- 필요한 데이터 추출

- select() 함수 사용
-
%>% 연산자는 파이프 연산자라고 하며 dplyr 패키지에 포함된 기능 중 하나다. 여러번 실행해야 하는 복잡한 코드를 한 번에 처리할 수 있게 연결해 주는 연산자다.
-
한 가지 변수 가져오기
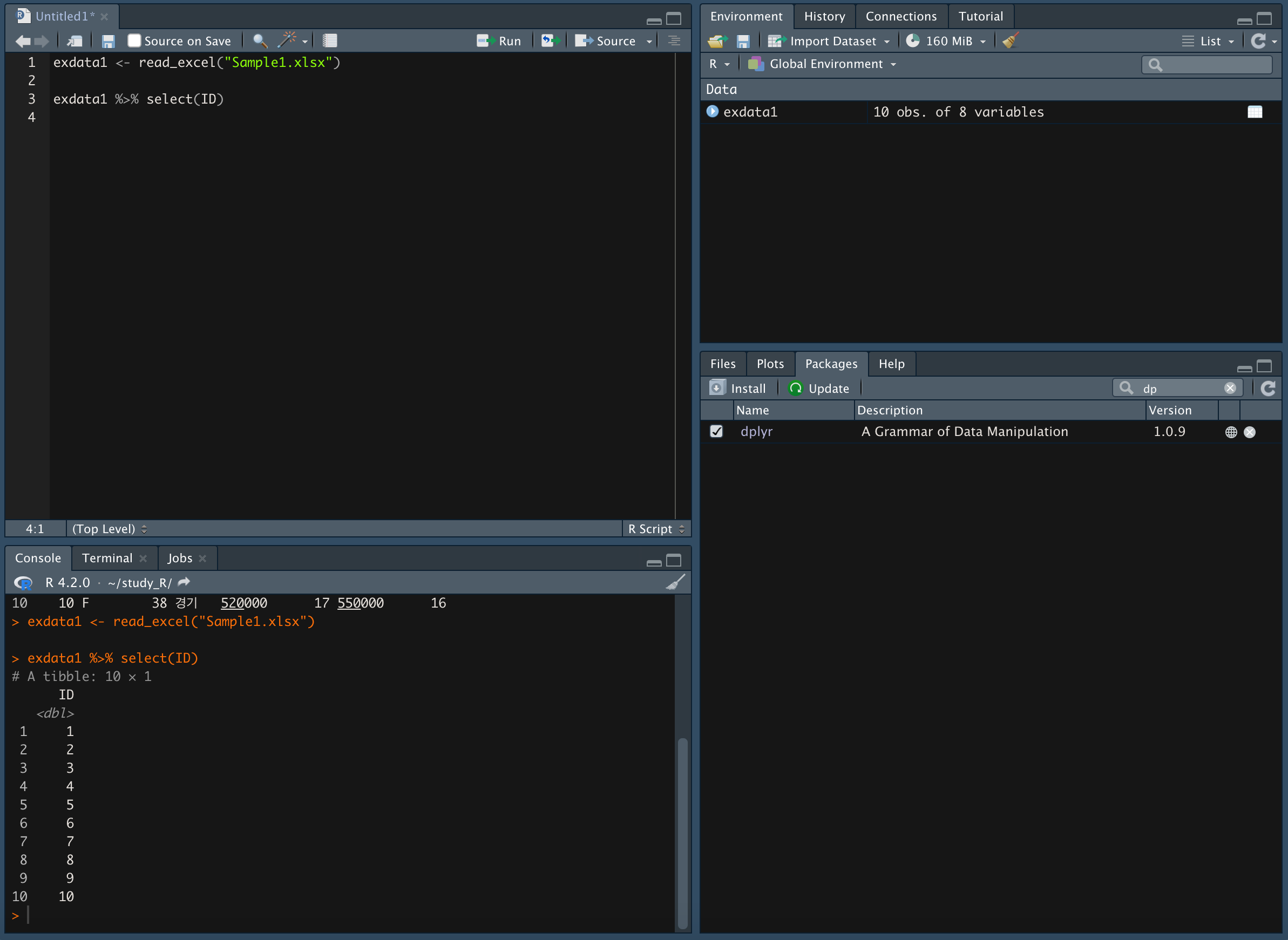
- 세 가지 변수 가져오기
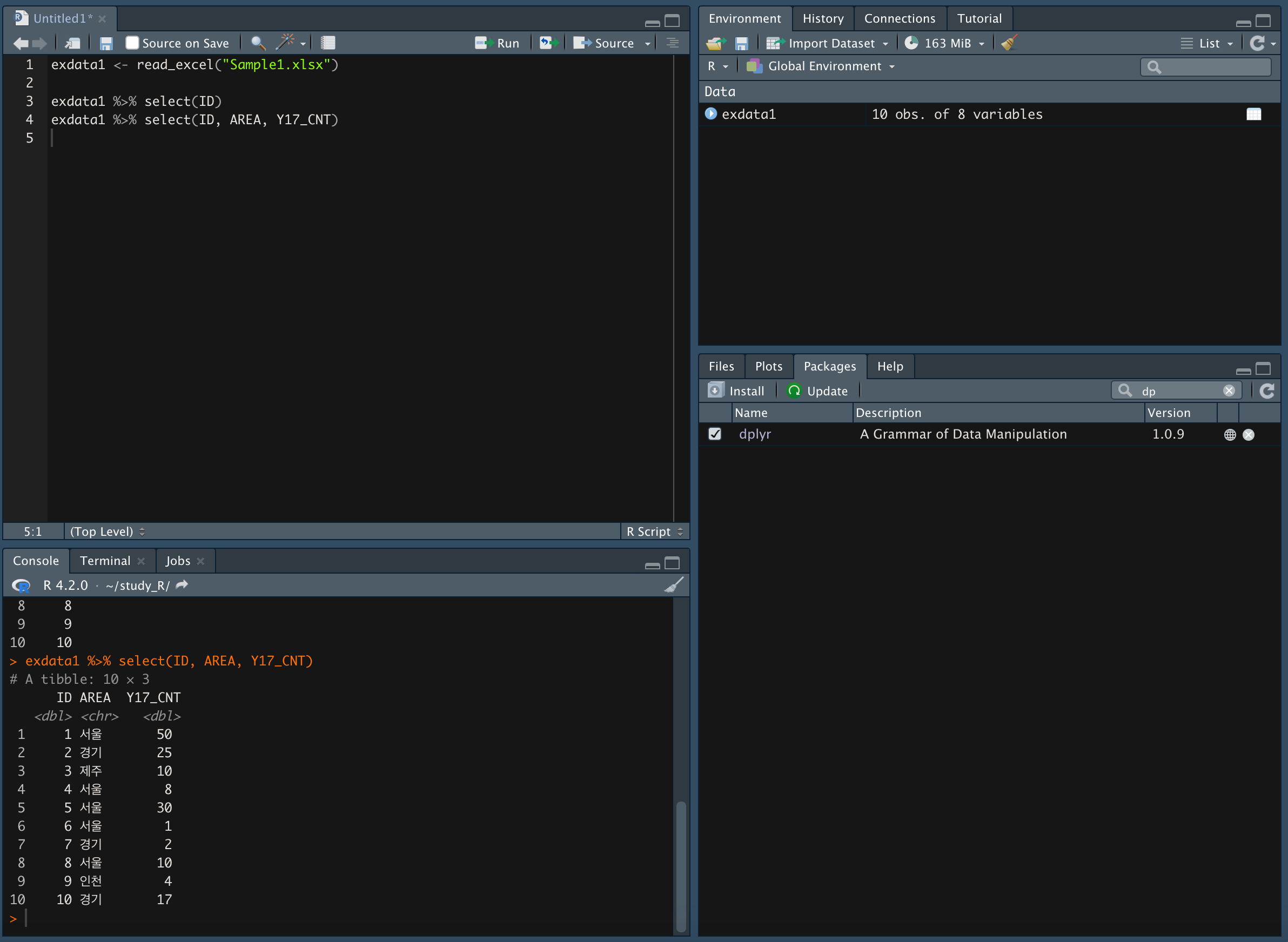
-
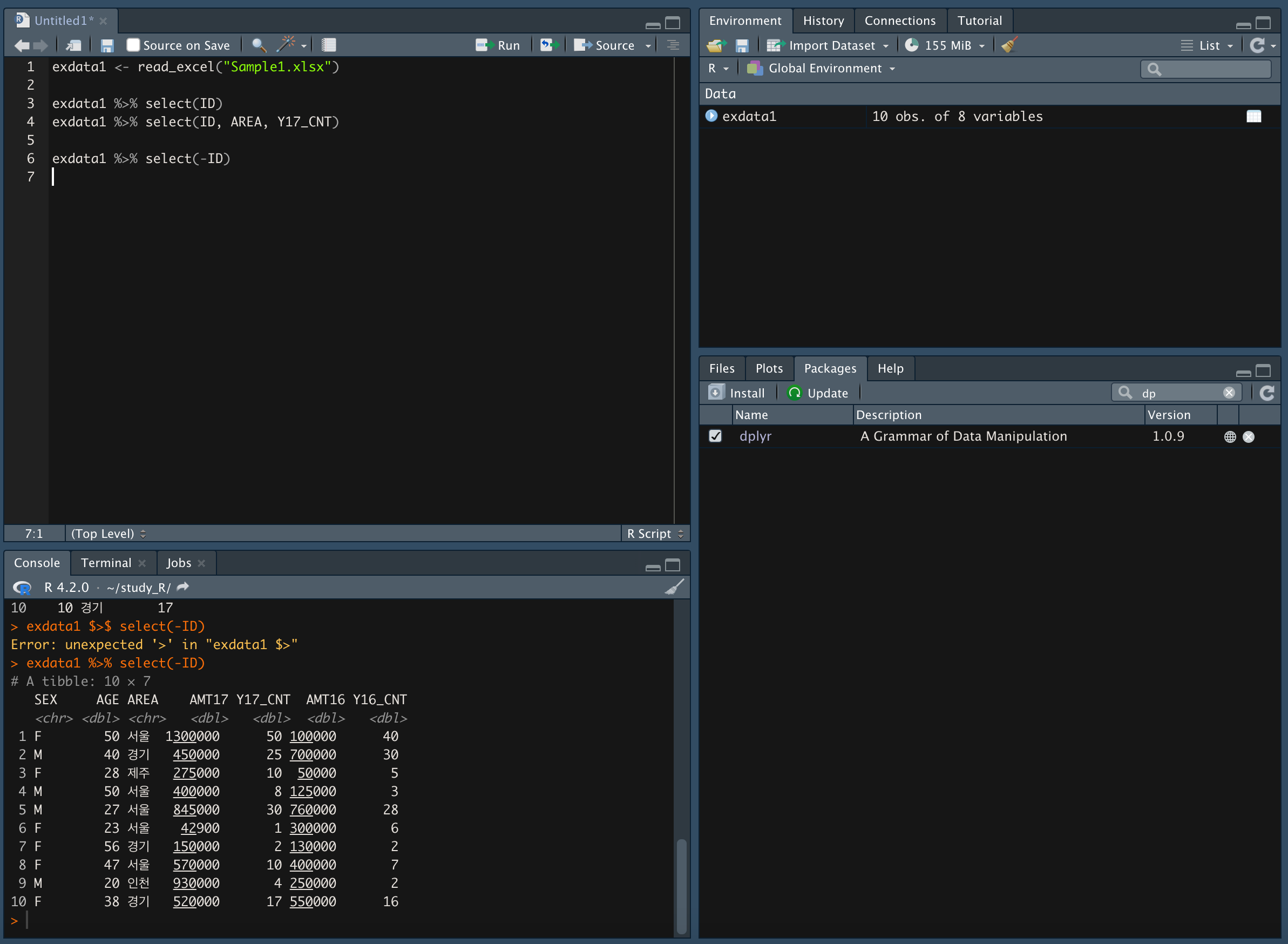
특정 변수만 제외하고 가져오기
-
select(-제외하고 싶은 변수명)
-
두 가지 변수 제외하고 가져오기
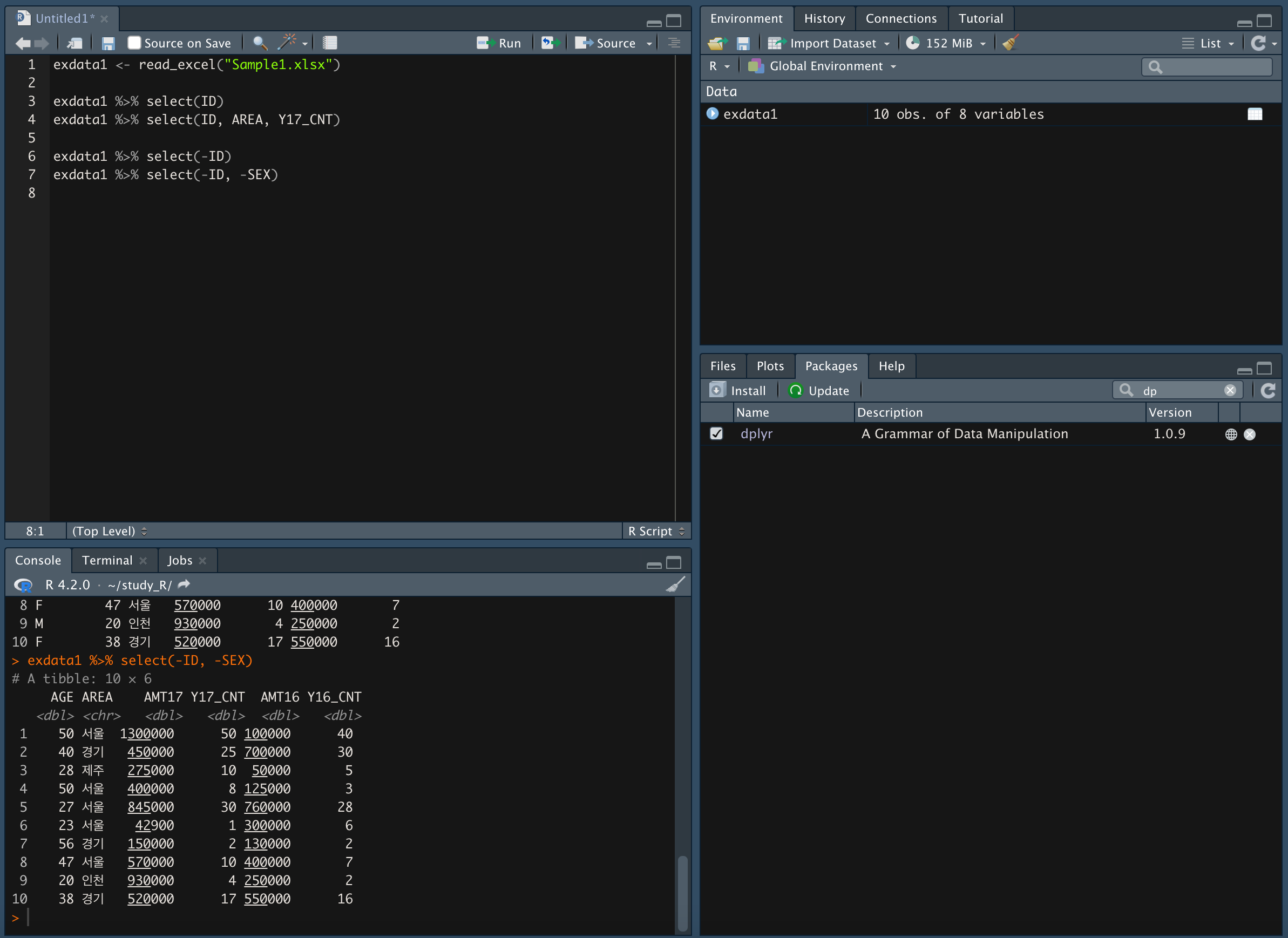
- filter() 함수 사용
-
<지역>이 "서울"인 데이터만 가져오기
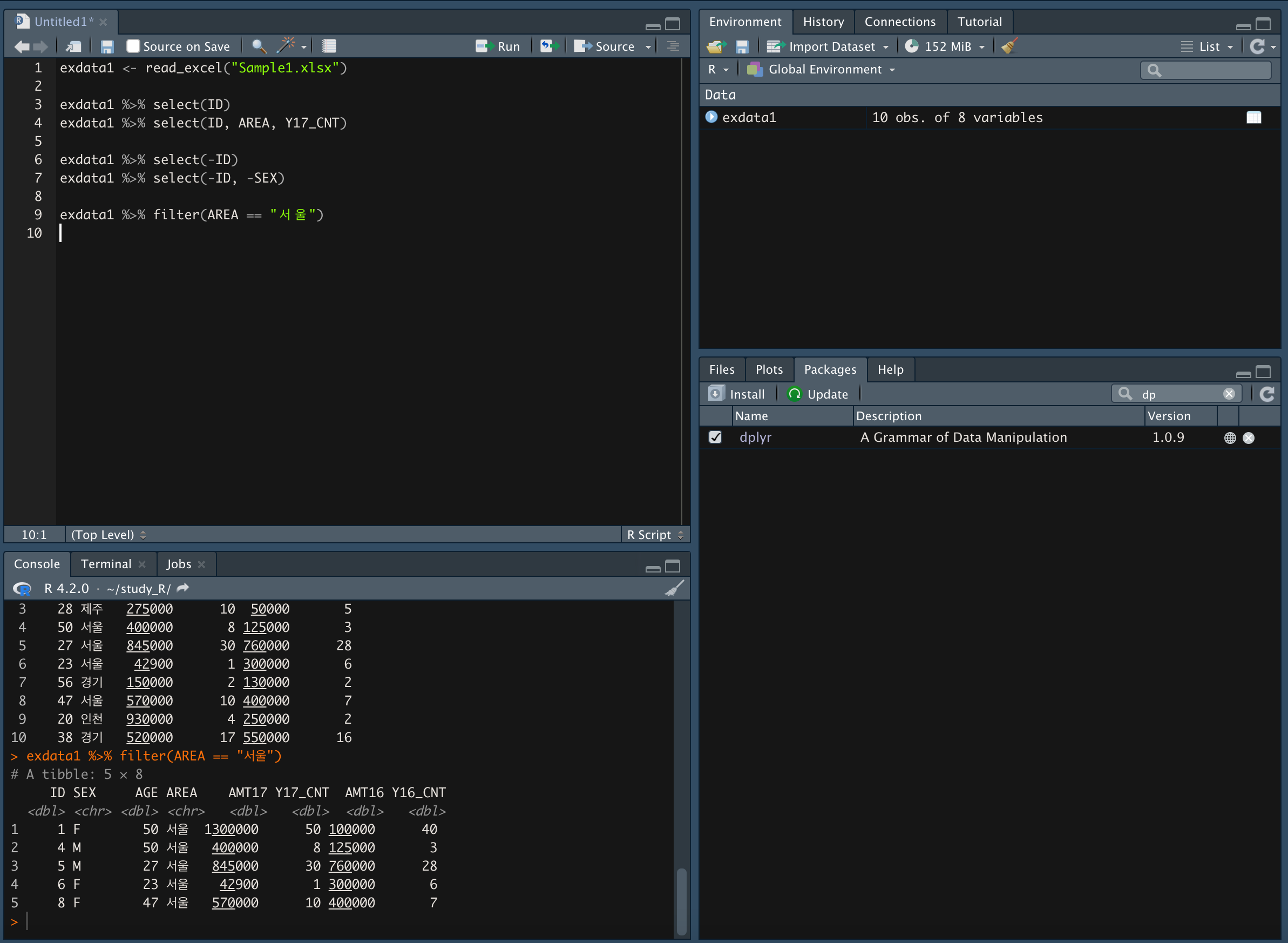
-
<지역>이 "서울" 이고, Y17_CNT 값이 10 이상인 데이터만 가져오기
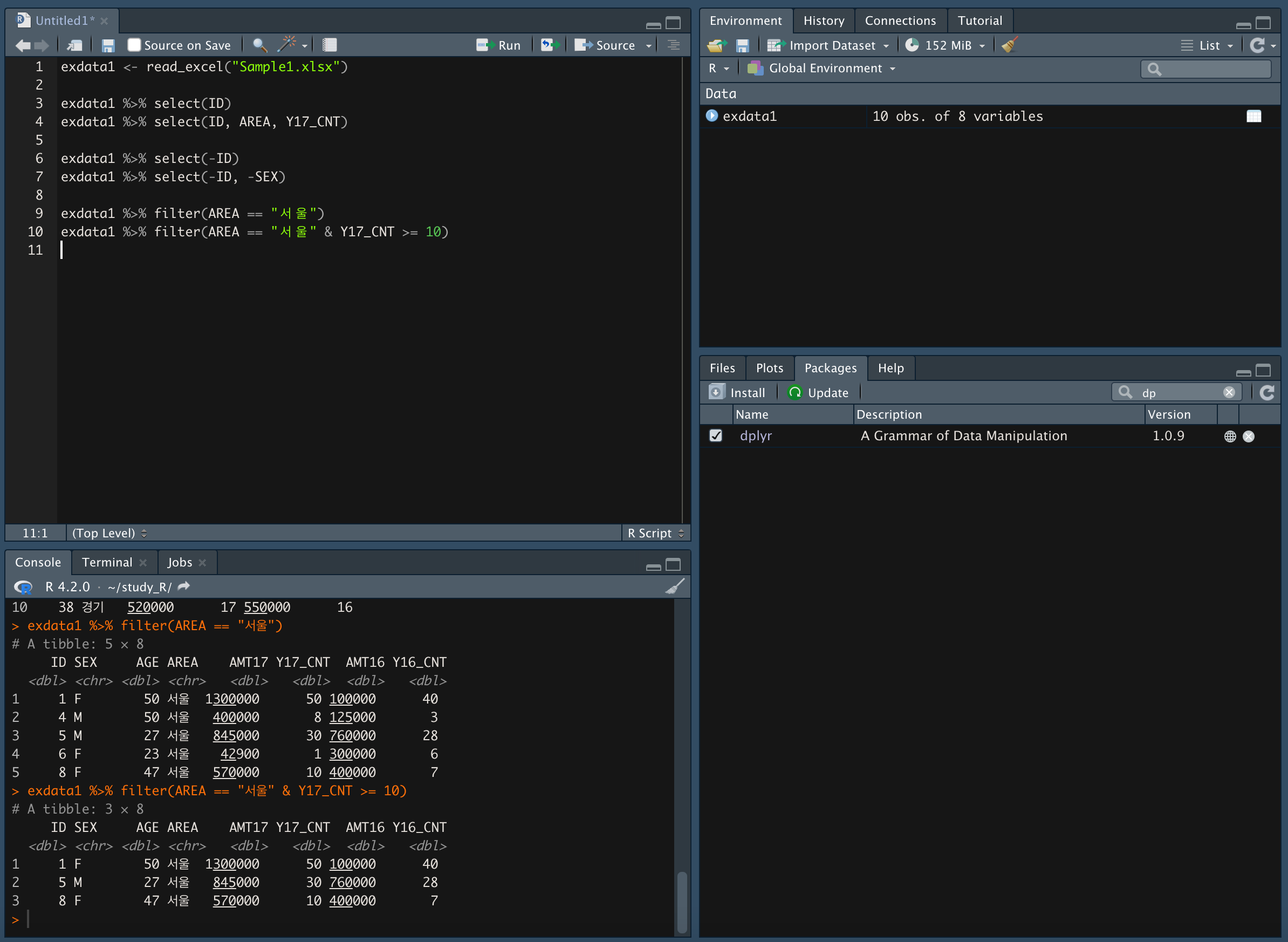
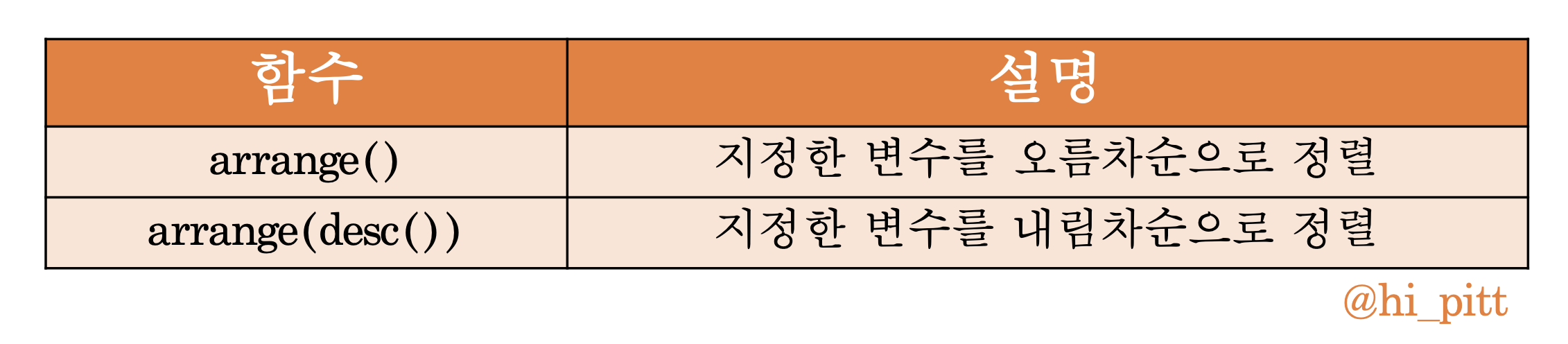
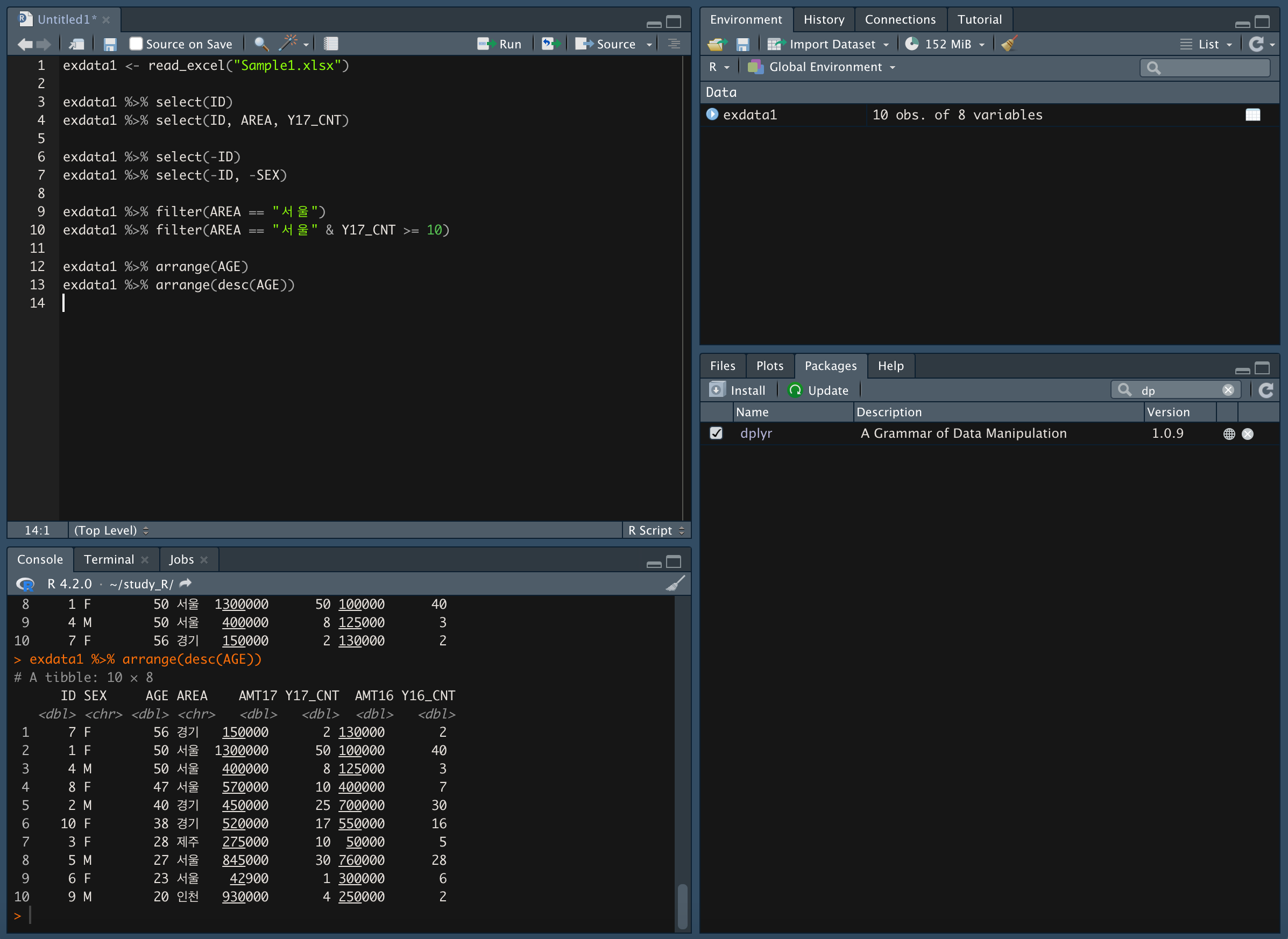
- 데이터 정렬
-
연령을 오름차순으로 정렬
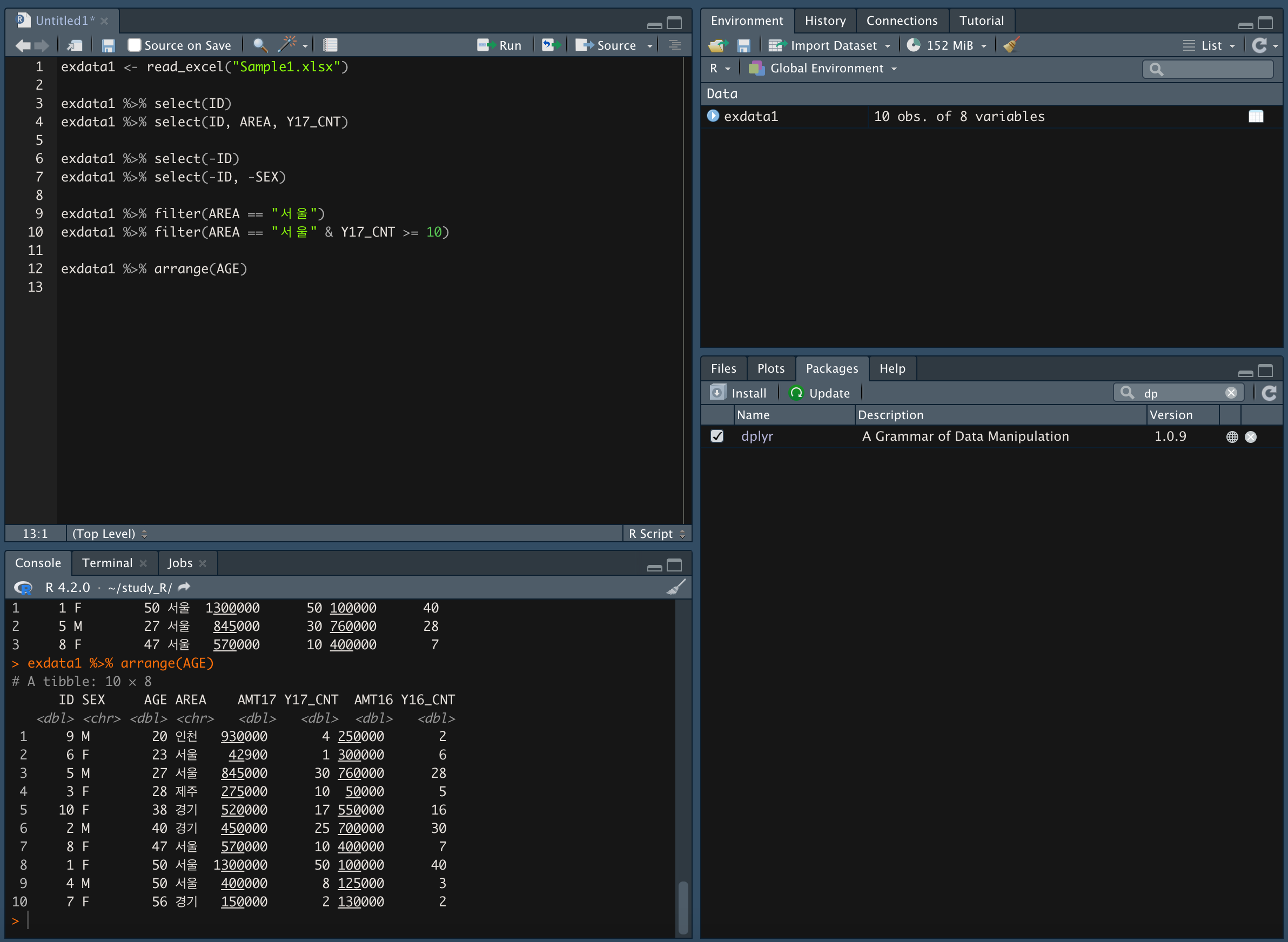
-
연령을 내림차순으로 정렬
- 데이터 요약
- dplyr 패키지의 group_by(), summarise() 함수를 사용한다.
분위수란 ?
전체 자료를 크기순으로 정렬할 때 경계에 해당하는 값을 의미한다.
- 1분위수 : 하위 25%에 해당하는 값
- 2분위수 : 50%에 해당하는 값, 중앙값과 동일하다
- 3분위수 : 상위 25%에 해당하는 값
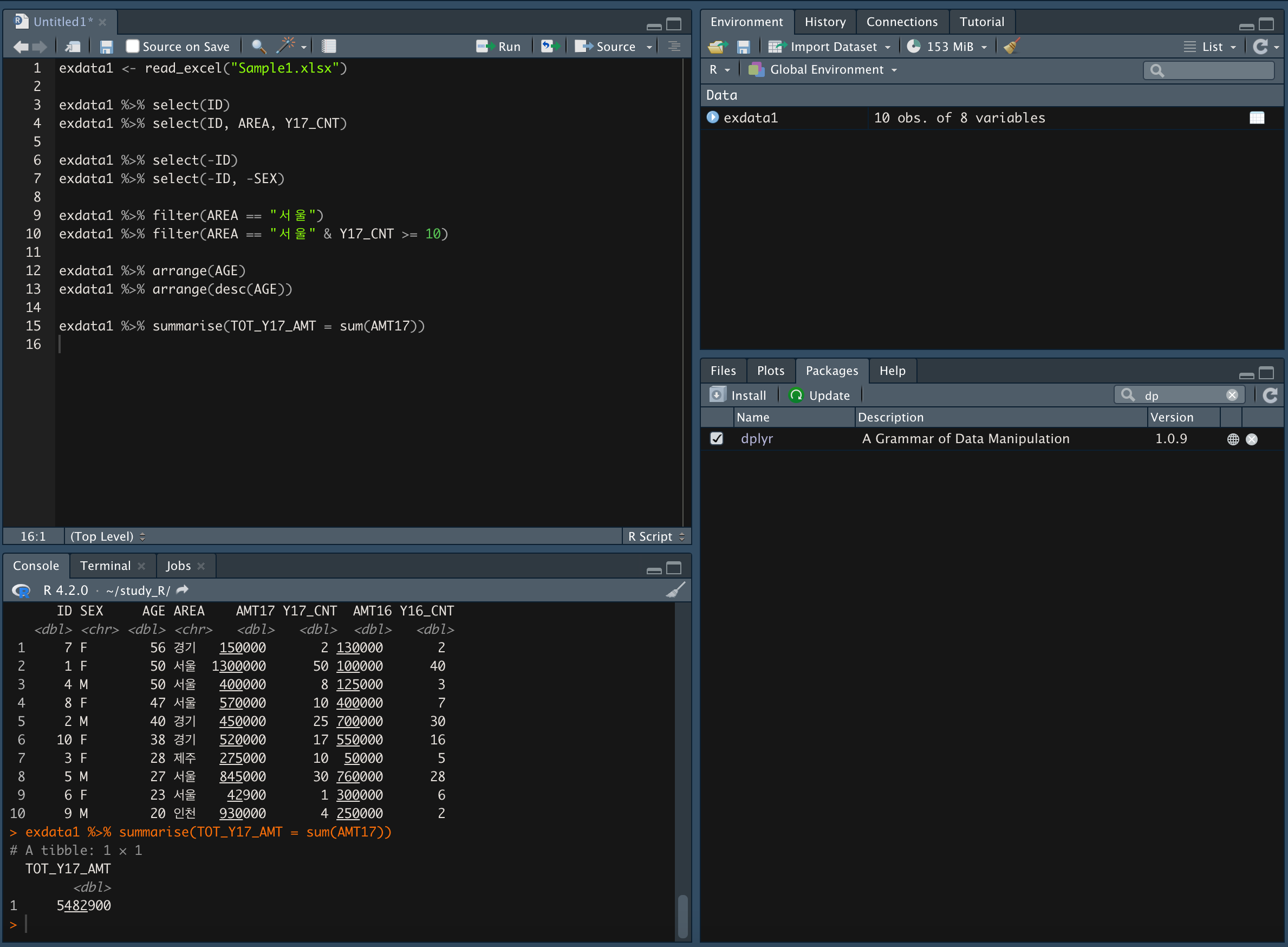
- summarise() 함수를 이용해 합계를 도출
- AMT17 값을 sum() 한다.
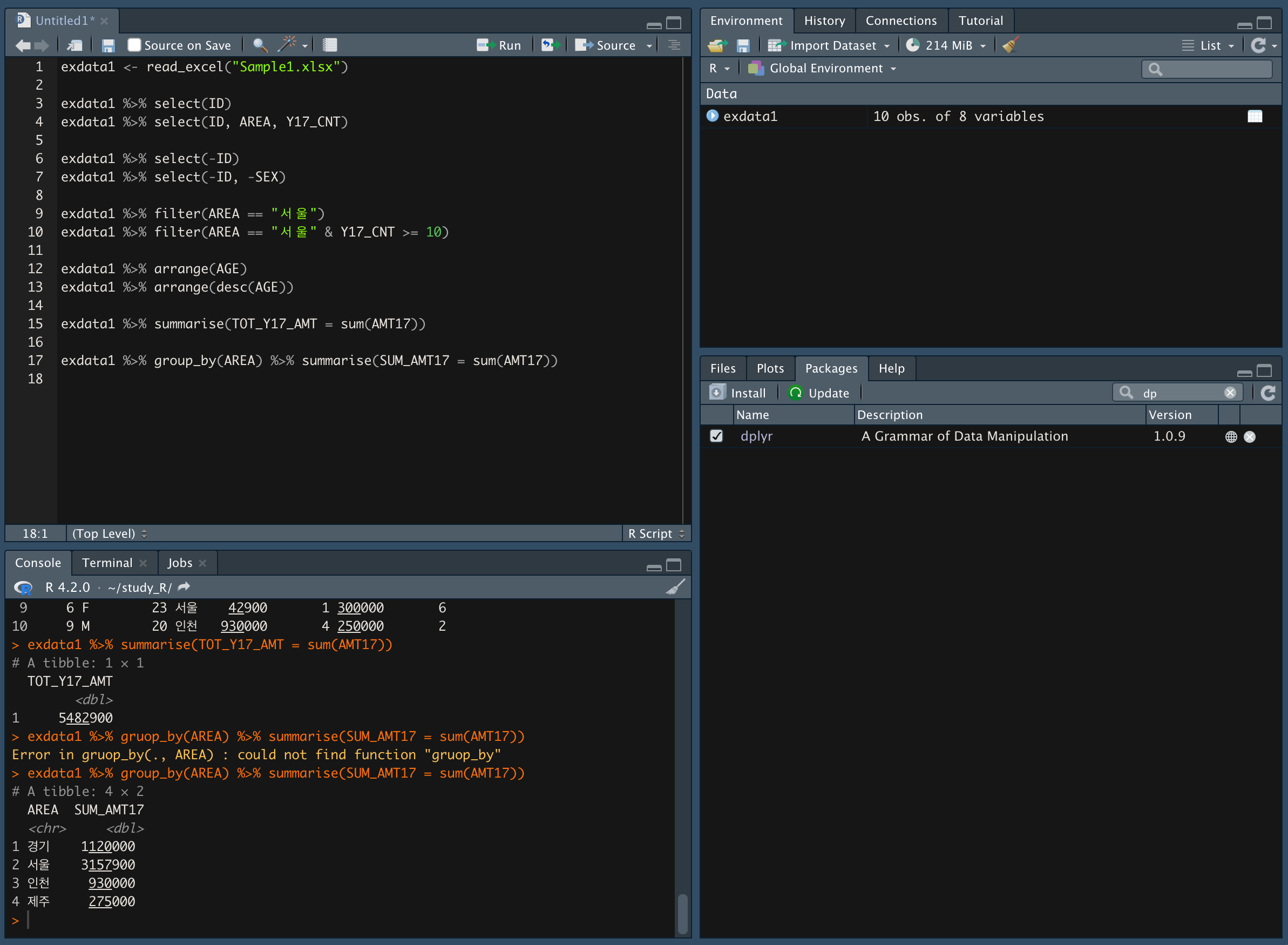
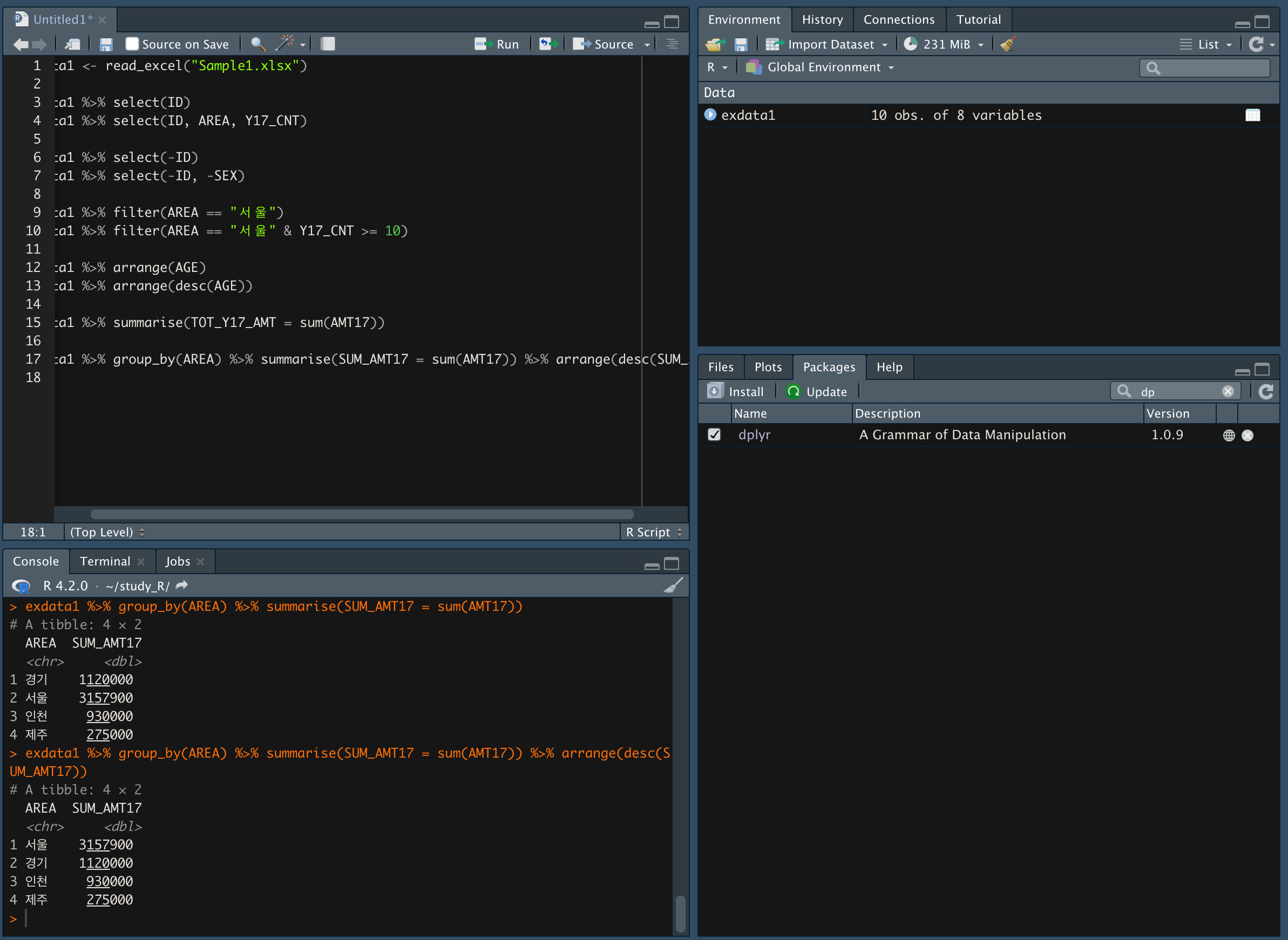
- group_by() 함수를 이용해 그룹의 값을 도출
-
group_by() 함수로 지역을 묶고, summarise() 함수로 AMT17 값을 더한다.
-
arrange(desc()) 함수를 이용해 내림차순으로 정렬한다.
[출처] 처음 시작하는 R데이터 분석, 강전희

데이터는 철저하게 해석은 자유롭게