DataFrame 생성
- 2차원 배열과 유사한 자료형
- 다차원 리스트, 딕셔너리 자료형으로 데이터 구성 가능
- 관계형 데이터베이스의 테이블 구조, excel/csv 데이터 구조와 유사
- 하나의 컬럼은 하나의 Series로서 하나의 Dataframe은 여러 개의 Series 묶음으로 구성됨
- index 특징
- row index(행 인덱스) : 기본 숫자형 인덱스가 아닌 새롭게 지정한 로우명(라벨) 인덱스를 사용해도 기본 숫자형 인덱스를 함께 사용할 수 있음
- column index(열 인덱스) : 새롭게 컬럼명(라벨) 인덱스를 사용하면 기본 숫자형 인덱스는 사용할 수 없음
다차원 리스트로 생성
import pandas as pd
# 다차원 자료형, 딕셔너리 자료형을 사용
# 주의점 : 자료형에 따라서 아이템 길이 이슈 발생
# 다차원 리스트 : 아이템 길이가 동일 / 서로 다른 타임
# 딕셔너리 : 아이템 길이가 동일 / 서로 다른 타입
# 데이터프레임의 셀(튜플)에는 모든 데이터 타입 및 여러 타입 혼합 가능
# 다차원 리스트 : 아이템 개수 3개, 하위 아이템 개수 4개
data1 = [[1, 2, 3, 4],
['a', 'b', 'c', 'd'],
[0.1, 0.2, 0.5, 0.8]]
# 아이템 3개 : 행 3줄 => df에 저장하는 데이터의 개수
# 하위 아이템 4개 : 열 4줄
df1 = pd.DataFrame(data1)
df1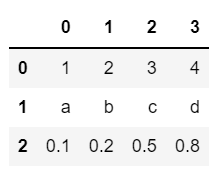
# 아이템 길이가 다른 다차원 리스트
# 최대 길이의 행을 기준으로 df구조가 생성됨
# 길이가 모자란 튜플(셀) : NaN으로 채워짐
data2 = [[1, 2, 3, 4, 5],
['a', 'b'],
[0.1, 0.2, 0.5]]
df2 = pd.DataFrame(data2)
df2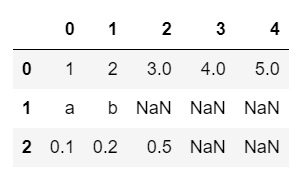
딕셔너리 자료형으로 생성
# 아이템 3개, value의 길이 4개 =>
# 아이템의 개수(컬럼의 개수),
# value의 길이(로우의 개수),
# 딕셔너리의 키 :
data3 = {'a':[10, 20, 30, 40],
'b':[1, 2, 3, 4],
'c':[5, 6, 7, 8]}
df3 = pd.DataFrame(data3)
df3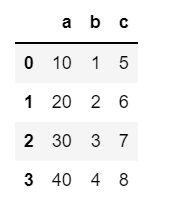
# 딕셔너리 자료형을 데이터프레임 데이터로 사용
# 아이템 개수 3개, value 길이는 다르게
# 개수가 모자란 튜플(셀):ValueError -> key별 매칭 value의 길이가 모두 동일해야함
data4 = {'a':[10],
'b':[1, 2, 3, 4],
'c':[5, 6, 7]}
df4 = pd.DataFrame(data4)
df4
컬럼명,로우명 지정(1)
# 인덱스를 지정하여 객체 생성 : DataFrame 함수에서 파라미터로 지정
# columns 파라미터 : 컬럼명(열 개수와 동일한 길이를 가진 리스트 전달)
# index 파라미터 : 로우명(행 개수와 동일한 길이를 가진 리스트 전달)
df5 = pd.DataFrame(data1,
index=['r1', 'r2', 'r3'],
columns=['c1', 'c2', 'c3', 'c4'])
df5
컬럼명,로우명 지정(2)
# 딕셔너리를 이용했을 때 컬럼 순서를 변경해서 df 생성 가능
df6 = pd.DataFrame(data3, index=list('wxyz'), columns=list('cab'))
df6
# data3에 없는 컬럼명을 전달하는 경우 : 없는 컬럼명으로 NaN 생성
df7 = pd.DataFrame(data3, columns=('abd'))
df7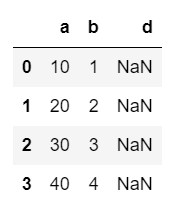
# 딕셔너리 data와 일치하지 않는 index 개수를 전달하는 경우 :
# df8 = pd.DataFrame(data3, index=[10, 20, 30, 40, 50])
# df8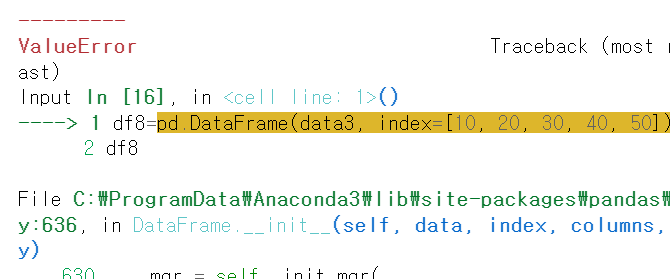
DataFrame 속성
- 속성은 소괄호를 붙이지 않음
- index : df 객체의 행 인덱스 배열을 반환
- columns : df 객체의 열 인덱스 배열을 반환
- axes : df 객체의 행, 열 인덱스를 아이템으로 가지는 배열을 반환
- values : df 객체의 데이터(값)를 아이템으로 가지는 2차원 배열을 반환
- dtypes : df 객체의 데이터 타입을 열 기준으로 반환
- size : df 객체의 데이터 개수(길이)를 반환
- shape : df 객체의 구조(행, 열, 차원)를 반환
- T : 행과 열을 전환시킴
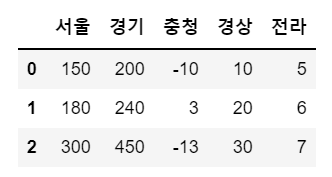
# 딕셔너리 타입 데이터로 데이터프레임 생성
# 서울, 경기, 충청, 경상, 전라 지역에 대해 2016, 2017, 2018년 유입인구 데이터 세팅
data = {'서울':[150, 180, 300],
'경기':[200, 240, 450],
'충청':[-10, 3, -13],
'경상':[10, 20, 30],
'전라':[5, 6, 7]}
sample = pd.DataFrame(data)
sample
df.index
# 행(row)인덱스 : 행 개수와 동일하게 리스트로 전달
sample.index = [2018, 2019, 2020]
sample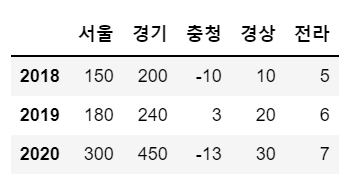
# 참고 : 행 인덱스 이름 지정
sample.index.name = 'year'
sample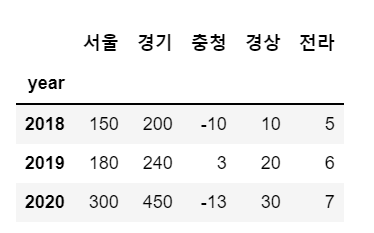
df.columns
# 열 인덱스
sample.columns
# 참고 : 열 인덱스 이름 지정
sample.columns.name = 'location'
sample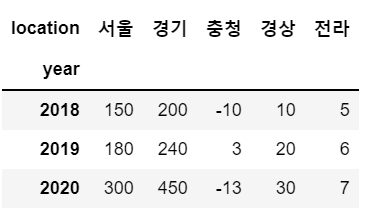
인덱스 수정
df.index=[]
# 행 인덱스(row)수정
# 속성값
# 1. 행의 개수와 동일한 리스트를 전달
# 2. 속성값으로 사용하는 인덱스 객체는 아이템 수정 불가(하나만 수정 불가)
sample.index = [1991, 1992, 1993]
sample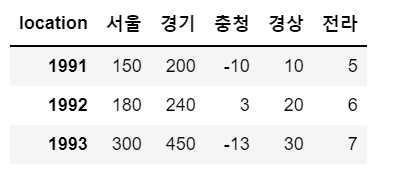
df.rename({ : }, inplace=F/T, axis=1/0)
# 인덱스 수정
# df 메서드 : df변수, rename(data, axis)
# axis 기본값 = 0(로우 == 'index')
# 열 인덱스(컬럼)에 대한 수정 : axis=1 혹은 axis='columns'
# data : 딕셔너리타입, {'이전 인덱스명' : '바꿀 인덱스명'}
# inplace=False(기본값) : 바뀐 결과가 적용x 시뮬레이션만 수행
# inplace=True : 바뀐 결과가 바로 적용
sample.rename({1991:1990}, inplace=False)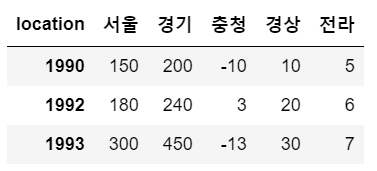
# 열 인덱스(컬럼) 변경 : axis=1, axis='columns'
# 전라 ->제주로 변경해보세요
sample.rename({'전라':'제주'}, axis='columns')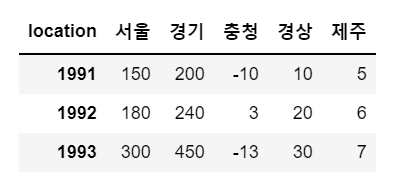
sampledf.axes
# 행, 열 인덱스 : df.axes
# 반환값 : 리스트 -> 첫 번째 아이템(행(row)인덱스), 두 번째 아이템(열(columns))인덱스
print(sample.axes)
df.reset_index(drop=True)
# reset_index(drop=True)를 사용하면 row에 배정된 인덱스를 일괄 삭제한다
sample.reset_index(drop=True)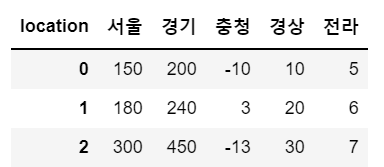
# 데이터 : df.values
# 반환값 : 2d array
sample.values
# drop에 대해서 True를 주지 않으면 이전 인덱스가 컬럼으로 편입됩니다.
sample.reset_index()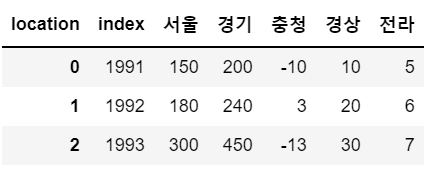
# 데이터 : df.values
# 반환값 : 2d array
sample.values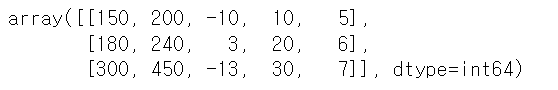
df.dtypes
#각 열의 데이터 타입
sample.dtypes
# len으로 조회시 2차원데이터로 간주해서 row개수만 반환됨
len(sample)
df.shape
# 데이터 구조(행, 열)
sample.shape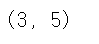
df.T
# 행과 열을 전치
sample_t = sample.T
sample.T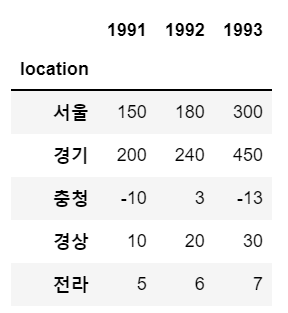
# 전치한 데이터 프레임의 행 인덱스
sample_t.index
# 전치한 데이터 프레임의 열 인덱스
sample_t.columns
sample_t.shape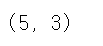
# 전치는 1회성으로 진행됨(원본 sample 변수는 그대로 3 * 5 를 유지중)
sample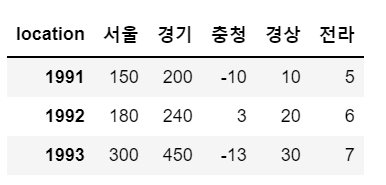
***
## 인덱싱
- 컬럼 조회
- df[col]
- df.col
- df.get(col)
- iloc, loc 메서드로 로우 조회
- df.iloc[idx] : 기본 숫자형 인덱스
- df.loc[label] : 새롭게 지정한 인덱스(숫자형이어도 기본 인덱스가 아니면 모두 loc 메서드로 조회)
# 기본적인 인덱싱 기법은 데이터프레임의 컬럼에서 값을 조회
# 객체[idx_n]
sample['서울']
# '서울' 컬럼 조회의 3가지 방법
# 1. 기본적인 인덱싱 기호 : df[column]
# 2. 컬럼명을 .을 이용해서 조회, 무조건 이름이 변수명으로 사용될때만 가능
# 3. df의 get 메서드로 조회 : df.get(colname)
#sample['서울']
#sample.서울
sample.get('서울')
sample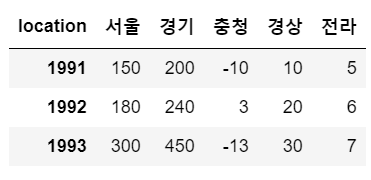
df.iloc[0]
# 첫 번째 행(로우) 조회 : 0번 인덱스 참조
# 반환값 : Series
# 라벨 인덱스 : 기존 데이터프레임의 컬럼
# Series name : 기존 데이터프레임에서 참조한 첫 번째 행의 라벨 인덱스
sample.iloc[0]
df.loc[1992]
# 숫자형 라벨로 조회 : 1992년 행 조회
sample.loc[1992]
df.[['서울', '경기']]
# 여러개의 열 조회 : 리스트로 묶어서 전달(서울, 경기)
sample[['서울', '경기']]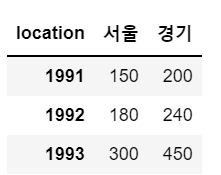
# 서울, 경기지역의 1992년 데이터만 조회
sample[['서울', '경기']].loc[1992]
sample.loc[1992][['서울', '경기']]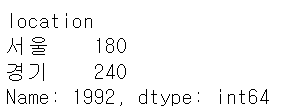
# 여러 개의 행 조회(1991, 1993년 한꺼번에 조회)
sample.loc[[1991, 1993]]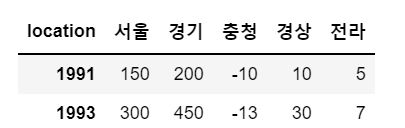
# 1990, 1993년도의 데이터에서 충청지역 데이터만 남겨보세요.
sample.loc[[1991,1993]]['충청']
sample.loc[[1991,1993]].get('충청')
sample.iloc[[0,2]].충청
슬라이싱
- 로우(행) 슬라이싱
- 순서가 있으며 로우 단독으로 슬라이싱 가능
- 기본 슬라이싱 문법은 기본 숫자형 인덱스를 기준으로 적용
- 기본 숫자형 인덱스로 슬라이싱할 때는 마지막 인덱스는 포함하지 않고 라벨 인덱스로 슬라이싱할 때는 마지막 인덱스를 포함
- 컬럼(열) 슬라이싱
- 순서가 없기 때문에 컬럼 단독으로 슬라이싱할 수 없음
- 라벨 기준으로 로우 기준 슬라이싱 결과에 대해 컬럼 슬라이싱 가능(기본 숫자형 인덱스는 적용 불가)
- 마지막 인덱스를 포함
sample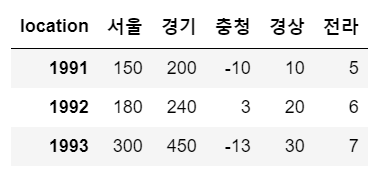
로우 슬라이싱
# 기본 로우 슬라이싱 : df[start:end:step]
# 0번부터 1번까지 슬라이싱
sample[0:2]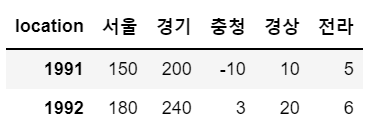
# 0번부터 2번까지 2행 간격으로 슬라이싱
sample[0:3:2]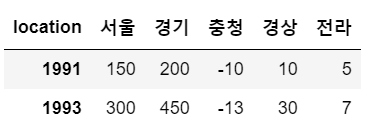
# 전체 로우에 대해 간격을 -1로 지정 : 행을 역순으로 나열
sample[::-1]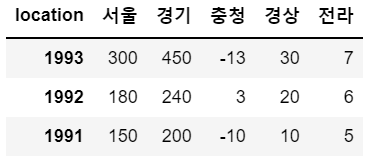
컬럼 슬라이싱
# 컬럼 슬라이싱 : 행에 대한 슬라이싱 결과에 열 슬라이싱 적용
# df[:, start:end:step]
# 기본 숫자형 인덱스 기준의 슬라이싱 -> 컬럼명으로 사용
sample.loc[:, :'경상']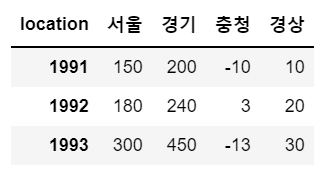
# 컬럼, 로우 인덱스 모두 기본 숫자형 인덱스인 경우
# 4 * 4 구조에서 모든 값이 0인 데이터프레임 생성
import numpy as np
data = np.zeros((4, 4))
data
# df화 시키기
df = pd.DataFrame(data)
df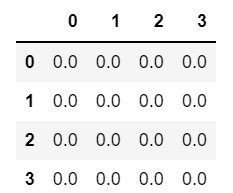
숫자형 슬라이싱
# 숫자형 슬라이싱
# [컬럼][로우]
df[:3][:2]
# 로우 컬럼이 모두 숫자인 경우
# 하나의 대괄호 안에 쓰면 에러난다
df[:3, :2]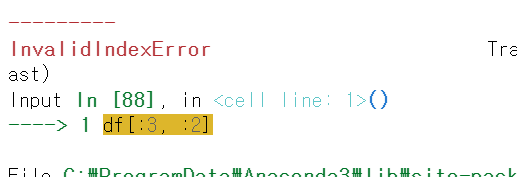
# 1. 컬럼 슬라이싱에서 사용하는 인덱스 : 기본 번호 인덱스
# 2. 컬럼 슬라이싱 조건 : 로우 슬라이싱 결과에서만 가능
# 3. 메서드를 사용한 로우 슬라이싱 : iloc / loc -> 1번 기준
df.iloc[:3, :2]
연습문제
아래와 같은 데이터프레임을 생성하고 출력화면과 동일한 결과를 생성하세요.
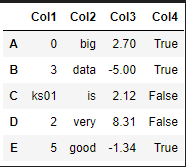
data = {"Col1": [0, 3, 'ks01', 2, 5],
"Col2":["big", "data", "is", "very", "good"],
"Col3":[2.7, -5.0, 2.12, 8.31, -1.34],
"Col4":[True, True, False, False, True]}
df = pd.DataFrame(data, index=list('ABCDE'))
df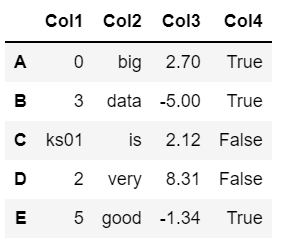
# Col1, Col3를 함께 조회해주세요.
df[["Col1", "Col3"]]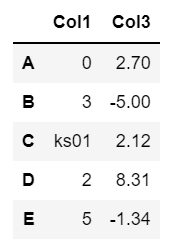
# A, C, D 로우만 조회해주세요.
df.loc[['A', 'C', 'D']]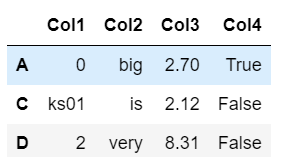
# B, D 로우의 Col1, Col2만 조회해주세요.
df[['Col1', 'Col2']].loc[['B', 'D']]
df.loc[['B', 'D']][['Col1','Col2']]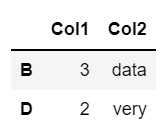
컬럼, 로우 추가
- 컬럼 추가 / 변경
- 컬럼 인덱싱 = 스칼라 값
- 컬럼 인덱싱 = 배열, 리스트(로우 개수와 아이템 개수 일치)
- 컬럼 인덱싱 = 컬럼 간의 연산
- 컬럼 인덱싱 = series
- 로우 추가
- 로우 인덱싱 = 스칼라 값
- 로우 인덱싱 = 로우 간의 연산
- 데이터 분석에서 컬럼과 로우의 의미
- 컬럼 : 변수(특성)
- 로우 : 개별 데이터(레코드)
- 전체 데이터를 구성하는 변수를 추가/삭제하는 일은 빈번하게 발생하지만 특정 인덱스를 기준으로 전체 로우 데이터를 추가/삭제하는 일은 자주 발생하지 않으며 데이터 처리를 하는 과정에서 권장하지 않는 작업
# 컬럼 추가 1 : 모든 로우에 대해서 동일한 값을 가지는 컬럼 => 스칼라값(단일값)
sample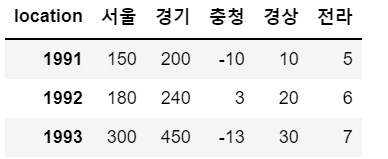
# 제주 컬럼 추가, 모든 데이터는 1로 통일
sample['제주'] = 1
sample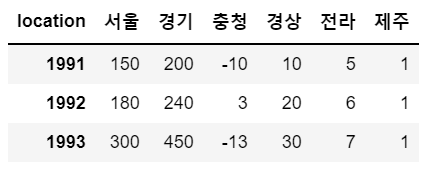
# 컬럼 추가 2 : 서로 다른 값을 가지는 데이터로 열을 구성하는 컬럼의 숫자
# 조건 : 전달하는 자료형(배열, 리스트)의 길이 = 행의 길이
# 부산 컬럼 추가, 데이터는 5부터 1씩 증가하는 숫자를 가지는 배열
sample['부산'] = np.arange(5, 8) # [5, 6, 7]
sample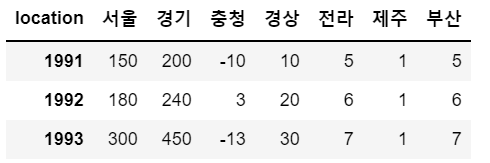
# 컬럼 추가 3 : 컬럼간의 연산 -> 파생변수
# 수도권 : 서울 + 경기
sample['수도권'] = sample['서울'] + sample['경기']
sample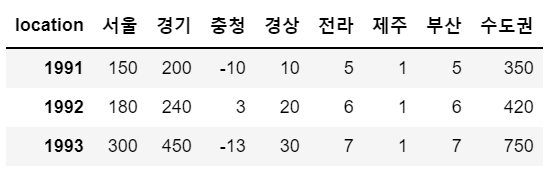
# 컬럼 추가 4 : Series 객체를 컬럼으로 전달
# 조건 : 추가 대상인 df의 구조와 추가 아이템인 Series의 구조를 파악해야함
# 라벨 인덱스를 기준으로 Series 데이터와 df 데이터가 매핑
# Series에 없는 라벨 인덱스의 경우에는 NaN
# 반드시 길이가 일치하지 않아도 된다
s1 = pd.Series([9, -99], index=[1991, 1992])
s1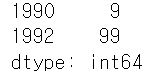
sample['강원'] = s1
sample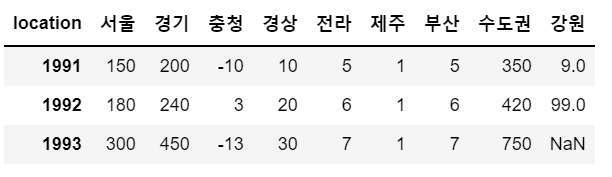
# 데이터 개수가 동일해도 라벨 기준으로 매핑하기 때문에, 값 전달이 이뤄지지 않는 케이스
s2 = pd.Series([100, 100, 100])
s2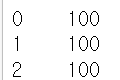
sample['test'] = s2
sample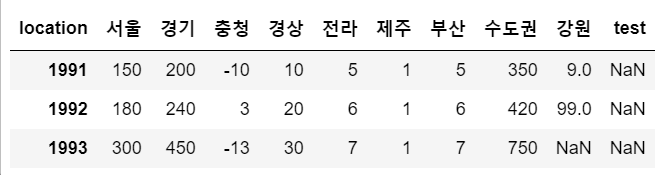
- 로우 추가
- 로우 인덱싱 = 스칼라 값
- 로우 인덱싱 = 로우 간의 연산
- 로우 인덱싱 = 자료형(배열, 리스트 / 컬럼 개수와 아이템 개수 일치)
.loc 로우 추가
# 로우는 .loc를 이용해서 추가해준다
# .loc가 붙는다는 점만 빼고는 컬럼과 완전히 동일한 문법을 사용한다.
sample.loc[1994] = 0
sample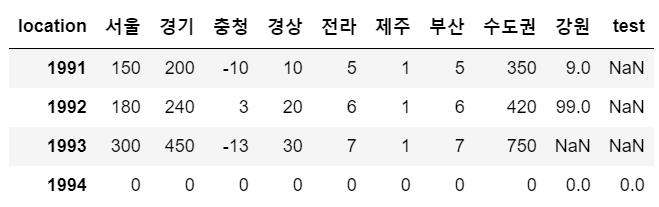
sample.shape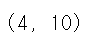
배열로 추가
# 배열, 리스트, 딕셔너리 : 로우 추가 가능한 자료형
# 컬럼개수와 아이템개수를 일치시켜 전달
sample.loc[1995] = np.arange(10)#0~9까지 증가하는 리스트를 전달해보세요
sample
딕셔너리로 추가
# 딕셔너리로 각 컬럼명:값 형식으로 매치된 자료를 연도 로우에 대입
sample.loc[1996] = {'서울':10, '경기':20, '충청':40, '경상':21, '전라':37,
'제주':103, '부산':28, '수도권':30, '강원':15, 'test':0}
sample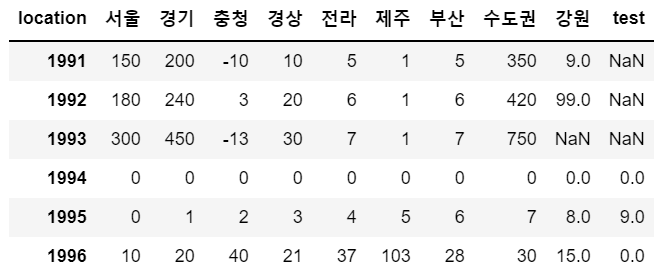
로우끼리 연산해 추가
# 로우끼리연산 : 1997년 로우를 추가해주시고, 95년 + 96년으로 입력해주세요.
sample.loc[1997] = sample.loc[1996] + sample.loc[1995]
sample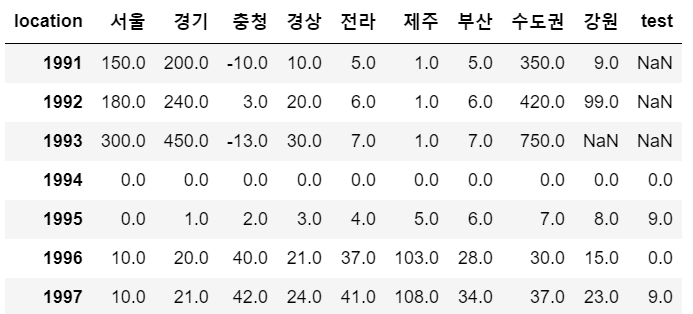

파이썬초짜의 기록