
다변량 시각화
- 두 개 이상의 변수로 구성된 데이터의 관계를 시각화 기반으로 파악하는 데이터 탐색 유형
주어진 변수 간의 패턴 및 관계를 다양한 그래프의 시각화를 통해 전체적으로 파악
다변량 시각화 종류
| 데이터 조합 | 시각화 방안 | 목적 |
|---|---|---|
| 범주형-범주형 | 모자이크플롯 | 두 개 범주형 변수 내 범주 별 조합의 빈도 크기를 개략적으로 파악 |
| 범주형-연속형 | 박스플롯 평행좌표 | 범주 별 기술통계량 및 경향성을 개략적으로 파악 |
| 연속형-연속형 | 산점도 | 연속형 변수 간 관계성을 개략적으로 파악(선형/비선형 및 음양 방향 등) |
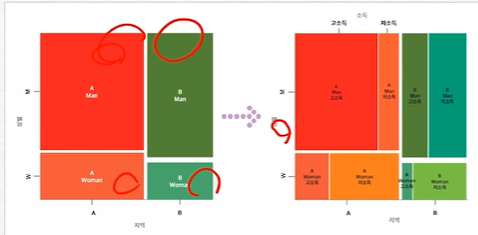
1. 모자이크플롯
- 범주 그룹 간 비중의 차이를 전체적으로 파악 가능
- 범주 수가 많고, 각 조합별 비중 차이가 크지 않을 경우 전체적 파악이 어려울 수 있음
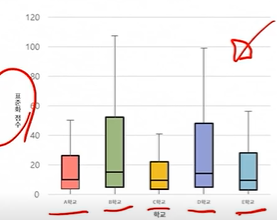
2-1. 박스플롯
- 많은 데이터를 눈으로 직접 확인하기 어렵고, 대표적 통계 값만으로 파악하기 어려울 때 용이함
- 범주 그룹(범주형 변수)간 수치(연속형 변수)의 집합 범위와 중앙값, 이상치 등을 빠르게 확인할 수 있음
- 비시각화 기반의 단순 수치값 비교보다 데이터가 설명하는 많은 정보 획득 가능
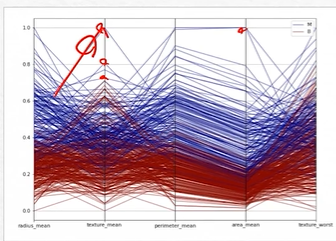
2-2. 평행좌표
- 연속형 데이터 기반으로 범주 별 경향성 파악에 용이함
- 데이터의 트렌드 판단 가능
- 연속형 변수 간 단위 표준화가 이루어지기 전의 데이터로 시각화할 경우 파악이 어려울 수 있음
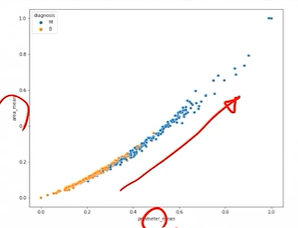
3. 산점도
- 연속형 데이터 간의 관계를 그래프상으로 어떠한 관계가 있는지 파악하기 위함
- 변수 간 분포를 통해 선형 혹은 비선형 관계 및 음양의 방향 등을 빠르게 파악할 수 있음
- 범주 Label 간 비교가 필요한 경우, 해당 부분의 그룹 정보를 표시하면 변수 간 관계 및 범주 그룹 간 관계를 함께 파악 가능
모자이크 플롯
범주 별 조합 그룹 비교 시각화
조합 간의 크기의 우위를 개략적으로 파악하는 것이 목적#모자이크 플롯 시각화 패키지 로딩
from statsmodels.graphics.mosaicplot import mosaic
#2개 범주 시각화
mosaic(housing_data,['MEDV_G', 'INDUS_G'])
plt.show()박스플롯
#box plot 시각화
plt.figure(figsize = (10,10))
sns.boxplot(data = housing_data, x='MEDV_G', y='RM')
plt.show()
#데이터 관측치 별 위치 poin추가
plt.figure(figsize = (10,10))
sns.boxplot(x="MEDV_G", y="RM", data=housing_data)
sns.striplot(x="MEDV_G", y="RM", data=housing_data, color="0.4")
plt.show()평행좌표
#평행좌표 시각화 패키지 로딩
from pandas.plotting import parallel_coordinates
#실습
plt.figure(figsize=(15,10))
parallel_coordinates(sub_data, 'MEDV_G', colormap = plt.get_cmap('jet'), alpha=0.5)
plt.show()산점도
연속형 변수 간 관계를 개략적으로 파악하기 위한 시각화
변수 간 선형성 및 양과 음의 관계성 등을 파악 가능#하위계층 비율과 평균 방의 개수간 상관관계확인
plt.figure(figsize=(10,8))
sns.scatterplot(x='LSTAT', y='RM', data = housing_data)
plt.show()
import scipy.stats as stats
stats.pearsonr(housing_data.LSTAT, housing_data.RM)다양한 상관관계의 정도를 시각화하는 방안 : Heatmap
- 본래
Heatmap은 범주형 자료의 범주 별 별로 연속형 자료를 집계한 자료를 사용하여, 집계한 값에 비례하여 색을 다르게 해서 2차원으로 자료를 시각화하는 영역에 활용 - 연속형 자료이나, 테이블 내 많은 조합 간 상관관계의 강도 및 정도의 강약을
Heatmap으로 시각화하여 쉽게 파악 가능- 컬럼 별 조합: 범주 별 조합
- 컬럼 별 상관계수: 범주 별 강도(빈도와 유사한 수치적 표현)
#모든 컬럼 간 상관관계 도출
np.round(housing_data.corr(), 2)
#상관관계 데이터프레임을 Heatmap으로 시각화
plt.figure(figsize=(15,12))
sns.heatmap(housing_data.corr(), annot=True, cmap='RdYIGn_r')
plt.show()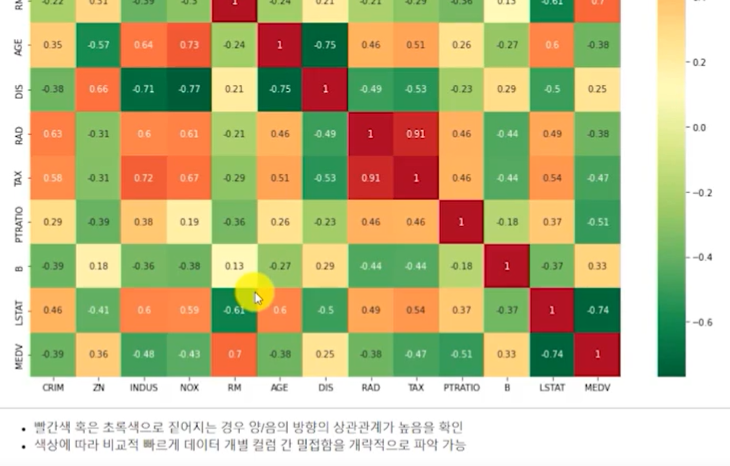
#범주별 빈도를 시각화를 위해 샘플 테이블 생성
sample_df = pd.DataFrame(sample_data, columns=columns)
#데이터 pivot
pivot_df = sample_df.pivot("city","year","visitor")
#pivot을 heatmap으로 시각화
plt.figure(figsize=(10,8))
sns.heatmap(pivot_df, annot=True, fmt='d') #annot : 빈도수, fmt : 빈도의 정수표현
plt.show()다변량 데이터 시각화 : 데이터 관계, 구성, 현상을 한눈에 파악할 수 있는 장점 존재, 데이터 탐색 과정은 향후 데이터 분석 모델링 과정을 위한 인사이트확보를 위한 중요한 작업

난 성미다.