카운트 기반의 단어 표현(Count based word Representation)
정보 검색과 텍스트 마이닝 분야에서 주로 사용
Count based word Representation 방법
- DTM
- TF-IDF
위 방법으로 수치화하여 통계적 접근방법으로 아래와 같은 작업을 할 수 있다.
- 특정 문서 내에 어떤 단어가 얼마나 중요한 지 나타내기
- 핵심어 추출
- 검색 엔진에서 검색 결과 순위 결정
- 문서들 간의 유사도 계산
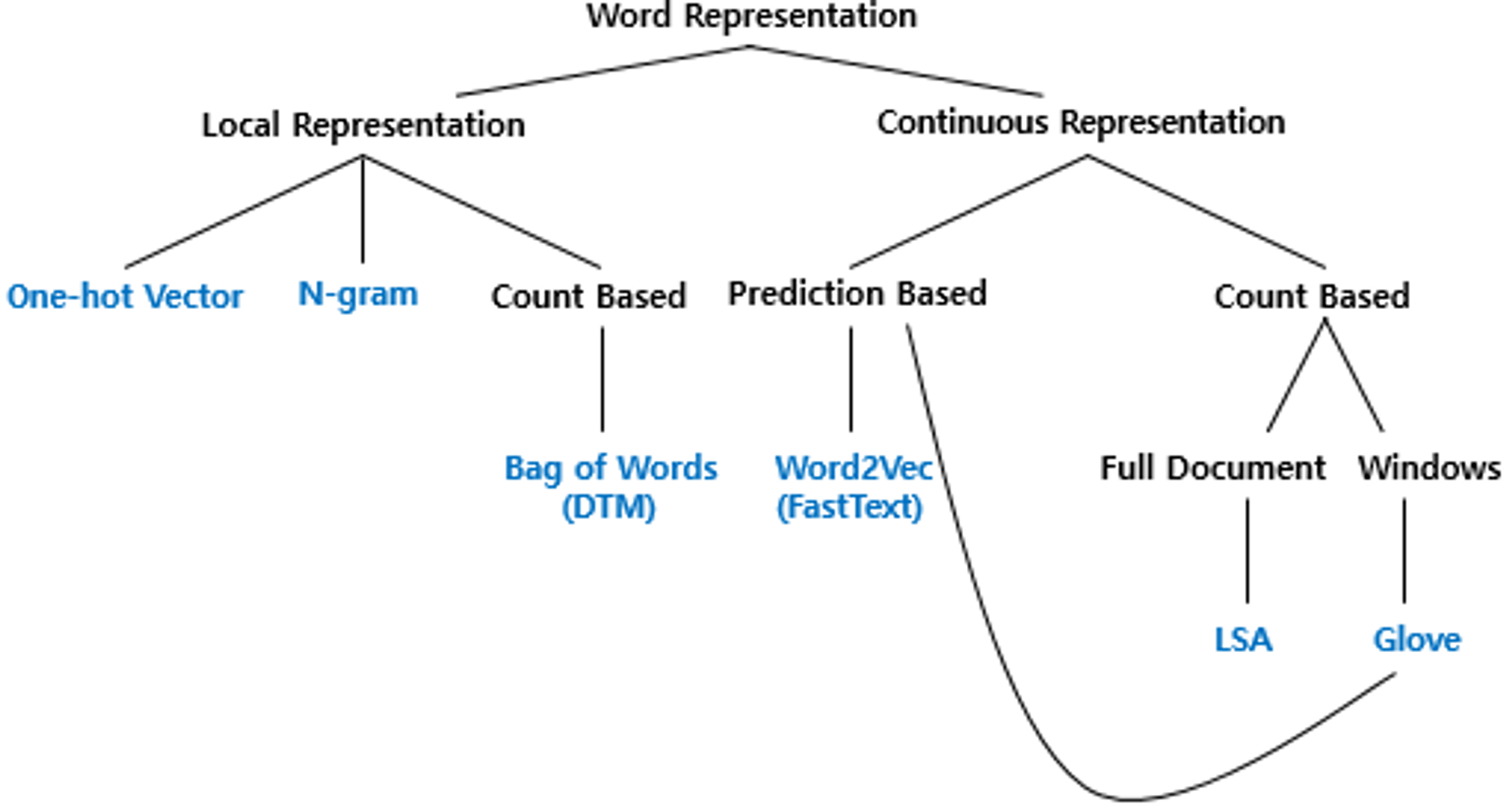
단어 표현 방법
크게 단어 표현 방법을 두 가지로 나눌 수 있는데 다음과 같다.
- Local Representation (aka Discrete Representation) : 해당 단어 자체만 보고, 특정값을 맵핑해서 단어 표현
- Distributed Representation (aka Continuous Representation) : 해당 단어 주변을 참고해 단어 표현 → Local Representation과 달리 단어의 뉘앙스 표현 가능
단어 표현 방법 종류
Bag of Words(BoW)
단어의 등장 순서를 고려하지 않는 Count 기반 단어 표현 방법
Bag of Words(BoW)란?
단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법
- 예시 "정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다.” 라는 시퀀스가 주어졌을 때,
vocabulary : {'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9} bag of words vector : [1, 2, 1, 1, 2, 1, 1, 1, 1, 1]
Vectorize(벡터화)
벡터화(Vectorize)는 자연어를 컴퓨터가 이해할 수 있도록 표현해주는 것이다
자연어를 어떻게 벡터로 표현할 것인 지는 자연어 처리 모델의 성능에 지대한 영향을 미치므로 상당히 중요하다.
문서 단어 행렬(Document-Term Matrix, DTM)
다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것
- 행(row) : 문서
- 열(column) : 단어
→ 각 문서에 대한 BoW를 하나의 행렬로 만든 것
| 과일이 | 길고 | 노란 | 먹고 | 바나나 | 사과 | 싶은 | 저는 | 좋아요 | |
|---|---|---|---|---|---|---|---|---|---|
| 문서1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 문서2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| 문서3 | 0 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 |
| 문서4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
DTM의 한계
-
희소 표현(Sparse representation)
= 희소 벡터(sparse vector) or 희소 행렬(sparse matrix) 특징
- 많은 문서 벡터의 대부분의 값이 0을 가짐
- 전체 코퍼스가 방대하다면 문서 벡터의 차원이 수만 이상 → 원-핫 벡터와 마찬가지로 전제 단어 집합의 크기가 각 문서의 벡터의 차원이 됨
많은 양의 저장 공간과 높은 계산 복잡도 요구
→ 불용어 제거, 단어 정규화 같은 텍스트 전처리 방법으로 단어 집합의 크기 줄이는 노력 필요
-
단순 빈도 수 기반 접근
단순히 빈도 수를 비교하기 때문에 불용어 같은 의미 없는 단어들의 빈도수를 기반으로 문서들이 유사하다는 판단을 내릴 수 있음
→ 불용어와 중요한 단어에 대한 가중치를 다르게 주는 노력 필요
: TF-IDF(Term Frequency-Inverse Document Frequency) 등장
TF-IDF(Term Frequency-Inverse Document Frequency)
DTM 내에 있는 각 단어에 대한 중요도를 계산할 수 있는 가중치
- 보다 많은 정보 고려해 문서들 비교
- 대부분 TF-IDF가 DTM보다 좋은 성능을 가짐 → 하지만 항상 그렇진 않음
TF-IDF 계산식
문서를 , 단어를 , 문서의 총 개수를 이라고 표현할 때 TF, IDF는 각각 다음과 같이 정의
TF (Term Frequency, 단어 빈도) :
특정 문서 에서의 특정 단어 의 등장 빈도
: 특정 문서 내에서 특정 단어가 얼마나 자주 나타나는지
tf(d, t) = (특정 단어 t의 문서 d 내 등장 횟수) / (해당 문서 d 내 총 단어 수)DF(Document Frequency, 문서 빈도) :
특정 단어 의 등장한 문서 수
: 특정 단어가 얼마나 다른 문서에서 자주 나타나는지
IDF(Inverse Document Frequency, 문서 빈도의 역수) :
log를 사용하는 이유
- log를 사용하지 않으면 총 문서의 수 n이 커질 수록, IDF의 값은 기하급수적으로 커짐
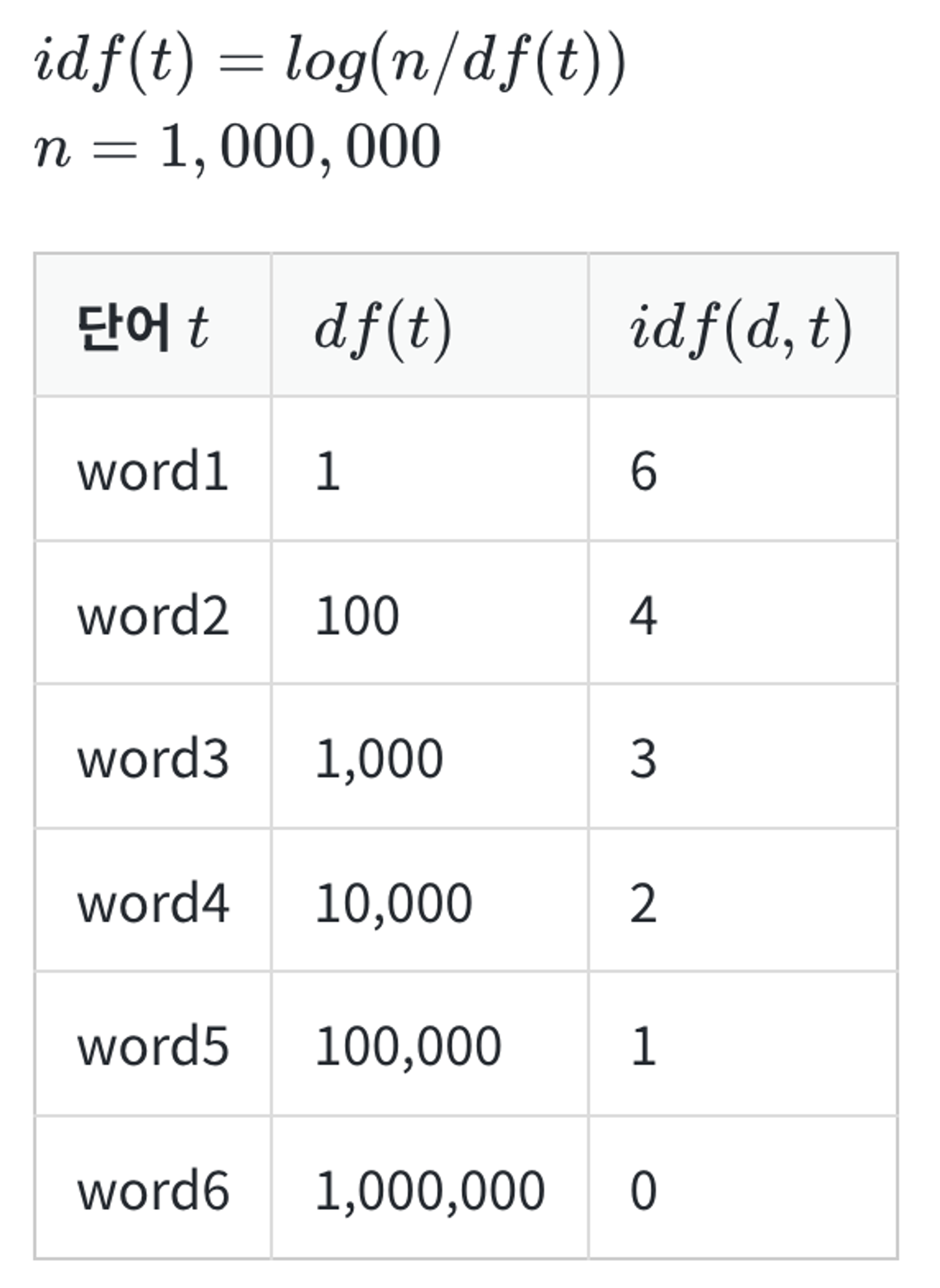
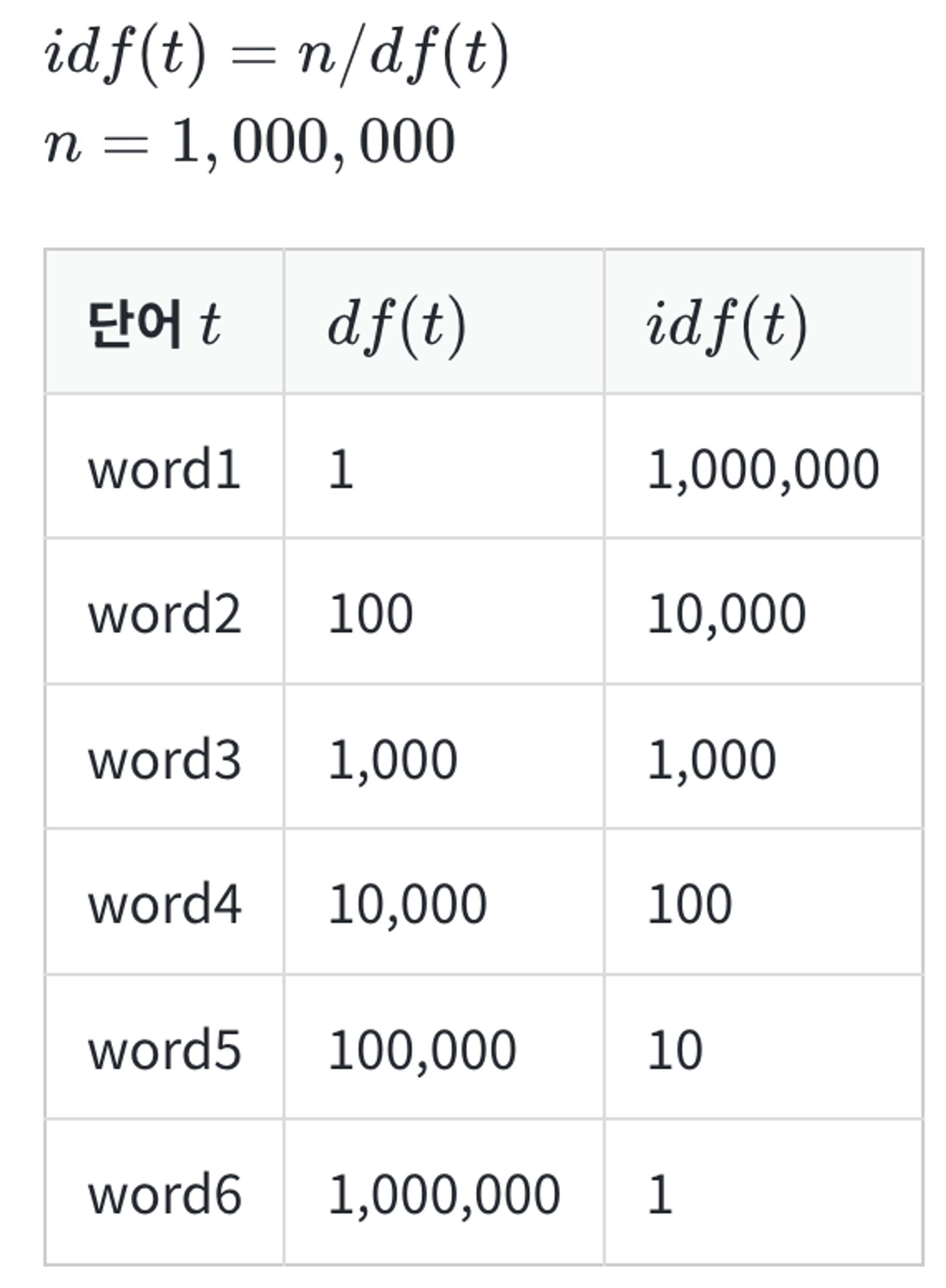
- 불용어처럼 자주 쓰이는 단어들과 희귀 단어들의 가중치 격차를 줄이기 위해
모든 문서에서 자주 등장하는 단어(like 불용어)는 중요도가 낮다고 판단하며, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단
