벡터 연산
- 요소들에 대한 연산을 벡터 연산으로 처리하면
- 일반적인 for반복문으로 연산 작업을 처리 하는 것보다 월등히 뛰어난 처리 속도로 효율적인 작업 가능
import numpy as np
# 0부터 시작하여 100000000개 요소를 가진 배열 생성
x = np.arange(100000000)
x
%%time
# 해당 셀을 수행하는데 소요된 시간을 표기해주는 주피터 노트북 명령어
# 셀의 가장 상단에 위치해야함 ( 주석 포함해서 가장 상단에 위치해야함.)
# 반복문을 통한 합계(x변수에 저장한 넘파이 배열 지표 총합 구하기)
# 시간단위 : 1s = 1,000ms(밀리세컨드) = 1,000,000㎛(마이크로세컨드)
loop_result = 0
for i in x:
loop_result += i
print(loop_result)
%%time
# 벡터연산(넘파이명령어)를 통한 합계 연산
np.sum(x)
%%time
x.sum()
(참고) 파이썬은 성능이 안좋은 언어축에 속한다.인터프리터 언어라서. 자바나 c언어 같은 컴파일언어가 빠름
배열 정렬
arr.sort(axis=-1), np.sort(axis=-1), np.argsort(arr)
- sort(axis = -1) 메서드 : axis를 기준으로 요소를 오름차순 정렬
- 기본값(axis = -1) : 현재 배열의 마지막 axis
- axis = 0 : 열 단위 정렬
- axis = 1 : 행 단위 정렬
- 원본 객체에 정렬 결과가 반영됨
- np.sort(axis = -1) : axis를 기준으로 요소를 오름차순 정렬
- 기본값(axis = -1) : 현재 배열의 마지막 axis
- axis = 0 : 열 단위 정렬
- axis = 1 : 행 단위 정렬
- 정렬된 새로운 배열을 반환함
- np.argsort(arr) : 정렬 순서를 반환
- 기본값(axis = -1) : 현재 배열의 마지막 axis
- axis = 0 : 열 단위 정렬
- axis = 1 : 행 단위 정렬
# 1차원 배열 생성
x = np.arange(0, 5)
np_print(x)
# 기본 파이썬 문법으로 순번 뒤집기
x[::-1]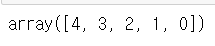
# 난수 패턴 고정
np.random.seed(20)# 오름차순 정렬
a = np.random.randint(0, 10, 5)
np_print(a)
# 1. np.sort(자료) -> 원본에 반영되진 않음
np.sort(a)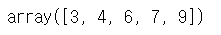
a
# 2. arr.sort() -> 원본 자료 변경
a.sort()
a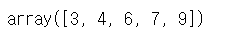
a
b = np.random.randint(0, 10, 5)
np_print(b)
# np.argsort(자료)는 내부의 아이템들을 오름차순으로 정렬하기 위해서
# 현재 몇 번 인덱스에 있는 자료를 어디에 배치해야 하는지 보여줌
np.argsort(b)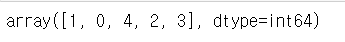
# 0이상 1미만의 범위에서 무작위로 실수값을 가지는 3행 3열의 배열 2개 생성
a = np.random.random((3, 3))
b = np.random.random((3, 3))
np_print(a)
np_print(b)
##### 예) 2차원 배열의 경우
기본값 axis = -1 <br>
현재 배열의 axis = 0, 1 <br>
마지막 axis = 1 (행별 정렬)
# 기본 방향(aixs = -1) -> 행별 정렬
np_print(a)
np.sort(a)

# 열별_정렬
np_print(a)
np.sort(a, axis=0)
인덱싱(Indexing), 슬라이싱(Slicing)
1. 인덱싱 : 하나의 요소에 대해 참조
- 각 차원에 따라 배열이 참조하는 인덱스의 개수가 다름
- 1차원 배열 : 인덱스 1개
- 2차원 배열 : 인덱스 2개
- 3차원 배열 : 인덱스 3개
- 인덱싱으로 참조한 요소에 대해 수정 가능
- 인덱스 배열을 전달하여 여러 개의 요소 참조
# 0부터 23까지 1씩 증가하는 값을 아이템으로 가지는 1차원 배열 생성
arr1 = np.arange(0, 24)
np_print(arr1)
# 1차원 배열 인덱싱 : 1번 인덱스 요소 접근
arr1[1]
# 1차원 배열 인덱싱 : 마지막 요소 접근
arr1[-1]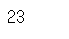
# 1차원 배열 인덱싱을 통한 값 수정
arr1[-1] = 100
arr1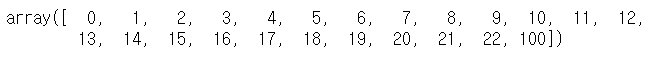
# 배열 arr1을 이용해 4 x 6 형태의 2차원 배열 arr2 만들기
arr2 = arr1.reshape(4, 6)
np_print(arr2)
# 2차원 배열 인덱싱 : 2차원배열[행인덱스, (열인덱스)]
# 하나의 행에 접근 : 1행
arr2[0]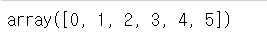
arr2[1][3]
# 하나의 열에 접근 : 모든 행에 대해서 하나의 열에 접근
# 반환값 : 1d array
arr2[:, 1] # (0, 1)(1, 1)(2, 1)(3, 1)값을 지정함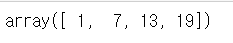
# 하나의 값에 접근
print(arr2[2][2])
print(arr2[2,2])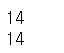
# 여러개의 행 조회
arr2[[0, 3]]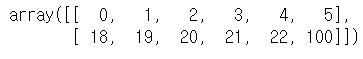
# 여러개의 열 조회
arr2[:, [0, 2]]
# quiz : 0번째, 2번째 로우의 3번째, 5번째 컬럼을 가져오도록 처리해보세요
arr2[[0, 2]][:,[3, 5]]
# 2차원 배열 인덱싱을 통한 값 수정
# 하나의 행/열에 대해 모두 동일한 값으로 수정 : 전달하는 값을 스칼라값으로 전달
# 서로 다른 값으로 수정 : 배열 구조에 맞춰서 자료 전달
# 하나의 값을 수정하는 예시
arr2[2] = 9
arr2
# 단일 값이 아닌 여러 값을 대입하고 싶을때는
arr2[1] = [9, 9, 9, 99, 99, 99]
arr2
np_print(arr2)
# 3차원 배열 생성
# 구조 : 2개의 층(페이지, 면), 4행 3열
# np.arange() => 24개의 size
arr3 = np.arange(0, 24).reshape(2, 4, 3)
np_print(arr3)
# 3차원 배열 인덱싱 : arr[면, 행, 열]
# 0번째 면(페이지)에 접근
arr3[0]
# quiz 첫 번째(0) 면, 1번 행에 접근
arr3[0][1]
# 첫 번째 면, 1번 행, 0번 열에 접근
arr3[0, 1, 0]
# 3차원 배열 역시 배열 인덱싱으로 값 수정이 가능하다
# 스칼라 연산을 통한 동일한 값으로 수정
# arr3의 2번면(1번 인덱스)를 0으로 일괄 변경해주세요.
arr3[1]=0
arr3
# 하나의 면에 대해 서로 다른 값으로 수정 : 1번면, 1번행을 [1, 2, 3]으로 바꿔주세요.
arr3[0,0]=[1, 2, 3]
arr3
# 아니면 아예 3 * 4형식으로 대입을 해버리는 방법도 있습니다.
arr3[0]=[[ 10, 20, 30],
[ 40, 50, 60],
[ 0, 0, 0],
[ 0, 0, 0]]
arr3
# 인덱스 배열을 전달하여 여러 개의 요소 참조
# (기존 인덱싱 방법) 0번째 장 0행 0열, 1행, 1열, 2행 2열 요소에 접근
arr3[0, 0, 0] # 10
#arr3[0, 1, 1] #50
#arr3[0, 2, 2] #0# 여러 개의 인덱싱을 배열로 전달
# (행0, 형0), (행1, 열1), (행2, 열2)
# 3차원 배열일 경우에 : [페이지, [[0, 1, 2], [0, 1, 2]]]
# arr3[면, 행, 열]-> 만약 여러 단위를 조회할때는 이중리스트로 입력
# 삼중리스트 입력시 이중리스트 요소를 반복
arr3[0, [[0, 1, 2], [0, 2, 3]]] # 0번째 면에서 0, 1, 2행과 0, 2, 3행 접근
arr3[:, [0, 1, 2]] # 0번째 면에서 0, 1, 2행에 접근, 1번째 면에서 0, 1, 2행에 접근
2. 슬라이싱 : 여러 개의 요소에 대해 참조
- axis 별로 범위 지정
- from_index : 시작 인덱스(포함), 0일 경우 생략 가능
- to_index : 종료 인덱스(미포함), 마지막 인덱스일 경우 생략 가능
- step : 연속되지 않은 범위의 경우 간격 지정
- 열만 조회하는 경우 : 전체 행에 슬라이싱으로 접근 후 특정 열을 조회
# 0부터 23까지 1씩 증가하는 정수값을 1차원 배열 생성
a = np.arange(0, 24)
np_print(a)
# 1차원 배열 슬라이싱 : 1번부터 4번까지 접근
a[1:5]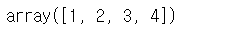
# 1번째 인덱스로부터 14번째 인덱스까지 2개씩 건너뛰면 접근
a[1:15:2]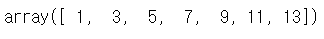
# 2차원 배열 생성
b = a.reshape(6,4)
np_print(b)
# 2차원 배열 슬라이싱 : 1행부터 4행까지 접근
# 2d_array[행(:열:간격)]
b[0:4]
# 1행부터 4행에 대해서, 2열부터 3열까지 접근
b[1:5,2:4]
# 2차원 배열 슬라이싱을 통한 값 수정
# 1행부터 4행에 대해 2열부터 3열까지의 모든 배열에 대해서 수정
s_arr = b[1:5,2:4]
s_arr
# 0번째 행과 마지막 열을 제외한 모든 값을 99로 수정
s_arr[1:, 0] =99 # s_arr[1:, :-1] =99
s_arr
# 얕은복사로 인한 원본배열의 변경
# 슬라이싱으로 뽑아와도 얕은 복사로 취급돼 원본인 b가 변경된다
b
# 2차원 배열 슬라이싱 : 연속되지 않은 범위의 열에 대한 인덱싱
# step1. 전체 행에 대해서 접근
# step2. 여러 개의 열 인덱싱 배열 전달
# b의 전체 행 +1, 3번째 열
# b[행, 열]
b[:, (1,3)]
연습문제
아래 정보는 학생들의 학번, 영어 성적, 국어 성적, 수학 성적 정보 입니다.
해당 정보를 첫번째 행(row)에 학번, 두번째 행에 영어 성적, 세번째 행에 국어 성적, 네번째 행에 수학 성적을 저장한 배열로 만들고 학생별로 영어 성적을 오름차순 기준으로 각 열(column)을 정렬하세요.
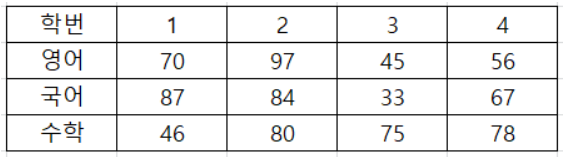
data = [[1, 2, 3, 4],
[70, 97, 45, 56],
[87, 84, 33, 67],
[46, 80, 75, 78]]
arr = np.array(data)arr.argsort()
내가짠코드
arr[:,(1, 0, 3, 2)]
# 영어에 해당하는 부분에 argsort()를 걸면 해당 자료들을 어디 배치해야 할지 나옵니다
# 그 인덱스 번호르 전체 행에 적용하시면 됩니다.
i = np.argsort(arr[1])
i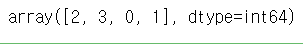
arr[:, i]
조건 색인(Boolean Indexing)
- 배열의 요소에 대해 조건을 적용하여 True, False로 조건에 대한 결과 반환
- True에 해당하는 요소만 조회하여 조건을 만족하는 결과 반환
- 많이 쓰이는 기능!!!
b
# 스칼라 연산을 이용해 10보다 큰 요소 조회하기
b > 10
# 조건색인 방법
# 자료[자료를 포함한 조건식]
b[b>10]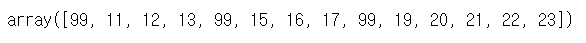
b[b>10].size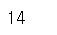
# 조건색인을 이용해 b에서 짝수인 자료만 남겨보세요
# 조건색인에 2개 이상의 조건을 걸고 싶을때는 각 조건 하나하나마다 ()로 감싸주고
# 조건사이를 and인 경우 &로, or인 경우는 |로 연결해준다.
b[(b % 2 == 0) & (b != 0)]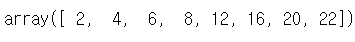
연습문제
조건색인을 활용해 공무원시험의 합격자 평균을 구해주세요.
합격점수는 60점 이상입니다.
아래는 시험 점수 결과입니다.
[31, 30, 55, 34, 83, 75, 86, 60, 94, 80, 42, 37, 73, 80, 30, 65, 34,
55, 56, 51]
score = np.array([31, 30, 55, 34, 83, 75, 86, 60, 94, 80, 42, 37, 73, 80, 30, 65, 34, 55, 56, 51])
score[score>=60].mean()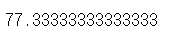

파이썬초짜의 기록