
다변량 비시각화
- 두 개 이상의 변수로 구성된 데이터의 관계를 교차표 및 상관계수 등으로 파악하는 데이터 탐색 유형
주어진 변수 간의 관계를 수치 및 통계적 지표 기반으로 파악하는 것이 목적 - 가장많은고민
다변량 비시각화 종류
| 데이터 조합 | 비시각화 방안 | 목적 |
|---|---|---|
| 범주형-범주형 | 교차표 | 두 개 범주형 변수의 범주 별 연관성 및 구성 파악 |
| 범주형-연속형 | 범주 별 통계량 | 범주 별 대표 통계량 비교 파악 |
| 연속형-연속형 | 상관계수 | 두 개 연속형 변수의 관계성 정도 파악 |
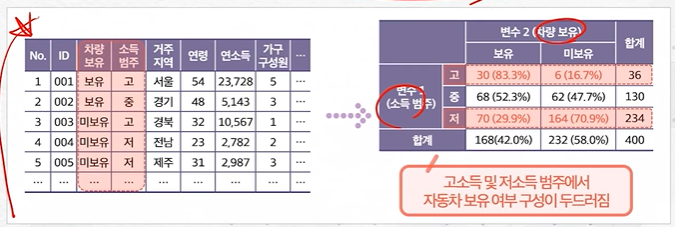
1. 교차표
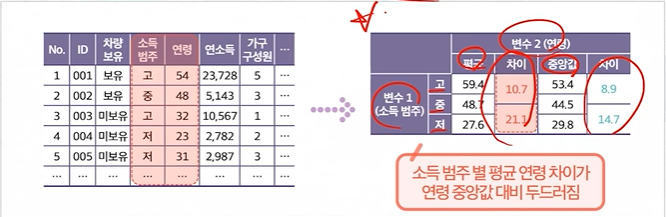
2. 범주 별 요약 통계량
3. 상관계수(Corr. coefficient)
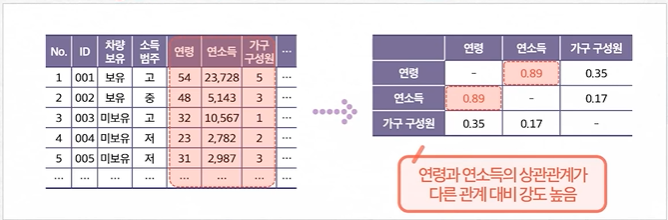
높은 상관계수 : 비슷한 정보를 제공하는 밀접한 관계의 변수
- 회귀분석에서 독립변수 간에 강한 상관관계 발생 -> 다중공선성 발생
- 독립변수 간의 관계는 독립적이라는 회귀분석 가정에 위배
- 회귀 계수가 불안정하여 종속변수에 미치는 영향력을 올바르게 설명치 못하므로 모델의 안정성 저해
🌟데이터 탐색 중 상관분석 결과를 통해 모델링 사전 단계 내 고려 필요
교차표
범주-범주 변수 교차하여 파악함으로써 각 범주 조합 간의 구성을 도출
조합 간의 구성을 통해 범주형 변수 간 관련성을 확인#활용데이터 확인
#CHAS컬럼을 범주형 데이터로 변환
#타겟변수인 주택가격 범주화
#평균 가격 기반으로 고가, 저가 범주로 구분
medv_bins = [0, np.mean(housing_data['MEDV']), np.max(housing_data['MEDV'])]
housing_data['MEDV_G'] = pd.cut(housing_data['MEDV'], medv_bins, labels=medv_names)
#주택가격과 범주화된 독립변수 간 관계확인
#1) CHAS와 관계
rst_CHAS = pd.crosstab(housing_data['CHAS'], housing_data['MEDV_G'], mergins = True)
- 대부분의 타운이 강경계에 위치하지 않음
#관측 범위를 평균을 기준으로 구간화, INDUS 변수 범주화
.
.
#주택가격과 범주화된 독립변수 간 관계확인
#1) INDUS_G와 관계
.
.
#관측 범위를 평균을 기준으로 구간화, RAD 변수 범주화
#2) RAD_G와 관계
.
.#INDUS_G, RM_G를 교차하여 MEDV_G 구성 확인
rst_df = pd.crosstab([housing_data['RAD_G'], housing_data['INDUS_G']], housing_data['MEDV_G'], margins = True)
#관측 범위를 동일한 길이로 구간화
#3) INDUS 변수 범주 범위 재조정
.
.범주 별 요약 통계
범주-연속 변수 교차하여 파악함으로써 각 범주 조합 간의 대표 수치 도출
대표적 수치 도출을 통해 범주 간 차이 확인#주택가격 범주 별 INDUS 변수 집계 - 평균, 중앙값 활용
pd.DataFrame(housing_data.groupby(['MEDV_G'])['INDUS'].mean())
pd.DataFrame(housing_data.groupby(['MEDV_G'])['INDUS'].median())상관관계
연속-연속 변수의 상관분석을 통해 관계성 정도를 파악
상관계수를 기반으로 연속형 변수 간의 밀접성 파악
도출방안
1. 한 컬럼과 다른 모든 컬럼들의 Correlation (corrwith)
2. 모든 컬럼간의 Correlation (corr)#상관관계 확인 : Person 상관계수
np.round(housing_data.corrwith(housing_data['MEDV']), 2).sort_values()
#모든 컬럼 간 상관관계 도출
np.round(housing_data.corr(), 2)
#상관관계 유의성 검정
import scipy.stats as stats
stats.pearsonr(housing_data.TAX, housing_data.RAD)
🌟논리적으로 적합한 변수를 선택 혹은 종속변수와 관계성을 더 보이는 변수 선택
모든 상관관계를 파악하는 경우 컬럼이 많아질수록 파악이 어려움 - 시각화의 필요성 존재!

난 성미다.