1. csv 파일 적재
- pd.read_csv()
- 컬럼명이 존재하는 데이터
- 컬럼명이 없는 데이터
- 구분자 설정
- (참고) 절대경로: 모든 경로를 다 입력해서 파일이나 경로를 가져오는 것(정확)(불편)
상대경로: 대상파일과 실행중인 파일간에 겹치는 경로가 존재할 때 겹치지 않는 부분부터 기술하는 것
1. 파일 읽어오기 .read_csv()
import pandas as pd
# data/ex1.csv 파일 읽기(컬럼명이 존재하는 csv파일)
# read_csv 기본동작 : 첫 행 데이터를 컬럼으로 사용
# C:\Users\Playdata\python_da\data/ex1.csv
# C:\Users\Playdata\python_da\untitled.ipynb
data = pd.read_csv('data/ex1.csv')
data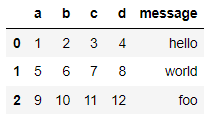
2. 컬럼명이 없는 파일 / header=None
# data/ex2.csv 읽기 (컬럼명이 없는 csv파일)
# read_csv : header = None
data = pd.read_csv('data/ex2.csv', header=None)
data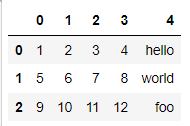
# 컬럼명 a, b, c, d, e를 data변수에 부여해보세요
data.columns=['a','b','c','d','e']
data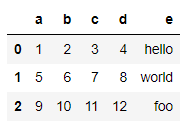
3. 콤마 외의 구분자처리 : sep='\s+'
# data/ex3.csv 읽기
# 기본 구분자 =,
# read_csv() : sep 파라미터
data2 = pd.read_csv('data/ex3.csv')
data2
data2.shape
# , 가 아닌 문자를 구분자로 사용하는 데이터 처리
# 구분자 : ",", " ", "\t", "/", "\" => 전부 \s+로 처리 가능
data2 = pd.read_csv('data/ex3.csv', sep='\s+')
data2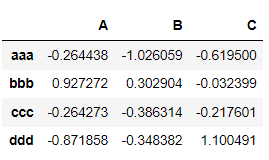
4. 주석이 포함된 파일 : skiprows=[ ], comment="#"
# data/ex4.csv 읽기(주석이 포함된 파일 읽기)
# 파라미터1 : skiprows = [생략하고 읽을 로우인덱스 번호]
pd.read_csv('data/ex4.csv', skiprows=[0, 2, 3])

# 파라미터 2 : comment '주석기호' (주석 유도시 사용한 주석 시작기호 입력)
pd.read_csv('data/ex4.csv', comment="#")
***
2. 엑셀 파일 읽기
- 기본적으로 첫번째 시트에 있는 데이터를 읽어와서 데이터프레임으로 저장
- 모든 시트를 읽기 위해서는 sheetname 인자를 None으로 설정
- 모든 시트의 데이터를 읽어서 사전 형태로 저장
- key = 시트의 이름, value = 각 시트에 있는 데이터들을 저장한 데이터프레임
- 특정 시트만 읽기 위해서는 sheetname 인자에 '시트명' 설정
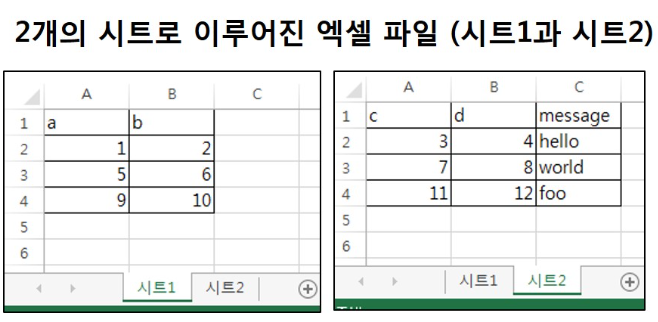
1) 파일읽기 .read_excel()
# 파일 읽기(첫 번째 시트만 자동으로 읽어옴, 디폴트)
pd.read_excel('data/ex6.xlsx')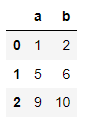
2) sheet_name = '시트명'
# 두 번째 시트 읽기 : sheet_name = '시트명'
pd.read_excel('data/ex6.xlsx', sheet_name='시트2')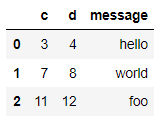
3) sheet_name = None
# 모든 시트 다 읽어오기
# sheet_name 파라미터 설정 : None
data = pd.read_excel('data/ex6.xlsx', sheet_name=None)
data
data.keys()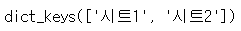
data.values()
4) 엑셀시트의 데이터로 DataFrame생성
# 시트1, 시트2의 데이터를 각각 변수 data1, data2에 저장하기
data1, data2 = data.values()
data1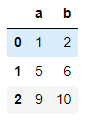
data2
5) 상위인덱스
# DataFrame 생성
# 구조 : 4 x 5
# 로우 인덱스 : 상위(2017, 2018) / 하위(모든 상위 인덱스에 대해 동일하게 'a', 'b')
# 컬럼 인덱스 : 상위(서울, 경기) / 하위(서울-강남, 잠실 / 경기-분당, 수원, 판교)
# 값 : 1씩 증가하는 20개
df = pd.DataFrame(np.arange(20).reshape(4, 5),
index=[[2017, 2017, 2018, 2018],
['a', 'b', 'a', 'b']],
columns=[['서울', '서울', '경기', '경기', '경기'],
['강남', '잠실', '분당', '수원', '판교']])
df
5-1) 상위 컬럼 접근 : df['서울']
# 컬럼의 상위 계층 접근 : 일반적인 df컬럼 인덱싱 방식
# 서울 데이터 조회
df['서울']
5-1) 하위 컬럼 접근 :df['서울']['강남'], df[('서울','강남')]
# 컬럼이 이중이기 때문에 인덱싱을 이중으로 해야 하나의 요소 조회 가능
df['서울']['강남']
# 한번에 조회하고 싶다면 튜플로 전달하면 됩니다.
df[('서울','강남')]
5-2) 상위 로우 접근 : df.loc[2017]
# 로우의 상위 계층 접근
# 2017년 데이터 조회
df.loc[2017]
5-2) 하위 로우 접근 : df.loc[2017].loc['a'], df[(2017, 'a')]
# 방법 1. 2017 전반기 데이터
df.loc[2017].loc['a']
# 방법 2. 튜플로 전달
df.loc[(2017, 'a')]
6) 슬라이스 (컬럼단독 슬라이스 불가)
df['경기'].loc[:, '분당','수원']
# 분당 ~ 수원까지 데이터 조회
# 주의점 : 데이터프레임 컬럼은 로우 슬라이싱 결과에 대해서만 슬라이싱 적용 가능
# df['경기']['분당','수원'] -> Error( 컬럼 슬라이싱은 단독으로 불가능)
df['경기'].loc[:,'분당':'수원']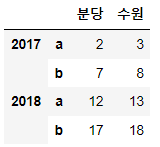
7) 하위로우->컬럼으로 올리기 : .unstack()
# 로우 최하위계층인 a, b를 컬럼으로 올려주세요
df.unstack()
# 컬럼 최하위를 로우의 하위계층으로 재배열해주세요
df.stack()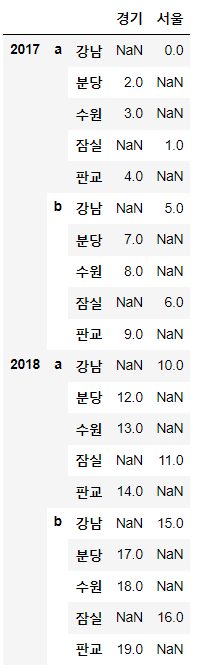
# 계층의 인덱스번호 또는 라벨을 사용하여 상/하위간 교환
# swaplevel(key1, key2, axis=0(기본값))
# axis가 0인 경우는 row의 상하위개념이 뒤집어진다.
df.swaplevel(1, 0)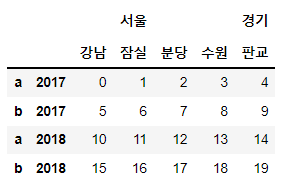
# axis=1은 로우 계층 변동이 아닌 컬럼 계층 변동
df.swaplevel(1, 0, axis=1)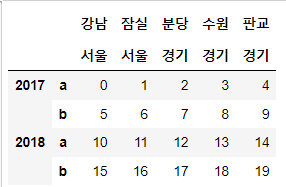
정렬
- obj.sort_index() : 인덱스를 기준으로 정렬 (기본값은 ascending=True, 오름차순 정렬)
- DataFrame, Series
- axis = 0 : 기본값, 로우 인덱스 기준으로 정렬
- axis = 1 : 컬럼 인덱스 기준으로 정렬
- DataFrame, Series
- obj.sort_values() : 값을 기준으로 정렬
- DataFrame, Series
- by : 정렬의 기준이 되는 인덱스 값 전달
- axis = 0 : 기본값, 컬럼을 기준으로 로우 인덱스를 정렬하며 기준값으로 by에 인덱스 컬럼 레벨 또는 컬럼명 전달
- axis = 1 : 로우 인덱스를 기준으로 컬럼 라벨을 정렬하며 기준값으로 by에 레벨 또는 라벨명 전달
- DataFrame, Series
# Series 생성
# 값과 인덱스라벨이 순서대로 들어가지 않은 Series
s1 = pd.Series([2, 3, 1, 7, 0], index=list('gacfd'))
s1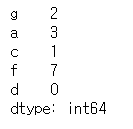
# 인덱스 기준 오름차순으로 정렬
# 기본동작 : 오름차순 & 로우 인덱스
s1.sort_index()
# 인덱스 기준 내림차순으로 정렬
s1.sort_index(ascending=False)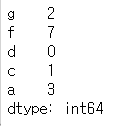
# 일시적 변경이므로 s1자체에는 영향 없음
s1
# 값 기준 오름차순으로 정렬
s1.sort_values()
# 값 기준 내림차순으로 정렬
s1.sort_values(ascending=False)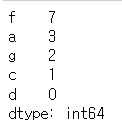
# 난수 시드 고정
np.random.seed(4)# DataFrame 생성
# 4 x 5, 무작위 정수
# 로우/컬럼 인덱스도 순서가 없는 값 지정
df1 = pd.DataFrame(np.random.randint(20, size=(4, 5)),
index=list('hcae'),
columns=list('EAFCD'))
df1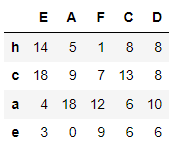
# 로우 인덱스 기준으로 오름차순 정렬(axis=0)
df1.sort_index()
# 로우 인덱스 기준으로 내림차순 정렬
df1.sort_index(ascending=False)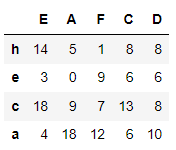
# 컬럼명 기준으로 내림차순 정렬
df1.sort_index(axis=1, ascending=False)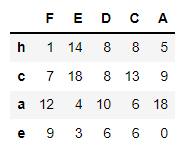
# 컬럼 기준으로 내림차순 정렬 후 , 로우 기준으로 오름차순 정렬
df1.sort_index(axis=1, ascending=False).sort_index()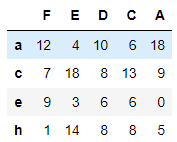
# 원본에는 영향 없음
df1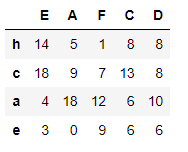
# 값 기준으로 정렬
# 컬럼 D의 값을 기준으로 오름차순 정렬
# sort_values(axis=0, by='기준컬럼이름') : 기본동작(정렬결과를 로우에 반영)
df1.sort_values(by='D')
# 컬럼 A를 기준으로 내림차순 정렬
df1.sort_values(by='A', ascending=False)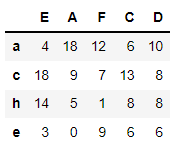
# 인덱스라벨(로우) c의 값을 오름차순으로 정렬
# 결과적으로 정렬되는 대상 : 컬럼
# 정렬의 기준 : 로우 레이블
df1.sort_values(by='c', axis=1)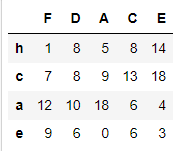
# 로우 'e'의 값을 기준으로 내림차순 정렬
df1.sort_values(by='e' , axis=1, ascending=False)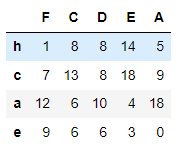
# 두 개의 컬럼에 대해서 정렬 : 리스트로 묶어서 by의 인자값으로 전달
# 정렬 우선순위 : 차례대로 1순위 >2순위(1순위 동점시 2순위로 넘어감)
# 1순위 정렬 후 1순위 컬럼의 동점값에 대해 2순위 컬럼의 값이 재정렬
# 동일한 값이 아니라면 무조건 1순위 컬럼이 우선
df1.sort_values(by=['D','E'])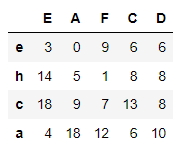
# e는 오름차순, a는 내림차순으로 하고 싶다면
# ascending=[True, False]와 같이 각각의 기준에 대해서 ascending을 따로 매겨준다
df1.sort_values(by=['e','c'], axis=1 ,ascending=[True,False])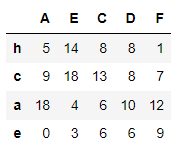
# 공통 컬럼이 두 개 이상인 경우
# 고객명, 날짜, 정보를 저장하고 있는 데이터프레임 생성
df3 = pd.DataFrame({'고객명':['김파이썬', '이장고', '박팬더스'],
'날짜':['2022-10-22', '2022-10-23', '2022-10-24'],
'정보':['010', '011', '019']})
df3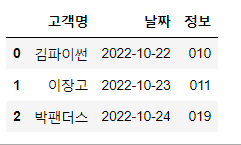
# 고객명, 정보를 저장하고 있는 데이터프레임 생성
df4 = pd.DataFrame({'고객명':['김파이썬', '박팬더스', '최넘파이'],
'정보':['F', 'M', 'M']})
df4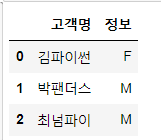
# 공통된 이름을 가진 컬럼이 두 개 이상인 경우 파라미터가 없으면 결과도 없다
pd.merge(df3, df4)
# on 파라미터 : 공통된 컬럼이 여럿인 경우 결합 기준 컬럼을 지정
# 합칠때 key로 사용할 컬럼 : '고객명'
# 공통컬럼 결과 : 고객명, 정보 -> 정보 컬럼 결과를 확인
# 기본동작으로 merge : inner
pd.merge(df3,df4, on='고객명')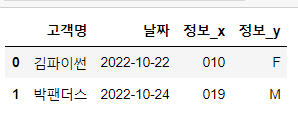
# left_on, right_on : 두 개의 데이터프레임에 대해서 서로 다른 기준컬럼을 지정
# 예) 동일한 속성의 자료를 저장하는 컬럼인데 표기하는 이름이 다른 경우
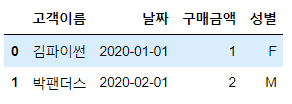
# 고객이름, 날짜, 구매금액을 저장하고 있는 데이터프레임 생성
df5 = pd.DataFrame({'고객이름':['김파이썬', '박팬더스', '강주피터'],
'날짜':['2020-01-01', '2020-02-01', '2020-02-15'],
'구매금액':[1, 2, 3]})
df5
# 고객명, 성별을 저장하고 있는 데이터프레임을 생성
df6 = pd.DataFrame({'고객명':['김파이썬', '박팬더스'],
'성별':['F', 'M']})
df6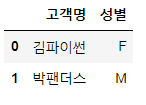
# 겹치는 컬럼명이 없어서 에러 발생
pd.merge(df5, df6)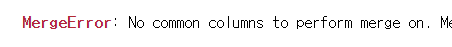
# left(df5), right(df6)에서 공통컬럼명을 각각 지정
tmp = pd.merge(df5, df6, left_on='고객이름', right_on='고객명')
tmp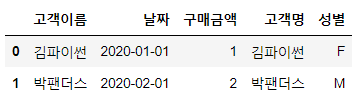
# drop 메서드를 이용해 컬럼 삭제(고객명)
tmp.drop(columns='고객명')
concat
- 특정 key를 기준으로 데이터를 합치는 것이 아니라 행, 열 기준으로 데이터를 연결
- 주요 파라미터
- axis : 0 / 행 방향(기본값)이며 컬럼을 key로 합치고, 1 / 열 방향으로 로우를 key로 합침
- join : 데이터프레임끼리 연결할 때 합치는 방법으로 outer(기본값), inner 방식 존재
- ignore_index : 합친 후 기존 인덱스를 유지 또는 새로운 인덱스를 지정
# 공통 인덱스 라벨을 가지는 Series 2개 생성
s1 = pd.Series([1, 2, 3], index=list('abc'))
s2 = pd.Series([5, 6, 7, 8], index=list('abfh'))
print(s1)
print(s2)
# 두 Series 간 연결
# 기본 : axis=0(행 방향으로 연결)
# 첫 번째로 전달된 객체가 위에, 두 번째로 전달된 객체가 아래로 추가(연결)
# 인덱스 라벨은 기존 값 유지
pd.concat([s1, s2])
# 새로운 인덱스로 초기화하기
pd.concat([s1, s2], ignore_index=True)
print(s1, s2)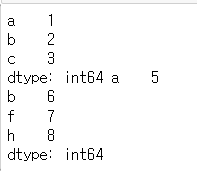
# 열 방향 연결 -> 두 개의 Series를 연결해서 하나의 DataFrame화 시키기
# 길이가 다른 경우
pd.concat([s1, s2], axis=1)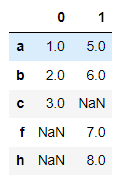
# 열 이름을 설정하면서 붙여주기 : keys파라미터에 컬럼명을 리스트로 전달
pd.concat([s1, s2], axis=1, keys=['c1','c2'], sort=False)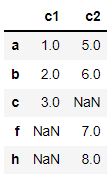
# 두 개의 데이터프레임 연결
# 고객명, 날짜, 구매금액
df1 = pd.DataFrame({'고객명':['김파이썬', '이장고', '박팬더스'],
'날짜':['2022-10-22', '2022-10-23', '2022-12-14'],
'구매금액':[1, 2, 3]})
# 고객명, 성별
df2 = pd.DataFrame({'고객명':['김파이썬', '최넘파이'],
'성별':['F', 'M']})
df1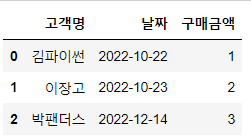
df2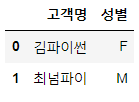
# 행 방향으로 데이터프레임 연결(로우개수 증가)
pd.concat([df1, df2])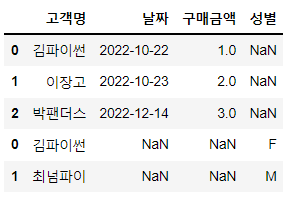
# 열 방향으로 데이터프레임 연결
pd.concat([df1, df2], axis=1)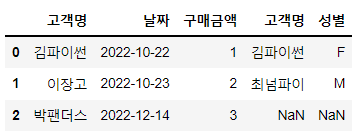
집계
- groupby(컬럼명)
- 특정 속성을 기준으로 묶어서 다양한 집계 함수 적용
- 대표적인 집계 함수
- sum : 총합
- mean : 평균값
- min : 최소값
- max : 최대값
- count : 개수
- std : 표준편차
- pivot table
- df.pivot(로우로 사용될 컬럼명, 컬럼으로 사용될 컬럼명, 튜플을 구성하는 값으로 사용될 컬럼명, 집계함수)
- 일차원으로 컬럼 및 로우가 단순 나열된 형식은 데이터를 파악하는데 적합하지 않기 때문에 pivot을 통해 계층 색인 및 형태 변경을 수행
# 엑셀 데이터 적재
# Os error -> engine='python'
# Unicode, Encoding -> encoding='utf-8' or 'cp949' or 'utf-16'
data = pd.read_excel('data/인구수예제.xlsx')
data

data.shape
# 상위 5개 자료만 조회
data.head()
# 하위 5개 자료만 조회
data.tail()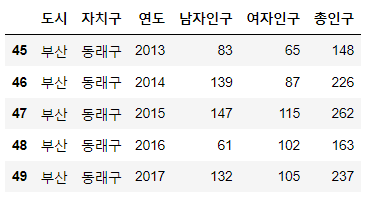
# 상위 10개 조회
data.head(10)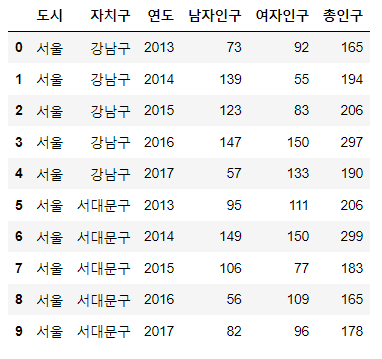
# 자치구별 남, 여 인구 각각의 총합
# 조사년도는 총 5개년
data.groupby('자치구')[['남자인구','여자인구']].sum()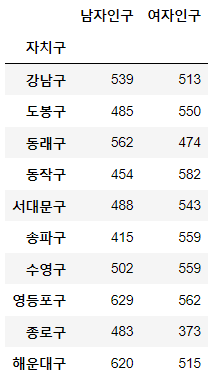
# 도시별 남여 인구 각각의 총합
data.groupby('도시')[['남자인구','여자인구']].sum()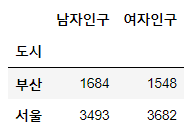
# 연도별, 도시별 남여 인구의 총합
# 컬럼명을 입력 안 하면 집계하는데 사용한 컬럼 이외의 나머지를 다 내보내줍니다.
data.groupby(['연도','도시']).sum()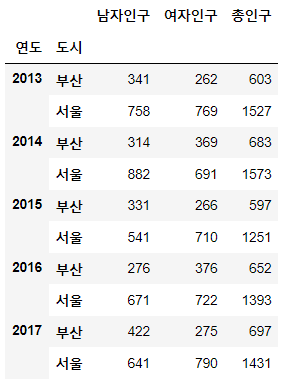
# 도시, 연도별 총인구 평균을 구해주세요.
data.groupby(['도시','연도'])[['총인구']].mean()
# 데이터 파악에 용이한 구조로 변경
data.groupby(['도시','연도'])[['총인구']].mean().unstack()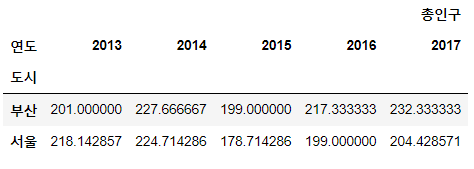

파이썬초짜의 기록