실무에서 AI프로젝트 생애주기는 어떻게 될까? SW2.0으로 인한 패러다임으로 데이터셋 제작의 중요성이 대두 되었고, 생애주기에도 데이터셋 제작의 중요성이 강조되었다.
실제 상품화되는 모델의 성능을 개선하고 유지보수하는데 좋은 데이터를 확보하는 것은 매우 중요하다.
AI Research vs AI Production
-
AI Research
정해진 데이터셋과 평가 방식으로 더 좋은 모델을 찾음 -
AI Production
데이터셋은 준비되어 있지 않고 서비스 요구사항만 존재함, 따라서 서비스에 적용되는 AI 개발 업무의 상당 부분이 데이터셋을 준비하는 작업임
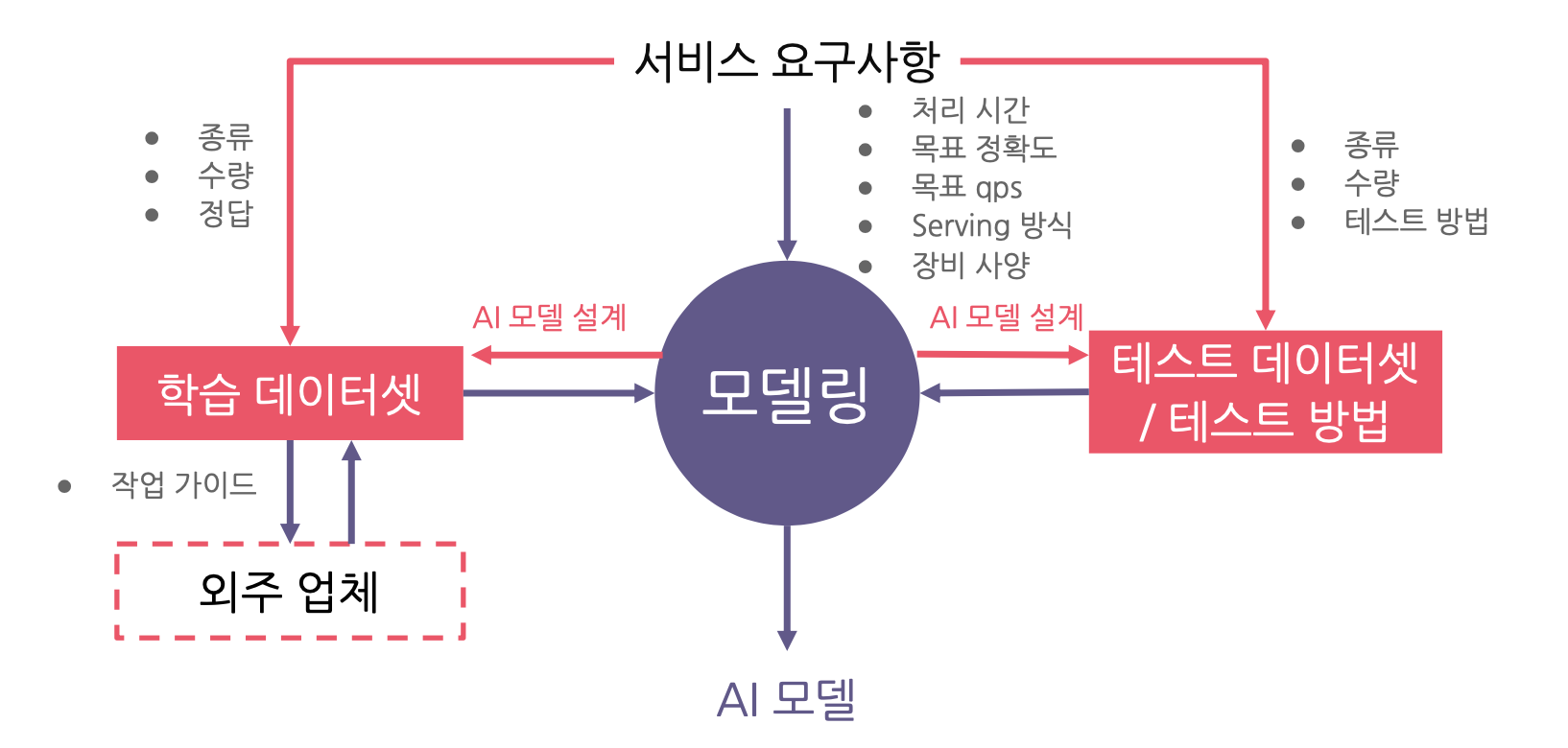
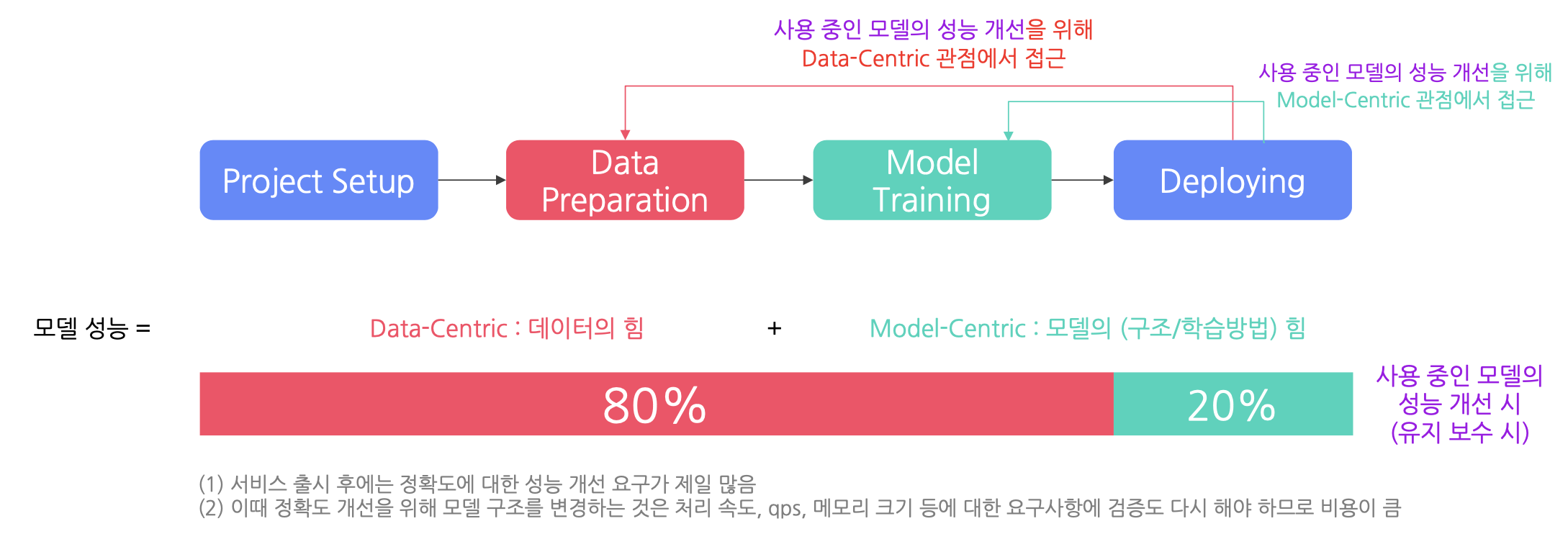
AI 서비스 개발 과정
-> 이때 서비스를 위한 요구사항을 충족시키는 모델을 지속적으로 확보하는 것이 중요한다
-> 이 방법은 데이터를 통해 모델 성능을 끌어올리는 방법과 모델 성능을 끌어올리는 방식이 있다.
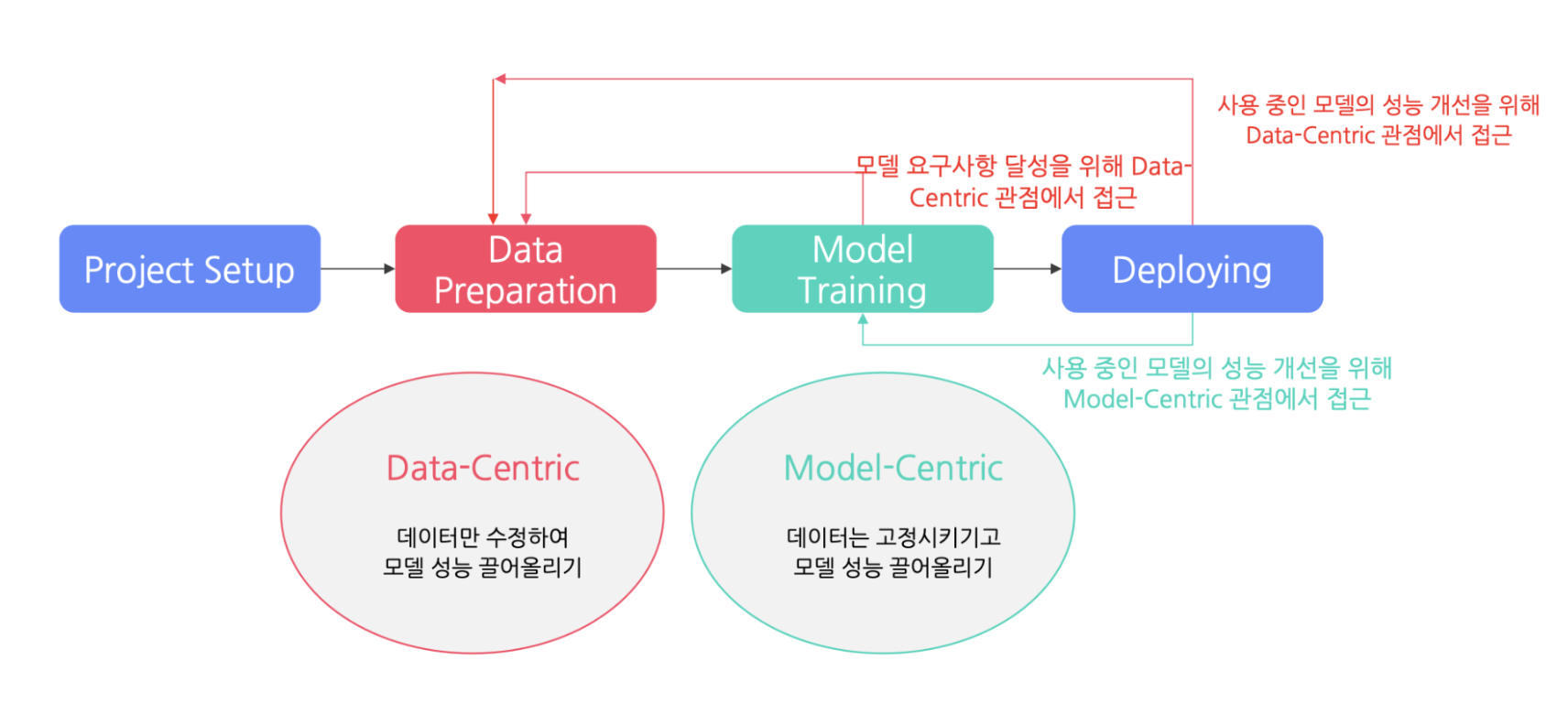
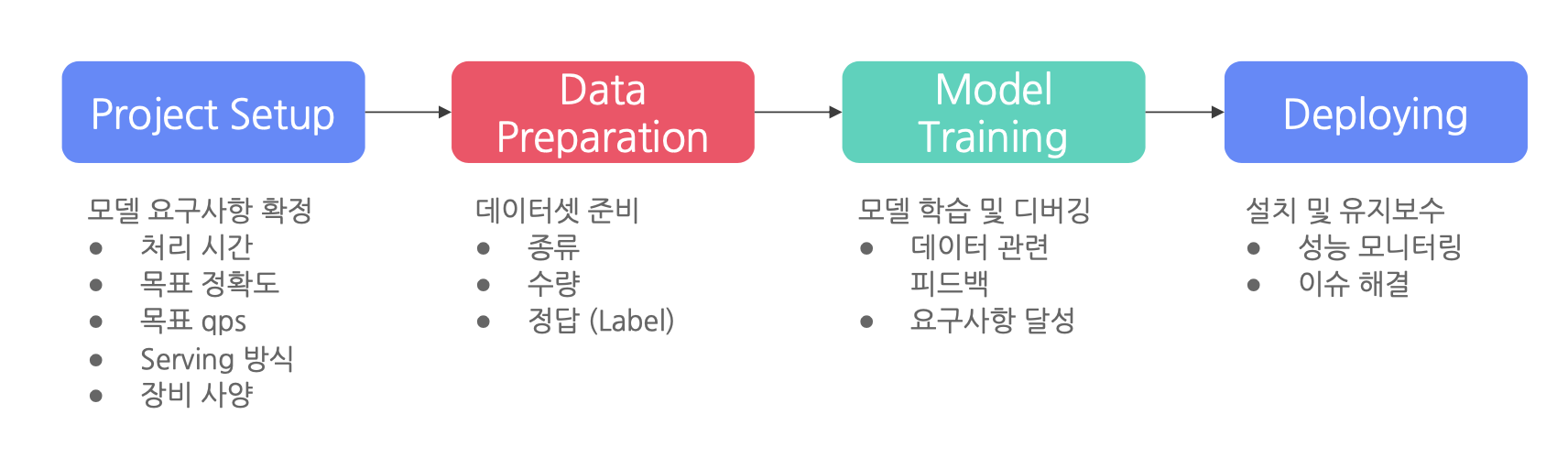
-
서비스화를 위한 모델 성능 달성 시 데이터와 모델의 비중
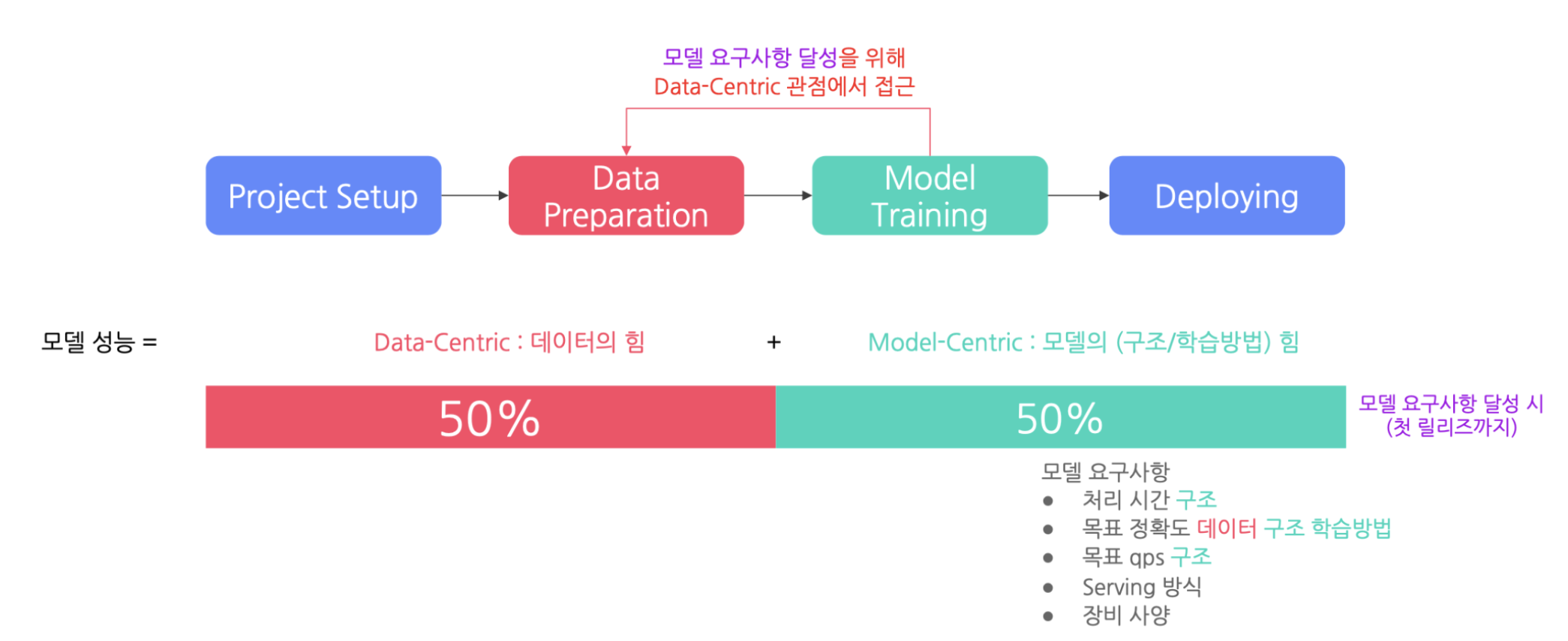
-
서비스 이후 모델 성능 개선 시 데이터와 모델에 대한 비중
데이터 관련 업무의 어려움
데이터 관련 업무가 많은 이유
어떻게 하면 좋을지 잘 안알려져 있다
학계에서 데이터를 다루기 힘든 이유
1. 좋은 데이터를 많이 모으기 힘듦
2. 라벨링 비용이 크다
3. 작업 기간이 오래 걸린다
데이터 라벨링 작업은 생각보다 많이 많이 어렵다
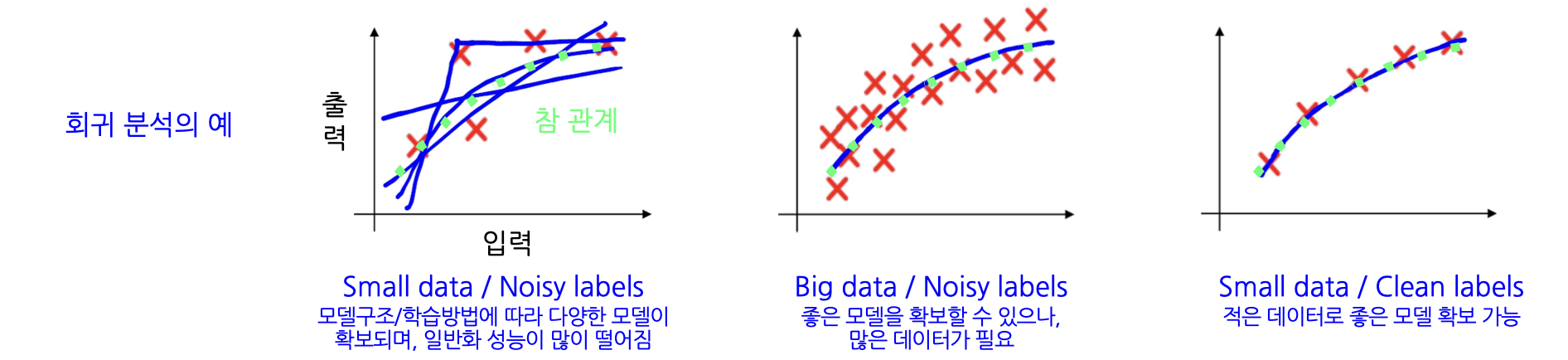
-> 데이터가 많다고 모델 성능이 항상 올라가는 것이 아니다, 따라서 제대로된 라벨링이 중요하다. 하지만 데이터 라벨링 작업 생각보다 많이 어렵다
=> 라벨링 노이즈는 학습에 얼마나 영향을 줄까?
=> 라벨링 노이즈를 학습 시 무시하게 하려면 적어도 깨끗이 라벨링된 결과가 2배 이상 필요하다
=> 그렇다면 양이 적더라도 제대로된 데이터만 있으면 괜찮을까?
=> 적은 데이터도 골고루 있어야지 너무 유사한 데이터만 있으면 좋은 모델을 확보하기 힘들다
라벨링 노이즈와 데이터 분포와 연관성
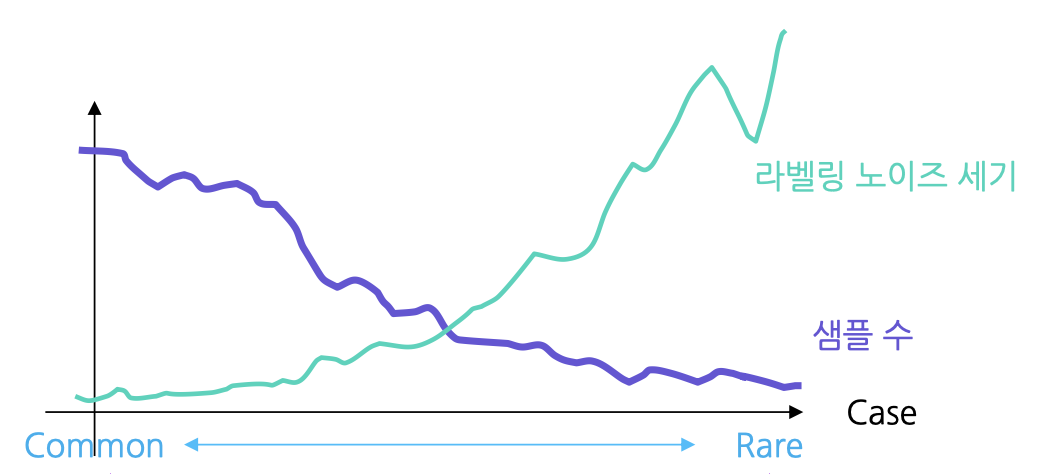
- Common : 자주 보는 샘플은 라벨링 작업자도 인지하고 있고, 작업 가이드를 만들 때 해당 데이터를 고려해서 만들기 때문에 라벨링 노이즈가 적다
- Rare : 희귀 케이스인 경우 작업 가이드에서 다루지 않을 수도 있고, 라벨링 작업자별로 다르게 생각해 작업할 가능성이 크다
ex)


데이터 불균형을 바로 잡기가 많이 어렵다
=> Rare 케이스일 경우 해당 샘플들을 모아 라벨링 가이드를 만들어야됌

=> Rare케이스를 바로 잡는 과정은 어떻게 효율화 할 수 있을까?
1. 해당 task에 대한 지식이 많아야 예외를 미리 인지 할 수 있다.
ex) 테슬라의 예외처리(트리거라고 지칭하고 221를 정의하고 관리함)

- 모든 경우를 완벽하게 아는 경우는 불가능하지 이를 반복적이고 자동화된 작업으로 만들어야함
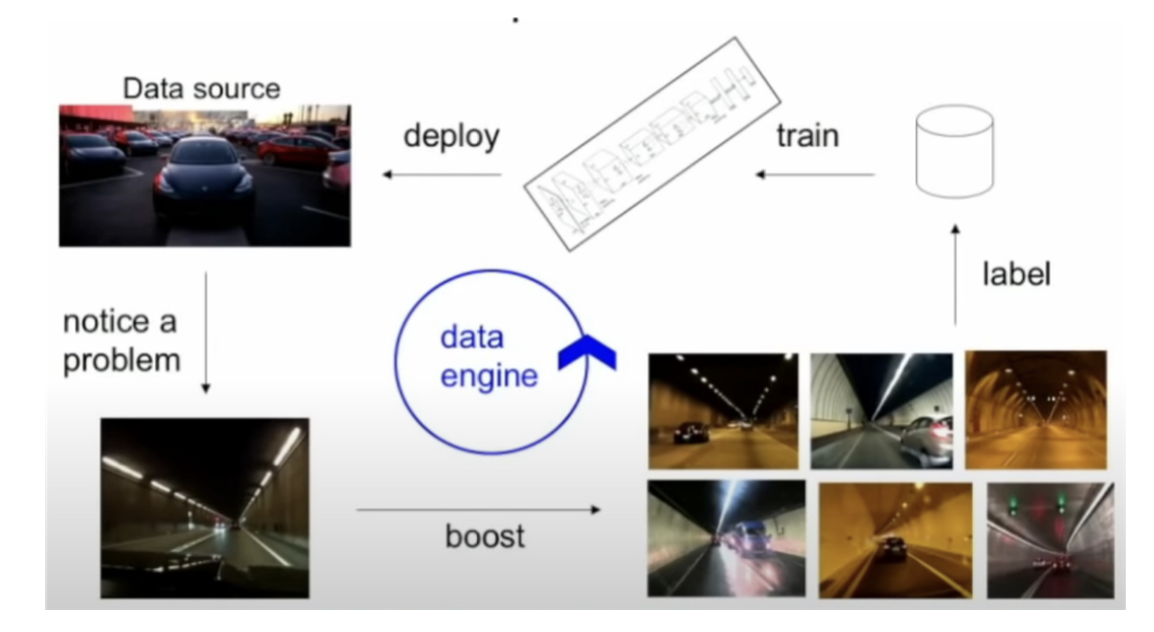
Data Engine & Flywheel
=> 데이터 관점에서 서비스 개발시 필요한 기능
-
데이터셋 시각화
-> 데이터, 레이블 분포 시각화, 레이블 시각화, 데이터 별 예측값 시각화 -
데이터 라벨링
-> 태스크 특화 기능, 라벨링 일관성 확인, 라벨링 작업 효율 확인, 자동 라벨링,... -
데이터셋 정제
-> 반복 데이터 제거, 라벨링 오류 수정 -
데이터셋 선별
-> 모델 성능 향상을 위해 어떤 데이터를 라벨링 해야하는가?
