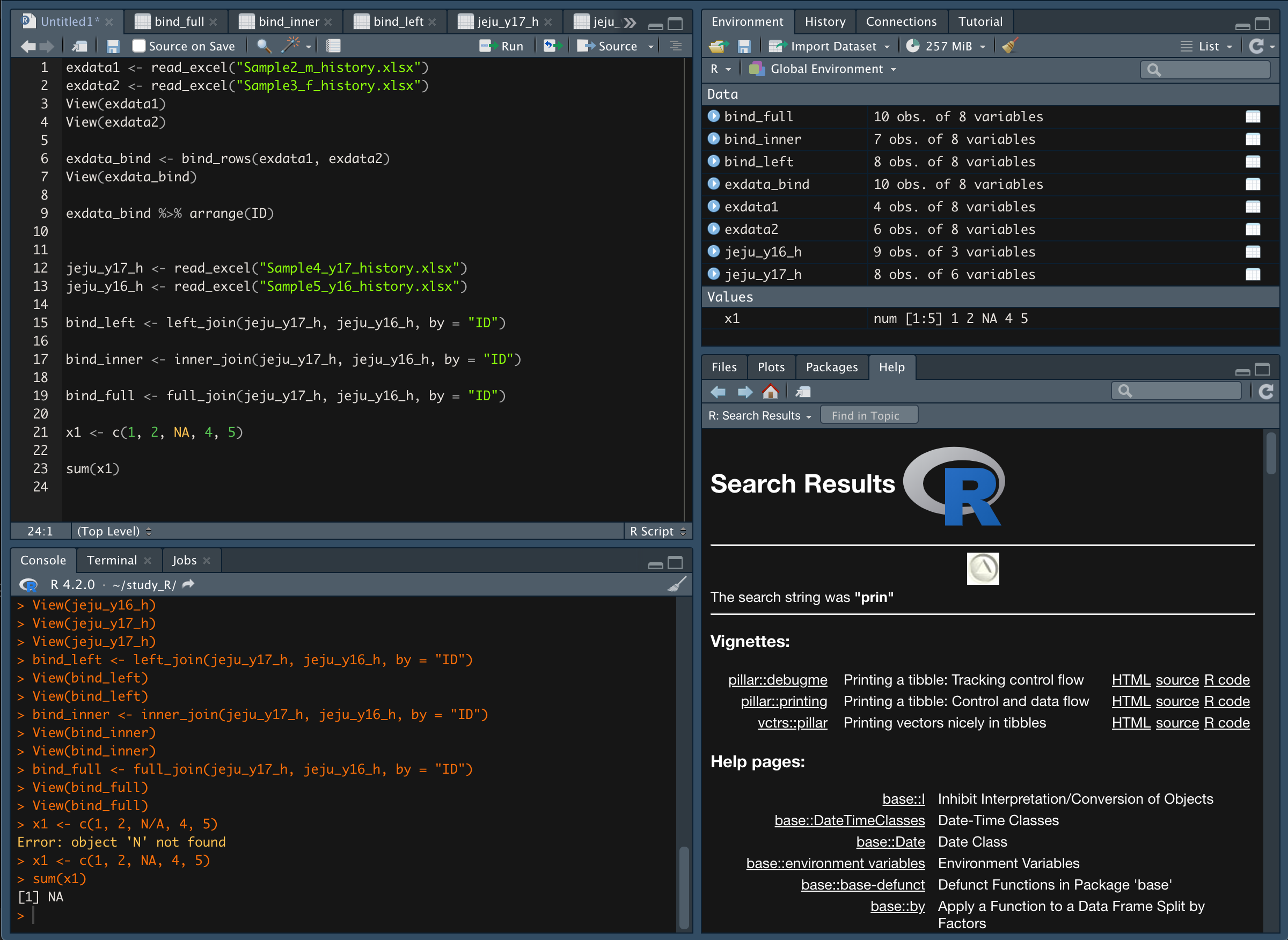
- Tip ) 결측값 제외하고 계산하는 방법
-
결측값이 있으면 연산을 해도 결측값으로 나온다.
-
na.rm = T 조건을 이용해 결측값을 제외한다.
[출처] 처음 시작하는 R데이터 분석, 강전희

데이터는 철저하게 해석은 자유롭게