
사랑하는 사람이 인공지능을 공부하는 데 내 글이 도움이 되길 바라며...
오늘부터 혼공머신 책과 유튜브 인강을 함께 공부하면서 머신러닝의 기본 개념과 실습을 해보겠습니다!
.
.
.
내가 고른 이 생선은 도미일까 빙어일까
머신러닝은
누가 말해주지 않아도 "00cm 길이의 생선은 도미이다" 라는 기준을 찾아주고,
이 기준을 이용해 내가 고른 생선이 도미인지, 아닌지 판별할 수 있어요!
super coooooooool~~~
.
.
머신러닝을 위한 학습 데이터 만들기
도미 데이터를 준비합니다.
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0, 500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0, 700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]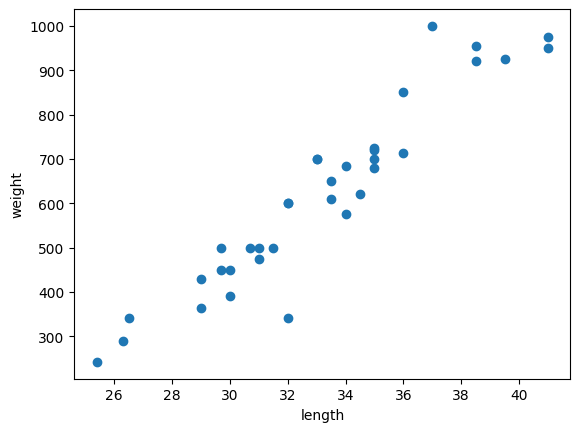
준비한 도미는 35마리 입니다.
도미의 길이와 무게는 선형적인 상관관계를 띄는 것을 산점도 그래프로 볼 수 있어요. 여기서 '길이'와 '무게'는 특성(Feature, 피쳐)라고 부릅니다.
길수록 무거운 건 어찌보면 당연하죠 ^^
빙어 데이터를 준비합니다.
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]준비한 빙어는 14마리 입니다.
도미와 빙어를 한번에 봅시다.
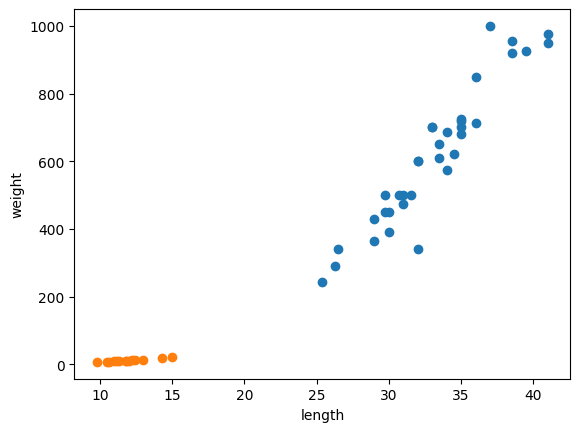
주황색 점은 빙어, 파란색 점은 도미를 나타냅니다.
빙어의 그래프도 마찬가지로 선형적인 관계의 분포를 띄지만 기울기가 도미보다 낮은 것으로 보아 무게가 길이에 영향을 덜 받는다고 볼 수 있어요.
.
길이와 무게를 하나의 리스트로 만들기
# 도미 길이 리스트와 빙어 길이 리스트를 합치기 (숫자를 더하는 게 아니에요!)
length = bream_length+smelt_length
# 도미 무게 리스트와 빙어 무게 리스트를 합치기
weight = bream_weight+smelt_weight
# 사이킷런 패키지를 사용하기 위해 피처 리스트를 세로로 늘어뜨린 2차원 리스트(리스트의 리스트)로 만들기
fish_data = [[l, w] for l, w in zip(length, weight)]
print(fish_data)

코드를 출력한 결과(너무 길어서 중간은 잘랐어요^^),
생선마다 길이와 무게가 포함된 리스트를 만들고, 각각의 리스트들이 전체의 큰 리스트 안에 들어간 것을 볼 수 있어요. (눈을 크게 떠봅시다 ㅎㅎ)
.
.
.
정답 데이터 만들기
현재 가지고 있는 데이터는 길이와 무게 뿐이지 그 길이와 무게를 갖는 생선이 도미인지 빙어인지는 알려주지 않았습니다.
지도학습을 하기 위해서는 답안지도 함께 만들어줘야 합니다.
만약 스무고개를 하는 데, 고개마다 답을 알려주지 않는다면 정답을 맞힐 수 없는 것과 같다고 생각하면 좋아요.
fish_target = [1]*35 + [0]*14
print(fish_target)[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]도미를 1, 빙어를 0으로 나타냈습니다.
앞에서 도미와 빙어를 순서대로 나열(리스트 합치기)했기 때문에 정답 리스트 안에는 1이 35번, 0이 14번 나옵니다.
.
.
K-Nearest Neighbors
(이하 KNN으로 부르겠습니다)
어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용합니다.
KNN을 사용하기 위해 준비해야할 것은 데이터를 모두 가지고 있는 게 전부입니다. 그리고 새로운 데이터를 예측할 때는 가장 가까운 직선거리에 어떤 데이터가 있는 지 확인하면 되는 거죠!
단점은, 데이터가 아주 많은 경우에는 직선거리를 계산하는 데 시간이 오래 걸리기 때문에 잘 사용하지 않습니다.
내 생애 첫번째 머신러닝 가즈아~~
# 사이킷런 패키지 임포트
import sklearn
# KNN 클래스 임포트
from sklearn.neighbors import KNeighborsClassifier
# 임포트한 KNN 클래스의 객체 만들기
kn = KNeighborsClassifier()
# 이 객체(모델)에 fish_data와 fish_target을 전달해서 학습(train)
kn.fit(fish_data, fish_target)
# 모델을 평가(정확도)
kn.score(fish_data, fish_target)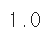
코드를 출력한 결과 1.0이라는 값을 얻었습니다.
이를 해석하면,
KNN모델을 이용하여 주어진 데이터를 학습한 결과, "새로운 100개 생선 중에 100개의 생선 모두 도미(1)인지, 빙어(0)인지 맞췄다" 는 것을 의미합니다.
(만약 0.79 이라는 값이 나왔다면 100개 중에 79개의 답을 맞췄다는 해석을 할 수 있는 것이죠!)
.
.
얼레벌레 따라오다 보니 벌써 첫번째 머신러닝을 마쳤네요?! ㅎㅎ 축하합니다!!
.
.
KNN에 대해서 더 알아볼까요?
사이킷런의 KNeighborsClassfier 클래스의
_fit_X 라는 속성에는 fish_data,
_y 라는 속성에는 fish_target
을 가지고 있습니다.
# 두 출력 결과 모두 동일
print(fish_data)
print(kn._fit_X)
# 두 출력 결과 모두 동일
print(fish_target)
print(kn._y)몇 명의 이웃에게 노크를 해볼까요~?
마음대로 정해도 되지만,
기본값은 5 입니다. 이 기준은 n_neighbors 매개변수로 바꿀 수 있어요.
kn49 = KNeighborsClassifier(n_neighbors=49)
kn49.fit(fish_data, fish_target)
kn49.score(fish_data, fish_target)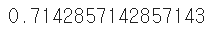
가장 가까운 49개의 이웃에게 노크를 하면 모든 이웃에게 노크를 하게 되는 것인데,
이는 49개 중에 도미가 35개로 다수이므로 앞으로 어떤 데이터를 넣어도 무조건 도미로 예측할 수밖에 없다는 것을 의미합니다!! (중요!!!!)
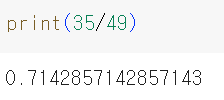
따라서 kn49 모델은 도미만 올바르게 맞히기 때문에 정확도 점수와 35/49의 값이 같게 나오게 됩니다.
.
.
.
마무리
오늘은 도미와 빙어를 구분하는 첫번째 머신러닝 프로그램을 KNN을 이용해 만들어보았습니다.
머신러닝 첫 시간인데 너무 어려웠나요~?
머신러닝을 즐겁게 시작하길 바라는 마음으로 준비해봤습니다!!
앞으로 더 어려운 알고리즘들이 당신을 기다리고 있으니 화이팅하자구요~~^^


이렇게 유익한 내용을 공유해주셔서 감사합니다.