언어 모델(Language Model)
단어 시퀀스(문장)에 확률을 할당(assign)하는 모델
- 가장 자연스러운 단어 시퀀스를 찾아내는 모델
- 확률 할당 방법 : 이전 단어들이 주어졌을 때 다음 단어를 예측 → 언어 모델링(Language Modeling)
언어 모델 만드는 방법
- 통계를 이용한 방법
- Statistical Language Model, SLM
- 인공 신경망을 이용한 방법
- GPT
- BERT
통계에 기반한 전통적인 언어 모델(Statistical Languagel Model, SLM)은 우리가 실제 사용하는 자연어를 근사하기에는 많은 한계가 있었고, 요즘 들어 인공 신경망이 그러한 한계를 많이 해결해주면서 통계 기반 언어 모델은 많이 사용 용도가 줄음
단어 시퀀스의 확률 할당으로 할 수 있는 일들
1. 기계번역(Machine Translation)
P(나는 버스를 탔다) > P(나는 버스를 태운다)두 문장을 비교해 좌측 문장 확률이 더 높다고 판단
2. 오타 교정(Spell Correction)
선생님이 교실로 부리나케
P(달려갔다) > P(잘려갔다)두 문장을 비교해 좌측 문장 확률이 더 높다고 판단
3. 음성 인식(Speech Recognition)
P(나는 메롱을 먹는다) < P(나는 메론을 먹는다)두 문장을 비교해 우측 문장 확률이 더 높다고 판단
→ 이렇듯 확률을 통해 보다 적절한 시퀀스를 판단
주어진 이전 단어들로 다음 단어 예측
단어 시퀀스에 확률을 할당하기 위해서 가장 보편적으로 사용하는 방법은 이전 단어들이 주어졌을 때, 다음 단어를 예측하도록 하는 것
이를 조건부 확률로 표현했을 때 다음과 같다.
단어 시퀀스의 확률
하나의 단어를 , 단어 시퀀스를 대문자 라고 한다면, 개의 단어가 등장하는 단어 시퀀스 의 확률은 다음과 같다.
다음 단어 등장 확률
n-1개의 단어가 나열된 상태에서 n번째 단어의 등장 확률
전체 단어 시퀀스의 확률은 모든 단어가 예측되고 나서 알 수 있기에 단어 시퀀스의 확률은 다음과 같다.
통계적 언어 모델(Statistical Language Model, SLM)
조건부 확률
어떤 사건이 발생했을 때 다른 사건이 발생할 확률
- 사건 B가 발생했을 때 사건 A가 발생할 확률
- 사건 B가 주어졌을 때 사건 A의 확률
조건부 확률의 연쇄 법칙(chain rule)
…
문장에 대한 확률
문장 'An adorable little boy is spreading smiles'의 확률 P(An adorable little boy is spreading smiles)를 식으로 표현하면 다음과 같다.
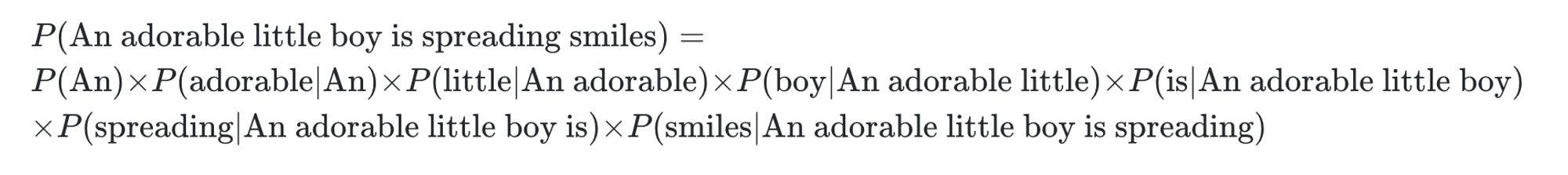
문장의 확률을 구하기 위해 각 단어에 대한 예측 확률들을 곱한다.
Count 기반의 접근
SLM은 이전 단어로부터 다음 단어에 대한 확률은 구할 때, 카운트에 기반하여 확률을 계산했다.
An adorable little boy가 나왔을 때, is가 나올 확률은 다음과 같다.
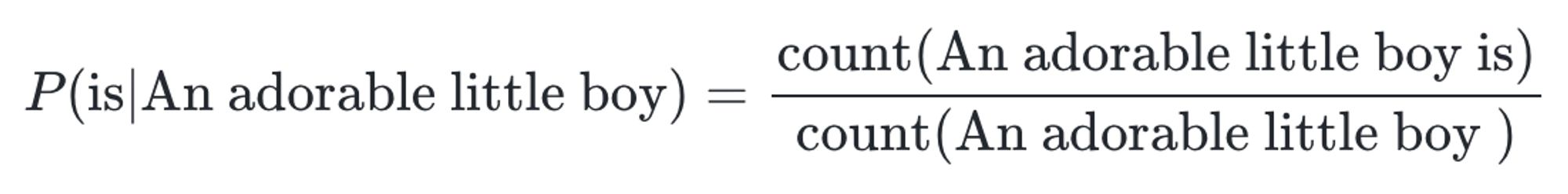
기계가 학습한 코퍼스 데이터에서 An adorable little boy가 100번 등장했는데 그 다음에 is가 등장한 경우는 30번이라고 하면 이 경우 30%의 확률이 된다.
Count 기반의 접근의 한계 : 희소 문제(Sparsity Problem)
충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제
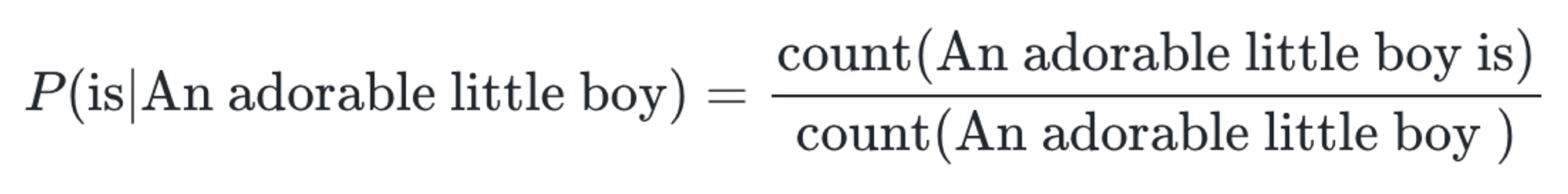
만약 기계가 훈련한 코퍼스에…
- An adorable little boy is라는 단어 시퀀스가 없었다면 이 단어 시퀀스에 대한 확률은 0이 됨
- An adorable little boy라는 단어 시퀀스가 없었다면 분모가 0이 되어 확률은 정의되지 않음
이렇듯 코퍼스에 충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제 → 희소 문제(sparsity problem)
N-gram 언어 모델(N-gram Language Model)
SLM의 일종으로 count에 기반한 통계적 접근을 사용
단, 모든 단어를 고려하는 것이 아니라 일부 단어(n개)만 고려
코퍼스에서 count하지 못하는 경우 감소
문장이 길어질수록 갖고있는 코퍼스에서 그 문장이 존재하지 않을 가능성이 높다.(aka 카운트할 수 없을 가능성이 높다)
→ 해결 방법 : 참고하는 단어들을 줄이자 !
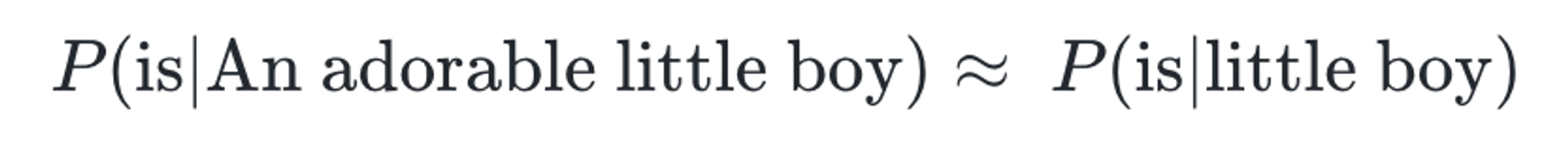
다음 단어의 확률을 구하고자 기준 단어의 앞 단어를 전부 포함해서 카운트하는 것이 아니라, 앞 단어 중 임의의 개수(n)만 포함해서 카운트하여 근사
→ 코퍼스에서 해당 단어의 시퀀스를 카운트할 확률이 높아짐
N의 크기
갖고 있는 코퍼스에서 n개의 단어 뭉치 단위로 끊어서 이를 하나의 토큰으로 간주
n-gram : n개의 연속적인 단어 나열
- n = 1일 때, 유니그램(unigram)
- n = 2일 때, 바이그램(bigram)
- n = 3일 때, 트라이그램(trigram)
- n = 4 이상일 때, gram 앞에 그대로 숫자를 붙여서 명명
다음 단어 예측 방법
다음에 나올 단어의 예측은 오직 n-1개의 단어에만 의존
예측하는 단어까지 합해서 총 n개 ! (예측하는 단어 + 이전 단어 n-1개 = n개)
'An adorable little boy is spreading' 다음에 나올 단어를 예측할 때 n = 4인 4-gram이라면, spreading 다음에 올 단어 앞의 n-1에 해당되는 앞의 3개의 단어만을 고려
An adorable little boy is spreading {?}
boy, is, spreading → n-1개의 단어
{?} → 예측할 단어 1개
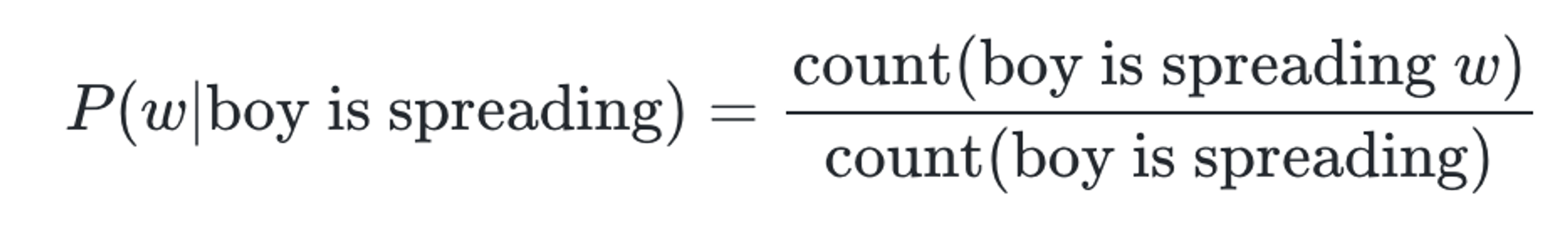
N-gram Language Model의 한계
앞의 단어 몇 개만 보다 보니 의도하고 싶은 대로 문장을 끝맺음하지 못하거나 문맥이 이상한 경우가 생김
→ 전체 문장을 고려한 언어 모델보다는 정확도가 떨어짐
-
희소 문제(Sparsity Problem)
코퍼스에서 카운트 할 수 있는 확률을 높일 수는 있었지만, 여전히 Sparsity Problem 존재
-
N의 크기에 대한 trade-off
- n을 크게 선택
- 실제 훈련 코퍼스에서 해당 n-gram을 카운트할 수 있는 확률은 적어지므로 희소 문제는 점점 심각
- n이 커질수록 모델 사이즈가 커짐 → 기본적으로 코퍼스의 모든 n-gram에 대해서 카운트를 해야 하기 때문
- n을 작게 선택
- 훈련 코퍼스에서 카운트는 잘 되겠지만 근사의 정확도는 현실의 확률분포와 멀어짐
그렇기 때문에 적절한 n을 선택해야 함. 앞서 언급한 trade-off 문제로 인해 정확도를 높이려면 n은 최대 5를 넘게 잡아서는 안 된다고 권장되고 있음
- n을 크게 선택
-
훈련에 사용된 도메인 코퍼스에 따라 성능이 비약적으로 달라짐
→ 다만 해당 도메인에서만 사용한다면 당연히 언어 모델이 제대로 된 언어 생성을 할 가능성이 높아짐
N-gram Language Model의 한계점을 극복하기위해 분모, 분자에 숫자를 더해서 카운트했을 때 0이 되는 것을 방지하는 등의 여러 일반화(generalization) 방법들이 존재
→ 본질적으로 n-gram 언어 모델에 대한 취약점을 완전히 해결하지 못해서 현재는 인공 신경망을 이용한 언어 모델이 사용되고 있음
Perplexity(PPL)
- 조금은 부정확할 수는 있어도 테스트 데이터에 대해서 빠르게 식으로 계산되는 더 간단한 평가 방
- 모델 내에서 자신의 성능을 수치화하여 결과를 내놓음
언어 모델의 평가 방법(Evaluation metric) : PPL
Perplexity
: 헷갈리는 정도
→ PPL 수치가 ⬇️ 낮을 수록 언어 모델의 성능이 ⬆️ 좋아진다
PPL 구하는 방법
Perplexity = 문장의 길이로 정규화된 문장 확률의 역수
문장()의 길이()일 때,
chain rule 적용하면,
n-gram 적용하면 bigram의 경우,
분리 계수(Branching factor)
PPL은 선택할 수 있는 가능한 경우의 수를 의미하는 분기계수(branching factor)이다.
- 이 언어 모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지를 의미 PPL이 10이 나왔다고 하면 해당 언어 모델은 테스트 데이터에 대해서 다음 단어를 예측하는 모든 시점(time step)마다 평균 10개의 단어를 가지고 어떤 것이 정답인지 고민하고 있다고 볼 수 있음
같은 테스트 데이터에 대해서 두 언어 모델의 PPL을 각각 계산 후에 PPL의 값을 비교하면, 두 언어 모델 중 PPL이 더 낮은 언어 모델의 성능이 더 좋다고 볼 수 있다.
단, PPL의 값이 낮다는 것은 테스트 데이터 상에서 높은 정확도를 보인다는 것이지, 사람이 직접 느끼기에 좋은 언어 모델이라는 것을 반드시 의미하진 않는다
