토근화(Tokenization)
토큰화(Tokenization)
주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업
- 토큰(Token) : 텍스트 데이터의 의미있는 단위
토큰화에서 고려해야 할 사항
- 구두점이나 특수 문자를 단순 제외해서는 안됨
- 마침표(.)와 같은 경우는 문장의 경계를 알 수 있는데 도움이 되므로 단어를 뽑아낼 때, 마침표(.)를 제외하지 않을 수 있음
- 줄임말과 단어 내에 띄어쓰기가 있는 경우
- 예시 : New York, Los Angeles
- 표준 토큰화 예제
- 표준 토큰화 방법 : Penn Treebank Tokenization의 규칙
자연어 처리에서 사용되는 토큰 종류
1. 단어 토큰화(Word Tokenization)
토큰의 기준이 단어(word)인 경우
- 단어(word) : 단어 단위 외 단어구, 의미를 갖는 문자열
(예시) 구두점(punctuation)과 같은 문자는 제외시키는 간단한 단어 토큰화 작업
- 구두점 : 마침표(.), 컴마(,), 물음표(?), 세미콜론(;), 느낌표(!) 등과 같은 기호
입력 : Time is an illusion. Lunchtime double so!
출력 : "Time", "is", "an", "illustion", "Lunchtime", "double", "so"
- 보통 토큰화 작업은 단순히 구두점이나 특수문자를 전부 제거하는 정제(cleaning) 작업을 수행하는 것만으로 해결되지 않음.구두점이나 특수문자를 전부 제거하면 토큰이 의미를 잃어버리는 경우가 발생.
- 띄어쓰기 단위로 자르면 사실상 단어 토큰이 구분되는 영어와 달리, 한국어는 띄어쓰기만으로는 단어 토큰을 구분하기 어려움
2. 문장 토큰화(Sentence Tokenization)
토큰의 단위가 문장(sentence)인 경우
여러 문장으로 이루어진 텍스트가 있을 때, 각 문장을 독립적으로 처리하기 위해
- 마침표는 문장의 끝이 아니더라도 등장할 수 있기에 단순히 punctuation으로 구분할 수는 없음
- 예시 : IP 192.168.56.31 서버에 들어가서 로그 파일 저장해서 aaa@gmail.com로 결과 좀 보내줘. 그 후 점심 먹으러 가자.
- 한국어 경우, KSS 패키지 사용해서 문장 토큰화 가능
3. 형태소 분석(Morphological Analysis)
토큰의 단위가 형태소(언어학적으로 의미를 가지는 최소 단위)인 경우
- 한국어에서 영어에서의 단어 토큰화와 유사한 형태를 얻으려면 어절 토큰화가 아니라 형태소 토큰화를 수행해야함
- 품사 태깅(Part of speech tagging) 단어 토큰화 과정에서 각 단어가 어떤 품사로 쓰였는지를 구분
- 단어는 표기는 같지만 품사에 따라서 단어의 의미가 달라지기 때문
- 예시 : fly의 의미 두 가지, ‘날다’와 ‘파리’
4. N-gram
연속된 n개의 단어나 문자열을 하나의 토큰으로 취급
- n은 정수이며, 일반적으로 1보다 큰 값
- 모델이 텍스트의 문맥을 파악하고 단어 간의 상호 작용을 이해 가능
- 예시 "natural language processing"이라는 문장에서 2-gram을 생성 → "natural language", "language processing" 토큰 생성
정제(Cleaning) and 정규화(Normalization)
토큰화 작업 전, 후에는 텍스트 데이터를 용도에 맞게 정제(cleaning) 및 정규화(normalization)
- 정제(cleaning) : 갖고 있는 코퍼스로부터 노이즈 데이터를 제거
- 정규화(normalization) : 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어줌
정수 인코딩(Integer Encoding)
인코딩(Encoding)
사용자가 입력한 문자나 기호들을 컴퓨터가 이해할 수 있는 바이너리 형식로 만드는 것
- ASCII나 Unicode와 같은 문자 인코딩 방식
정수 인코딩(Integer Encoding)
단어에 정수 인덱스를 부여하는 과정
- 방법
- 빈도수 : 단어를 빈도수 순으로 정렬한 단어 집합(vocabulary)을 만들고, 빈도수가 높은 순서대로 차례로 낮은 숫자부터 정수를 부여
패딩(Padding)
데이터에 특정 값을 채워서 데이터의 크기(shape)를 조정하는 작업
→ 병렬 연산을 위해서 여러 문장의 길이를 임의로 동일하게 맞춰
- 제로 패딩(zero padding) : 최대 길이보다 짧은 문장은 0을 채워넣음
원-핫 인코딩(One-Hot Encoding)
단어 집합의 크기를 벡터의 차원으로 했을 때, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식
- 단어 집합(vocabulary)은 서로 다른 단어들의 집합
- 중복을 허용하지 않음
- 기본적으로 book과 books와 같이 단어의 변형 형태도 다른 단어로 간주
방법
- 정수 인코딩 수행
- 표현하고 싶은 단어의 고유한 정수를 인덱스로 간주하고 해당 위치에 1을 부여하고, 다른 단어의 인덱스의 위치에는 0을 부여
✍️ 예시 : 나는 자연어 처리를 배운다
['나', '는', '자연어', '처리', '를', '배운다']
-
정수 인코딩
단어 집합 : {'나': 0, '는': 1, '자연어': 2, '처리': 3, '를': 4, '배운다': 5}
-
표현하고 싶은 단어의 고유한 정수를 인덱스로 간주하고 해당 위치에 1을 부여하고, 다른 단어의 인덱스의 위치에는 0을 부여
‘자연어’의 경우 원-핫 인코딩으로 나타내면, [0, 0, 1, 0, 0, 0]
→ 정수 인코딩한 값이 2이므로 원-핫 벡터는 인덱스 2의 값이 1이며, 나머지 값은 0인 벡터
한계
- 단어 집합의 원소의 개수가 늘어날 수록, 벡터의 차원이 늘어남 → 원 핫 벡터는 단어 집합의 크기가 곧 벡터의 차원 수가 되기 때문
- 단어의 유사도를 표현하지 못함 → 검색 시스템 등에서는 문제가 될 소지가 있음
- 예시 : '삿포로 숙소'라는 검색어에 대해서 '삿포로 게스트 하우스', '삿포로 료칸', '삿포로 호텔'과 같은 유사 단어에 대한 결과도 함께 보여줄 수 있어야 하지만 단어간 유사성을 계산할 수 없기에 '게스트 하우스'와 '료칸'과 '호텔'이라는 연관 검색어를 보여줄 수 없음
데이터의 분리(Splitting Data)
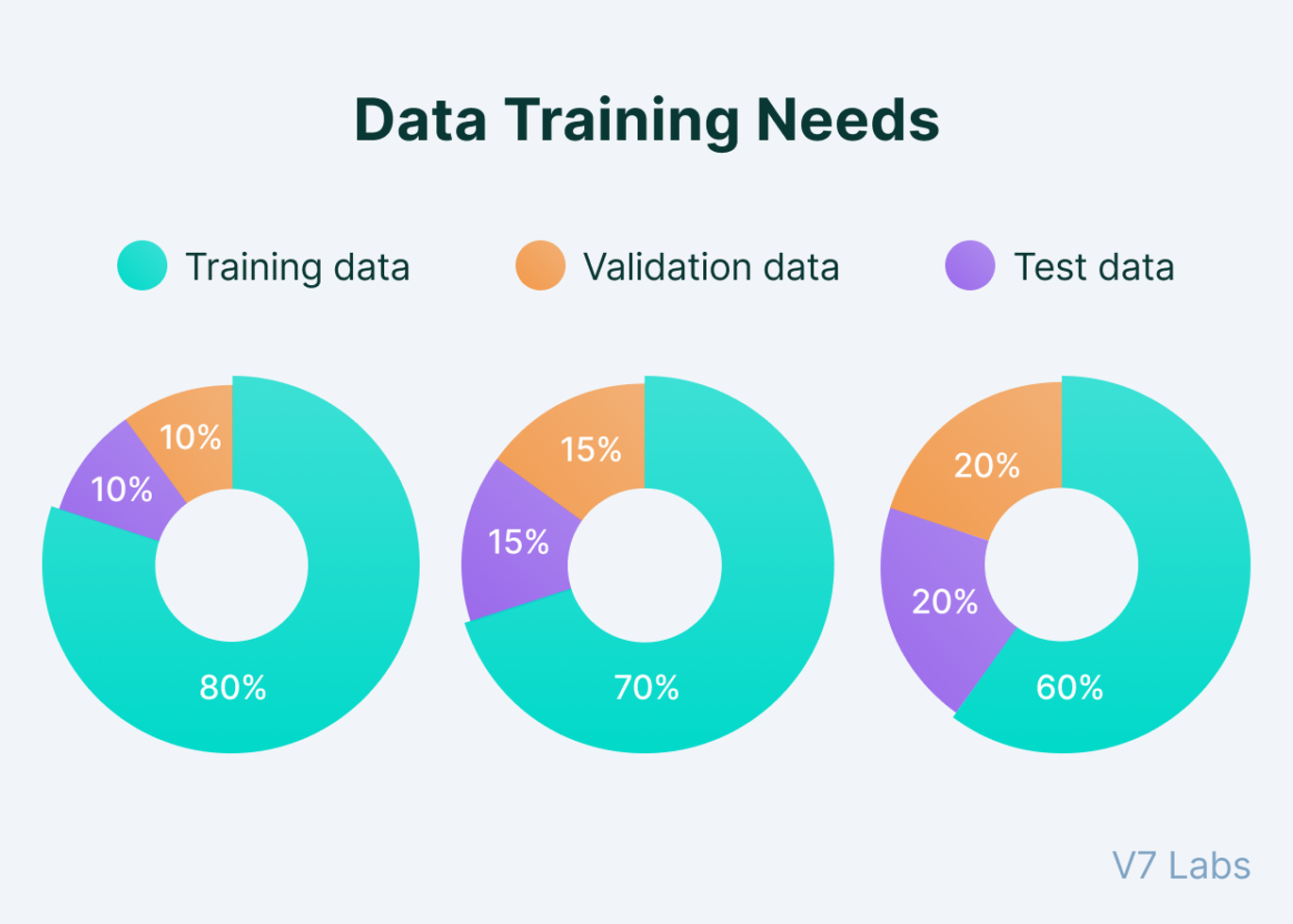
머신 러닝 모델을 학습시키고 평가하기 위해서는 train 데이터와 test 데이터를 적절하게 분리하는 작업이 필요
Reference
