Hyperparameter Tuning
- 머신 러닝 모델의 성능을 최적화하는 중요한 과정
- 모델의 성능을 최대화하고
- 과적합을 방지해줌
- 대규모 데이터셋과 복잡한 모델에서 영향이 크기 때문에 적절한 튜닝이 필요함
Hyperparameter
- 모델 학습 전에 설정되는 파라미터, 학습 과정 제어
ex) knn : n_neighbors
decision tree : max_depth 등
1. KNN
- k 값에 따라 성능이 달라짐 - n_neghbors
- k 값이 가장 클 때 (= 전체 데이터 개수) 가장 단순 모델 ➡️ 평균, 최빈값
- k 값이 작을수록 복잡한 모델
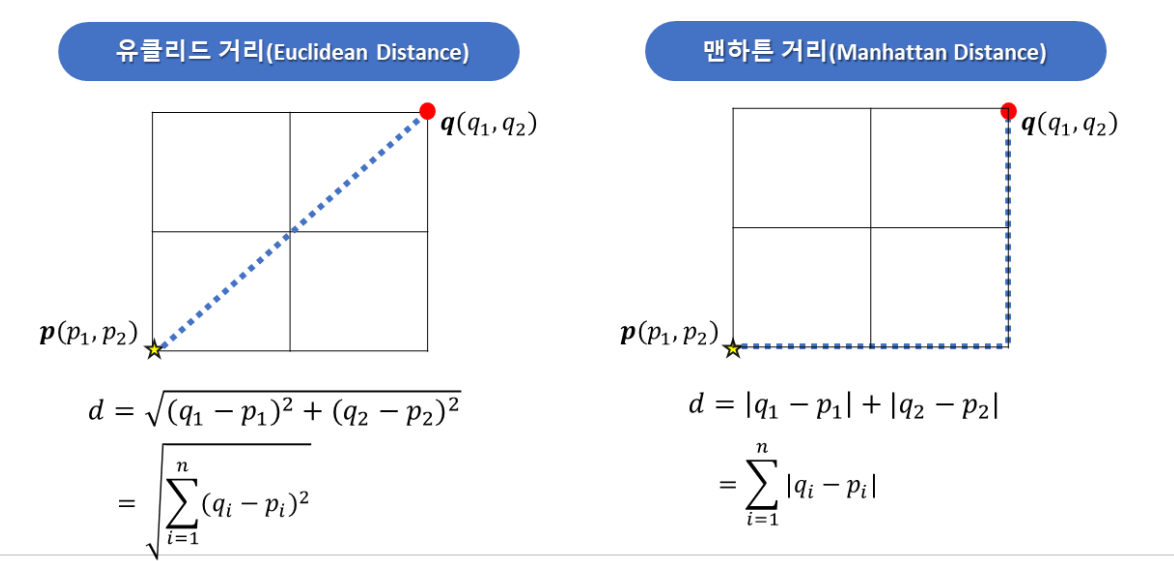
거리계산법에 따라 성능이 달라짐
2. Decision Tree
max_depth- 트리의 최대 깊이 제한
- 기본값 : 값이 결정될 때까지 깊이 키우며 분할 or 노드 데이터 개수가
min_samples_split보다 작아질 때까지 깊이 증가 - 작을수록 트리 깊이가 제한되어 모델이 단순해 짐
min_samples_leaf- leaf가 되기 위한 최소한의 샘플 데이터 수
- 클수록 단순
min_samples_split- 노드를 분할하기 위한 최소한의 샘플 데이터 수
- 클수록 단순
💡위 파라미터 값을 조정해 모델을 단순화 시켜 과대적합 위험을 줄임
하이퍼파라미터 찾는 과정
1. Grid Search
- 지정된 파라미터의 모든 조합을 사용하여 학습데이터에 대해 가장 좋은 성능을 보인 파라미터 값으로 자동 학습함
장점
- 성능 최적화
- 자동화
- 객관성
사용법
- GridSearchCV
- n_iter 옵션을 지정하지 않음
- KNN
# 함수 불러오기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# 파라미터 선언
param = {'n_neighbors': range(1, 500, 10),
'metric': ['euclidean', 'manhattan']}
# 기본모델 선언
knn_model = KNeighborsClassifier()
# Grid Search 선언
model = GridSearchCV(knn_model, param, cv=3)
# 학습하기
model.fit(x_train, y_train)
# 수행 정보
model.cv_results_
# 최적 파라미터
model.best_params_
# 최고 성능
model.best_score_
- Decision Tree
# 모델링
model = DecisionTreeRegressor(max_depth=5, random_state=1)
# 파라미터 선언
param = {'max_depth': range(1, 21)}
model = GridSearchCV(DecisionTreeRegressor(max_depth=5),
param,
cv = 5,
)
model.fit(x_train, y_train)
print('최적파라미터:', model.best_params_)
print('예측성능:', model.best_score_)
y_val_pred = model.predict(x_val)
# 평가하기
print('MAE:', mean_absolute_error(y_val, y_val_pred))
print('R2:', r2_score(y_val, y_val_pred))
2. Random Search
- 가능한 파라미터의 값들 중 무작위로 선택하여 학습
사용법
- RandomSearchCV
- n_iter : 수행횟수 지정 (임의의 파라미터 조합수)
# 함수 불러오기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import RandomizedSearchCV
# 파라미터 선언
param = {'n_neighbors': range(1, 500, 10),
'metric': ['euclidean', 'manhattan']}
# 기본모델 선언
knn_model = KNeighborsClassifier()
# Random Search 선언
model = RandomizedSearchCV(knn_model,
param,
cv=3,
n_iter=20)
# 학습하기
model.fit(x_train, y_train)
# 수행 정보
model.cv_results_
# 최적 파라미터
model.best_params_
# 최고 성능
model.best_score_모델 튜닝
# 파라미터 선언
# max_depth: 1~50
param = {'max_depth': range(1, 51)}
# Random Search 선언
# cv=5
# n_iter=20
# scoring='r2' 사용할 평가지표 기본
model = RandomizedSearchCV(DecisionTreeRegressor(),
param,
cv=3, # k 분할 개수
n_iter=20 # 몇 개를 선택할 것인가
)
# 학습하기
model.fit(x_train, y_train)
# 중요 정보 확인
print('테스트로얻은성능:', model.cv_results_['mean_test_score'])
print('최적파라미터:', model.best_params_)
print('최고성능:', model.best_score_)
# model.best_estimator_ 모델의 변수 중요도
plt.figure(figsize=(5, 5))
plt.barh(y=list(x), width=model.best_estimator_.feature_importances_)
plt.show()
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print('MAE:', mean_absolute_error(y_test, y_pred))
print('R2-Score:', r2_score(y_test, y_pred))
# 시각화 모듈 불러오기
from sklearn.tree import export_graphviz
from IPython.display import Image
# 이미지 파일 만들기
export_graphviz(model.best_estimator_, # 모델 이름
out_file='tree.dot', # 파일 이름
feature_names=x.columns, # Feature 이름
rounded=True, # 둥근 테두리
precision=2, # 불순도 소숫점 자리수
max_depth=3, # 표시할 깊이 지정
filled=True) # 박스 내부 채우기
# 파일 변환(dpi defaulr 96)
!dot tree.dot -Tpng -otree.png -Gdpi=96
# 이미지 파일 표시
Image(filename='tree.png', width=650)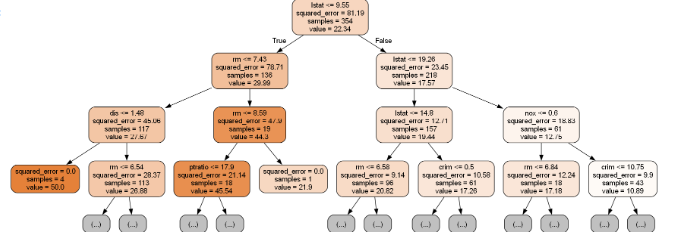
Grid vs Random
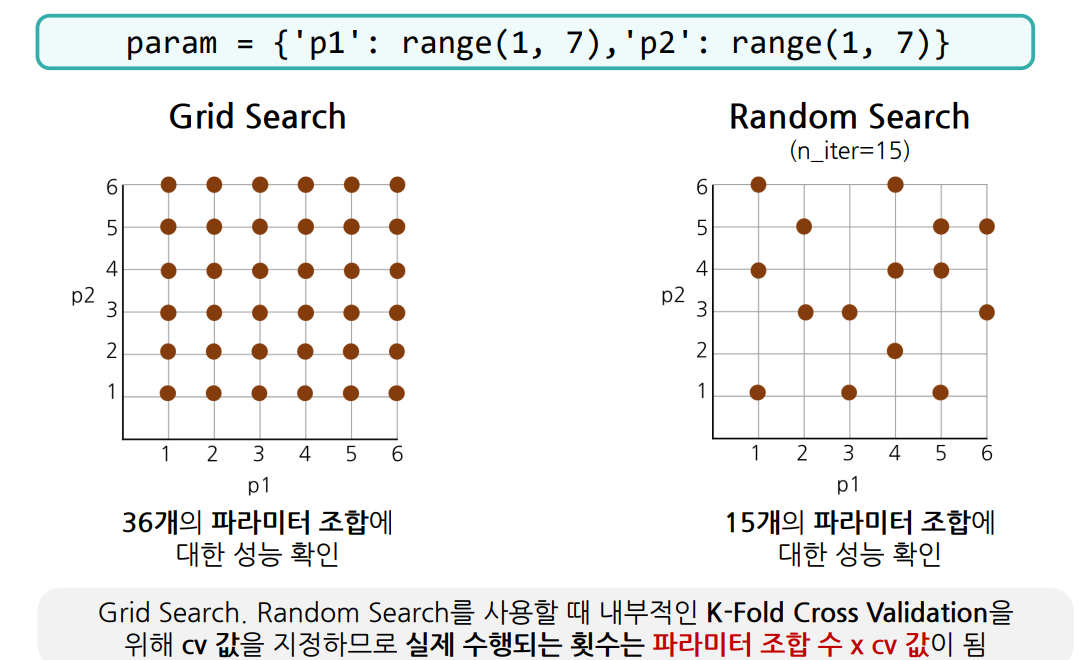
# 파라미터 하나의 경우
param = {'n_neighbors': range(1, 101)}
# 파라미터 두 개 경우
param = {'n_neighbors': range(1, 101),
'metric': ['euclidean', 'manhattan']}| grid | random |
|---|---|
| 100번 수행, 모든 경우 확인 | 지정한 개수의 임의의 값에 대해서 확인 |
튜닝시 주의 사항
- 최적화된 성능을 얻어도 성능보장이 어려움
- 과적합될 수 있음

난 성미다.