Describe Anything Model?
-
DAM 모델은 DLC 문제를 해결하기 위해 Nvidia에서 제안한 인공지능 모델
-
Code / Paper PDF / Quick Demo
Detailed Localized Captioning (DLC) task
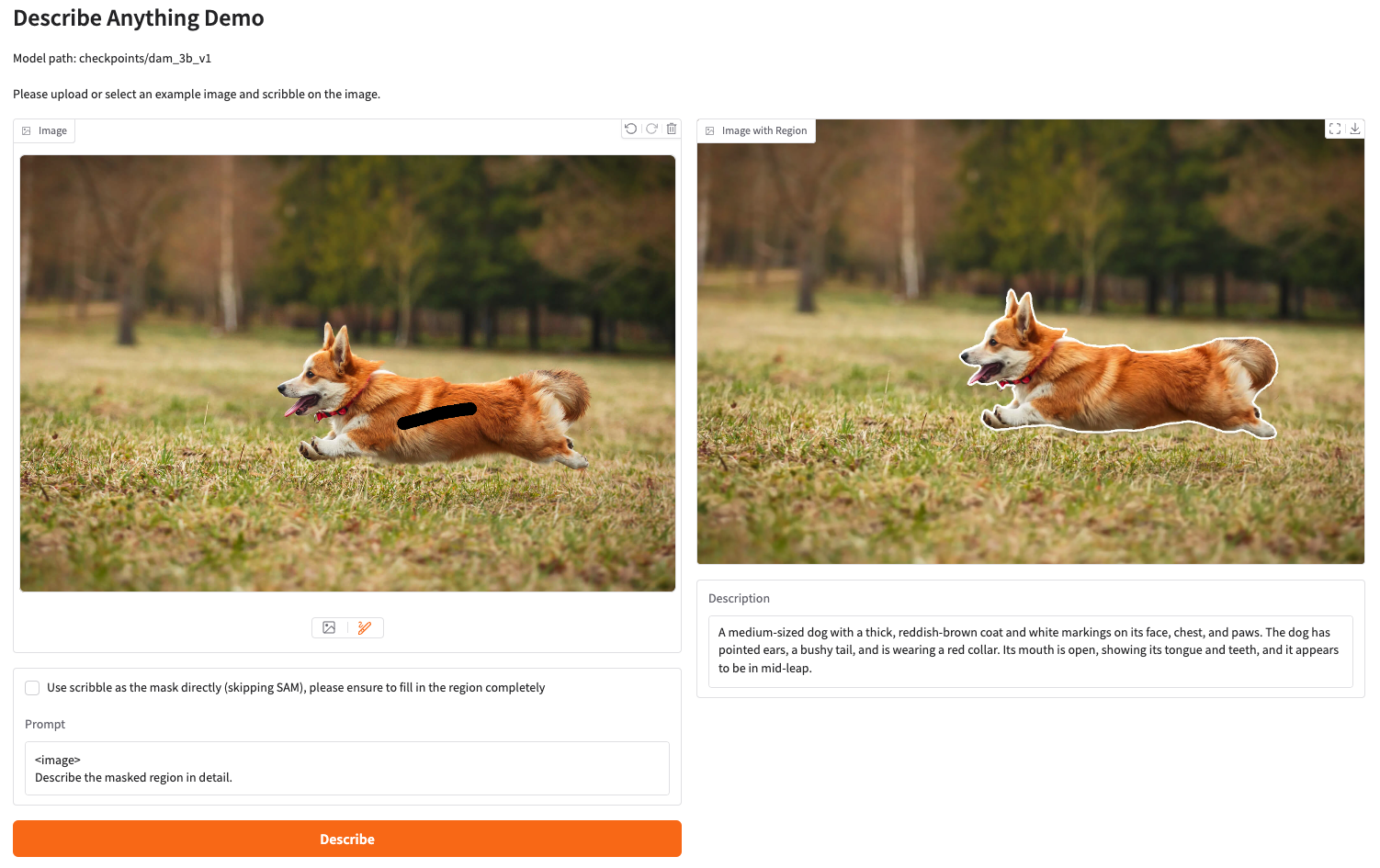
- User prompt로 지정한 영역에 대해서 Captioning을 수행하는 task.
- 본 논문이 제안됨과 동시에 같이 정의된 task로 보임
Model Arch & Training
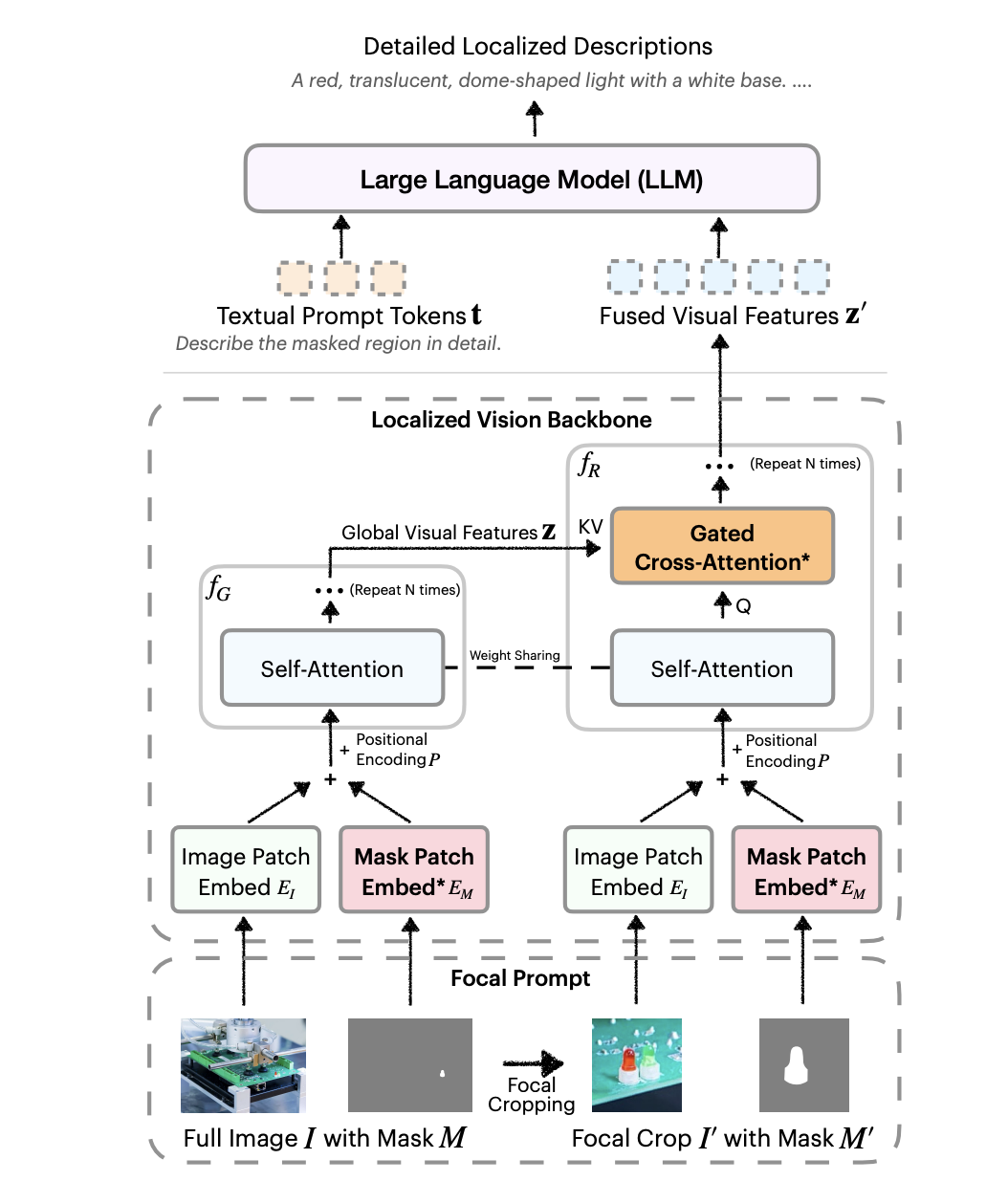
-
모델 Input: { 전체 이미지, User Prompt -> SAM2 -> Local Mask}
- 프롬프트는 항상 Visual Prompt이며, 항상 마스크로 변환되어 사용됨
-
모델 Output: Masking 된 영역에 대한 Captioning
-
Architecture에서 주목할 부분:
- Focal Prompt
- Mask → Bbox 변환
- Fit하게 잡은 뒤 마진 값 를 가로, 세로에 곱함
- Box 가로 세로 크기 조정
- Max(Bbox’s Width or Height x , 48)
- 크기 조정한 Bbox로 이미지, 마스크를 각각 crop.
- Handling Localization Inputs (Embedder)
- 전체 영상 임베더와 크롭 영상 임베더를 따로 두고 학습시킴.
- 단순하게 크롭시키는 것은 성능하락 한다고 함
- Global Visual Feature Cross Attention

- f_R 의 모든 레이어에 cross attention을 삽입
- General, Region간의 Cross Attention임.
- 대신 아래와 같이 , 라는 learnable param을 두고 FFN 전에 사용.
- 초기 값은 0으로 둠
Fine tuning 시에 smooth adapt됨
또 상대적으로 적은 train 셋으로 학습 가능해짐
- 초기 값은 0으로 둠
- Video일 땐? -> 매 프레임마다 feature 추출 후 concat, LLM으로 쏨
- Semi supervised로 학습됨
- Fine level의 데이터로 우선 학습
- Web 이미지 수집 -> 우선 학습된 DAM으로 infer
- Clip으로 생성된 caption confidence filtering 함.
- Focal Prompt
