Pandas
- 데이터 처리 및 분석을 위한 라이브러리
- 대용량 데이터를 안정적이면서도 간편하게 처리
- 서로 다른 데이터타입으로 열을 구성할 수 있음
(참고) Numpy : 전체 배열 원소를 동일한 타입으로 제한 - 주요 기능
- 데이터 입출력 : csv, excel, RDB, JSON 등 다양한 포맷의 데이터를 효율적으로 처리할 수 있는 형식을 사용
- 데이터 가공 : 분리, 결합, 계층, 피봇 등
- 통계 분석 처리
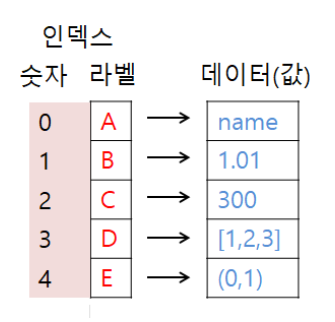
Series자료형
- Series
- 1차원 배열과 유사한 자료형
- 색인(index) : 행 번호
- 각각의 데이터에 부여하는 속성으로 기본값은 0부터 1씩 증가하는 숫자 지정
- index 파라미터를 통해 새로운 값으로 변경 가능
- 리스트, 튜플 타입으로 새로운 값을 전달해야하며 다차원 자료형은 사용할 수 없음
- 전달하는 색인의 개수와 데이터의 개수가 일치해야 함
- 각각의 색인과 데이터가 매핑되어 있으므로 dictionary 자료형과 유사
- 여러 가지 데이터 타입 사용 가능
# pandas 라이브러리 및 Series, dataFrame 네임스페이스 불러오기
import pandas as pd
# Series 생성
pd.Series()
Series 생성
- 하나의 값(숫자, 문자) 또는 자료형(리스트, 튜플, np 배열)으로 데이터 전달
Series 속성
- 속성은 소괄호를 붙이지 않음
- index : series 객체의 인덱스 배열을 반환
- values : series 객체의 데이터(값) 배열을 반환
- name : series 객체의 이름을 반환
- dtype : series 객체의 데이터 타입을 반환
- size : series 객체의 데이터 개수(길이)를 반환
- shape : series 객체의 구조(행, 열, 차원)를 반환
1-1) 숫자 Series 생성
# 숫자 10을 데이터로 가지고 있는 Series
# 결과 해석
# 왼쪽 0 = 자동으로 생성되는 기본 인덱스 번호(0부터 시작)
# 오른쪽 10 = 입력한 데이터 값
s1 = pd.Series(10)
s1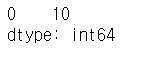
# 값을 얻을때는 인덱싱이나 슬라이싱을 활용함
s1[0]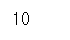
# 데이터 내부에 저장된 값 확인
s1.values
# 인덱스 번호 확인
# RangeIndex : 기본적으로 생성되는 인덱스번호를 사용하는 경우 부여
s1.index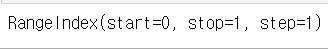
1-2) 문자 Series 생성
# 문자
s2 = pd.Series('abc')
s2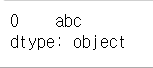
# 데이터 확인
s2.values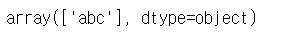
# 인덱스 확인
s2.index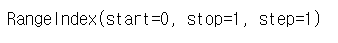
1-3) 리스트 Series 생성
# 리스트 자료형
s3 = pd.Series([10, 20, 30])
s3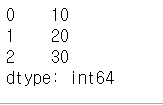
# 데이터 확인
s3.values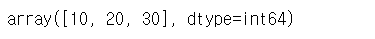
# 인덱스 확인
# 0이상 3미만의 RangeIndex : 0, 1, 2
s3.index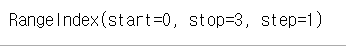
# 데이터 타입이 서로 다른 리스트 자료형
s4 = pd.Series([10.3, 'test', 200, [1, 2, 3]])
s4
# 데이터 확인
s4.values
# 인덱스 확인
s4.index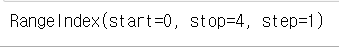
1-4) 딕셔너리 Series 생성
# 딕셔너리 자료형(자동으로 라벨 부여, key가 index, value가 실제 데이터)
s5 = pd.Series({'a':10, 'b':20, 'c':30})
s5
# 데이터 확인
s5.values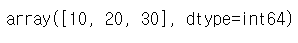
# 인덱스 확인
s5.index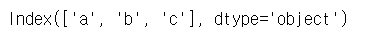
# 숫자인덱스도 병행해서 사용 가능
s5[0]
s5['a']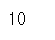
# 인덱스 새롭게 지정하기
# 인덱스 속성(길이)을 참조하여 리스트, 튜플 타입으로 전달
# 라벨 인덱스가 없던 경우 => 새롭게 라벨 인덱스 부여
# 라벨 인덱스가 있던 경우 => 기존에 있던 라벨 인덱스에 덮어씌우기
s5.index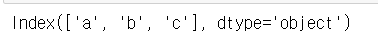
1-5) 튜플 Series 생성
# 튜플로도 생성 가능
s6 = pd.Series((1, 2, 3, 4, 5.0))
s6
# 인덱스를 새롭게 지정할때는 RangeIndex 범위만큼 길이를 가지는 리스트를 사용
# 행 개수 (데이터 개수)와 동일한 길이를 전달해야 한다.
s6.index =[2018, 2019, 2020, 2021, 2022]
s6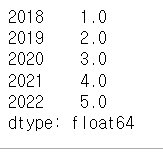
# 인덱스를 지정하여 객체 생성
# 인덱스 객체에 대해서 아이템 참조는 가능
s6.index[3]
s6[2018]
# 인덱스 객체 내부의 단일 라벨 인덱스만 수정하는 것은 불가능
s6.index[-1] = 2023
Series 인덱스 라벨링
# 인덱스 라벨링 수정시 전체 인덱스를 대입해줘야 한다
s6.index = [2018, 2019, 2020, 2021, 2023]
s6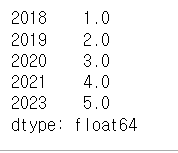
# 딕셔너리 없이 시리즈에 라벨인덱스를 부여하고 싶은 경우
# Series() 생성시 index를 파라미터로 줘서 처리할 수 있음
#pd.Series(data, index=[])
s7 = pd.Series([10, 20, 30, 40], index=['mon', 'tue', 'wed', 'thur'])
s7
s7.values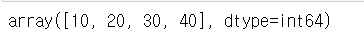
s7.index
# 자동 부여된 숫자 인덱스도 여전히 사용 가능
s7[3]
s7['thur']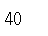
dictionary 자료형과 유사한 Series 자료형
# dictionary 자료형으로 Series 생성
data = {'서울':100, '경기':200, '강원':300, '부산':400}
sample = pd.Series(data)
print(data)
print(sample)
# Series 객체와 in 연산자
# dictionary와 유사 : in 연산자를 사용해 내부 요소 검사시
# key값에 해당하는 라벨을 이용해 해당 요소가 있는지 없는지 여부를 True,False로 출력
print('서울' in data) # 딕셔너리 자료형
print('서울' in sample) # Series 자료형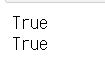
# for문에서 in연산자로 접근 : Series의 value값을 참조
for key in data:
print(key)
print("--------------")
for value in sample.values:
print(value)
# 서울, 경기, 강원, 부산 => 서울, 경기, 강원, 제주로 라벨 인덱싱 변경
# 지정한 index 기준으로 Series 생성
# 사용하는 인덱스에 없는 값은 Series에 NaN값으로 저장
# NaN : Not a Number(결측치) -> numpy에서 해당 위치가 비었음을 의미하는 자료 (null)
# None : 파이썬 기본 자료형에서 값이 없음을 의미하는 자료
index2 = ['서울', '경기', '강원', '제주']
sample2 = pd.Series(data, index=index2)
sample2
인덱싱(Indexing)
- 하나의 특정 값을 선택하거나 변경
- 참조하는 인덱스 : 기본 숫자 인덱스, 라벨 인덱스
- 새로운 인덱스를 설정해도 기본 숫자 인덱스 사용가능
s6_data = {'a':10, 'b':20, 'c':30}
s6 = pd.Series(s6_data)
s6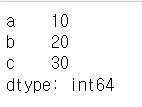
# Series s6의 첫 번째 데이터 =>인덱스 0으로 조회
# Series객체 [인덱스번호 or 라벨숫자]
print(s6.index[0]) #인덱스의 0번째는 'a'
print(s6[0]) #s6자체의 0번째 자료는 10
# Series s6의 인덱스 a에 매칭된 데이터 조회
s6['a']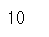
# 요일 - 자료 매칭 데이터 조회
s7
# Series s7의 인덱스 tue에 해당하는 데이터 값을 변경
# 인덱스(라벨링)은 개별적으로 하나하나 변경 불가능
# 인덱스에 매칭된 데이터는 개별 데이터별 변경 가능
s7['tue'] = 700
s7
# 시리즈에서 원하는 로우(행)만 조회하기 : 조회할 로우명을 리스트로 묶어서 전달
# Series s7에서 wed, mon 라벨 조회
# 이중리스트를 사용해 조회해야함 -> s7['wed', 'mon'] 에러 발생
s7[['wed', 'mon']]
# 여러개의 인덱스를 조회할때는 리스트만 대입할 수 있다.
s7[('mon', 'wed')]
슬라이싱(Slicing)
- Series객체[시작인덱스 : 끝인덱스 : 간격]
- 특정 범위의 값을 선택하거나 변경
- 기본 숫자 인덱스 또는 새로운 인덱스 모두 사용 가능
- 기본 숫자 인덱스를 사용해서 슬라이싱 할 때는 끝 인덱스 미포함
- 라벨 인덱스를 사용해서 슬라이싱 할 때 끝 인덱스까지 모두 포함
# 인덱스 0에서 인덱스 2(포함)까지 조회
s1 = pd.Series([10, 20, 30, 40 ,50], index=list('abcde'))
s1
# RangeIndex : 0, 1
s1[0:2]
# 라벨 'a'에서 라벨 'c'(c포함)
s1['a':'c']
# 0~ 3범위를 2개 간격으로 인덱싱
s1[0:4:2]
# 인덱스 'b'에서 인덱스 'd'(포함)까지 2개 간격으로 조회
s1['b':'d':2]
조건 색인(Boolean Indexing)
- 객체에 벡터와 스칼라 연산을 적용하여 True인 데이터만 반환
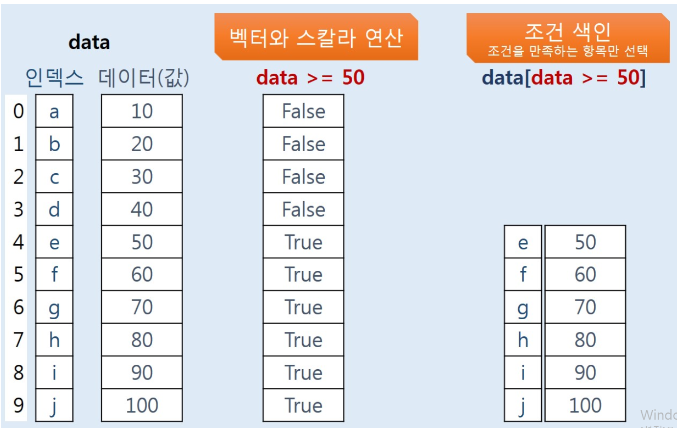
# 양수와 음수 데이터를 저장하고 있는 Series 생성
s2 = pd.Series([10, -3, 14, 70, -44, -18, -5, 1, -2, 12, 5])
s2
# 음수인 데이터는 True로, 양수인 데이터는 False로 만들기
s2 < 0
# 위의 조건식에서 음수만 남겨주세요
s2[s2 < 0]
# 두개 이상의 조건 병렬형태로 처리하기
# 양수이면서 10보다 작은 값만 조건식으로 남겨주세요.
s2[(s2 > 0) & (s2 < 10)]
산술연산
- series 객체와 스칼라 값의 산술연산 => BroadCasting
- series 객체 간의 산술연산
- 인덱스의 라벨이 동일한 것끼리 연산 수행, 공통으로 존재하지 않는 경우 NaN 반환
- 라벨이 없는 경우 차례대로 연산 수행, 개수가 동일하지 않는 경우 NaN 반환
- fill_value 인자를 통해 NaN이 아닌 특정 값으로 대체 가능
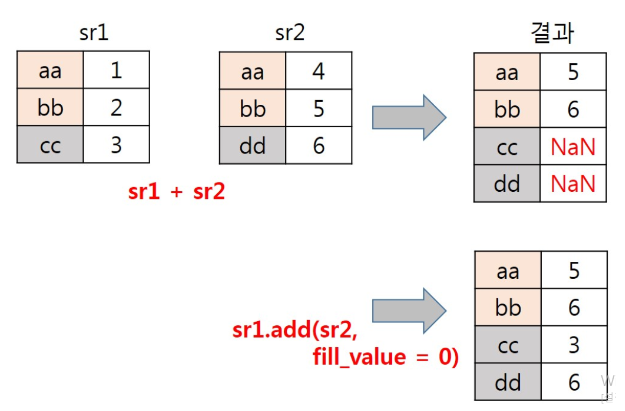
- 연산의 종류
- 더하기 : +, add() 메서드
- 빼기 : -, sub() 메서드
- 곱하기 : *, mul() 메서드
- 나머지만 반환 : %
- 몫만 반환 : //
# s1 -> 라벨 : a, b, c, d -> 데이터 4개 [1, 2, 3, 4]
# s2 -> 라벨 : a, c, d, e, f, g -> 데이터 6개 [10, 20, 30, 40, 50, 60]
s1 = pd.Series([1, 2, 3, 4], index=list('abcd'))
s2 = pd.Series([10, 20, 30, 40, 50, 60], index=list('acdefg'))s1
s2
더하기
# Series 객체와 스칼라값의 산술연산
s1 * 3
# Series끼리 더하기
# 공통라벨인 a, c, d에만 값 부여, 어느 한쪽에만 존재하는 라벨들은 NaN
s1 + s2
# fill_value 파라미터 : 공통으로 존재하지 않는 라벨에 대해서 NaN값을
# 적용하지 않고 특정 값으로 대체해서 사용할 수 있다.
# Series 메서드를 사용할 때의 파라미터로 입력 가능
s1.add(s2)
s1.add(s2, fill_value=0)
빼기
# Series 객체간의 빼기 연산
s1 - s2
s1.sub(s2, fill_value=100)
곱하기
# Series 객체 간의 곱하기 연산
s1 * s2
s1.mul(s2, fill_value=1)
나누기
# Series 객체 간의 나누기 연산
s1 / s2
s1.divide(s2, fill_value=1)
https://pandas.pydata.org/pandas-docs/stable/reference/series.html
위 사이트에서 추가적인 fill_value 사용 가능 연산자별 명령어를 확인할 수 있다.
연습 문제 ╰(°▽°)╯
1. 실습 데이터 생성 : 1 ~ 100(미만) 사이의 랜덤 정수 값을 26개 저장한 Series를 생성하고 A~Z까지의 알파벳으로 라벨링 설정
import numpy as np
np.random.seed(1021)
data= np.random.randint(1,100,26)
sss = pd.Series(data, index=list('abcdefghijklmnopqrstuvwxyz'))
sss
2. 인덱스 라벨이 'K' 항목의 값 출력
sss['k']
3. 인덱스 라벨이 'A','F','C'항목의 값 출력
sss[['a','f','c']]
4. 5번 인덱스부터 15번 인덱스까지의 항목 출력
sss[5:16]
sss['f':'p']
5. 뒤에서 5개 항목 출력
sss[-5:]
6. data의 항목의 갯수를 출력
len(sss)
sss.size
# 두가지 가능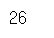
7. data항목 값들의 평균보다 큰 항목만 출력
sss[sss > sss.mean()]
8. data의 항목 값 중에 50이 있는지 확인하여, 있으면 True, 없으면 False를 출력
sss == 50
50 in sss 
50 in sss.values
(☞゚ヮ゚)☞ 데이터프레임으로 넘어가보자!파이팅!!

파이썬초짜의 기록