
탐색적 데이터 분석
- EDA(Exploratory Data Analysis)는 데이터를 다양한 측면에서 바라보고 이해하는 과정
통계적 요약, 분포 파악 및 시각화 등의 기법을 통해 직관적으로 데이터 특성 파악
EDA 기본 개요
- 데이터가 표현하는 현상을 이해하고 다양한 패턴 발견
| 속성파악 | 관계파악 |
|---|---|
| 분석 목적 및 개별 변수 속성 파악 | 변수 간의 관계 파악 및 가설 검증 |
| ex) 가격 예측 분석 과제에서 가격 컬럼 유형 및 관측치 범위 확인 | ex) 건물의 건축연도와 가격 사이 유의미한 영향 관계 유무 확인 |
사전 데이터 탐색
| 데이터 정의 확인 | 실 데이터 확인 |
|---|---|
| 정의서 기반 데이터 확인 > 테이블별 변수 목록, 개수, 설명, 타입 등 | 실제 데이터 개요, 결측치, 형상 등 확인 > head,tail,info 기반확인 |
| 변수별 정의된 범위 및 분포 등 확인 > 관측치 번위. 분포 등 |
요인별 EDA 유형 구분
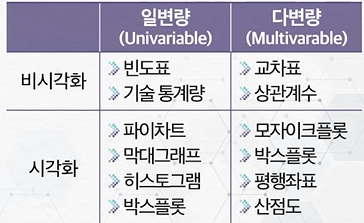
- 데이터 변수 개수가 몇 개인가?
- 결과를 어떻게 파악할 것인가?
- 데이터의 유형은 무엇인가?
⇩⇩⇩
일변량 비시각화
- 분석 대상 데이터가 하나의 변수로 구성되고 요약 통계량, 빈도 등으로 표현하는 탐색 유형
단일 변수이므로 원인 및 결과를 다루지는 않으나 데이터 설명 및 구성을 파악
범주형 비시각화
| 빈도표(범주형 데이터의 구성 및 비율 등을 확인) |
|---|
| - 특정 범주 별 빈도 파악이 목적 |
| - 범주 별 빈도 수 기반의 구성 파악 및 결측치 빈도 파악 |
| - 데이터 전체 수 대비 각 범주 별 분포 파악 |

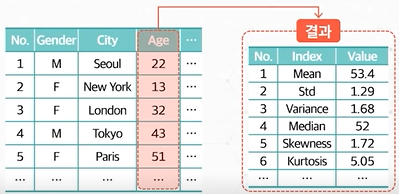
연속형 비시각화
| 주요 통계 지표(연속형 데이터의 기술 통계량 및 주요 지표 등을 확인) |
|---|
| 1. 평균, 분산 등의 기술 통계량 (Descriptive Statistics) |
| 2. 중앙값 등의 시분위수 (Quantile Statistics) |
| 3. 왜도, 첨도 등의 분포 관련 지표 (Distribution) |
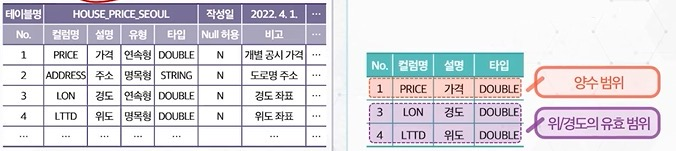
테이블 정의서
- 테이블 내 존재하는 데이터들의 기본 정보 확인을 위한 관리 체계
- 변수(컬럼) 별 컬럼명, 속성염, 타입, 길이, NULL 허용여부 등 정보 확인import numpy as np
import pandas as pd#sklearn 패키지 로딩, 보스턴 주택가격 데이터 로딩
import warnings
from sklearn.datasets import load_boston
with warnings.catch_warnings():
warnings.fllterwarnings('ignore')
data = load_boston()
#데이터 프레임 생성 및 머지
X = pd.DataFrame(data.data, columns = data.feature_names)
Y = pd.DataFrame(data.target, columns = ['MEDV'])
housing = pd.merge(X, y, left_index = True, right_index = True, how = 'inner')
housing#데이터 copy
housing_data = housing.copy()
#개요 및 결측치 확인
housing_data.info()
#데이터 head, tail 확인
housing_data.head(10)
housing_data.tail(10) #데이터 종합성 체크
#일부 데이터 범위 확인
print('CRIM_min', min(housing_data.CRIM) #AGE, MEDV 등도 진행, 데이터별 관측 정의서를 기반으로 확인범주형 일변량 비시각화
#CHAS컬럼을 범주형 데이터로 변환
housing_data = housing_data.astype({'CHAS': 'object'})
#범주형 데이터 빈도표
pd.crosstab(housing_data.CHAS, columns = 'count') #경계에 있고 없는 town 지역 개수가 차이를 보임
#비율 환산
pd.crosstab(housing_data.CHAS, columns = 'count', normalize=True)
#합 추가하기
pd.crosstab(housing_data.CHAS, columns = 'count', margins=True)
#합 추가하기
pd.crosstab(housing_data.CHAS, columns = 'count', normalize=True,margins=True)연속형 일변량 시각화
#CHAS컬럼을 범주형 데이터로 변환
#기술통계량 및 4분위수 도출
housing_data.describe()
#4분위수 기반의 IQR연산
q1 = housing_data['CRIM'].quantile(0.25)
q3 = housing_data['CRIM'].quantile(0.75)
iqr = q3-q1왜도 첨도란?
- 왜도(Skewness): 분포의 비대칭성을 나타내는 척도, 얼마나 비대칭인지 확인
- 왜도의 경우 값이 0보다 크면 왼쪽으로 치우치고, 오른쪽 꼬리가 긴 형태의 분포를 보임
- 첨도(Kurtosis): 분포의 뾰족한 정도를 나타내는 척도, 평균에 관측치가 얼마나 모여있는지를 확인
- 첨도의 경우 값이 0보다 크면 뾰족한 모양을 지님# 왜도, 첨도 확인
print('왜도', round(housing_data['CRIM'].skew(), 4))
print('첨도', round(housing_data['CRIM'].kurt(), 4))Pandas-Profiling 패키지 소개
- 기본 EDA를 자동화하여 리포트를 생성하는 패키지
데이터 head, tail 및 결측치, 범주형 및 연속형 변수의 주요 통계량 도출, 시각화 제공
특징 요약
- 간단한 코드 구현으로, 데이터의 대부분 정보 확인 가능
- 의사결정을 위한, 리포트를 자동으로 생성하여 업무 활용 가능
- 다만, 큰 데이터를 대상으로 실행시 데이터 요약 및 리포트생성에 오랜 시간이 소요됨
- 큰 데이터를 대상으로 사용을 고려할 시, 적절하게 추출한 샘플데이터를 대상으로 전체적인 데이터 흐름만 살펴보는 방안을 고려 가능
리포트 카테고리
- Overview: 데이터 개요 확인
컬럼 수, 데이터 관측치 수, 결측치 수, 중복 데이터 행, 컬럼 타입 별 개수 등
- Variable: 각 컬럼 별 타입 및 정보 확인
고유값 개수
연속형: 평균, 최대, 최소 및 Quantile statistics 및 왜도 첨도 등 통계량
범주형: 범주 별 빈도 및 비율
- Interactions, Correlations: 두 개의 변수 간 상관관계 확인
- Missing values: 결측치 확인
- Sample: data head, tailimport pandas_profiling
from pandas_profiling import ProfileReport
housing_data.profile_report()
#프로파일링 결과 html을 파일로 저장
housing_data.profile_report().to_file('./housing_data_pr_report.html')
난 성미다.