로우, 컬럼 삭제
- 컬럼 삭제
- del 키워드 + 컬럼 인덱싱
- df.drop(col, axis=1)
- df.drop(columns=col)
- 로우 삭제
- df.drop(idx) : axis = 0 (기본값)
sample = pd.DataFrame({'서울':[150.0, 180.0, 300.0, 0.0, 0.0, 10.0, 10.0],
'경기':[200.0, 240.0, 450.0, 0.0, 1.0, 20.0, 21.0],
'충청':[-10.0, 3.0, -13.0, 0.0, 2.0, 40.0, 42.0],
'경상':[10.0, 20.0, 30.0, 0.0, 3.0, 21.0, 24.0],
'전라':[5.0, 6.0, 7.0, 0.0, 4.0, 37.0, 41.0],
'제주':[1.0, 1.0, 1.0, 0.0, 5.0, 103.0, 108.0],
'부산':[5.0, 6.0, 7.0, 0.0, 6.0, 28.0, 34.0],
'수도권':[350.0, 420.0, 750.0, 0.0, 8.0, 30.0, 37.0],
'강원':[9.0, -99.0, np.NAN, 0.0, 8.0, 15.0, 23.0],
'test':[np.NAN, np.NAN, np.NAN, 0.0, 9.0, 0.0, 9.0]},
index=[1990, 1992, 1993, 1994, 1995, 1996, 1997])
sample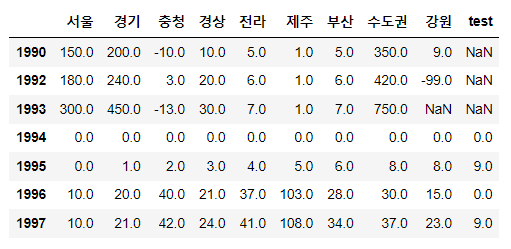
컬럼삭제 1. del df['컬럼인덱싱']
# 컬럼 삭제 1 : del 키워드 + 컬럼 인덱싱
# 특징 : 원본 객체에서 바로 데이터가 사라짐(시뮬레이션이 아니고 즉시 적용)
del sample['test']
sample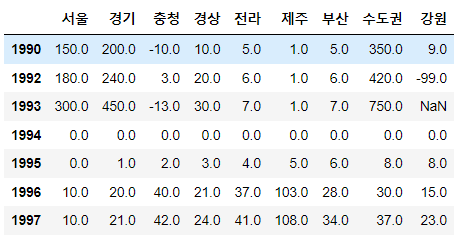
컬럼삭제 2. df.drop(columns =컬럼이름, inplace=True)
# 컬럼 삭제 2 : df.drop(columns = 컬럼이름)
# 특징 : 원본 반영 되지 않음 -> inplace=True 기입시 원본에 바로 반영
# 경상 컬럼을 위의 설명을 참조해 삭제하고 코드를 저한테 보내주세요.
sample.drop(columns='경상', inplace=True)
sample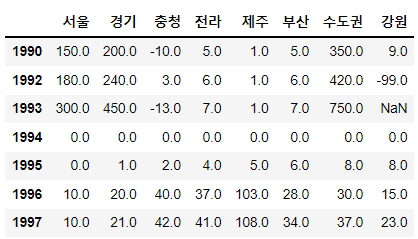
컬럼삭제 3. df.drop('컬럼명', axis=1, inplace=True)
# 컬럼 삭제 3 : df.drop(컬럼명, axis=1)
# 충청 컬럼을 삭제하고 코드를 보내주세요.
sample.drop('충청', axis=1, inplace=True)
sample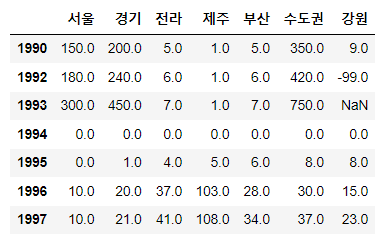
로우삭제 df.drop(로우명, (axis=0), inplace=True)
# 로우 삭제
# df.drop(로우명, axis=0(생략가능))
# 1995년 데이터를 삭제해주세요.
sample.drop(1995, inplace=True, axis=0)
sample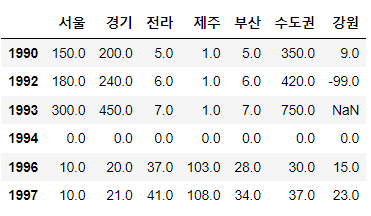
두개 이상 컬럼/로우 삭제 : 리스트
# 두 개 이상의 컬럼이나 로우 삭제 : 리스트로 묶어서 전달
# [제주, 강원] 을 삭제해주세요.
sample.drop(['제주', '강원'], axis=1, inplace=True)
sample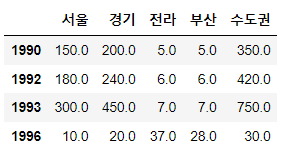
***
산술연산
- dataframe 과 스칼라 값 산술연산
- dataframe 과 series 간의 산술연산
- dataframe 간의 산술연산
- 컬럼, 로우 인덱스를 기준으로 연산 수행
- 공통으로 존재하지 않는 경우 NaN 반환
- fill_value 인자 값을 통해 NaN이 아닌 값으로 대체 가능
- 연산의 종류
- 더하기 : +, add() 메서드
- 빼기 : -, sub() 메서드
- 곱하기 : *, mul() 메서드
- 나머지만 반환 : %
- 몫만 반환 : //
-dataframe 과 스칼라 값 산술연산
# 컬럼명을 서울, 경기, 인천으로, 로우명을 a, b, c로 가지고
# 0부터 1씩 증가하는 정수 값을 데이터로 가지는 DataFrame
df1 = pd.DataFrame(np.arange(9).reshape(3, 3),
index=list('abc'),
columns=['서울', '경기', '인천'])
df1
# 컬럼명을 서울, 경기, 인천, 세종, 강원으로
# 로우명을 a, b, c, d로 가지고 0부터 1씩 증가하는 정수값을 데이터로 가지는 DataFrame
df2 = pd.DataFrame(np.arange(20).reshape(4, 5),
columns=['서울', '경기', '인천', '세종', '강원'],
index=list('abcd'))
df2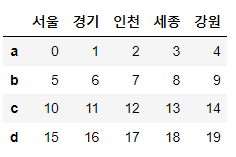
더하기
# 데이터프레임간의 더하기 연산
# 결과 해석 : 공통 컬럼, 로우인 데이터만 정상 더하기, 아닌 부분은 NaN
df1 + df2
# fill_value : add 메서드의 파라미터
df1.add(df2, fill_value=0)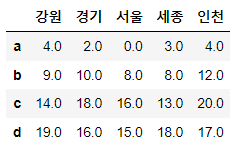
빼기
# 데이터프레임간의 빼기 연산
df1.loc[['a', 'c', 'b', 'd']] - df2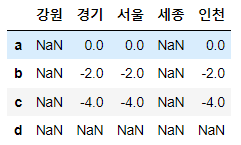
df1.sub(df2, fill_value=0)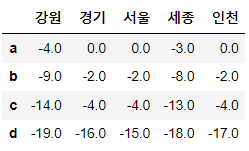
곱하기
# 데이터프레임간의 곱하기 연산
df1 * df2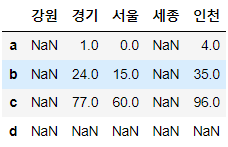
# .mul로 처리 가능합니다. 곱연산시 대상 값이 없는 부분을 1로 간주하고 계산해주세요.
df1.mul(df2, fill_value=1)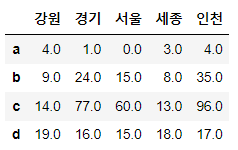
나누기
# 데이터프레임의 나누기 연산
df1 /df2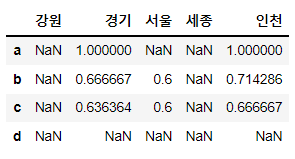
# .divide를 이용해 값이 없는 부분을 1로 간주해 나눠주세요.
df1.divide(df2, fill_value=1)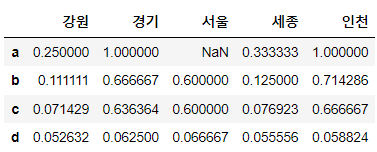
df2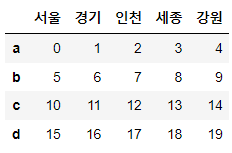
-DataFrame과 Series 간의 연산
- 기본적인 동작은 Series 객체의 인덱스를 DataFrame 객체의 컬럼 인덱스와 매핑하여 브로드캐스팅과 유사하게 연산 수행
- 두 객체 간의 공통된 인덱스가 아닌 대상은 NaN 값으로 대입
- 메서드를 사용하여 연산을 수행할 때는 axis 파라미터를 통해 연산을 적용할 축 지정(0:행, 1:열)
- 연산의 종류
- 더하기 : +, add() 메서드
- 빼기 : -, sub() 메서드
- 곱하기 : *, mul() 메서드
# 컬럼명 : a, b, c, d
# 로우명 : 2010, 2011, 2012
# 데이터 : 0부터 1씩 증가하는 정수
df = pd.DataFrame(np.arange(12).reshape(3, 4),
index=[2010, 2011, 2012],
columns=list('abcd'))
df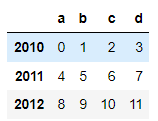
* DataFrame+Series 더하기
# 첫 번째 행을 추출
# s1 : 라벨인덱스가 적용된 시리즈
s1 = df.iloc[0]
s1
df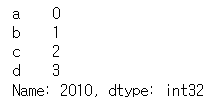
# Series(라벨인덱스 a, b, c, d)와 df의 결합기준 : 이름이 일치할때 더하기
df + s1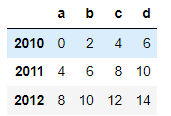
DataFrame Series 곱하기
# 데이터프레임
# 컬럼명 : a, b, c, d, e
# 데이터 : 20개의 0
df2 = pd.DataFrame(np.zeros(20).reshape(4, 5),
columns=list('abcde'))
df2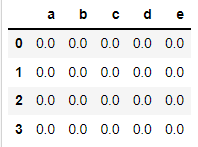
# 기본 인덱스를 가진 시리즈
# 데이터 0, 1, 2, 3, 4
s2 = pd.Series(np.arange(5))
s2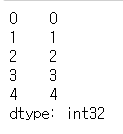
# 열 단위 산술 연산
# 기본 동작 : Series의 로우 인덱스를 df의 컬럼에서 매핑
# 결과해석
df2.sub(s2)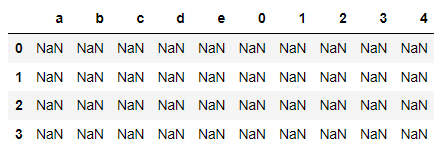
# axis=0 : 컬럼과 시리즈의 라벨인덱스가 아닌 로우와 시리즈의 라벨인덱스 일치시 연산
# 결과해석 : idx 4번의 결과만 NaN(s2의 4번 인덱스)
df2.sub(s2, axis=0)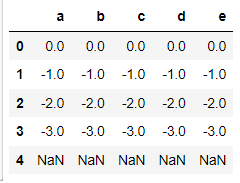
df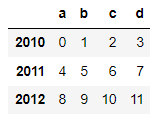
* 공통되지 않은 값과 연산 NaN
# df의 컬럼에 없는 인덱스를 가진 Series
# 인덱스 : a, c, e
# 데이터 : 3, 3, 3
s3 = pd.Series([3, 3, 3], index=list('ace'))
s3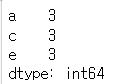
# 공통되지 않은 인덱스값과 컬럼값 -> NaN
df - s3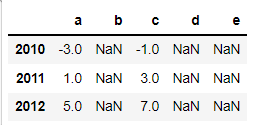
df.sub(s3)

파이썬초짜의 기록