
가설 검정이란?
- 모집단에 어떤 가설을 설정한 뒤, 통계 기법을 이용한 가설의 채택 여부를 확률적으로 판정하는 통계적 추론의 방법
정치분야 : 주류세 인상은 음주운전율을 줄였다
| 귀무가설 | 대립가설 |
|---|---|
| 비교하는 값과 차이가 없다 | 비교하는 값과 차이가 있다 |
| >기존 이론 가설 H0: Null Hypothesis | >연구자 목적, 주장 H1: Alternative Hypothesis |
가설 검정 통계적 오류
제 1종 오류와 제 2종 오류가 존재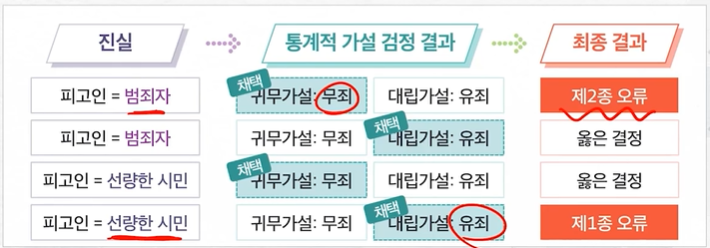
| 의사결정 \ 실제 | 귀무가설 : 진실 | 대립가설 : 진실 |
|---|---|---|
| 귀무가설 선택 | 옳은 결정 신뢰수준 (1-α) | 제2종 오류 (β) |
| 대립가설 선택 | 제1종 오류 유의수준 (α) | 옳은 결정 검정력 (1-β) |
제1종 오류 : H0이 참이지만 H1으로 잘못 선택 → "유의수준"이라고 불림
제2종 오류 : H1이 참이지만 H0으로 잘못 선택
가설 검정 방법
- 목적에 맞는 설정 필요
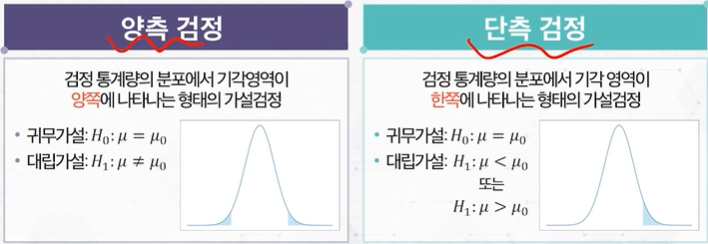
가설 기반 의사 결정 방법
- 검정 통계량과 유의 확률을 토대로 가설 채택 여부 결정
검정통계량>기각역→ 귀무가설 기각
검정통계량<기각역→ 귀무가설 채택
유의확률<유의수준→ 귀무가설 기각
유의확률>유의수준→ 귀무가설 채택
🌟기각의 기준을 어떻게 결정하느냐
기각역 세워서 판단, 귀무설을 기각하게되는 검정 통계량의 관측값의 영역
귀무가설이 옳다라는 전제하에 검정통계량이 기각역에 속할 확률이 유의수준인 검정통계량 분포에 일부 영역이다.
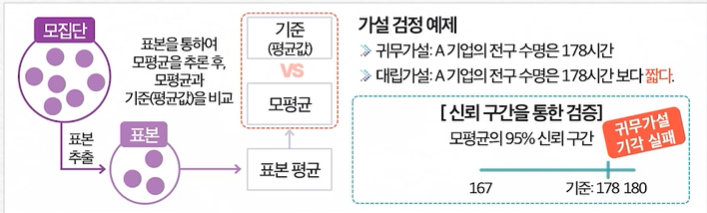
단일표본 t검정
-
가장 기본적인 가설 검정 중 하나 한 모집단의 평균값과 기준값의 차이를 비교하는 분석법
-
두 집단 간 평균의 차이를 비교하는 분석법
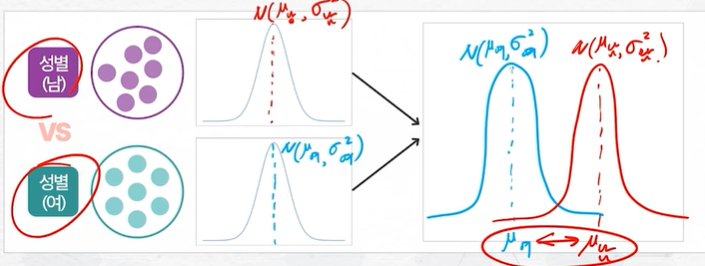

연구 목적에 따른 가설 검정 예제
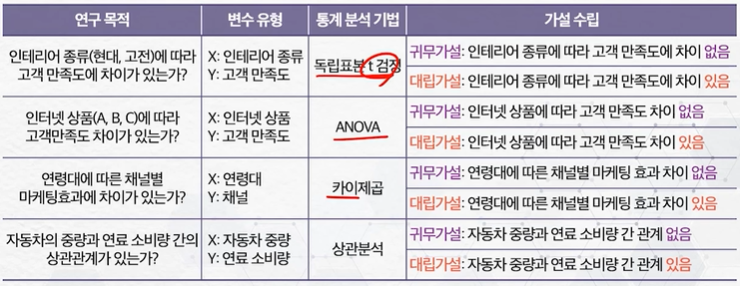
가설 검정 순서
- 가설 수립 -> 2. 판단 기준 수립 -> 3. 통계 기법 도출 -> 4. 분석 통계량 산출 -> 5. 판단 기준 -> 6. 결과 도출
가설 검정 - 두 집단 평균 비교
목적 : 독립된 두 표본집단의 평균 차이에 대한 가설 검정
예제: k 모바일 대리점 내부 인테리어 종류에 따라 고객 선호도에 대한 차이가 통계적으로 유의미한지 확인import numpy as np
import pandas as pd
from scipy import stats #scipy: 수학 과학 공학에 특화된 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns
#데이터셋 로딩
df = pd.read_csv('~')
display(df.head())
#데이터셋 셔플
df = df.sample(frac=1, random_state=0).reset_index(drop=True)
df.shapeAssumption
-
독립성
독립변수 그룹은 서로 독립적 두개의 집단을 구성하는 구성원이나 구성들이 서로 관계가 없음을 의미 즉, 아무런 관계가 없어야함 -
정규성 확인
가설을 세워두고 입증해야함 귀무 가설 : H0 정규성 만족 대립 가설 : H1 정규성 만족 X
classic_pref = df.loc[~]
modern_pref = df.loc[~]
#정규성 확인
print('classic 인테리어 선호도 정규성 : ', stats.shapiro(classic_pref))
print('mordern 인테리어 선호도 정규성 : ', stats.shapiro(modern_pref))- 등분산성 확인
두 집단이 동일한 분산을 가지는가 F 검정으로 확인 - H0 : 분산 동일, H1 : 분산 동일 X
독립표본 t 검정
print(np.mean(classic_pref))
print(np.mean(morden_pref))
result = stats.ttest_ind(classic_pref, modern_pref, equal_var=False)
result
난 성미다.