
다차원 배열 vs Dataframe
딥러닝 Input 데이터 통계 분석 / 머신러닝
Numpy 라이브러리 Pandas 라이브러리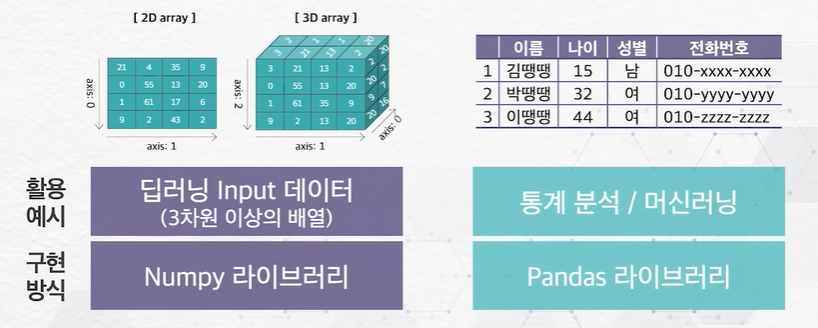
Numpy 라이브러리
conda install numpy- 고속연산
- 쉽고 빠른 배열 변환
- 다양한 함수 제공
Numpy 배열
| 1 | 2 | 3 | 4 |
|---|
Numpy가 제공하는 ndarray의 shape/ndim/size 속성을 이용해
배열의 형태/차원/원소 개수 파악 가능
ex) 1D array
shape: (4,)
ndim: 1
size: 4
Numpy 데이터 선택
N차원 배열에서 특정 면/행/열 등을 탐색하거나
조건에 맞는 데이터를 확인하고자 할 때 사용
Slicing: 배열을 쉽게 자를 수 있음 ex) arr[1:]
Indexing: 리스트와 다르게 [x,y] 표기법 가능 ex) arr[1, 0]
Boolean Indexing: 특정조건에 따른 값을 배열로 추출 ex) arr[arr > 3]
Fancy Indexing: 배열에 인덱싱 값을 주어 변환 ex) arr[[0,0]]
Pandas 라이브러리
conda install pandas-
강력한 스프레드시트 처리 (쉽고 빠른 데이터 선택)
-
데이터 통계 분석
-
데이터 구조
- Dataframe, Series로 구분됨
Pandas 데이터 선택
Dataframe에서 특정 열/행을 탐색하거나
조건에 맞는 데이터를 확인하고자 할 때 사용
Slicing: 배열을 쉽게 자름 ex) df[0:2]
Indexing: 컬럼 이름 명시 ex) df['a']
Boolean Indexing: 특정조건 ex) df[df['a'] > 20]
Fancy Indexing: 컬럼 이름을 리스트에 담아서 출력 ex) df[['a','b']]
loc 인덱서: 원하는 행렬, 컬럼 명 문자열 ex) df.loc[행, 원하는열이름]
iloc 인덱서: 원하는 행렬, 컬럼 숫자 ex) df.iloc[행, 열의 순서]

난 성미다.