
Chapter3 운영체제의 마지막
<6> 파일 시스템에 대해 알아보자.
우리가 일상적으로 사용하는 파일과 디렉터리는 모두 운영체제 내부에 있는 파일 시스템이라고 하는 프로그램이 관리해주는 대상들이다.
한 컴퓨터 내에 여러 개의 파일 시스템을 사용할 수도 있다.
파일과 디렉터리는 기본적으로 데이터의 관점으로만 본다면 보조기억장치에 저장된 데이터 덩어리라고 할 수 있다.
이것을 운영체제가 파일과 디렉터리로서 정리하고 관리해 주는 것.
📘 파일(File)
파일이란 보조기억장치에 저장되어 있는 의미있는 정보들을 모은 논리적 단위이다.
파일을 이루는 정보는
- 파일의 이름
- 파일을 실행하기 위한 정보
- 파일과 관련한 부가 정보
가 있다.
파일과 관련한 부가 정보를
속성(attribute) 또는 메타데이터(metadata)라고 부른다.
📘 디렉터리(Directory)
윈도우 운영체제에서는 폴더(Folder)라고 부른다.
옛 운영체제에서는 하나의 디렉터리만 존재했었다. 이것을 1단계 디렉터리로 부르기도 한다.
하나의 디렉터리가 있고 이 디렉터리 아래에 다양한 파일들이 존재하는 구조로 파일들이 관리가 됐었다.
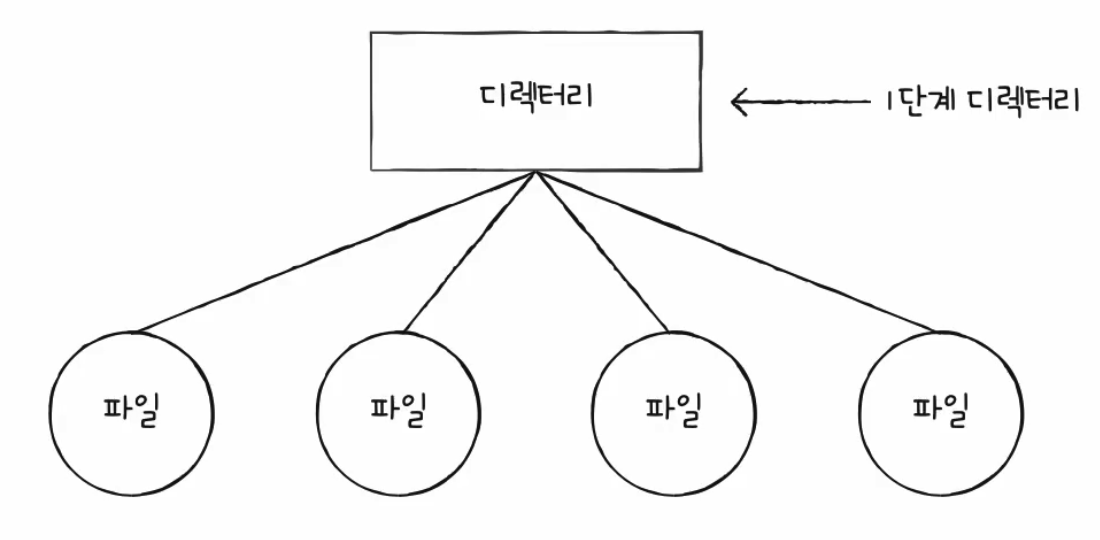
요즘엔 컴퓨터 용량도 커지고 저장할 수 있는 파일들도 많아졌다.
그리고 디렉터리 안에 서브 디렉터리, 그 안에 또다른 서브 디렉터리,
이런 식으로 여러 개의 디렉터리가 계층적으로 구성된다.
이렇게 여러 계층으로 파일 및 디렉터리를 관리하는 것을
트리 구조 디렉터리(Tree-Structured Directory)라 한다.
트리 구조에서 가장 최상단에 있는 디렉터리가 있다.
이 디렉터리를 루트 디렉터리(Root Directory)라고 한다.
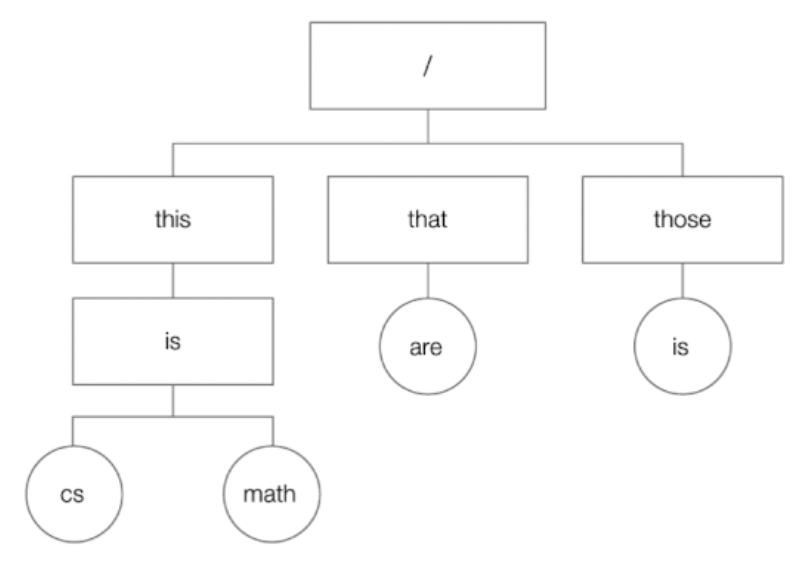
그림에서 알 수 있듯 이 루트 디렉터리를 ' / ' 로 표현한다.
디렉터리 정보를 활용해 파일 위치를 특정하는 정보를 경로(path)라고 한다.
그림으로 예를 들자면 루트 디렉터리에 포함된 this 디렉터리에 포함된 is 디렉터리에 포함된 cs 라는 파일을
/this/is/cs 라고 표현할 수 있다.
참고로, 윈도우 운영체제에서는 최상위 디렉터리를 'C:W'로 표현하고 백슬래시를 디렉터리의 구분자로 사용한다.
파일과 디렉터리가 별개라고 생각할 수 있는데, 운영체제에서는 디렉터리를 조금 특별한 파일로 간주한다.
정확히는 디렉터리에 속한 요소의 관련 정보가 포함된 파일로 간주한다.
디렉터리에 속한 요소의 관련 정보는 테이블(표)의 형태로 표현되고, 테이블 형태로 표현된 정보의 행 하나 하나를
디렉터리 엔트리(Directory Entry)라고 한다.
이제 파일 시스템에 대해 알아보도록 하자.
파일 시스템은 파일과 디렉터리를 보조기억장치에 저장하고 또 접근할 수 있도록 하는 운영체제의 내부 프로그램이다.
파일 시스템에는 다양한 종류가 있다.
파일 시스템에 대해 알아보기 전에 알아야 하는 용어가 있다.
파티셔닝과 포매팅이다.
📌 파티셔닝(Partitioning)
저장장치의 논리적인 영역을 구획하는 작업.
보조기억장치를 서랍에 비유해보자. 서랍 안에 내가 어떤 물건을 넣어둘 때 아무렇게나 넣어버리면 나중에 다시 그 물건을 찾을 때 찾기도 어렵고 물건들을 정리하기도 쉽지 않다. 서랍에 칸막이를 설치하고 목적에 따라 물건들을 나눠두면 정리도 쉽고 나중에 찾기도 편해진다.
이렇게 칸막이처럼 보조기억장치의 영역을 나누는 작업을 파티셔닝이라고 한다.
이렇게 파티셔닝을 통해 나누어진 하나 하나의 영역을 파티션(Partition)이라고 한다.
📌 포매팅(Formatting)
파일 시스템을 설정하여 어떤 방식으로 파일을 저장하고 관리할 것인지를 결정하고 새로운 데이터를 쓸 준비를 하는 작업.
포매팅까지 완료해 파일 시스템을 설정했다면 이제 파일과 디렉터리의 생성이 가능해진다.
하드디스크의 파일과 디렉터리가 어떤 식으로 저장되는지 보자.
운영체제는 파일과 디렉터리를 하드디스크의 블록 단위로 읽고 쓴다.
하드 디스크의 가장 작은 저장단위는 섹터(Sector)다.
섹터는 갯수가 너무 많고 크기도 작기 때문에 파일 시스템이 모든 섹터를 관리하긴 힘들다.
그래서 운영체제는 하나 이상의 섹터를 블록이라는 단위로 묶은 뒤에 블록 단위로 파일과 디렉터리를 관리하게 된다.
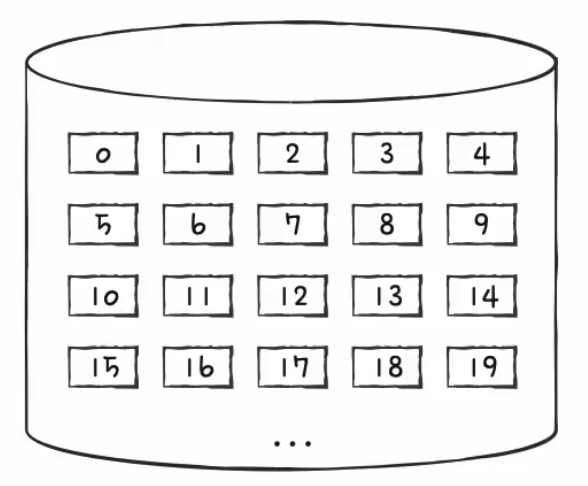
다음 그림과 같이 하드디스크 내에 여러개의 블록이 있다고 가정을 해보자.
이 네모들이 전부 블록이다.
블록 안에 적힌 번호는 블록의 위치를 식별하는 주소라고 생각하면 된다.
이제 사용할 파일을 이 보조기억장치에 저장하기 위해서 이 블록에 사용할 파일을 할당해야 한다.
만약 파일의 크기가 작다면 적은 수의 블록에 걸쳐서 저장이 되고, 파일의 크기가 크다면 많은 수의 블록에 걸쳐서 저장이 될 것이다.
여기서 파일을 할당하는 방법 중에서는 여러가지 방법이 있다.
크게 두 가지 방법만 알아보도록 하자.
연속할당 방식과 불연속할당 방식이다.
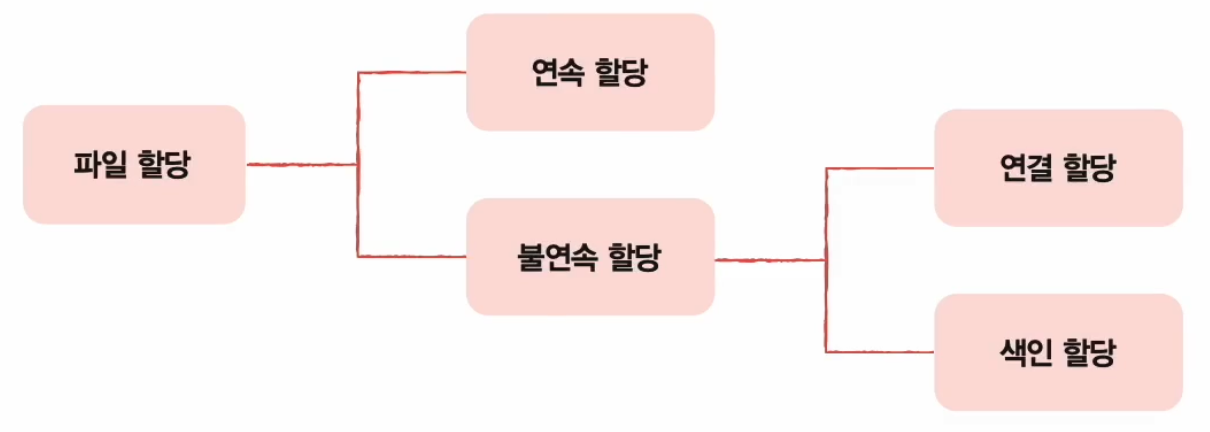
불연속 할당 방식에는 연결 할당과 색인 할당이라고 하는 종류가 있다.
연속할당 방식부터 알아보자.
📘 연속 할당 방식
보조기억장치 내 연속적인 블록에 파일을 할당하는 방식
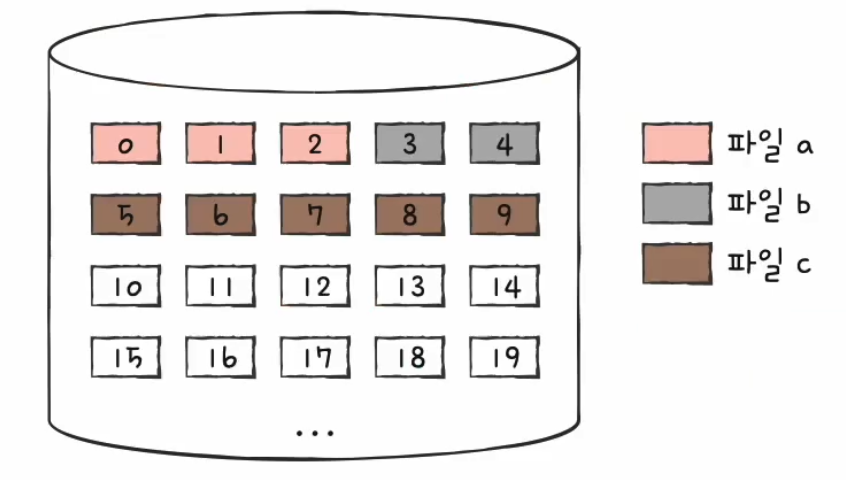
파일 a 가 3개의 블록에 걸쳐서 저장되는 크기라면 그림처럼 0, 1, 2 세 개의 블록에 저장되고, 파일 b, c 도 마찬가지로 그 크기에 맞춰서 연속적으로 블록에 할당된다.
이 연속할당을 사용하는 시스템에서 어떤 파일을 읽어들이기 위해서 어떤 파일이 저장되어 있는 위치를 식별하기 위해서 필요한 두 가지 정보는 파일의 첫 번째 블록 주소와 블록 단위의 길이다.
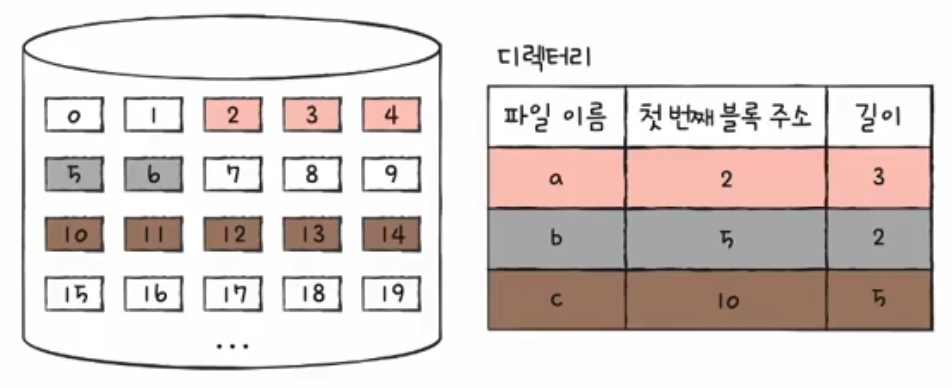
그래서 연속할당을 사용하는 디렉터리 엔트리에는 파일 이름, 첫 번째 블록 주소와 길이가 명시된다.
하지만 연속할당 방식은 외부단편화를 야기할 수 있다는 단점 때문에 요즘엔 불연속 할당 방식을 주로 사용하고 있다.
이 연속할당의 문제를 해결할 수 있는 방식이 불연속 할당 방식이다.
그 중에서 불연속 할당 - 연결 할당 방식부터 알아보자.
📘 불연속 할당 - 연결 할당
각 블록의 일부에 다음 블록의 주소를 저장하여 각 블록이 다음 블록을 가리키는 형태로 할당한다.
파일을 이루는 데이터 블록을 연결 리스트로 관리한다.
파일이 여러 블록에 흩어져 저장되어도 불연속 할당의 일종이기 때문에 괜찮다.
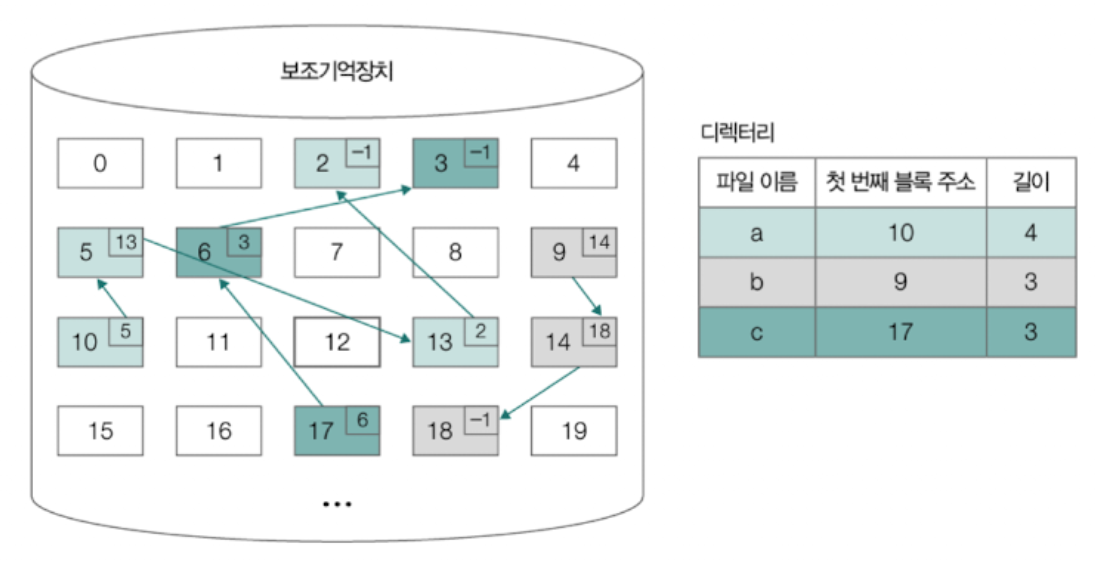
연결 할당 방식은 외부 단편화 문제를 해결할 수 있지만,
이 또한 단점이 있다.
반드시 파일의 첫 번째 블록부터 접근해서 하나씩 읽어들여야 한다는 단점이 있다.
그래서 파일의 임의의 위치에 접근하는 속도가 매우 느리다.
그리고 하드웨어 고장이나 오류가 발생하면 어떤 해당 블록 이후부터의 블록은 접근할 수가 없다.
블록 하나만 고장나도 다음 블록이 어디를 가리키고 있는지 모르기 때문이다.
다음으로 알아볼 것은 불연속 할당 - 색인 할당이다.
📘 불연속 할당 - 색인 할당
파일의 모든 블록 주소를 색인 블록이라는 하나의 블록에 모아 관리하는 방식.
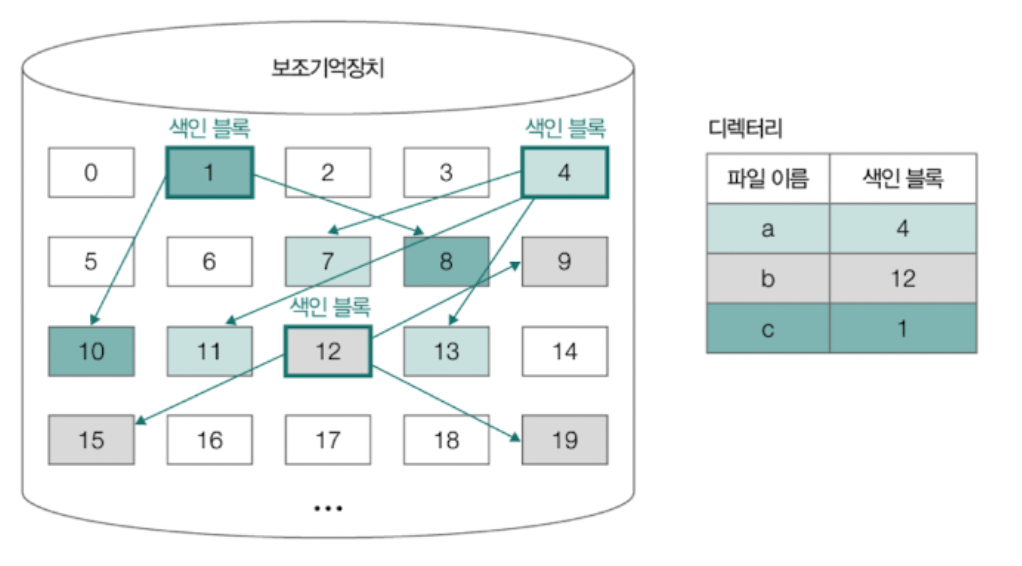
예를 들어 색인 블록이 4번이다 라고 가정한다면
7번 읽고, 11번 읽고, 13번 읽어라는 파일의 주소들을 모두 이 색인 블록에 저장하는 것이다.
연결 할당 기법보다 파일에 접근하기가 용이하다.
자, 이제 실제로 사용되는 파일 시스템의 종류와 대략 어떻게 동작하는지에 대해 알아보자.
📌 FAT 시스템
연결 할당 기반의 파일 시스템
앞서 말했던 연결 할당 방식의 단점들을 보완한 파일 시스템이라고도 볼 수 있다.
FAT 시스템에서는 각 블록에 포함된 다음 블록 주소를 모아 테이블(FAT; File Allocation Table)로 관리 한다.
FAT 시스템은 옛날 운영체제인 MS-DOS에서 많이 사용되었고, 최근에는 USB 메모리나 SD 카드처럼 저장장치용 파일 시스템으로 많이 사용되고 있다.
📌 유닉스 파일 시스템
색인 할당 기반의 파일 시스템
유닉스 파일 시스템은 색인 블록을 i-node(index-node)라고 부른다.
i-node에는 파일의 속성 정보와 15개의 블록 주소를 저장할 수 있다.
이제 운영체제가 모두 끝났다. 다음은 자료구조로 돌아오겠다.
