자연어 처리(NLP, Natural Language Processing)
- 자연어(natural language) : 우리가 일상 생활에서 사용하는 언어
- 자연어 처리(natural language processing) : 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일
- 예시
- 음성 인식
- 내용 요약
- 번역
- 사용자의 감성 분석
- 텍스트 분류 작업(스팸 메일 분류, 뉴스 기사 카테고리 분류)
- 챗봇
- 예시
앞으로 배울 것들
- 자연어 처리에 필요한 전처리 방법
- 딥 러닝 이전 주류로 사용되었던 통계 기반의 언어 모델
- 자연어 처리의 비약적인 성능을 이루어낸 딥 러닝을 이용한 자연어 처리
머신러닝 관련 프레임워크와 라이브러리
텐서플로우(Tensorflow)
구글이 2015년에 공개한 머신 러닝 오픈소스 라이브러리
머신 러닝과 딥 러닝을 직관적이고 손쉽게 할 수 있도록 설계
케라스(Keras)
딥 러닝 프레임워크인 텐서플로우에 대한 추상화 된 API를 제공
백엔드로 텐서플로우를 사용하며, 좀 더 쉽게 딥 러닝을 사용할 수 있게 해줌
→ 케라스를 이용해 텐서플로우 코드를 훨씬 간단하게 작성 가능
- 케라스를 직접 설치 후에 사용할 수도 있지만, 텐서플로우에서 케라스를 사용 가능
tf.keras라고 표기하여 사용
- 케라스 개발자조차 keras보다는
tf.keras를 사용할 것을 권장
젠심(Gensim)
머신 러닝을 사용하여 토픽 모델링과 자연어 처리 등을 수행할 수 있게 해주는 오픈 소스 라이브러리
사이킷런(Scikit-learn)
파이썬 머신러닝 라이브러리
- 나이브 베이즈 분류, 서포트 벡터 머신 등 다양한 머신 러닝 모듈 보유
- 머신 러닝을 연습하기 위한 아이리스 데이터, 당뇨병 데이터 등 자체 데이터 제공
주피터 노트북(Jupyter Notebook)
웹에서 코드를 작성하고 실행할 수 있는 오픈소스 웹 어플리케이션
NLTK
자연어 처리를 위한 파이썬 패키지
- NLTK의 기능을 제대로 사용하기 위해서는 NLTK Data라는 여러 데이터를 추가적으로 설치해야 함
nltk.download()코드를 실행하여 각종 패키지와 코퍼스 다운로드
KoNLPy
한국어 자연어 처리를 위한 형태소 분석기 패키지
데이터 분석을 위한 패키지
판다스(Pandas)
파이썬 데이터 처리를 위한 라이브러리
import pandas as pdPandas 데이터 구조
- 시리즈(Series)
- 1차원의 데이터를 관리하는 자료구조
- 1차원 배열의 값(values)에 각 값에 대응되는 인덱스(index)를 부여 가능, 따로 인덱스 지정해주지 않으면 자동으로 정수 인덱스 생성
- 예시
sr = pd.Series([17000, 18000, 1000, 5000], index=["피자", "치킨", "콜라", "맥주"]) print('시리즈 출력 :') print('-'*15) print(sr)# 출력 값 시리즈 출력 : --------------- 피자 17000 치킨 18000 콜라 1000 맥주 5000 dtype: int64
- 데이터프레임(DataFrame)
- 행과 열을 가지는 2차원 자료구조
- row 방향 인덱스(index)와 column 방향 인덱스(column)
- 열(columns), 인덱스(index), 값(values)으로 구성
- 데이터프레임은 리스트(List), 시리즈(Series), 딕셔너리(dict), Numpy의 ndarrays, 또 다른 데이터프레임으로부터 생성 가능
- 예시
values = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] index = ['one', 'two', 'three'] columns = ['A', 'B', 'C'] df = pd.DataFrame(values, index=index, columns=columns) print('데이터프레임 출력 :') print('-'*18) print(df)# 출력 값 데이터프레임 출력 : ------------------ A B C one 1 2 3 two 4 5 6 three 7 8 9
- 행과 열을 가지는 2차원 자료구조
- 패널(Panel)
넘파이(Numpy)
수치 데이터를 다루는 파이썬 패키지
-
Numpy의 핵심이라고 불리는 다차원 행렬 자료구조인 ndarray를 통해 벡터 및 행렬을 사용하는 선형 대수 계산에서 주로 사용
- ndarray
- Numpy의 N차원 배열 객체
- Python의 list와 다르게 하나의 데이터 타입만 넣을 수 있음(No Dynamic typing)
- C의 array와 동일
np.array()로 리스트, 튜플, 배열로 부터 ndarray를 생성
- ndarray
-
속도면에서도 순수 파이썬에 비해 압도적으로 빠름
-
- 특정한 조건이 만족한다면 모양이 다른 배열끼리도 계산할 수 있도록 배열을 자동적으로 변환하는 것
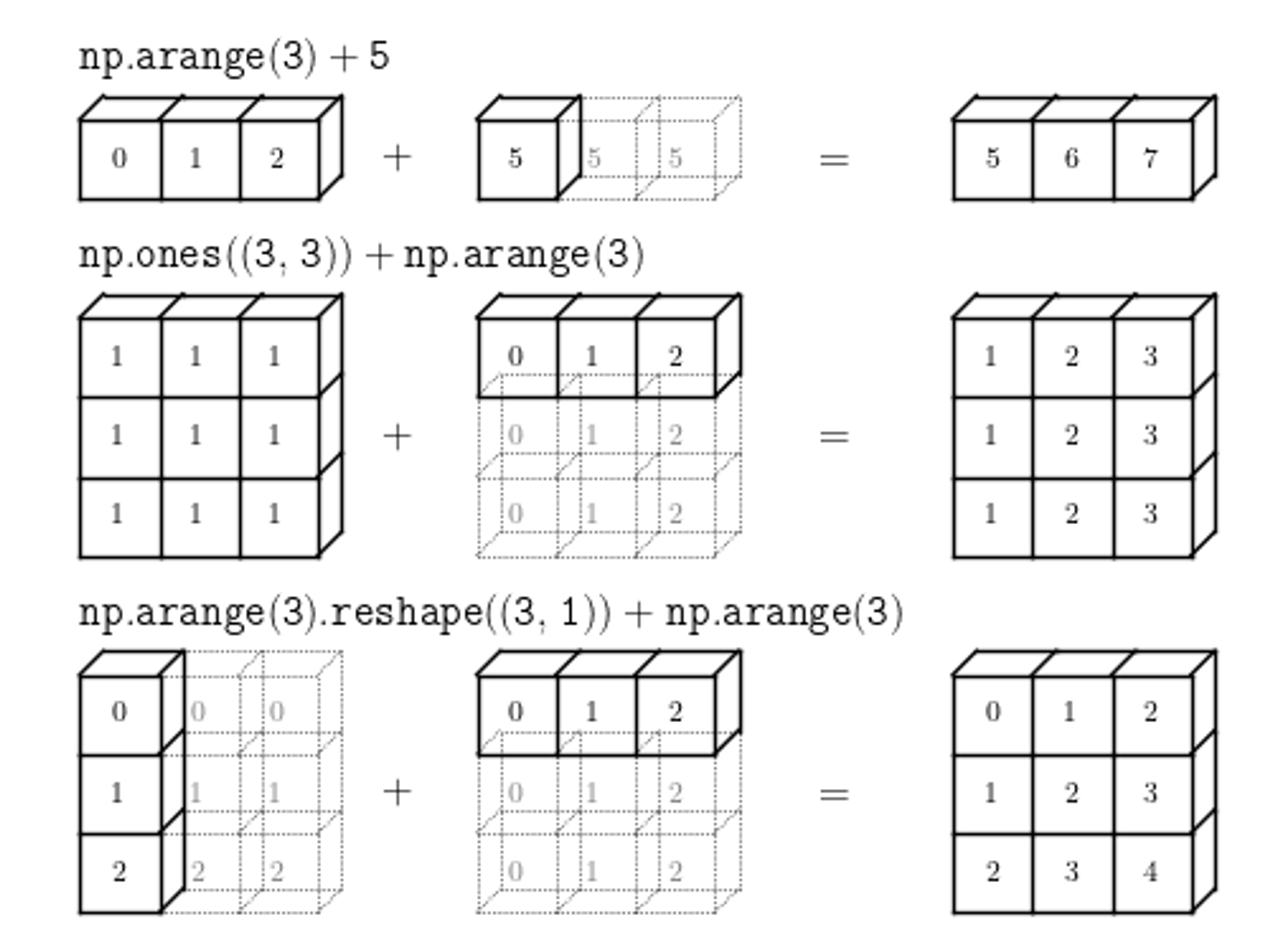
- 덕분에 저차원 배열의 연산으로 고차원 배열 생성 가능
- 브로드 캐스팅 조건
-
원소가 하나인 배열은 어떤 배열이나 브로드캐스팅 가능
-
둘 중 하나의 배열이 1차원 배열인 경우
-
차원의 짝이 맞을때 브로드캐스팅이 가능
arr1.shape = (3, 1) arr2.shape = (1, 3) np.add(arr1, arr2) # 가능
-
- 특정한 조건이 만족한다면 모양이 다른 배열끼리도 계산할 수 있도록 배열을 자동적으로 변환하는 것
맷플롯립(Matplotlib)
데이터를 차트(chart)나 플롯(plot)으로 시각화하는 패키지
머신 러닝 워크플로우(Machine Learning Workflow)
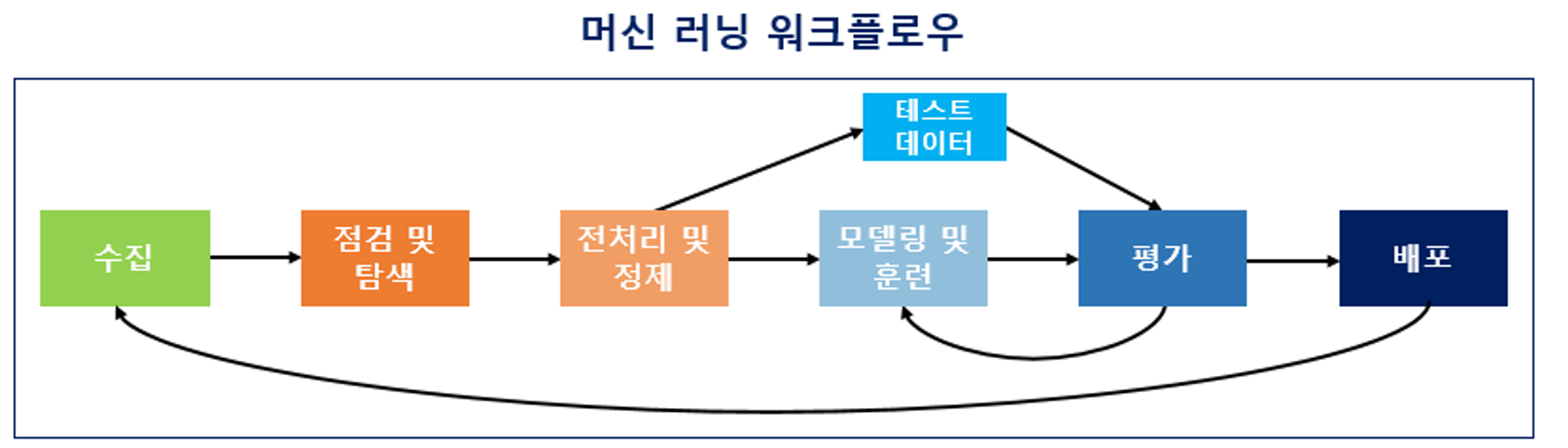
1) 수집(Acquisition)
기계에 학습시켜야 할 데이터 수집
- 자연어 처리의 경우 데이터를 말뭉치 또는 코퍼스(Corpus)라고 함 Corpus : 조사나 연구 목적에 의해서 특정 도메인으로부터 수집된 텍스트 집합
- 텍스트 데이터의 파일 형식은 txt 파일, csv 파일, xml 파일 등 다양하며 그 출처도 음성 데이터, 웹 수집기를 통해 수집된 데이터, 영화 리뷰 등 다양함
2) 점검 및 탐색(Inspection and exploration)
수집한 데이터를 점검하고 탐색
- 데이터의 구조, 노이즈 데이터, 머신 러닝 적용을 위해서 데이터를 어떻게 정제해야하는지 등을 파악
- 탐색적 데이터 분석(Exploratory Data Analysis, EDA) 단계라고도 함 독립 변수, 종속 변수, 변수 유형, 변수의 데이터 타입 등을 점검하며 데이터의 특징과 내재하는 구조적 관계를 알아내는 과정. 시각화와 간단한 통계 테스트를 진행하기도 함
3) 전처리 및 정제(Preprocessing and Cleaning)
머신 러닝 워크플로우에서 가장 까다로운 작업 중 하나인 데이터 전처리 과정
- 자연어 처리에서의 데이터 전처리 단계
- 토큰화
- 정제
- 정규화
- 불용어 제거 등
- 빠르고 정확한 데이터 전처리를 하기 위해서는 사용하고 있는 툴의 다양한 라이브러리에 대한 지식이 필요
- 정말 까다로운 전처리의 경우에는 전처리 과정에서 머신 러닝이 사용되기도 함
4) 모델링 및 훈련(Modeling and Training)
Modeling(모델링) → 전처리한 데이터를 가지고 Training(학습 aka 훈련)
-
Modeling(모델링)
- 머신 러닝에 대한 코드를 작성하는 단계
- 적절한 머신 러닝 알고리즘을 선택
-
Training(학습 aka 훈련)
-
전처리가 완료 된 데이터를 머신 러닝 알고리즘을 통해 기계에게 학습
-
학습과 훈련 두 용어를 혼용해서 사용
-
데이터 중 일부는 테스트용으로 남겨두고 훈련용 데이터만 훈련에 사용해야함

- 기계가 학습을 하고나서, 테스트용 데이터를 통해서 현재 성능이 얼마나 되는지를 측정 가능
- 과적합(overfitting) 상황을 막을 수 있음
- 최선은 훈련용, 테스트용으로 두 가지만 나누는 것보다는 훈련용, 검증용, 테스트용으로 데이터를 세 가지로 나누고 훈련용 데이터만 훈련에 사용하는 것
-
5) 평가(Evaluation)
테스트용 데이터로 성능 평가
- 평가 방법 기계가 예측한 데이터가 테스트용 데이터의 실제 정답과 얼마나 가까운지를 측정
6) 배포(Deployment)
평가 단계에서 기계가 성공적으로 훈련이 된 것으로 판단된다면 완성된 모델이 배포
피드백을 통해 모델을 업데이트 해야하는 상황이 온다면 수집 단계로 돌아감
Reference
