OCR?
OCR : Optical Character Recognition
(vs STR : Scene Text Recognition)
OCR = 글자읽기 = 글자 영역 찾기 + 영역 내 글자 인식

Object Detection VS OCR
Object Detection : 입력이미지에서 정해진 클래스들이 해당하는 각 객체들의 위치는 어디인가?
OCR = Text Detector + Text Recognizer + Serializer + Text Parser
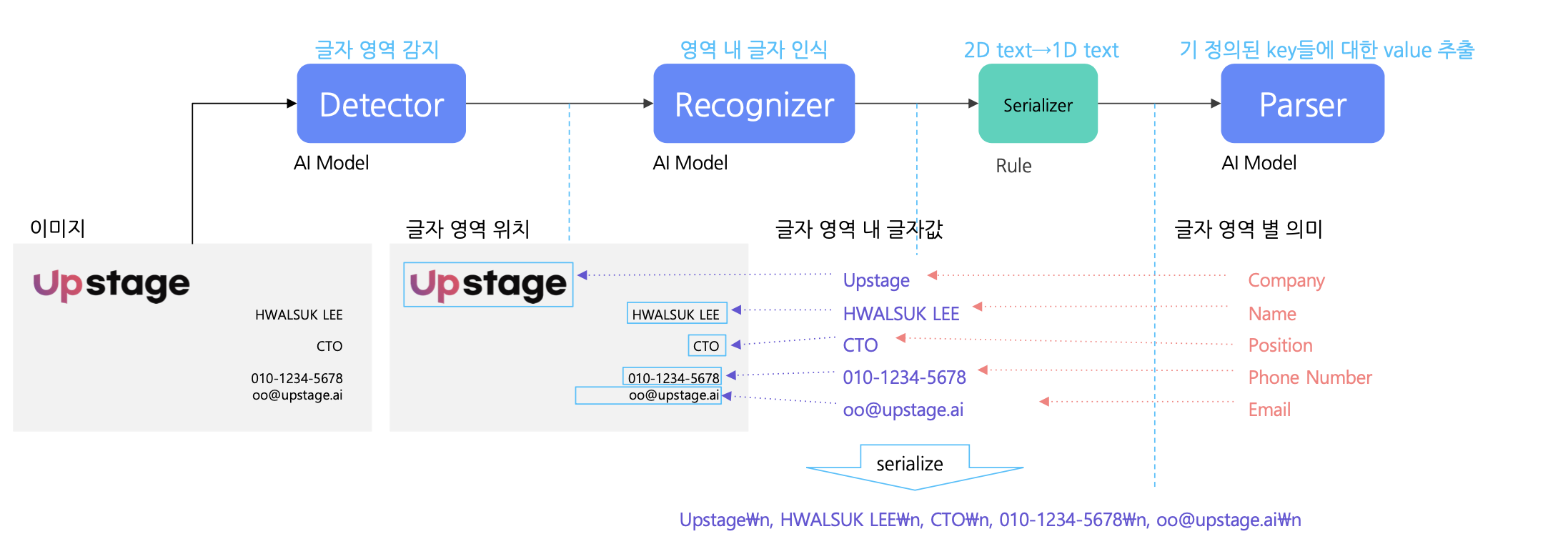
Text Detection : 클래스 정보가 필요없고, 글자 영역에 해당 하는 객체의 위치만 추정함
=> Text Detector : 이미지 입력에 글자 영역 위치가 출력인 모델, Object Detection과 다르게 영역의 종횡비, 객체 밀도
=> Text Recognizer : 하나 글자 영역 이미지 입력에 해당 영역 글자열을 출력하는 모델
OCR : Computer Vision과 Natural Language Processing의 교집합
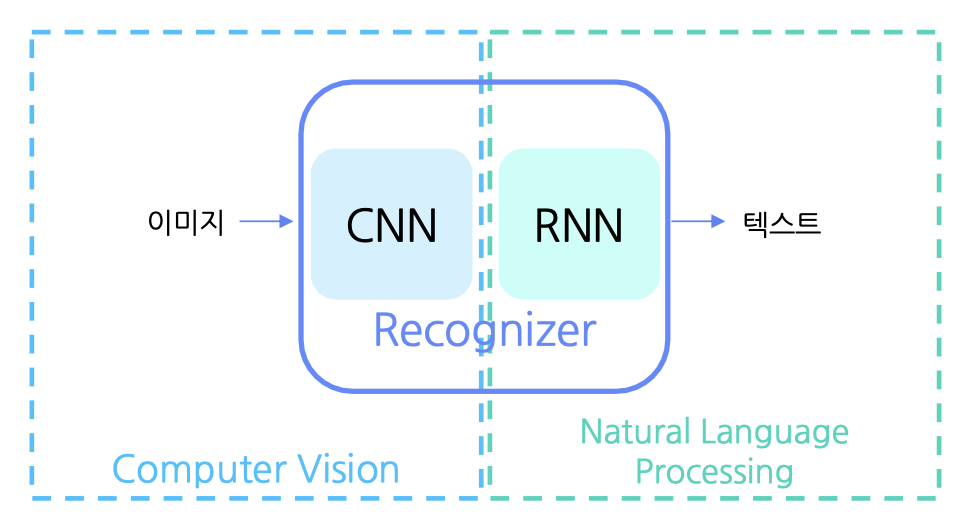
(cf. 유사한 기술 영역으로 Image Captioning(이미지 설명하는 문장생성)이 있음)
=> Serializer : OCR 결과값을 자연어 처리 하기 편하게 일렬로 정렬하는 모듈, 상용화된 기술은 규칙기반이 대부분임
=> Text Parser : 자연어 처리 모듈 중 가장 많이 사용되는 것은 기 정의된 Key들에 대한 value 추출임
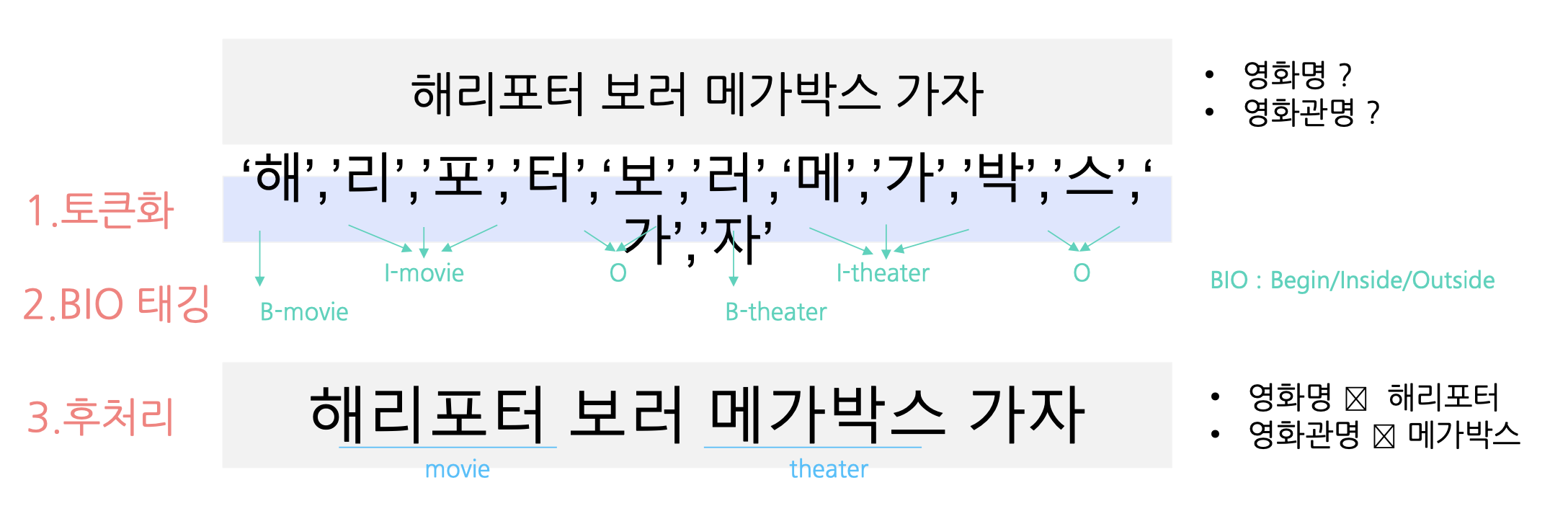
ex ) BIO 태깅을 활용한 개체명 인식 : 문장에서 기 정의된 개체에 대한 값 추출


AI Learning, Parcelled Innovations, Carrying All